

Procedimiento de prueba
 Sugerir cambios
Sugerir cambios
Esta sección describe las tareas necesarias para completar la validación.
Prerrequisitos
Para ejecutar las tareas descritas en esta sección, debe tener acceso a un host Linux o macOS con las siguientes herramientas instaladas y configuradas:
Escenario 1: Inferencia bajo demanda en JupyterLab
-
Cree un espacio de nombres de Kubernetes para cargas de trabajo de inferencia de IA/ML.
$ kubectl create namespace inference namespace/inference created
-
Utilice el kit de herramientas NetApp DataOps para aprovisionar un volumen persistente para almacenar los datos en los que realizará la inferencia.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Utilice el kit de herramientas NetApp DataOps para crear un nuevo espacio de trabajo de JupyterLab. Monte el volumen persistente que se creó en el paso anterior utilizando el
--mount- pvcopción. Asigne GPU NVIDIA al espacio de trabajo según sea necesario mediante el uso de-- nvidia-gpuopción.En el siguiente ejemplo, el volumen persistente
inference-dataestá montado en el contenedor del espacio de trabajo de JupyterLab en/home/jovyan/data. Al utilizar imágenes de contenedor oficiales del Proyecto Jupyter,/home/jovyanse presenta como el directorio de nivel superior dentro de la interfaz web de JupyterLab.$ netapp_dataops_k8s_cli.py create jupyterlab --namespace=inference --workspace-name=live-inference --size=50Gi --nvidia-gpu=2 --mount-pvc=inference-data:/home/jovyan/data Set workspace password (this password will be required in order to access the workspace): Re-enter password: Creating persistent volume for workspace... Creating PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Creating Service 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Service successfully created. Attaching Additional PVC: 'inference-data' at mount_path: '/home/jovyan/data'. Creating Deployment 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Deployment 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Deployment 'ntap-dsutil-jupyterlab-live-inference' to reach Ready state. Deployment successfully created. Workspace successfully created. To access workspace, navigate to http://192.168.0.152:32721
-
Acceda al espacio de trabajo de JupyterLab utilizando la URL especificada en la salida del
create jupyterlabdominio. El directorio de datos representa el volumen persistente que se montó en el espacio de trabajo.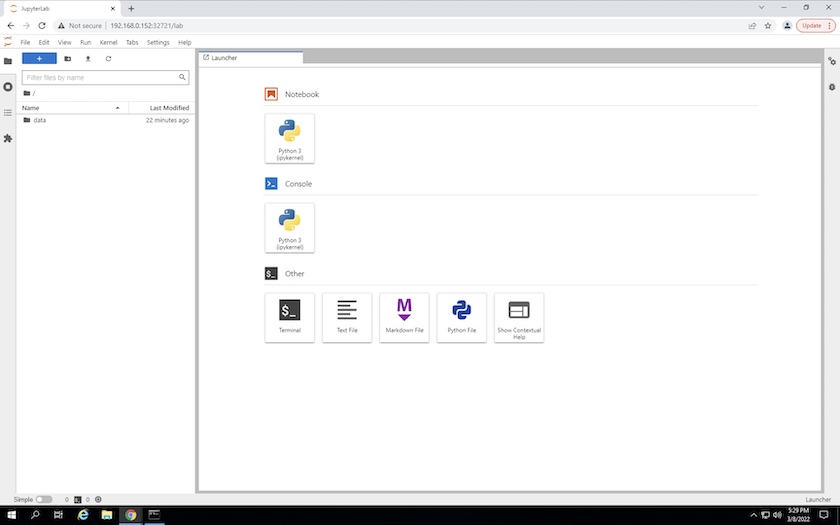
-
Abrir el
datadirectorio y cargar los archivos sobre los cuales se realizará la inferencia. Cuando se cargan archivos en el directorio de datos, se almacenan automáticamente en el volumen persistente que se montó en el espacio de trabajo. Para cargar archivos, haga clic en el ícono Cargar archivos, como se muestra en la siguiente imagen.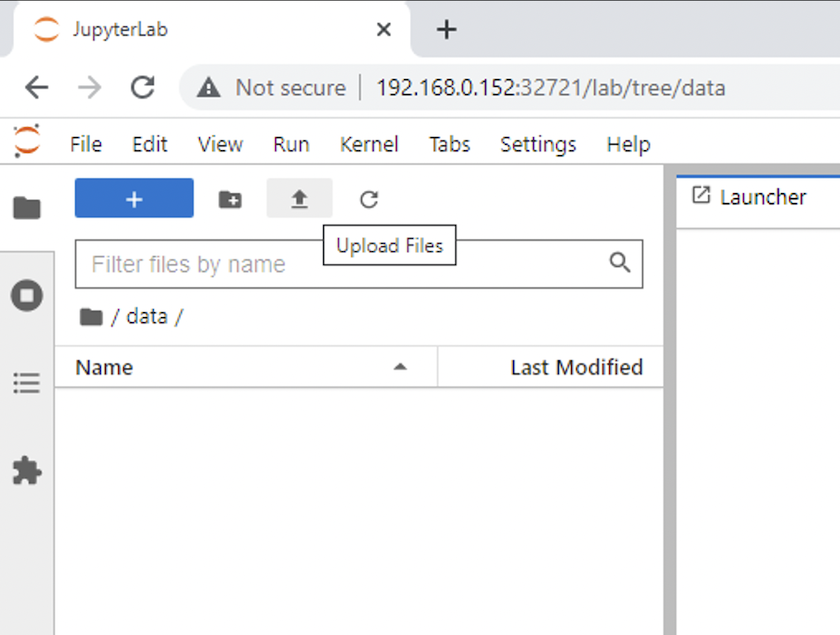
-
Regrese al directorio de nivel superior y cree un nuevo cuaderno.
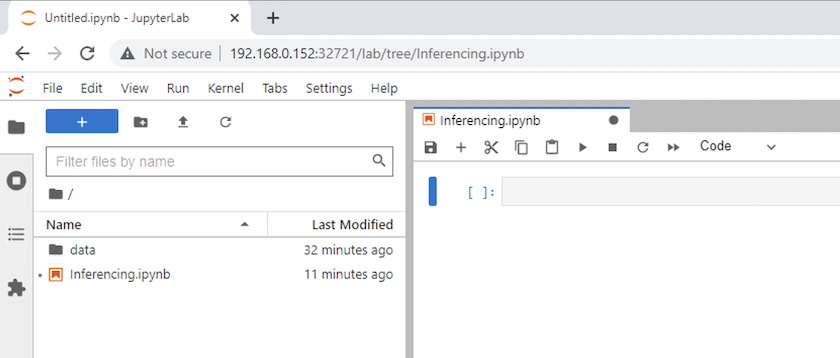
-
Añade código de inferencia al cuaderno. El siguiente ejemplo muestra el código de inferencia para un caso de uso de detección de imágenes.
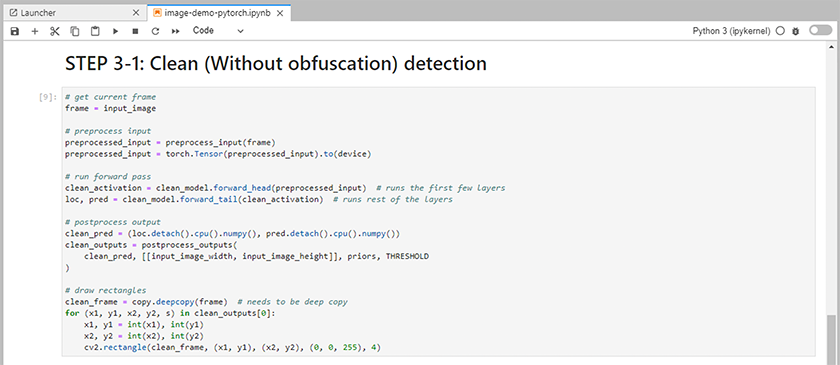
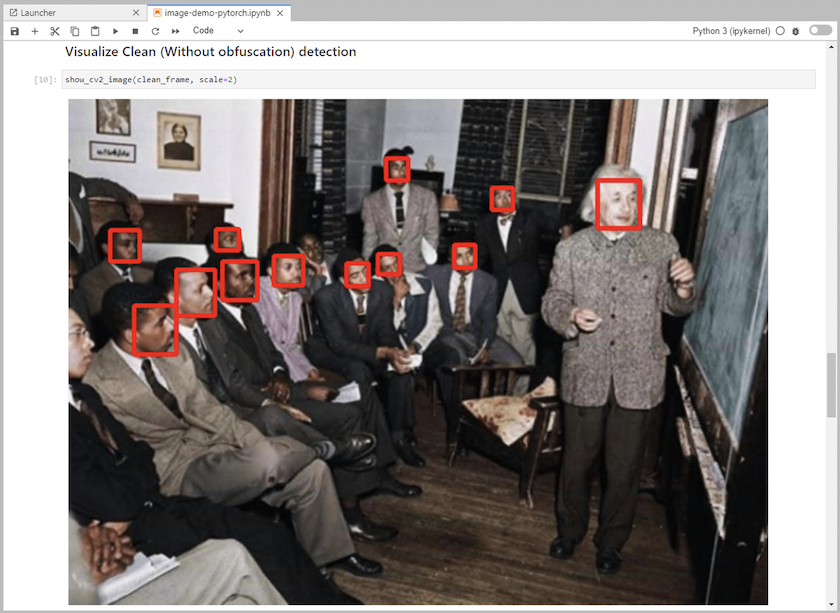
-
Agregue la ofuscación de Protopia a su código de inferencia. Protopia trabaja directamente con los clientes para proporcionar documentación específica de cada caso de uso y está fuera del alcance de este informe técnico. El siguiente ejemplo muestra el código de inferencia para un caso de uso de detección de imágenes con ofuscación de Protopia agregada.
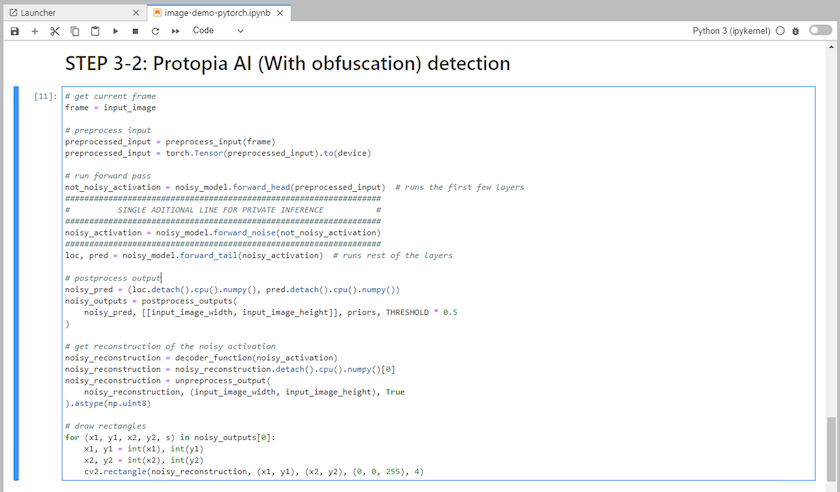
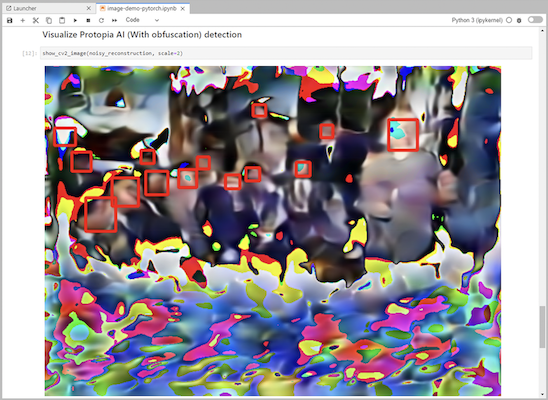
Escenario 2: Inferencia por lotes en Kubernetes
-
Cree un espacio de nombres de Kubernetes para cargas de trabajo de inferencia de IA/ML.
$ kubectl create namespace inference namespace/inference created
-
Utilice el kit de herramientas NetApp DataOps para aprovisionar un volumen persistente para almacenar los datos en los que realizará la inferencia.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Rellene el nuevo volumen persistente con los datos sobre los que realizará la inferencia.
Existen varios métodos para cargar datos en un PVC. Si sus datos están actualmente almacenados en una plataforma de almacenamiento de objetos compatible con S3, como NetApp StorageGRID o Amazon S3, puede utilizar "Capacidades de NetApp DataOps Toolkit S3 Data Mover" . Otro método simple es crear un espacio de trabajo de JupyterLab y luego cargar archivos a través de la interfaz web de JupyterLab, como se describe en los pasos 3 a 5 en la sección "Escenario 1: Inferencia bajo demanda en JupyterLab . "
-
Cree un trabajo de Kubernetes para su tarea de inferencia por lotes. El siguiente ejemplo muestra un trabajo de inferencia por lotes para un caso de uso de detección de imágenes. Este trabajo realiza inferencias en cada imagen de un conjunto de imágenes y escribe métricas de precisión de inferencia en stdout.
$ vi inference-job-raw.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-raw namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-raw.yaml job.batch/netapp-inference-raw created -
Confirme que el trabajo de inferencia se completó correctamente.
$ kubectl -n inference logs netapp-inference-raw-255sp 100%|██████████| 89/89 [00:52<00:00, 1.68it/s] Reading Predictions : 100%|██████████| 10/10 [00:01<00:00, 6.23it/s] Predicting ... : 100%|██████████| 10/10 [00:16<00:00, 1.64s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.9491256561145955 FDDB-fold-2 Val AP: 0.9205024466101926 FDDB-fold-3 Val AP: 0.9253013871078468 FDDB-fold-4 Val AP: 0.9399781485863011 FDDB-fold-5 Val AP: 0.9504280149478732 FDDB-fold-6 Val AP: 0.9416473519339292 FDDB-fold-7 Val AP: 0.9241631566241117 FDDB-fold-8 Val AP: 0.9072663297546659 FDDB-fold-9 Val AP: 0.9339648715035469 FDDB-fold-10 Val AP: 0.9447707905560152 FDDB Dataset Average AP: 0.9337148153739079 ================================================= mAP: 0.9337148153739079
-
Agregue la ofuscación de Protopia a su trabajo de inferencia. Puede encontrar instrucciones específicas de casos de uso para agregar la ofuscación de Protopia directamente desde Protopia, lo cual está fuera del alcance de este informe técnico. El siguiente ejemplo muestra un trabajo de inferencia por lotes para un caso de uso de detección de rostros con ofuscación de Protopia agregada mediante un valor ALPHA de 0,8. Este trabajo aplica la ofuscación de Protopia antes de realizar la inferencia para cada imagen en un conjunto de imágenes y luego escribe métricas de precisión de inferencia en stdout.
Repetimos este paso para los valores ALPHA 0,05, 0,1, 0,2, 0,4, 0,6, 0,8, 0,9 y 0,95. Puedes ver los resultados en"Comparación de precisión de inferencia."
$ vi inference-job-protopia-0.8.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-protopia-0.8 namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent env: - name: ALPHA value: "0.8" command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB", "--alpha", "$(ALPHA)", "--noisy"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-protopia-0.8.yaml job.batch/netapp-inference-protopia-0.8 created -
Confirme que el trabajo de inferencia se completó correctamente.
$ kubectl -n inference logs netapp-inference-protopia-0.8-b4dkz 100%|██████████| 89/89 [01:05<00:00, 1.37it/s] Reading Predictions : 100%|██████████| 10/10 [00:02<00:00, 3.67it/s] Predicting ... : 100%|██████████| 10/10 [00:22<00:00, 2.24s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.8953066115834589 FDDB-fold-2 Val AP: 0.8819580264029936 FDDB-fold-3 Val AP: 0.8781107458462862 FDDB-fold-4 Val AP: 0.9085731346308461 FDDB-fold-5 Val AP: 0.9166445508275378 FDDB-fold-6 Val AP: 0.9101178994188819 FDDB-fold-7 Val AP: 0.8383443678423771 FDDB-fold-8 Val AP: 0.8476311547659464 FDDB-fold-9 Val AP: 0.8739624502111121 FDDB-fold-10 Val AP: 0.8905468076424851 FDDB Dataset Average AP: 0.8841195749171925 ================================================= mAP: 0.8841195749171925
Escenario 3: Servidor de inferencia NVIDIA Triton
-
Cree un espacio de nombres de Kubernetes para cargas de trabajo de inferencia de IA/ML.
$ kubectl create namespace inference namespace/inference created
-
Utilice NetApp DataOps Toolkit para aprovisionar un volumen persistente para utilizarlo como repositorio de modelos para el servidor de inferencia NVIDIA Triton.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=triton-model-repo --size=100Gi Creating PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'. PersistentVolumeClaim (PVC) 'triton-model-repo' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'.
-
Almacene su modelo en el nuevo volumen persistente en un "formato" que es reconocido por el servidor de inferencia NVIDIA Triton.
Existen varios métodos para cargar datos en un PVC. Un método simple es crear un espacio de trabajo de JupyterLab y luego cargar archivos a través de la interfaz web de JupyterLab, como se describe en los pasos 3 a 5 en "Escenario 1: Inferencia bajo demanda en JupyterLab . "
-
Utilice NetApp DataOps Toolkit para implementar una nueva instancia de NVIDIA Triton Inference Server.
$ netapp_dataops_k8s_cli.py create triton-server --namespace=inference --server-name=netapp-inference --model-repo-pvc-name=triton-model-repo Creating Service 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Service successfully created. Creating Deployment 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Deployment 'ntap-dsutil-triton-netapp-inference' created. Waiting for Deployment 'ntap-dsutil-triton-netapp-inference' to reach Ready state. Deployment successfully created. Server successfully created. Server endpoints: http: 192.168.0.152: 31208 grpc: 192.168.0.152: 32736 metrics: 192.168.0.152: 30009/metrics
-
Utilice un SDK de cliente Triton para realizar una tarea de inferencia. El siguiente extracto de código Python utiliza el SDK del cliente Python de Triton para realizar una tarea de inferencia para un caso de uso de detección de rostros. Este ejemplo llama a la API Triton y pasa una imagen para inferir. Luego, el servidor de inferencia Triton recibe la solicitud, invoca el modelo y devuelve el resultado de la inferencia como parte de los resultados de la API.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass clean_activation = clean_model_head(preprocessed_input) # runs the first few layers ###################################################################################### # pass clean image to Triton Inference Server API for inferencing # ###################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_base" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(clean_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ###################################################################################### # postprocess output clean_pred = (loc_numpy, pred_numpy) clean_outputs = postprocess_outputs( clean_pred, [[input_image_width, input_image_height]], priors, THRESHOLD ) # draw rectangles clean_frame = copy.deepcopy(frame) # needs to be deep copy for (x1, y1, x2, y2, s) in clean_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(clean_frame, (x1, y1), (x2, y2), (0, 0, 255), 4) -
Agregue la ofuscación de Protopia a su código de inferencia. Puede encontrar instrucciones específicas de casos de uso para agregar la ofuscación de Protopia directamente desde Protopia; sin embargo, este proceso está fuera del alcance de este informe técnico. El siguiente ejemplo muestra el mismo código Python que se muestra en el paso 5 anterior, pero con la ofuscación de Protopia agregada.
Tenga en cuenta que la ofuscación de Protopia se aplica a la imagen antes de pasarla a la API de Triton. De esta manera la imagen no ofuscada nunca sale de la máquina local. Sólo la imagen ofuscada pasa a través de la red. Este flujo de trabajo es aplicable a casos de uso en los que los datos se recopilan dentro de una zona confiable pero luego deben pasarse fuera de esa zona confiable para realizar inferencias. Sin la ofuscación de Protopia, no es posible implementar este tipo de flujo de trabajo sin que los datos confidenciales salgan de la zona confiable.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass not_noisy_activation = noisy_model_head(preprocessed_input) # runs the first few layers ################################################################## # obfuscate image locally prior to inferencing # # SINGLE ADITIONAL LINE FOR PRIVATE INFERENCE # ################################################################## noisy_activation = noisy_model_noise(not_noisy_activation) ################################################################## ########################################################################################### # pass obfuscated image to Triton Inference Server API for inferencing # ########################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_noisy" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(noisy_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ########################################################################################### # postprocess output noisy_pred = (loc_numpy, pred_numpy) noisy_outputs = postprocess_outputs( noisy_pred, [[input_image_width, input_image_height]], priors, THRESHOLD * 0.5 ) # get reconstruction of the noisy activation noisy_reconstruction = decoder_function(noisy_activation) noisy_reconstruction = noisy_reconstruction.detach().cpu().numpy()[0] noisy_reconstruction = unpreprocess_output( noisy_reconstruction, (input_image_width, input_image_height), True ).astype(np.uint8) # draw rectangles for (x1, y1, x2, y2, s) in noisy_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(noisy_reconstruction, (x1, y1), (x2, y2), (0, 0, 255), 4)