

Ejemplo de flujo de trabajo: Entrenamiento de un modelo de reconocimiento de imágenes mediante Kubeflow y el kit de herramientas DataOps de NetApp
 Sugerir cambios
Sugerir cambios
Esta sección describe los pasos necesarios para entrenar e implementar una red neuronal para reconocimiento de imágenes utilizando Kubeflow y NetApp DataOps Toolkit. Esto pretende servir como ejemplo para mostrar un trabajo de capacitación que incorpora almacenamiento NetApp .
Prerrequisitos
Cree un Dockerfile con las configuraciones necesarias para utilizar en los pasos de entrenamiento y prueba dentro del pipeline de Kubeflow. Aquí hay un ejemplo de un Dockerfile:
FROM pytorch/pytorch:latest
RUN pip install torchvision numpy scikit-learn matplotlib tensorboard
WORKDIR /app
COPY . /app
COPY train_mnist.py /app/train_mnist.py
CMD ["python", "train_mnist.py"]Dependiendo de sus requisitos, instale todas las bibliotecas y paquetes necesarios para ejecutar el programa. Antes de entrenar el modelo de aprendizaje automático, se supone que ya tienes una implementación de Kubeflow en funcionamiento.
Entrene una red neuronal pequeña con datos MNIST usando PyTorch y Kubeflow Pipelines
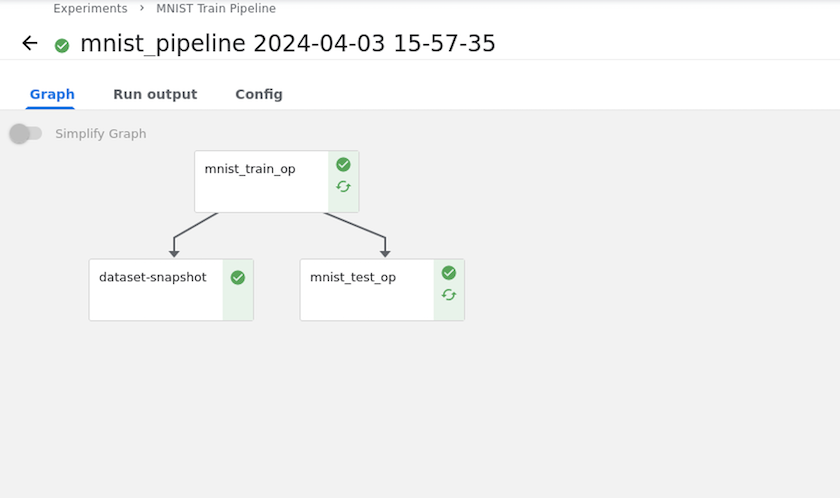
Utilizamos el ejemplo de una pequeña red neuronal entrenada con datos MNIST. El conjunto de datos MNIST consta de imágenes escritas a mano de dígitos del 0 al 9. Las imágenes tienen un tamaño de 28x28 píxeles. El conjunto de datos se divide en 60.000 imágenes de trenes y 10.000 imágenes de validación. La red neuronal utilizada para este experimento es una red de propagación hacia adelante de dos capas. El entrenamiento se ejecuta utilizando Kubeflow Pipelines. Consulte la documentación "aquí" Para más información. Nuestra canalización de Kubeflow incorpora la imagen de Docker de la sección Requisitos previos.
Visualizar resultados con Tensorboard
Una vez entrenado el modelo, podemos visualizar los resultados utilizando Tensorboard. "Tablero tensor" Está disponible como una función en el panel de Kubeflow. Puede crear un tensorboard personalizado para su trabajo. A continuación se muestra un ejemplo de la gráfica de la precisión del entrenamiento frente al número de épocas y de la pérdida de entrenamiento frente al número de épocas.

Experimente con hiperparámetros usando Katib
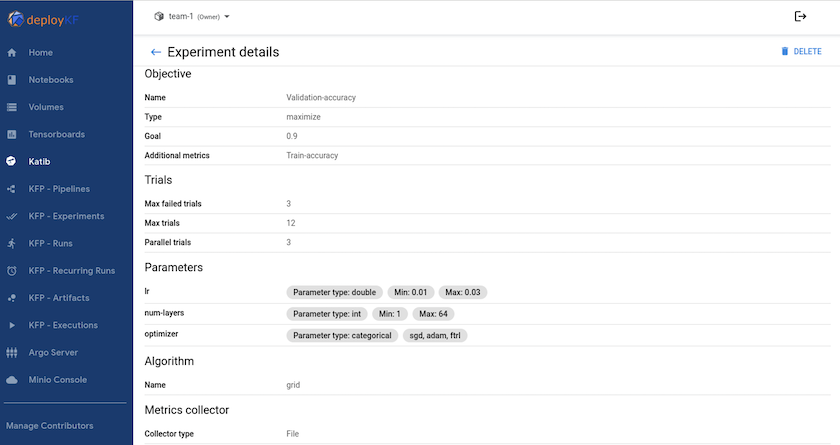
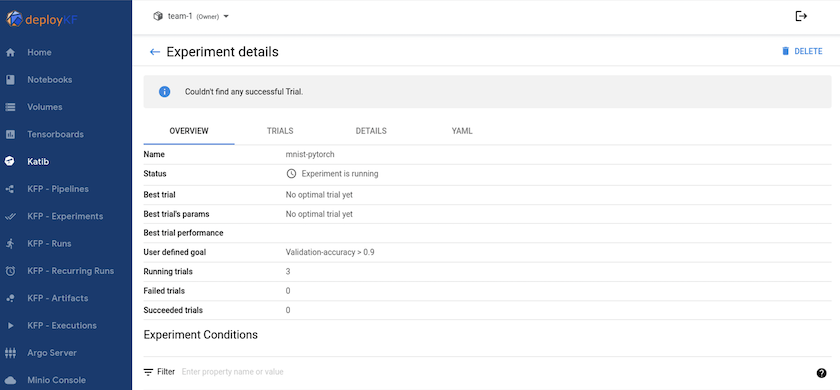
"Katib"es una herramienta dentro de Kubeflow que se puede utilizar para experimentar con los hiperparámetros del modelo. Para crear un experimento, primero defina una métrica/objetivo deseado. Generalmente esta es la precisión de la prueba. Una vez definida la métrica, elija los hiperparámetros con los que desea experimentar (optimizador/tasa de aprendizaje/número de capas). Katib realiza un barrido de hiperparámetros con los valores definidos por el usuario para encontrar la mejor combinación de parámetros que satisfagan la métrica deseada. Puede definir estos parámetros en cada sección de la interfaz de usuario. Alternativamente, podría definir un archivo YAML con las especificaciones necesarias. A continuación se muestra una ilustración de un experimento de Katib:
Utilice instantáneas de NetApp para guardar datos para trazabilidad
Durante el entrenamiento del modelo, es posible que queramos guardar una instantánea del conjunto de datos de entrenamiento para facilitar la trazabilidad. Para ello, podemos agregar un paso de instantánea a la canalización como se muestra a continuación. Para crear la instantánea, podemos utilizar el "Kit de herramientas de NetApp DataOps para Kubernetes" .

Consulte la "Ejemplo de NetApp DataOps Toolkit para Kubeflow" Para más información.