

MLOps de código abierto con NetApp
 Sugerir cambios
Sugerir cambios
Mike Oglesby, NetApp Sufian Ahmad, NetApp Rick Huang, NetApp Mohan Acharya, NetApp
Empresas y organizaciones de todos los tamaños y de muchas industrias están recurriendo a la inteligencia artificial (IA) para resolver problemas del mundo real, ofrecer productos y servicios innovadores y obtener una ventaja en un mercado cada vez más competitivo. Muchas organizaciones están recurriendo a herramientas MLOps de código abierto para mantenerse al día con el rápido ritmo de innovación en la industria. Estas herramientas de código abierto ofrecen capacidades avanzadas y características de última generación, pero a menudo no tienen en cuenta la disponibilidad ni la seguridad de los datos. Lamentablemente, esto significa que los científicos de datos altamente capacitados se ven obligados a pasar una cantidad significativa de tiempo esperando obtener acceso a los datos o esperando que se completen operaciones rudimentarias relacionadas con los datos. Al combinar las populares herramientas MLOps de código abierto con una infraestructura de datos inteligente de NetApp, las organizaciones pueden acelerar sus canales de datos, lo que, a su vez, acelera sus iniciativas de IA. Pueden extraer valor de sus datos y al mismo tiempo garantizar que permanezcan protegidos y seguros. Esta solución demuestra la combinación de las capacidades de gestión de datos de NetApp con varias herramientas y marcos de código abierto populares para abordar estos desafíos.
La siguiente lista destaca algunas capacidades clave que permite esta solución:
-
Los usuarios pueden aprovisionar rápidamente nuevos volúmenes de datos de alta capacidad y espacios de trabajo de desarrollo respaldados por almacenamiento NetApp de alto rendimiento y escalabilidad horizontal.
-
Los usuarios pueden clonar casi instantáneamente volúmenes de datos de alta capacidad y espacios de trabajo de desarrollo para permitir la experimentación o la iteración rápida.
-
Los usuarios pueden guardar casi instantáneamente instantáneas de volúmenes de datos de alta capacidad y espacios de trabajo de desarrollo para realizar copias de seguridad y/o trazabilidad/establecimiento de referencia.
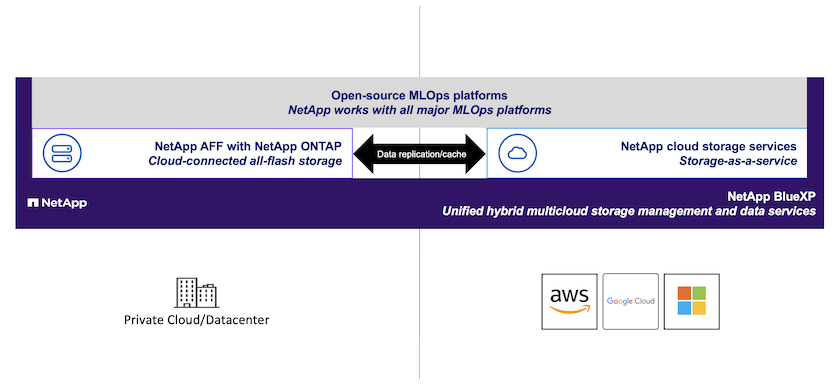
Un flujo de trabajo típico de MLOps incorpora espacios de trabajo de desarrollo, que generalmente toman la forma de"Cuadernos Jupyter" seguimiento de experimentos; canales de entrenamiento automatizados; canales de datos; e inferencia/implementación. Esta solución destaca varias herramientas y marcos diferentes que pueden usarse de forma independiente o en conjunto para abordar los diferentes aspectos del flujo de trabajo. También demostramos la combinación de las capacidades de gestión de datos de NetApp con cada una de estas herramientas. Esta solución está diseñada para ofrecer bloques de construcción a partir de los cuales una organización puede construir un flujo de trabajo MLOps personalizado que sea específico para sus casos de uso y requisitos.
Esta solución cubre las siguientes herramientas y marcos:
La siguiente lista describe patrones comunes para implementar estas herramientas de forma independiente o en conjunto.
-
Implementar JupyterHub, MLflow y Apache Airflow en conjunto - JupyterHub para"Cuadernos Jupyter" , MLflow para seguimiento de experimentos y Apache Airflow para capacitación automatizada y canalización de datos.
-
Implementar Kubeflow y Apache Airflow en conjunto - Kubeflow para"Cuadernos Jupyter" seguimiento de experimentos, canales de entrenamiento automatizados e inferencia; y Apache Airflow para canales de datos.
-
Implemente Kubeflow como una solución de plataforma MLOps todo en uno para"Cuadernos Jupyter" , seguimiento de experimentos, entrenamiento automatizado y canalización de datos, e inferencia.