

Casos de uso de bases de datos vectoriales
 Sugerir cambios
Sugerir cambios
Esta sección proporciona una descripción general de los casos de uso de la solución de base de datos vectorial de NetApp .
Casos de uso de bases de datos vectoriales
En esta sección, analizamos dos casos de uso, como la recuperación de generación aumentada con modelos de lenguaje grandes y el chatbot de TI de NetApp .
Generación aumentada de recuperación (RAG) con modelos de lenguaje grandes (LLM)
Retrieval-augmented generation, or RAG, is a technique for enhancing the accuracy and reliability of Large Language Models, or LLMs, by augmenting prompts with facts fetched from external sources. In a traditional RAG deployment, vector embeddings are generated from an existing dataset and then stored in a vector database, often referred to as a knowledgebase. Whenever a user submits a prompt to the LLM, a vector embedding representation of the prompt is generated, and the vector database is searched using that embedding as the search query. This search operation returns similar vectors from the knowledgebase, which are then fed to the LLM as context alongside the original user prompt. In this way, an LLM can be augmented with additional information that was not part of its original training dataset.
El operador NVIDIA Enterprise RAG LLM es una herramienta útil para implementar RAG en la empresa. Este operador se puede utilizar para implementar un pipeline RAG completo. La tubería RAG se puede personalizar para utilizar Milvus o pgvecto como base de datos vectorial para almacenar incrustaciones de la base de conocimientos. Consulte la documentación para obtener más detalles.
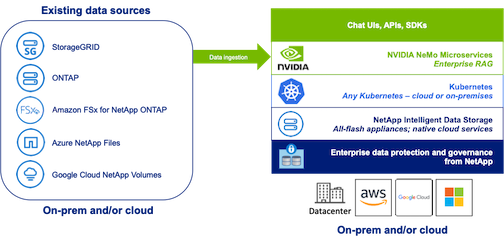
NetApp has validated an enterprise RAG architecture powered by the NVIDIA Enterprise RAG LLM Operator alongside NetApp storage. Refer to our blog post for more information and to see a demo. Figure 1 provides an overview of this architecture.
Figura 1) RAG empresarial impulsado por NVIDIA NeMo Microservices y NetApp
Caso de uso del chatbot de TI de NetApp
El chatbot de NetApp sirve como otro caso de uso en tiempo real para la base de datos vectorial. En este caso, NetApp Private OpenAI Sandbox proporciona una plataforma eficaz, segura y eficiente para gestionar las consultas de los usuarios internos de NetApp. Al incorporar estrictos protocolos de seguridad, sistemas eficientes de gestión de datos y sofisticadas capacidades de procesamiento de IA, garantiza respuestas precisas y de alta calidad a los usuarios en función de sus roles y responsabilidades en la organización a través de la autenticación SSO. Esta arquitectura resalta el potencial de fusionar tecnologías avanzadas para crear sistemas inteligentes centrados en el usuario.
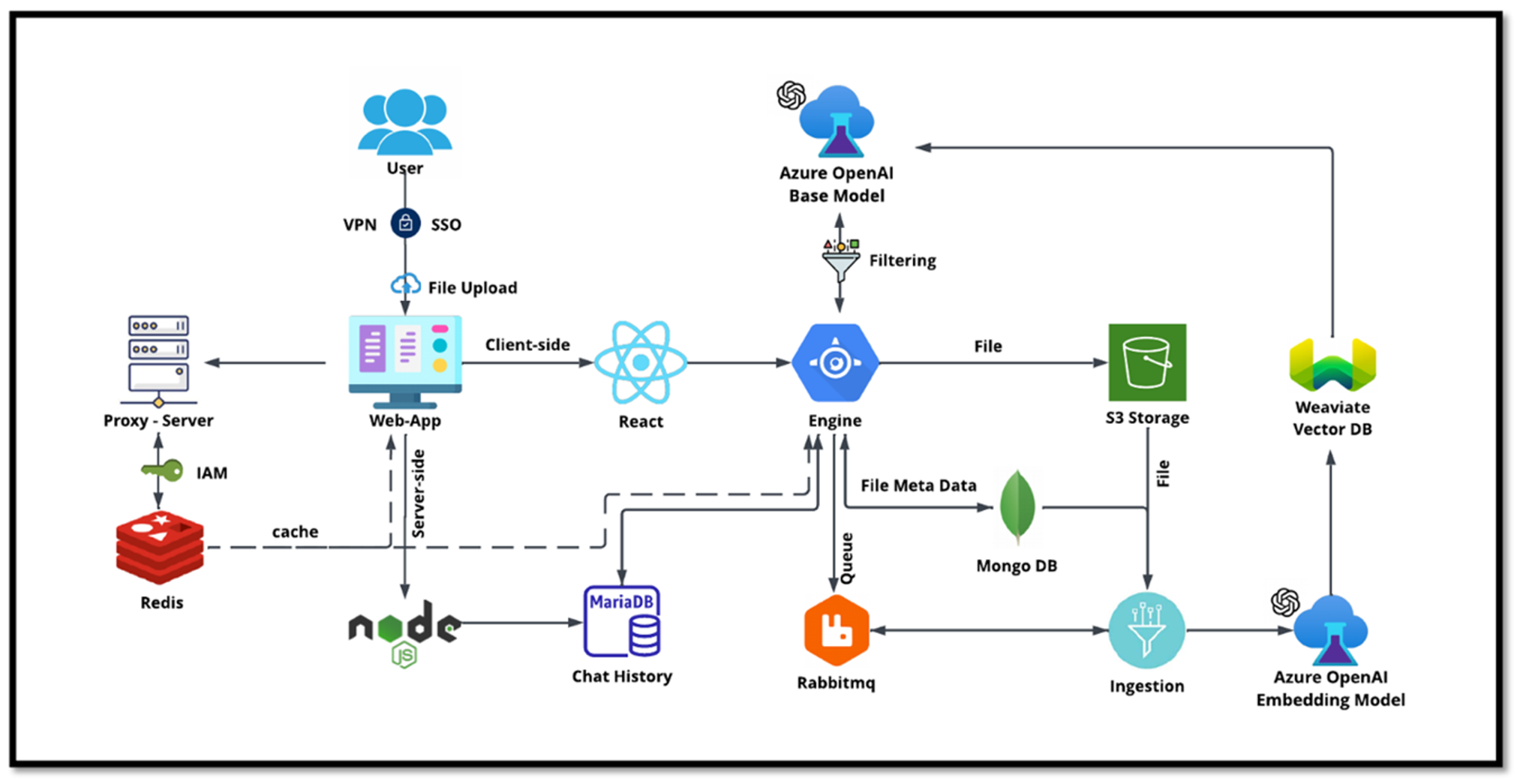
El caso de uso se puede dividir en cuatro secciones principales.
Autenticación y verificación de usuarios:
-
Las consultas de usuario primero pasan por el proceso de inicio de sesión único (SSO) de NetApp para confirmar la identidad del usuario.
-
Después de una autenticación exitosa, el sistema verifica la conexión VPN para garantizar una transmisión de datos segura.
Transmisión y procesamiento de datos:
-
Una vez validada la VPN, los datos se envían a MariaDB a través de las aplicaciones web NetAIChat o NetAICreate. MariaDB es un sistema de base de datos rápido y eficiente utilizado para administrar y almacenar datos de usuarios.
-
Luego, MariaDB envía la información a la instancia de Azure de NetApp , que conecta los datos del usuario con la unidad de procesamiento de IA.
Interacción con OpenAI y filtrado de contenido:
-
La instancia de Azure envía las preguntas del usuario a un sistema de filtrado de contenido. Este sistema limpia la consulta y la prepara para su procesamiento.
-
Luego, la entrada limpiada se envía al modelo base de Azure OpenAI, que genera una respuesta basada en la entrada.
Generación y moderación de respuestas:
-
Primero se verifica la respuesta del modelo base para garantizar que sea precisa y cumpla con los estándares de contenido.
-
Después de pasar la verificación, la respuesta se envía de vuelta al usuario. Este proceso garantiza que el usuario reciba una respuesta clara, precisa y adecuada a su consulta.