

Descripción general de la tecnología
 Sugerir cambios
Sugerir cambios
Esta sección se centra en la descripción general de la tecnología para MLOps de código abierto con NetApp.
Inteligencia artificial
La IA es una disciplina de la informática en la que se entrena a las computadoras para imitar las funciones cognitivas de la mente humana. Los desarrolladores de IA entrenan a las computadoras para aprender y resolver problemas de una manera similar, o incluso superior, a la de los humanos. El aprendizaje profundo y el aprendizaje automático son subcampos de la IA. Las organizaciones están adoptando cada vez más IA, ML y DL para respaldar sus necesidades comerciales críticas. Algunos ejemplos son los siguientes:
-
Analizar grandes cantidades de datos para descubrir información empresarial previamente desconocida
-
Interactuar directamente con los clientes mediante el procesamiento del lenguaje natural
-
Automatizar diversos procesos y funciones empresariales
Las cargas de trabajo de inferencia y entrenamiento de IA modernas requieren capacidades informáticas masivamente paralelas. Por lo tanto, las GPU se utilizan cada vez más para ejecutar operaciones de IA porque las capacidades de procesamiento paralelo de las GPU son muy superiores a las de las CPU de propósito general.
Contenedores
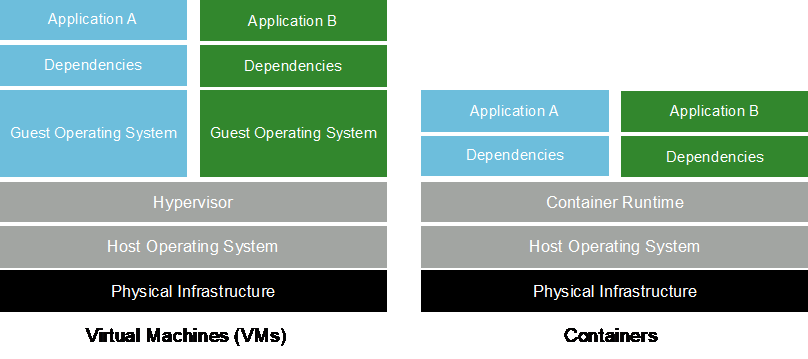
Los contenedores son instancias de espacio de usuario aisladas que se ejecutan sobre un núcleo de sistema operativo host compartido. La adopción de contenedores está aumentando rápidamente. Los contenedores ofrecen muchos de los mismos beneficios de sandbox de aplicaciones que ofrecen las máquinas virtuales (VM). Sin embargo, debido a que se han eliminado las capas de hipervisor y sistema operativo invitado de los que dependen las máquinas virtuales, los contenedores son mucho más livianos. La siguiente figura muestra una visualización de máquinas virtuales versus contenedores.
Los contenedores también permiten el empaquetado eficiente de dependencias de aplicaciones, tiempos de ejecución, etc., directamente con una aplicación. El formato de embalaje de contenedores más utilizado es el contenedor Docker. Una aplicación que se ha contenedorizado en el formato de contenedor Docker se puede ejecutar en cualquier máquina que pueda ejecutar contenedores Docker. Esto es cierto incluso si las dependencias de la aplicación no están presentes en la máquina porque todas las dependencias están empaquetadas en el propio contenedor. Para obtener más información, visite el "Sitio web de Docker" .
Kubernetes
Kubernetes es una plataforma de orquestación de contenedores distribuida y de código abierto que fue diseñada originalmente por Google y ahora es mantenida por la Cloud Native Computing Foundation (CNCF). Kubernetes permite la automatización de funciones de implementación, administración y escalamiento para aplicaciones en contenedores. En los últimos años, Kubernetes ha surgido como la plataforma dominante de orquestación de contenedores. Para obtener más información, visite el "Sitio web de Kubernetes" .
Trident de NetApp
"Trident"permite el consumo y la gestión de recursos de almacenamiento en todas las plataformas de almacenamiento NetApp más populares, en la nube pública o en las instalaciones, incluidas ONTAP (AFF, FAS, Select, Cloud, Amazon FSx ONTAP), el servicio Azure NetApp Files y Google Cloud NetApp Volumes. Trident es un orquestador de almacenamiento dinámico compatible con la interfaz de almacenamiento de contenedores (CSI) que se integra de forma nativa con Kubernetes.
Kit de herramientas DataOps de NetApp
El"Kit de herramientas DataOps de NetApp" es una herramienta basada en Python que simplifica la gestión de espacios de trabajo de desarrollo/entrenamiento y servidores de inferencia respaldados por almacenamiento NetApp de alto rendimiento y escalabilidad horizontal. Las capacidades clave incluyen:
-
Aprovisione rápidamente nuevos espacios de trabajo de alta capacidad respaldados por almacenamiento NetApp de alto rendimiento y escalabilidad horizontal.
-
Clonar casi instantáneamente espacios de trabajo de alta capacidad para permitir la experimentación o la iteración rápida.
-
Guarde casi instantáneamente instantáneas de espacios de trabajo de alta capacidad para realizar copias de seguridad y/o trazabilidad/establecimiento de referencia.
-
Aprovisione, clone y cree instantáneas de volúmenes de datos de alto rendimiento y alta capacidad de manera casi instantánea.
Flujo de aire de Apache
Apache Airflow es una plataforma de gestión de flujo de trabajo de código abierto que permite la creación, programación y supervisión programática de flujos de trabajo empresariales complejos. A menudo se utiliza para automatizar flujos de trabajo de ETL y canalización de datos, pero no se limita a estos tipos de flujos de trabajo. El proyecto Airflow fue iniciado por Airbnb, pero desde entonces se ha vuelto muy popular en la industria y ahora está bajo los auspicios de The Apache Software Foundation. Airflow está escrito en Python, los flujos de trabajo de Airflow se crean a través de scripts de Python y Airflow está diseñado bajo el principio de "configuración como código". Muchos usuarios empresariales de Airflow ahora ejecutan Airflow sobre Kubernetes.
Gráficos acíclicos dirigidos (DAG)
En Airflow, los flujos de trabajo se denominan gráficos acíclicos dirigidos (DAG). Los DAG se componen de tareas que se ejecutan en secuencia, en paralelo o en una combinación de ambas, según la definición del DAG. El programador Airflow ejecuta tareas individuales en una matriz de trabajadores, cumpliendo con las dependencias a nivel de tarea que se especifican en la definición de DAG. Los DAG se definen y crean mediante scripts de Python.
Cuaderno Jupyter
Los Jupyter Notebooks son documentos tipo wiki que contienen código en vivo y texto descriptivo. Los Jupyter Notebooks se utilizan ampliamente en la comunidad de IA y ML como un medio para documentar, almacenar y compartir proyectos de IA y ML. Para obtener más información sobre Jupyter Notebooks, visite el sitio web "Sitio web de Jupyter" .
Servidor de Jupyter Notebook
Un servidor Jupyter Notebook es una aplicación web de código abierto que permite a los usuarios crear Jupyter Notebooks.
JupyterHub
JupyterHub es una aplicación multiusuario que permite a un usuario individual aprovisionar y acceder a su propio servidor Jupyter Notebook. Para obtener más información sobre JupyterHub, visite el sitio "Sitio web de JupyterHub" .
Flujo de ml
MLflow es una popular plataforma de gestión del ciclo de vida de la IA de código abierto. Las características clave de MLflow incluyen el seguimiento de experimentos de IA/ML y un repositorio de modelos de IA/ML. Para obtener más información sobre MLflow, visite el sitio web "Sitio web de MLflow" .
Kubeflow
Kubeflow es un kit de herramientas de inteligencia artificial y aprendizaje automático de código abierto para Kubernetes que fue desarrollado originalmente por Google. El proyecto Kubeflow hace que las implementaciones de flujos de trabajo de IA y ML en Kubernetes sean simples, portátiles y escalables. Kubeflow abstrae las complejidades de Kubernetes, lo que permite a los científicos de datos centrarse en lo que mejor saben: la ciencia de datos. Vea la siguiente figura para ver una visualización. Kubeflow es una buena opción de código abierto para las organizaciones que prefieren una plataforma MLOps todo en uno. Para obtener más información, visite el "Sitio web de Kubeflow" .
Tuberías de Kubeflow
Las canalizaciones de Kubeflow son un componente clave de Kubeflow. Kubeflow Pipelines es una plataforma y un estándar para definir e implementar flujos de trabajo de IA y ML portátiles y escalables. Para obtener más información, consulte la "documentación oficial de Kubeflow" .
Cuadernos de Kubeflow
Kubeflow simplifica el aprovisionamiento y la implementación de servidores Jupyter Notebook en Kubernetes. Para obtener más información sobre Jupyter Notebooks en el contexto de Kubeflow, consulte "documentación oficial de Kubeflow" .
Katib
Katib es un proyecto nativo de Kubernetes para el aprendizaje automático automatizado (AutoML). Katib admite el ajuste de hiperparámetros, la detención anticipada y la búsqueda de arquitectura neuronal (NAS). Katib es un proyecto que es agnóstico a los marcos de aprendizaje automático (ML). Puede ajustar hiperparámetros de aplicaciones escritas en cualquier lenguaje elegido por el usuario y admite de forma nativa muchos marcos de ML, como TensorFlow, MXNet, PyTorch, XGBoost y otros. Katib admite muchos algoritmos AutoML diferentes, como optimización bayesiana, estimadores de árbol de Parzen, búsqueda aleatoria, estrategia de evolución de adaptación de matriz de covarianza, hiperbanda, búsqueda de arquitectura neuronal eficiente, búsqueda de arquitectura diferenciable y muchos más. Para obtener más información sobre Jupyter Notebooks en el contexto de Kubeflow, consulte "documentación oficial de Kubeflow" .
ONTAP de NetApp
ONTAP 9, la última generación de software de gestión de almacenamiento de NetApp, permite a las empresas modernizar la infraestructura y realizar la transición a un centro de datos preparado para la nube. Al aprovechar las capacidades de gestión de datos líderes en la industria, ONTAP permite la gestión y protección de datos con un único conjunto de herramientas, independientemente de dónde residan esos datos. También puede mover datos libremente a donde sea necesario: el borde, el núcleo o la nube. ONTAP 9 incluye numerosas características que simplifican la gestión de datos, aceleran y protegen datos críticos y habilitan capacidades de infraestructura de próxima generación en arquitecturas de nube híbrida.
Simplificar la gestión de datos
La gestión de datos es crucial para las operaciones de TI de la empresa y los científicos de datos, de modo que se utilicen los recursos adecuados para las aplicaciones de IA y el entrenamiento de conjuntos de datos de IA/ML. La siguiente información adicional sobre las tecnologías de NetApp está fuera del alcance de esta validación, pero podría ser relevante según su implementación.
El software de gestión de datos ONTAP incluye las siguientes características para optimizar y simplificar las operaciones y reducir el costo total de operación:
-
Compactación de datos en línea y deduplicación ampliada. La compactación de datos reduce el espacio desperdiciado dentro de los bloques de almacenamiento y la deduplicación aumenta significativamente la capacidad efectiva. Esto se aplica a los datos almacenados localmente y a los datos almacenados en la nube.
-
Calidad de servicio mínima, máxima y adaptativa (AQoS). Los controles granulares de calidad de servicio (QoS) ayudan a mantener los niveles de rendimiento de las aplicaciones críticas en entornos altamente compartidos.
-
FabricPool de NetApp . Proporciona niveles automáticos de datos fríos en opciones de almacenamiento en la nube pública y privada, incluidas Amazon Web Services (AWS), Azure y la solución de almacenamiento NetApp StorageGRID . Para obtener más información sobre FabricPool, consulte "TR-4598: Prácticas recomendadas de FabricPool" .
Acelerar y proteger los datos
ONTAP ofrece niveles superiores de rendimiento y protección de datos y amplía estas capacidades de las siguientes maneras:
-
Rendimiento y menor latencia. ONTAP ofrece el mayor rendimiento posible con la menor latencia posible.
-
Protección de datos. ONTAP proporciona capacidades de protección de datos integradas con gestión común en todas las plataformas.
-
Cifrado de volumen de NetApp (NVE). ONTAP ofrece cifrado nativo a nivel de volumen con soporte para administración de claves interna y externa.
-
Autenticación multitenencia y multifactor. ONTAP permite compartir recursos de infraestructura con los más altos niveles de seguridad.
Infraestructura a prueba de futuro
ONTAP ayuda a satisfacer necesidades comerciales exigentes y en constante cambio con las siguientes características:
-
Escalabilidad fluida y operaciones sin interrupciones. ONTAP admite la incorporación de capacidad sin interrupciones a controladores existentes y a clústeres de escalamiento horizontal. Los clientes pueden actualizar a las últimas tecnologías sin necesidad de costosas migraciones de datos ni interrupciones.
-
Conexión a la nube. ONTAP es el software de gestión de almacenamiento más conectado a la nube, con opciones para almacenamiento definido por software e instancias nativas de la nube en todas las nubes públicas.
-
Integración con aplicaciones emergentes. ONTAP ofrece servicios de datos de nivel empresarial para plataformas y aplicaciones de próxima generación, como vehículos autónomos, ciudades inteligentes e Industria 4.0, utilizando la misma infraestructura que respalda las aplicaciones empresariales existentes.
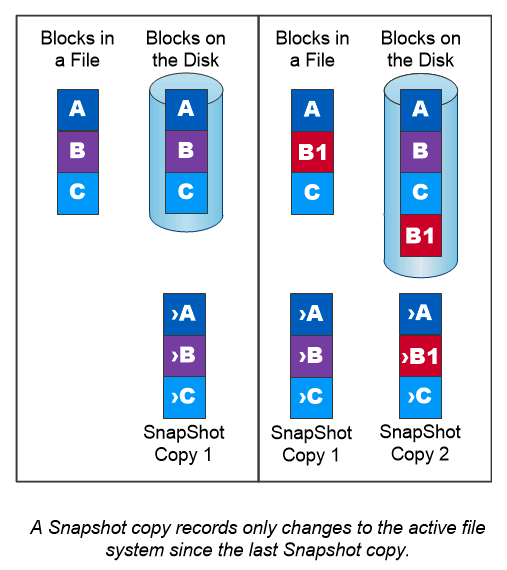
Copias instantáneas de NetApp
Una copia Snapshot de NetApp es una imagen de un volumen en un punto en el tiempo y de solo lectura. La imagen consume un espacio de almacenamiento mínimo y genera una sobrecarga de rendimiento insignificante porque solo registra los cambios en los archivos creados desde que se realizó la última copia de instantánea, como se muestra en la siguiente figura.
Las copias instantáneas deben su eficiencia a la tecnología central de virtualización de almacenamiento de ONTAP , Write Anywhere File Layout (WAFL). Al igual que una base de datos, WAFL utiliza metadatos para señalar bloques de datos reales en el disco. Pero, a diferencia de una base de datos, WAFL no sobrescribe los bloques existentes. Escribe datos actualizados en un nuevo bloque y cambia los metadatos. Esto se debe a que ONTAP hace referencia a metadatos cuando crea una copia instantánea, en lugar de copiar bloques de datos, que las copias instantáneas son tan eficientes. Al hacerlo así se elimina el tiempo de búsqueda que otros sistemas incurren para localizar los bloques a copiar, así como el coste de realizar la copia en sí.
Puede utilizar una copia instantánea para recuperar archivos individuales o LUN o para restaurar todo el contenido de un volumen. ONTAP compara la información del puntero en la copia instantánea con los datos del disco para reconstruir el objeto faltante o dañado, sin tiempo de inactividad ni un costo de rendimiento significativo.
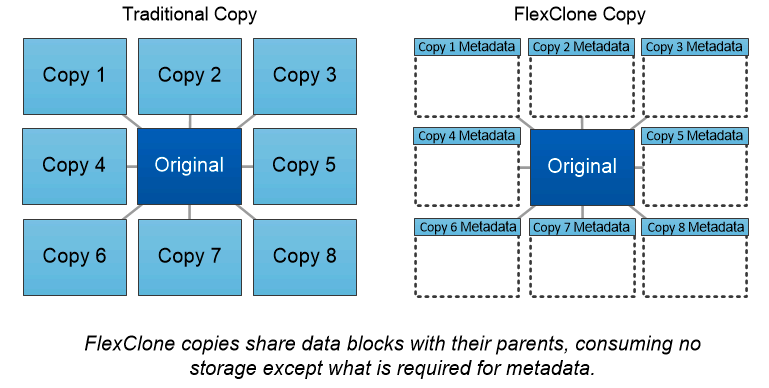
Tecnología FlexClone de NetApp
La tecnología NetApp FlexClone hace referencia a metadatos de Snapshot para crear copias grabables en un punto determinado del tiempo de un volumen. Las copias comparten bloques de datos con sus padres y no consumen almacenamiento excepto lo necesario para los metadatos hasta que se escriben los cambios en la copia, como se muestra en la siguiente figura. Donde las copias tradicionales pueden tardar minutos o incluso horas en crearse, el software FlexClone le permite copiar incluso los conjuntos de datos más grandes casi instantáneamente. Esto lo hace ideal para situaciones en las que se necesitan múltiples copias de conjuntos de datos idénticos (un espacio de trabajo de desarrollo, por ejemplo) o copias temporales de un conjunto de datos (probar una aplicación contra un conjunto de datos de producción).
Tecnología de replicación de datos SnapMirror de NetApp
El software NetApp SnapMirror es una solución de replicación unificada rentable y fácil de usar en toda la estructura de datos. Replica datos a altas velocidades a través de LAN o WAN. Le ofrece alta disponibilidad de datos y rápida replicación de datos para aplicaciones de todo tipo, incluidas aplicaciones críticas para el negocio en entornos virtuales y tradicionales. Cuando replica datos a uno o más sistemas de almacenamiento NetApp y actualiza continuamente los datos secundarios, sus datos se mantienen actualizados y están disponibles siempre que los necesite. No se requieren servidores de replicación externos. Vea la siguiente figura para ver un ejemplo de una arquitectura que aprovecha la tecnología SnapMirror .
El software SnapMirror aprovecha las eficiencias de almacenamiento de NetApp ONTAP al enviar solo los bloques modificados a través de la red. El software SnapMirror también utiliza compresión de red incorporada para acelerar las transferencias de datos y reducir la utilización del ancho de banda de la red hasta en un 70%. Con la tecnología SnapMirror , puede aprovechar un flujo de datos de replicación delgada para crear un único repositorio que mantenga tanto el espejo activo como las copias de puntos en el tiempo anteriores, lo que reduce el tráfico de red hasta en un 50%.
Copia y sincronización de NetApp BlueXP
"Copia y sincronización de BlueXP"Es un servicio de NetApp para la sincronización de datos rápida y segura. Ya sea que necesite transferir archivos entre recursos compartidos de archivos NFS o SMB locales, NetApp StorageGRID, NetApp ONTAP S3, Google Cloud NetApp Volumes, Azure NetApp Files, AWS S3, AWS EFS, Azure Blob, Google Cloud Storage o IBM Cloud Object Storage, BlueXP Copy and Sync mueve los archivos donde los necesita de manera rápida y segura.
Una vez transferidos los datos, estarán totalmente disponibles para su uso tanto en el origen como en el destino. BlueXP Copy and Sync puede sincronizar datos a pedido cuando se activa una actualización o sincronizar datos de manera continua según un cronograma predefinido. De todos modos, BlueXP Copy and Sync solo mueve los deltas, por lo que se minimiza el tiempo y el dinero gastados en la replicación de datos.
BlueXP Copy and Sync es una herramienta de software como servicio (SaaS) extremadamente sencilla de configurar y utilizar. Las transferencias de datos que se activan mediante BlueXP Copy and Sync se llevan a cabo a través de corredores de datos. Los agentes de datos de copia y sincronización de BlueXP se pueden implementar en AWS, Azure, Google Cloud Platform o en las instalaciones locales.
XCP de NetApp
"XCP de NetApp"es un software basado en el cliente para migraciones de datos de cualquier plataforma NetApp y de NetApp a NetApp , así como para obtener información sobre sistemas de archivos. XCP está diseñado para escalar y lograr el máximo rendimiento al utilizar todos los recursos del sistema disponibles para manejar conjuntos de datos de gran volumen y migraciones de alto rendimiento. XCP le ayuda a obtener visibilidad completa del sistema de archivos con la opción de generar informes.
Volúmenes FlexGroup de NetApp ONTAP
Un conjunto de datos de entrenamiento puede ser una colección de potencialmente miles de millones de archivos. Los archivos pueden incluir texto, audio, video y otras formas de datos no estructurados que deben almacenarse y procesarse para poder leerse en paralelo. El sistema de almacenamiento debe almacenar grandes cantidades de archivos pequeños y debe leer esos archivos en paralelo para realizar E/S secuenciales y aleatorias.
Un volumen FlexGroup es un espacio de nombres único que comprende múltiples volúmenes miembros constituyentes, como se muestra en la siguiente figura. Desde el punto de vista de un administrador de almacenamiento, un volumen FlexGroup se administra y actúa como un FlexVol volume de NetApp . Los archivos de un volumen FlexGroup se asignan a volúmenes miembro individuales y no se distribuyen entre volúmenes o nodos. Permiten las siguientes capacidades:
-
Los volúmenes FlexGroup proporcionan múltiples petabytes de capacidad y una latencia baja predecible para cargas de trabajo con alto contenido de metadatos.
-
Admiten hasta 400 mil millones de archivos en el mismo espacio de nombres.
-
Admiten operaciones paralelizadas en cargas de trabajo NAS en CPU, nodos, agregados y volúmenes FlexVol constituyentes.
