

Base de datos de vectores
 Sugerir cambios
Sugerir cambios
Esta sección cubre la definición y el uso de una base de datos vectorial en las soluciones de IA de NetApp .
Base de datos de vectores
Una base de datos vectorial es un tipo especializado de base de datos diseñada para manejar, indexar y buscar datos no estructurados utilizando incrustaciones de modelos de aprendizaje automático. En lugar de organizar los datos en un formato tabular tradicional, organiza los datos como vectores de alta dimensión, también conocidos como incrustaciones vectoriales. Esta estructura única permite que la base de datos maneje datos complejos y multidimensionales de manera más eficiente y precisa.
Una de las capacidades clave de una base de datos vectorial es el uso de IA generativa para realizar análisis. Esto incluye búsquedas de similitud, donde la base de datos identifica puntos de datos que son similares a una entrada dada, y detección de anomalías, donde puede detectar puntos de datos que se desvían significativamente de la norma.
Además, las bases de datos vectoriales son adecuadas para manejar datos temporales o datos con marca de tiempo. Este tipo de datos proporciona información sobre "qué" sucedió y cuándo sucedió, en secuencia y en relación con todos los demás eventos dentro de un sistema de TI determinado. Esta capacidad de manejar y analizar datos temporales hace que las bases de datos vectoriales sean particularmente útiles para aplicaciones que requieren una comprensión de los eventos a lo largo del tiempo.
Ventajas de las bases de datos vectoriales para ML e IA:
-
Búsqueda de alta dimensión: las bases de datos vectoriales se destacan en la gestión y recuperación de datos de alta dimensión, que a menudo se generan en aplicaciones de IA y ML.
-
Escalabilidad: Pueden escalar de manera eficiente para manejar grandes volúmenes de datos, respaldando el crecimiento y la expansión de proyectos de IA y ML.
-
Flexibilidad: Las bases de datos vectoriales ofrecen un alto grado de flexibilidad, lo que permite la adaptación de diversos tipos y estructuras de datos.
-
Rendimiento: Proporcionan gestión y recuperación de datos de alto rendimiento, fundamentales para la velocidad y la eficiencia de las operaciones de IA y ML.
-
Indexación personalizable: las bases de datos vectoriales ofrecen opciones de indexación personalizables, lo que permite una organización y recuperación optimizadas de datos según necesidades específicas.
Bases de datos vectoriales y casos de uso.
Esta sección proporciona varias bases de datos vectoriales y detalles de sus casos de uso.
Faiss y ScaNN
Son bibliotecas que sirven como herramientas cruciales en el ámbito de la búsqueda vectorial. Estas bibliotecas proporcionan una funcionalidad útil para la gestión y búsqueda de datos vectoriales, lo que las convierte en recursos invaluables en esta área especializada de gestión de datos.
Elasticsearch
Es un motor de búsqueda y análisis ampliamente utilizado, que recientemente ha incorporado capacidades de búsqueda vectorial. Esta nueva característica mejora su funcionalidad, permitiéndole manejar y buscar datos vectoriales de manera más efectiva.
Piña
Es una base de datos vectorial robusta con un conjunto único de características. Admite vectores densos y dispersos en su funcionalidad de indexación, lo que mejora su flexibilidad y adaptabilidad. Una de sus principales fortalezas radica en su capacidad de combinar métodos de búsqueda tradicionales con la búsqueda vectorial densa basada en IA, creando un enfoque de búsqueda híbrido que aprovecha lo mejor de ambos mundos.
Pinecone, basado principalmente en la nube, está diseñado para aplicaciones de aprendizaje automático y se integra bien con una variedad de plataformas, incluidas GCP, AWS, Open AI, GPT-3, GPT-3.5, GPT-4, Catgut Plus, Elasticsearch, Haystack y más. Es importante tener en cuenta que Pinecone es una plataforma de código cerrado y está disponible como una oferta de software como servicio (SaaS).
Dadas sus capacidades avanzadas, Pinecone es particularmente adecuado para la industria de la ciberseguridad, donde sus capacidades de búsqueda de alta dimensión y búsqueda híbrida se pueden aprovechar de manera efectiva para detectar y responder a las amenazas.
Croma
Es una base de datos vectorial que tiene una API central con cuatro funciones principales, una de las cuales incluye un almacén de vectores de documentos en memoria. También utiliza la biblioteca Face Transformers para vectorizar documentos, mejorando su funcionalidad y versatilidad. Chroma está diseñado para operar tanto en la nube como en las instalaciones, ofreciendo flexibilidad según las necesidades del usuario. En particular, se destaca en aplicaciones relacionadas con el audio, lo que lo convierte en una excelente opción para motores de búsqueda basados en audio, sistemas de recomendación de música y otros casos de uso relacionados con el audio.
Tejer
Es una base de datos vectorial versátil que permite a los usuarios vectorizar su contenido utilizando sus módulos integrados o módulos personalizados, proporcionando flexibilidad según necesidades específicas. Ofrece soluciones totalmente administradas y auto hospedadas, que se adaptan a una variedad de preferencias de implementación.
Una de las características clave de Weaviate es su capacidad de almacenar tanto vectores como objetos, mejorando sus capacidades de manejo de datos. Se utiliza ampliamente para una variedad de aplicaciones, incluida la búsqueda semántica y la clasificación de datos en sistemas ERP. En el sector del comercio electrónico, potencia los motores de búsqueda y recomendación. Weaviate también se utiliza para la búsqueda de imágenes, la detección de anomalías, la armonización automatizada de datos y el análisis de amenazas de ciberseguridad, lo que demuestra su versatilidad en múltiples dominios.
Redis
Redis es una base de datos vectorial de alto rendimiento conocida por su rápido almacenamiento en memoria, que ofrece baja latencia para operaciones de lectura y escritura. Esto lo convierte en una excelente opción para sistemas de recomendación, motores de búsqueda y aplicaciones de análisis de datos que requieren un acceso rápido a los datos.
Redis admite varias estructuras de datos para vectores, incluidas listas, conjuntos y conjuntos ordenados. También proporciona operaciones vectoriales como calcular distancias entre vectores o encontrar intersecciones y uniones. Estas características son particularmente útiles para la búsqueda de similitud, la agrupación en clústeres y los sistemas de recomendación basados en contenido.
En términos de escalabilidad y disponibilidad, Redis se destaca en el manejo de cargas de trabajo de alto rendimiento y ofrece replicación de datos. También se integra bien con otros tipos de datos, incluidas las bases de datos relacionales tradicionales (RDBMS). Redis incluye una función de publicación/suscripción (Pub/Sub) para actualizaciones en tiempo real, lo que resulta beneficioso para administrar vectores en tiempo real. Además, Redis es liviano y fácil de usar, lo que lo convierte en una solución fácil de usar para administrar datos vectoriales.
Milvus
Es una base de datos vectorial versátil que ofrece una API como un almacén de documentos, muy parecido a MongoDB. Se destaca por su soporte para una amplia variedad de tipos de datos, lo que lo convierte en una opción popular en los campos de la ciencia de datos y el aprendizaje automático.
Una de las características únicas de Milvus es su capacidad de multivectorización, que permite a los usuarios especificar en tiempo de ejecución el tipo de vector a utilizar para la búsqueda. Además, utiliza Knowwhere, una biblioteca que se encuentra encima de otras bibliotecas como Faiss, para administrar la comunicación entre las consultas y los algoritmos de búsqueda vectorial.
Milvus también ofrece una integración perfecta con los flujos de trabajo de aprendizaje automático, gracias a su compatibilidad con PyTorch y TensorFlow. Esto lo convierte en una herramienta excelente para una variedad de aplicaciones, incluido el comercio electrónico, el análisis de imágenes y videos, el reconocimiento de objetos, la búsqueda de similitud de imágenes y la recuperación de imágenes basada en contenido. En el ámbito del procesamiento del lenguaje natural, Milvus se utiliza para agrupar documentos, buscar semántica y sistemas de preguntas y respuestas.
Para esta solución, elegimos milvus para la validación de la solución. Para el rendimiento, utilizamos tanto milvus como postgres(pgvecto.rs).
¿Por qué elegimos milvus para esta solución?
-
Código abierto: Milvus es una base de datos vectorial de código abierto que fomenta el desarrollo y las mejoras impulsados por la comunidad.
-
Integración de IA: aprovecha la incorporación de aplicaciones de IA y búsqueda de similitud para mejorar la funcionalidad de la base de datos vectorial.
-
Manejo de grandes volúmenes: Milvus tiene la capacidad de almacenar, indexar y administrar más de mil millones de vectores de incrustación generados por redes neuronales profundas (DNN) y modelos de aprendizaje automático (ML).
-
Fácil de usar: es fácil de usar y la configuración toma menos de un minuto. Milvus también ofrece SDK para diferentes lenguajes de programación.
-
Velocidad: Ofrece velocidades de recuperación increíblemente rápidas, hasta 10 veces más rápidas que algunas alternativas.
-
Escalabilidad y disponibilidad: Milvus es altamente escalable, con opciones para escalar verticalmente o horizontalmente según sea necesario.
-
Rica en funciones: admite diferentes tipos de datos, filtrado de atributos, compatibilidad con funciones definidas por el usuario (UDF), niveles de consistencia configurables y tiempo de viaje, lo que la convierte en una herramienta versátil para diversas aplicaciones.
Descripción general de la arquitectura de Milvus
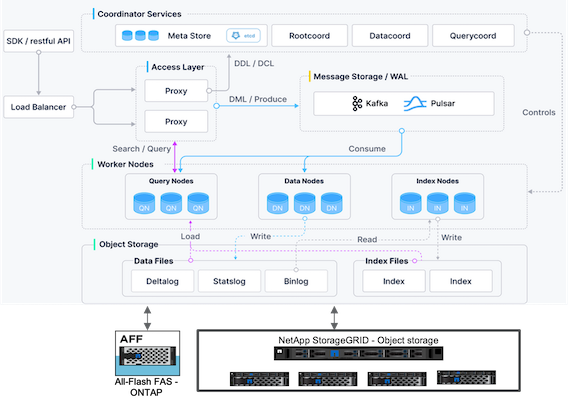
Esta sección proporciona componentes y servicios de nivel superior que se utilizan en la arquitectura Milvus. * Capa de acceso: está compuesta por un grupo de servidores proxy sin estado y actúa como capa frontal del sistema y punto final para los usuarios. * Servicio de coordinación: asigna las tareas a los nodos de trabajo y actúa como el cerebro del sistema. Tiene tres tipos de coordinador: coordenada raíz, coordenada de datos y coordenada de consulta. * Nodos de trabajo: siguen las instrucciones del servicio coordinador y ejecutan comandos DML/DDL activados por el usuario. Tiene tres tipos de nodos de trabajo: el nodo de consulta, el nodo de datos y el nodo de índice. * Almacenamiento: es responsable de la persistencia de los datos. Incluye almacenamiento de metadatos, agente de registros y almacenamiento de objetos. El almacenamiento de NetApp , como ONTAP y StorageGRID, proporciona almacenamiento de objetos y almacenamiento basado en archivos a Milvus tanto para datos de clientes como para datos de bases de datos vectoriales.