

Flujo de trabajo de recuperación ante desastres
 Sugerir cambios
Sugerir cambios
Las empresas han adoptado la nube pública como un recurso viable y un destino para la recuperación ante desastres. SnapCenter hace que este proceso sea lo más sencillo posible. Este flujo de trabajo de recuperación ante desastres es muy similar al flujo de trabajo de clonación, pero la recuperación de la base de datos se ejecuta a través del último registro disponible que se replicó en la nube para recuperar todas las transacciones comerciales posibles. Sin embargo, existen pasos adicionales de preconfiguración y posconfiguración específicos para la recuperación ante desastres.
Clonar una base de datos de producción Oracle local a la nube para recuperación ante desastres
-
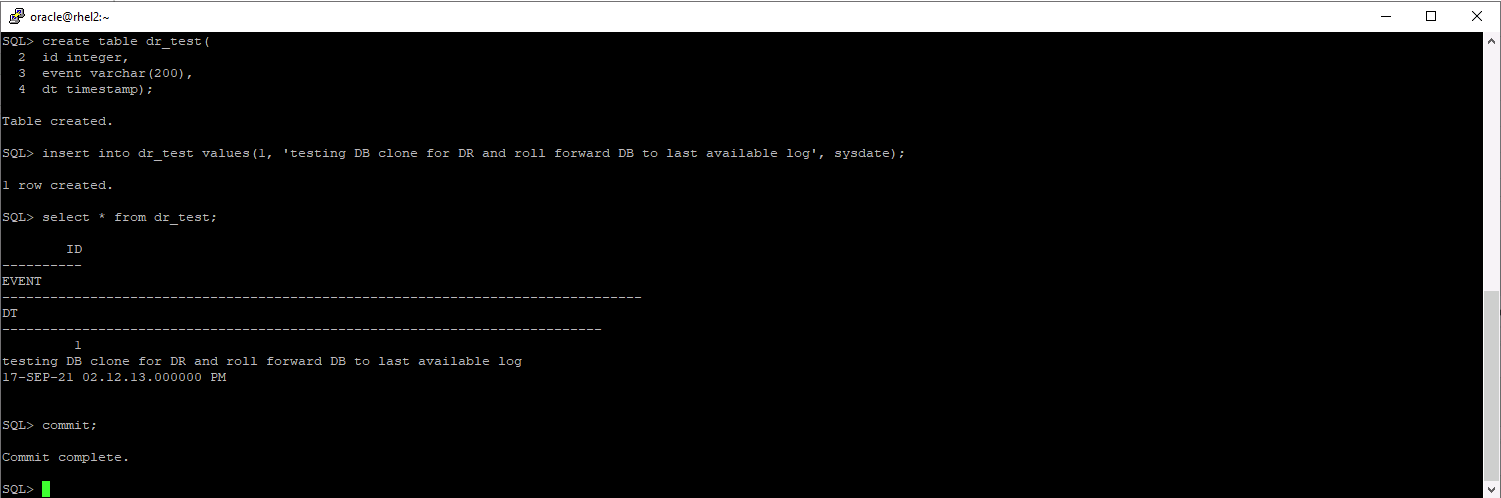
Para validar que la recuperación del clon se ejecute a través del último registro disponible, creamos una pequeña tabla de prueba e insertamos una fila. Los datos de prueba se recuperarían después de una recuperación completa al último registro disponible.
-
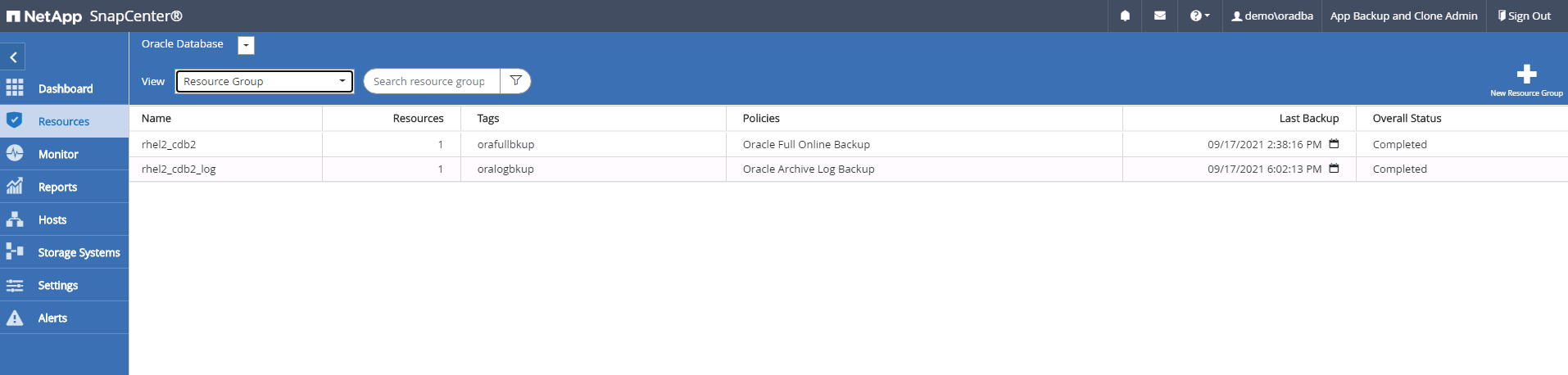
Inicie sesión en SnapCenter como un ID de usuario de administración de base de datos para Oracle. Vaya a la pestaña Recursos, que muestra las bases de datos de Oracle que están protegidas por SnapCenter.
-
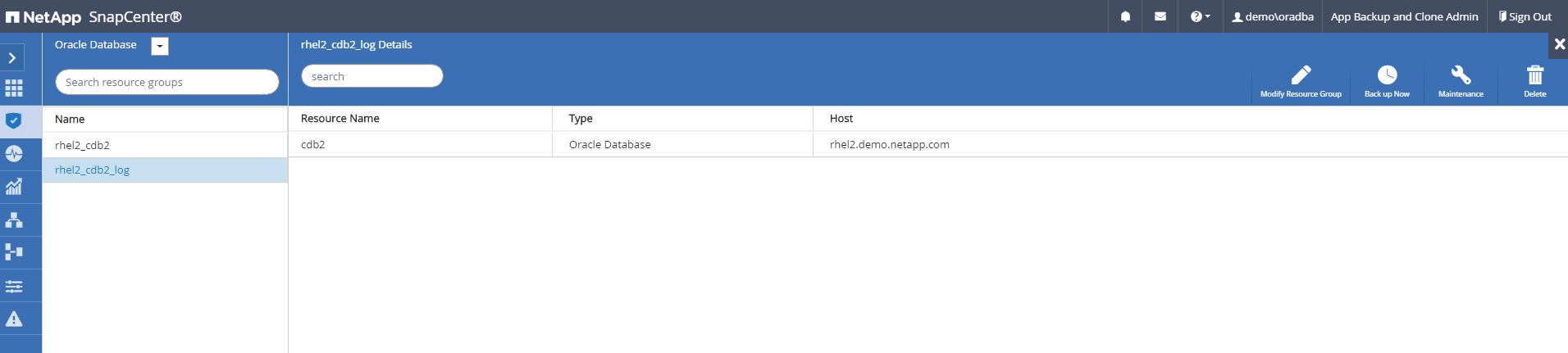
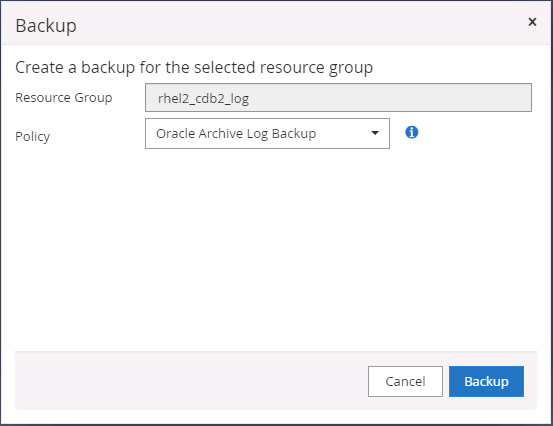
Seleccione el grupo de recursos de registro de Oracle y haga clic en Realizar copia de seguridad ahora para ejecutar manualmente una copia de seguridad del registro de Oracle para vaciar la última transacción en el destino en la nube. En un escenario de DR real, la última transacción recuperable depende de la frecuencia de replicación del volumen del registro de la base de datos a la nube, que a su vez depende de la política de RTO o RPO de la empresa.

SnapMirror asincrónico pierde datos que no llegaron al destino en la nube en el intervalo de respaldo del registro de la base de datos en un escenario de recuperación ante desastres. Para minimizar la pérdida de datos, se pueden programar copias de seguridad de registros más frecuentes. Sin embargo, existe un límite en la frecuencia de las copias de seguridad de registros que es técnicamente alcanzable. -
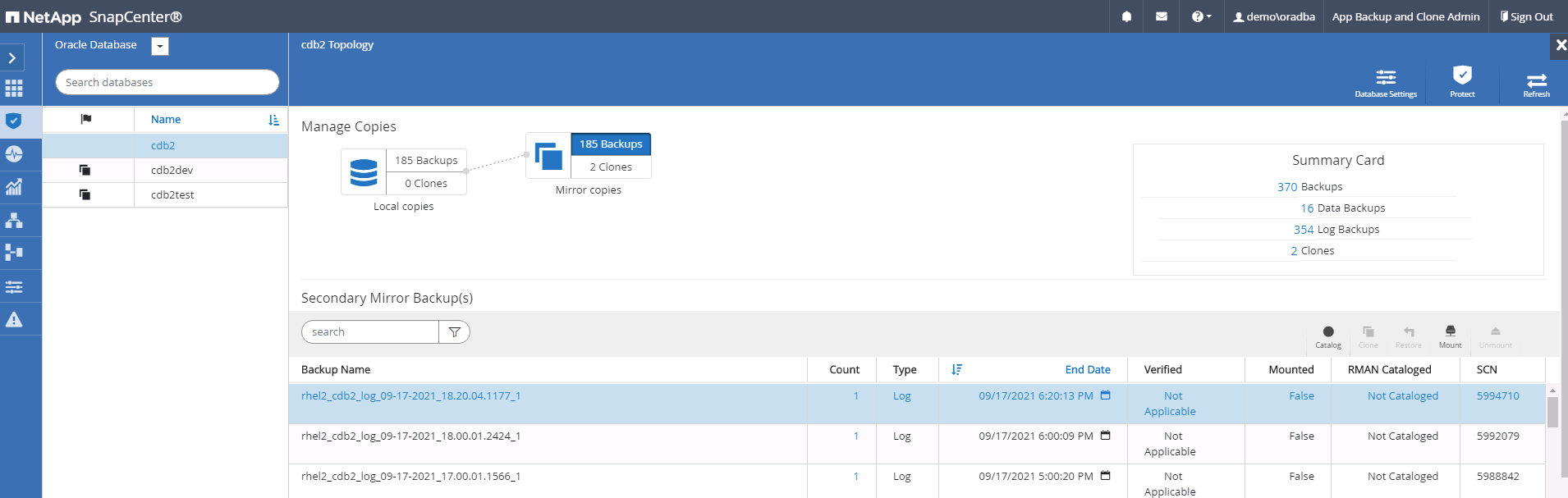
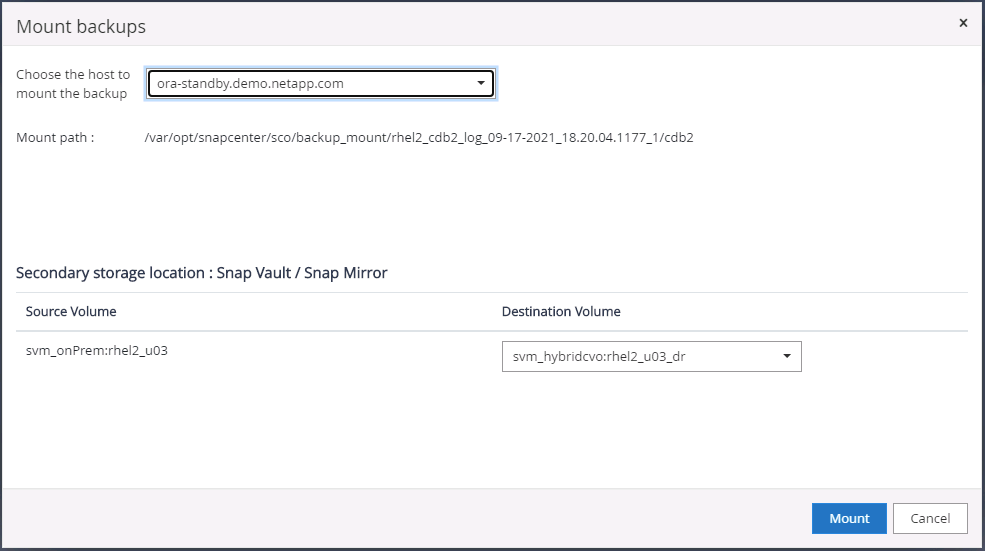
Seleccione la última copia de seguridad del registro en las copias de seguridad del espejo secundario y monte la copia de seguridad del registro.
-
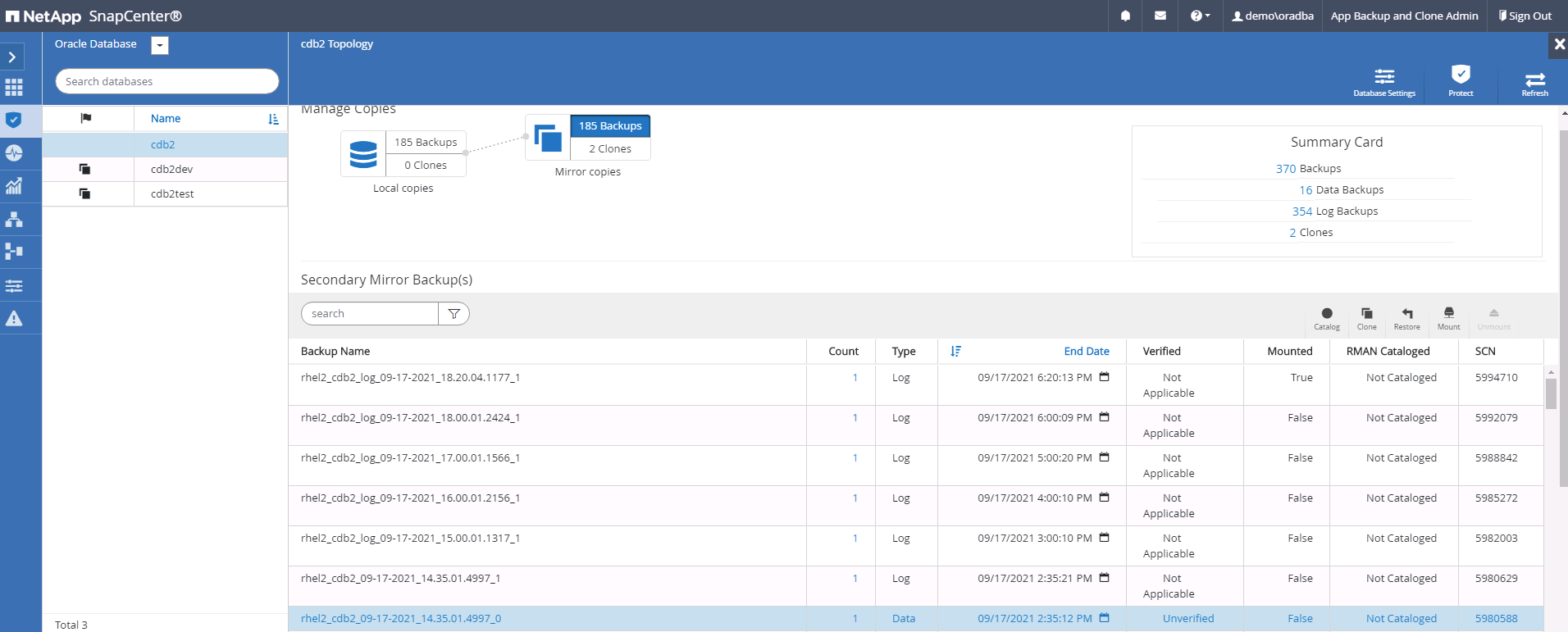
Seleccione la última copia de seguridad completa de la base de datos y haga clic en Clonar para iniciar el flujo de trabajo de clonación.
-
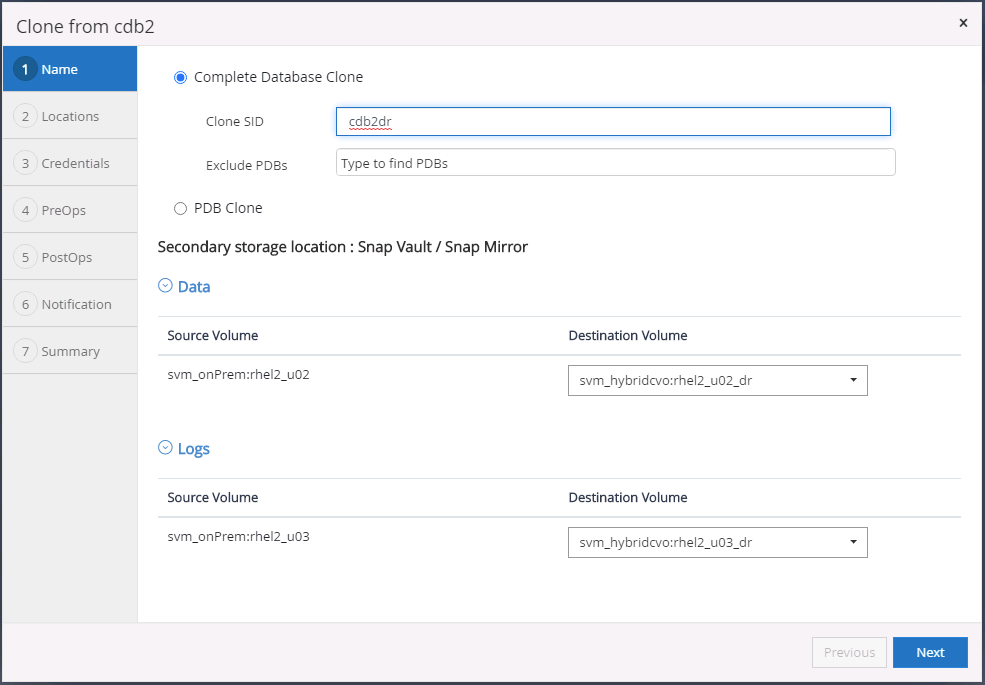
Seleccione un ID de base de datos clonada único en el host.
-
Aprovisione un volumen de registro y móntelo en el servidor DR de destino para el área de recuperación flash de Oracle y los registros en línea.
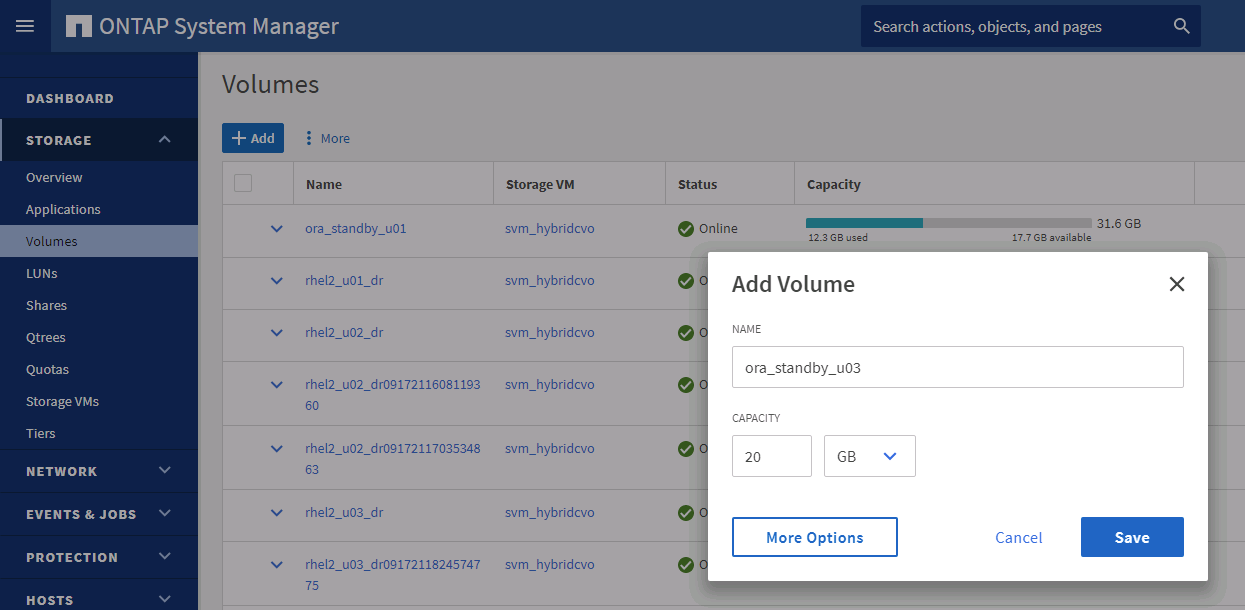
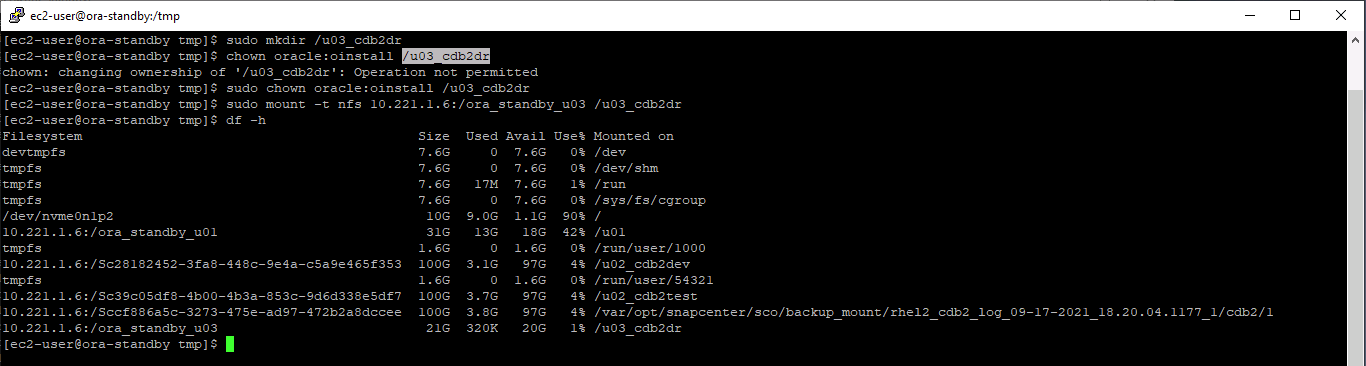
El procedimiento de clonación de Oracle no crea un volumen de registro, que debe aprovisionarse en el servidor DR antes de la clonación. -
Seleccione el host de clonación de destino y la ubicación para colocar los archivos de datos, los archivos de control y los registros de rehacer.
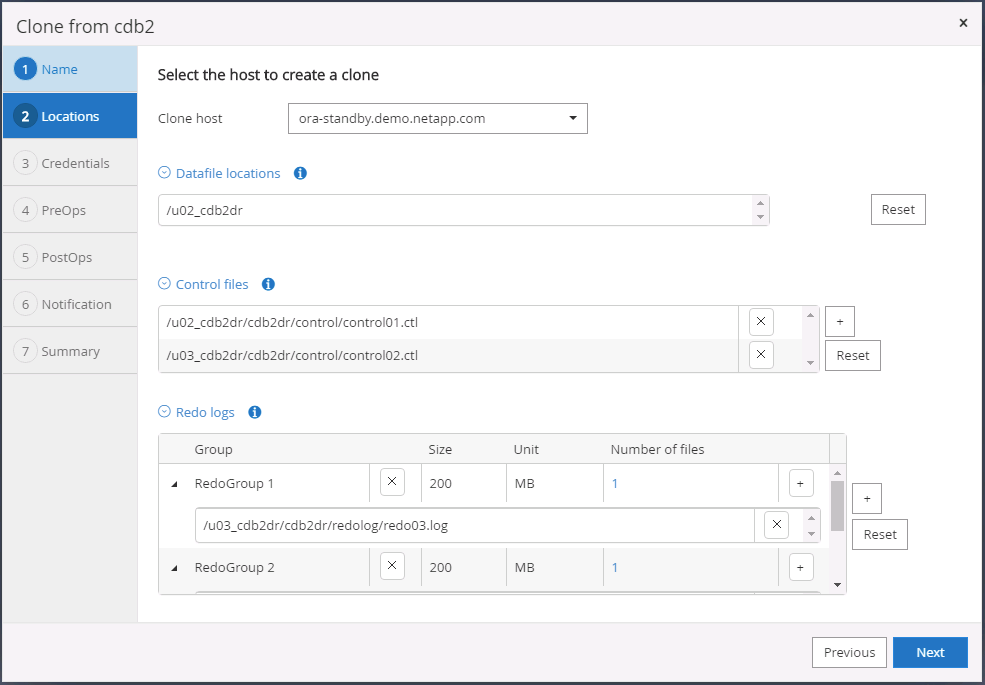
-
Seleccione las credenciales para el clon. Complete los detalles de la configuración de inicio de Oracle en el servidor de destino.
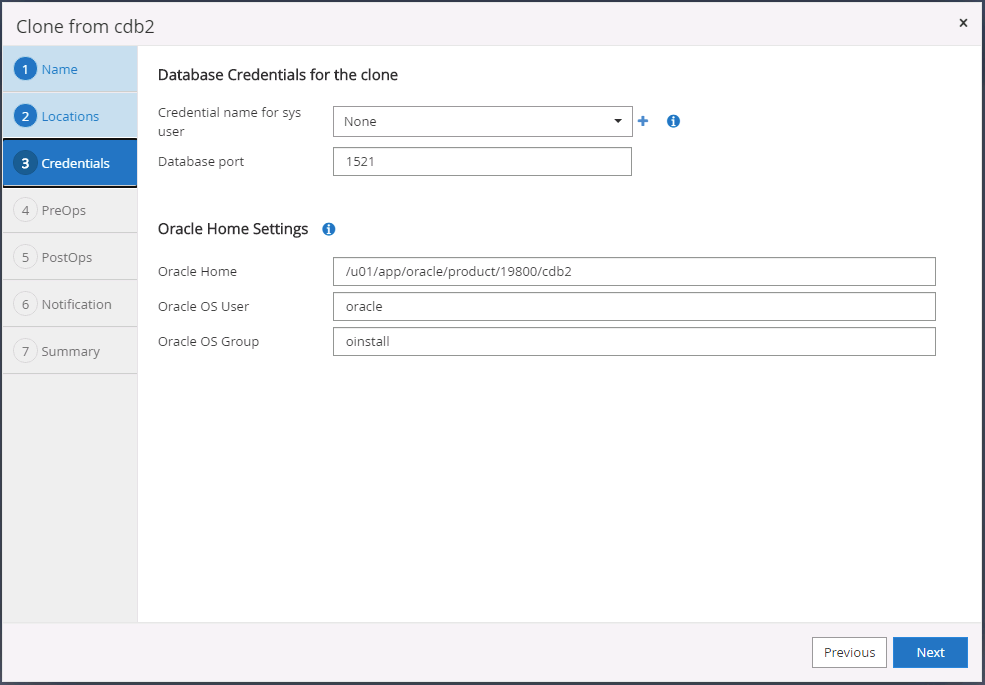
-
Especifique los scripts que se ejecutarán antes de la clonación. Los parámetros de la base de datos se pueden ajustar si es necesario.
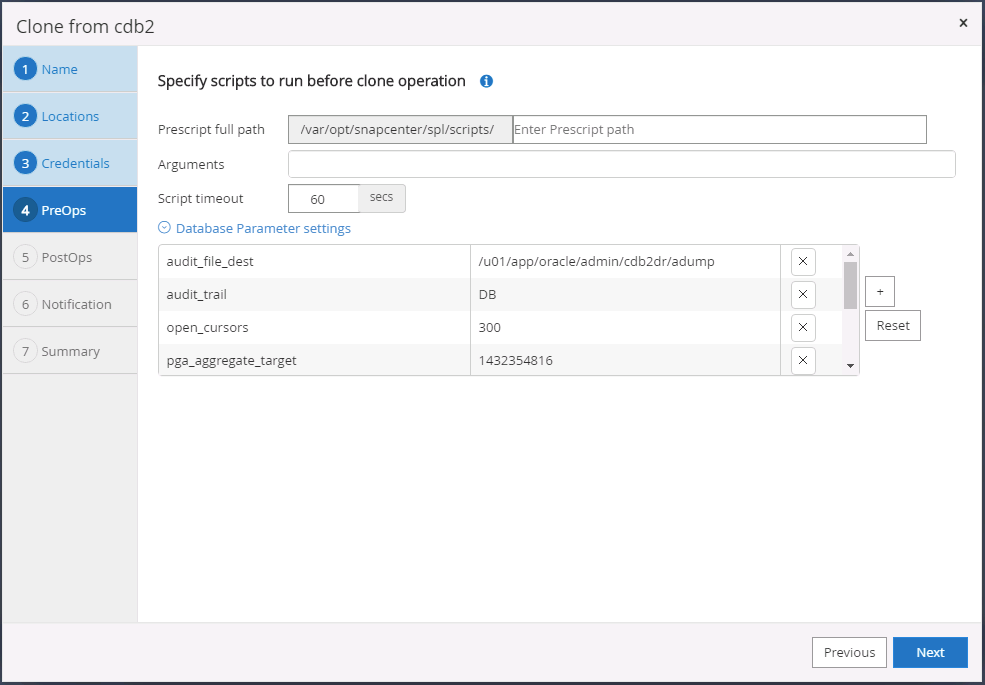
-
Seleccione Hasta cancelar como la opción de recuperación para que la recuperación se ejecute en todos los registros de archivo disponibles para recuperar la última transacción replicada en la ubicación de la nube secundaria.
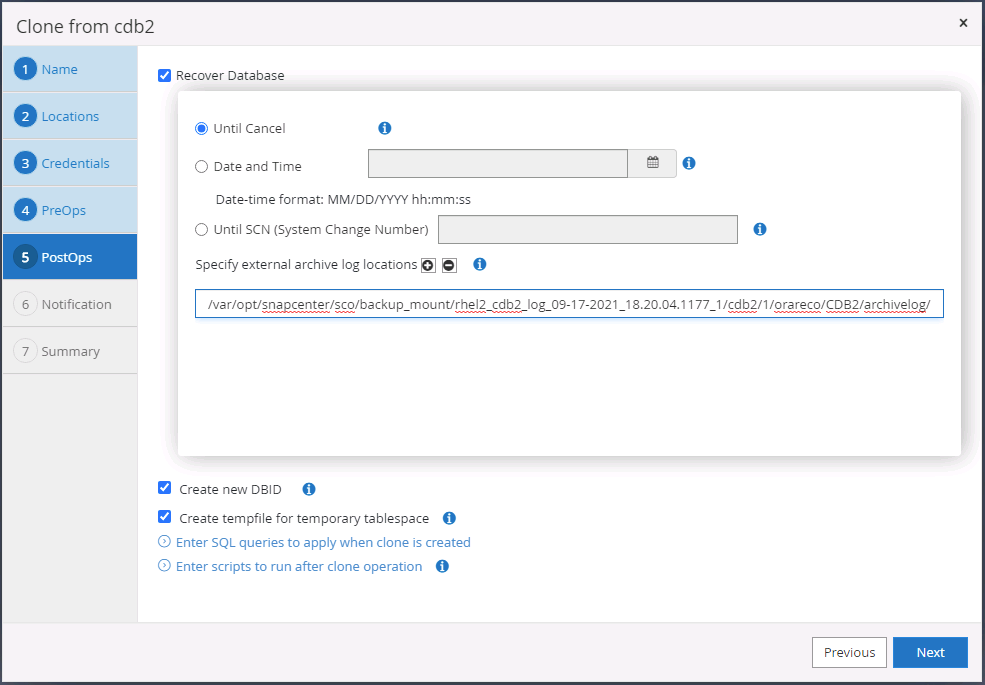
-
Configure el servidor SMTP para notificaciones por correo electrónico si es necesario.
-
Resumen del clon DR.
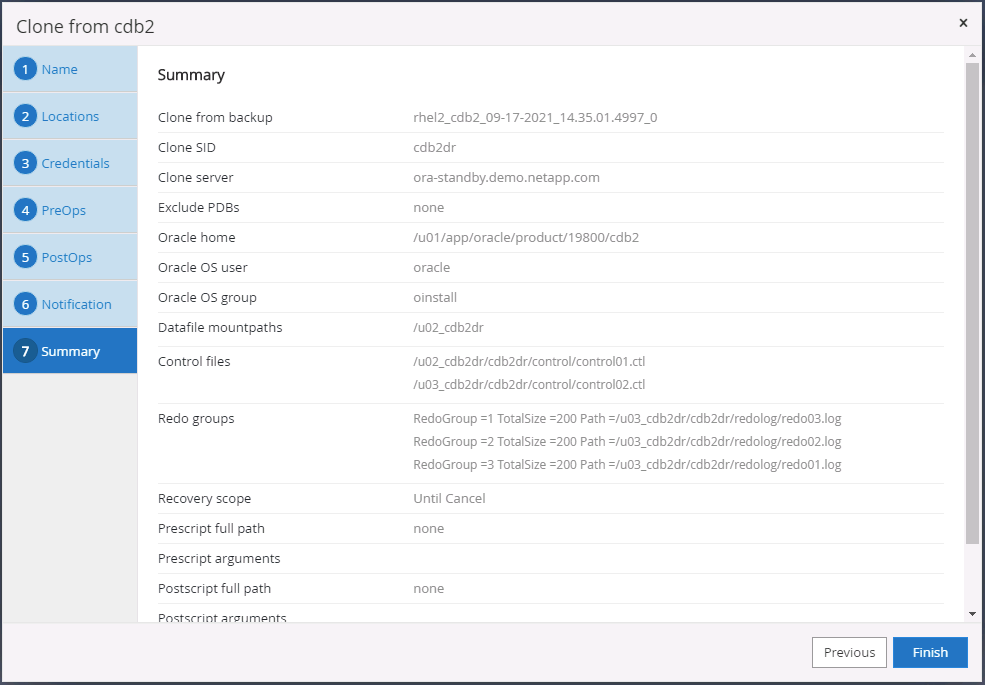
-
Las bases de datos clonadas se registran en SnapCenter inmediatamente después de completarse la clonación y luego están disponibles para protección de respaldo.
Validación y configuración posterior a la clonación DR para Oracle
-
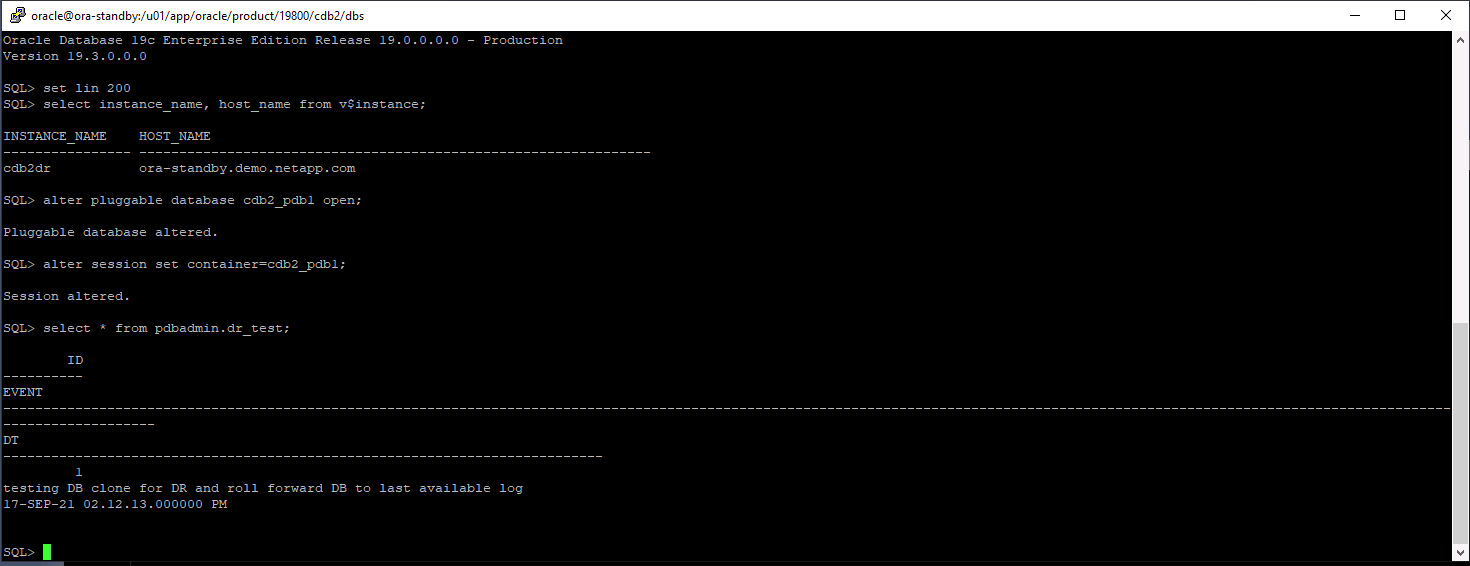
Valide la última transacción de prueba que se ha vaciado, replicado y recuperado en la ubicación de recuperación ante desastres en la nube.
-
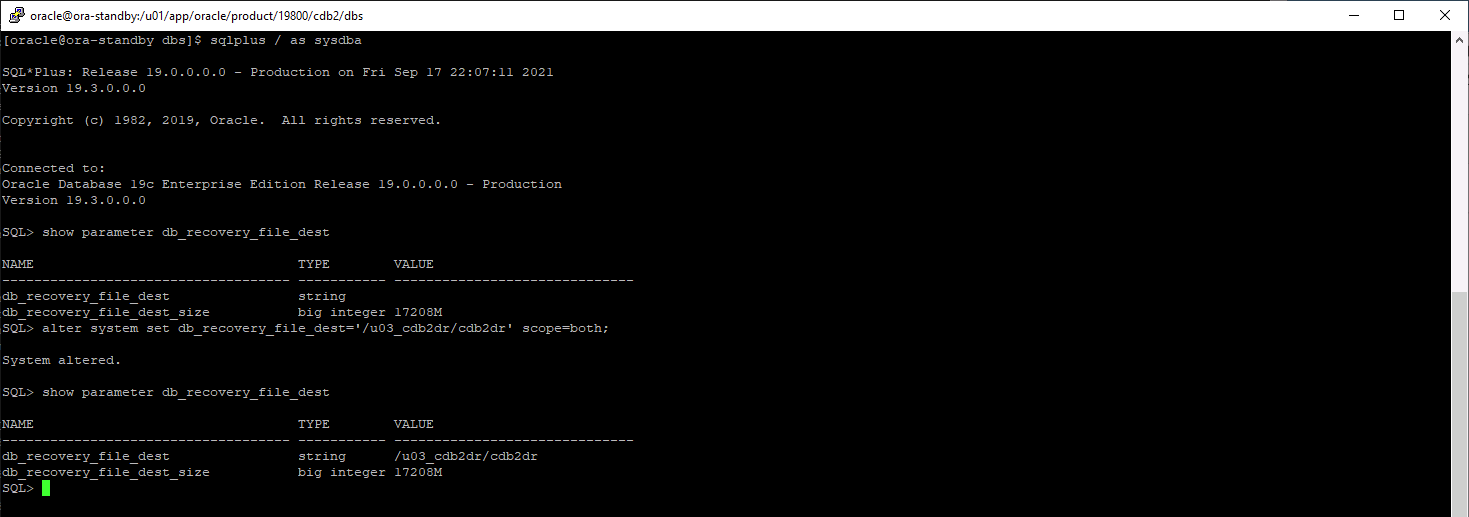
Configurar el área de recuperación flash.
-
Configure el escucha de Oracle para el acceso de usuarios.
-
Divida el volumen clonado del volumen de origen replicado.
-
Replicación inversa de la nube a las instalaciones locales y reconstrucción del servidor de base de datos local fallido.
|
|
La división de clones puede generar un uso de espacio de almacenamiento temporal mucho mayor que el funcionamiento normal. Sin embargo, una vez reconstruido el servidor de base de datos local, se puede liberar espacio adicional. |
Clonar una base de datos de producción SQL local a la nube para recuperación ante desastres
-
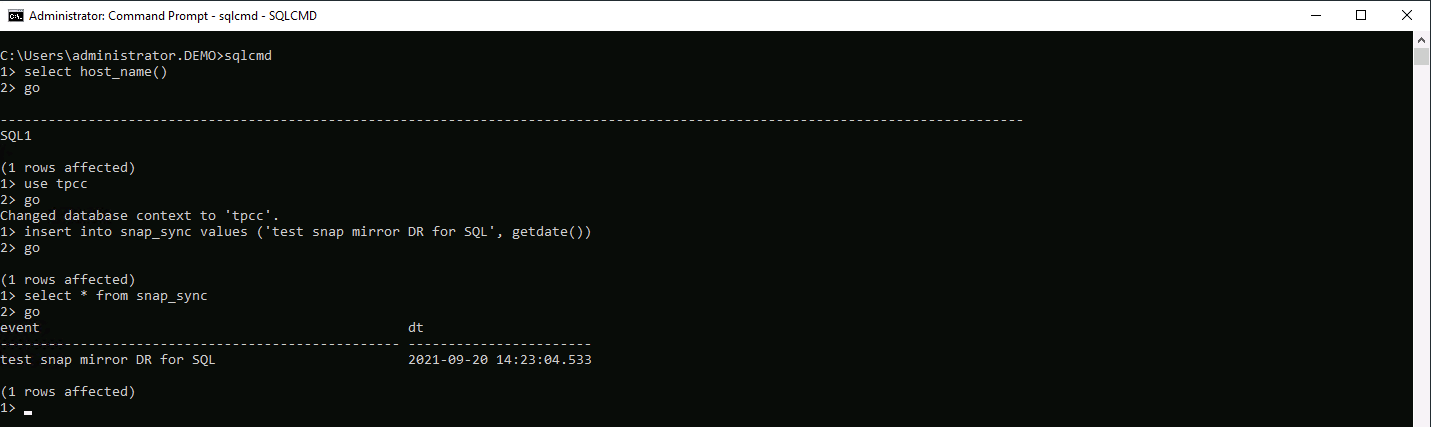
De manera similar, para validar que la recuperación del clon SQL se ejecutó a través del último registro disponible, creamos una pequeña tabla de prueba e insertamos una fila. Los datos de prueba se recuperarían después de una recuperación completa al último registro disponible.
-
Inicie sesión en SnapCenter con un ID de usuario de administración de base de datos para SQL Server. Vaya a la pestaña Recursos, que muestra el grupo de recursos de protección de SQL Server.

-
Ejecute manualmente una copia de seguridad del registro para borrar la última transacción que se replicará en el almacenamiento secundario en la nube pública.
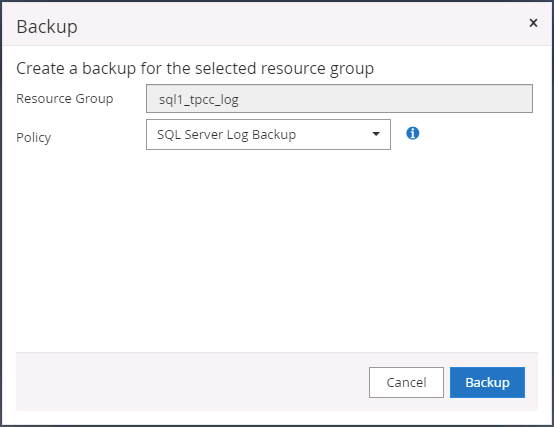
-
Seleccione la última copia de seguridad completa de SQL Server para el clon.
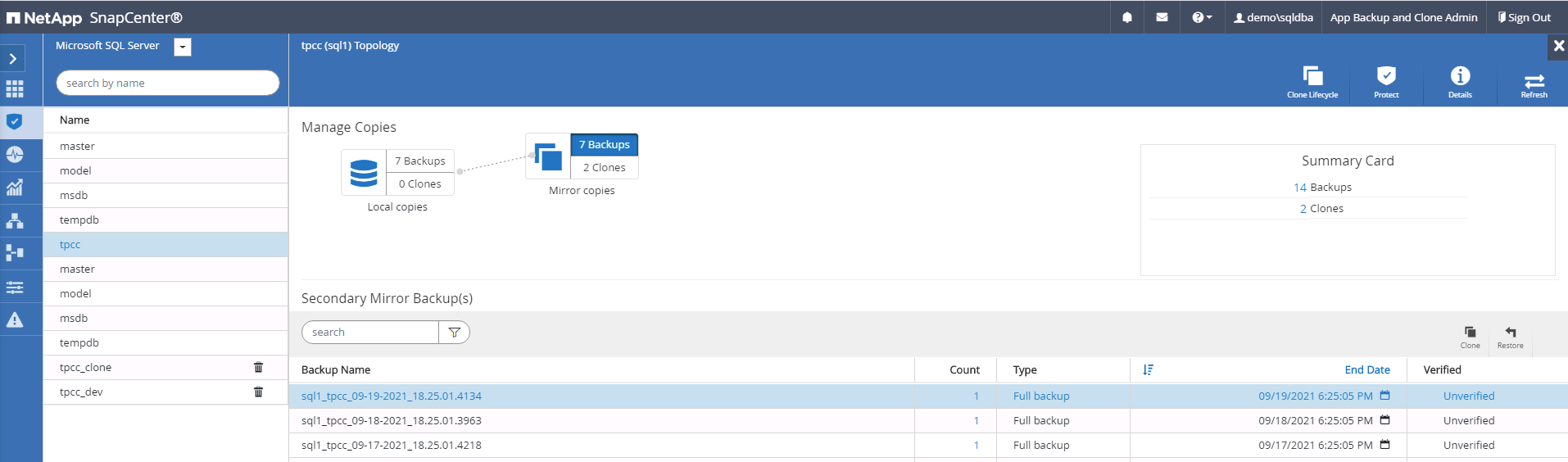
-
Establezca la configuración de clonación, como el servidor de clonación, la instancia de clonación, el nombre de clonación y la opción de montaje. La ubicación de almacenamiento secundaria donde se realiza la clonación se completa automáticamente.
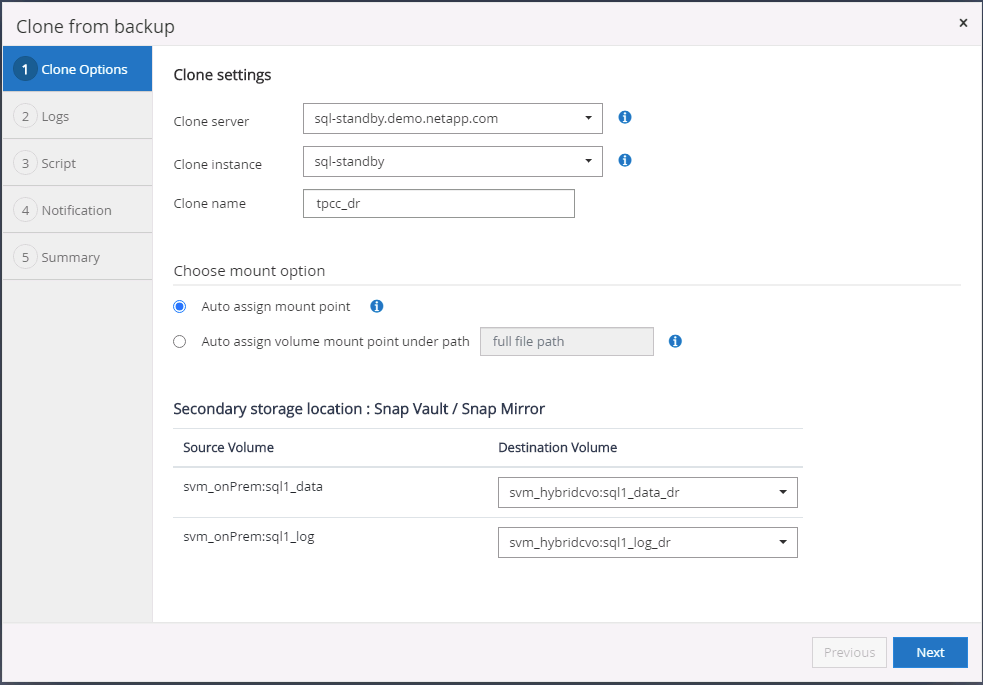
-
Seleccione todas las copias de seguridad de registros que se aplicarán.
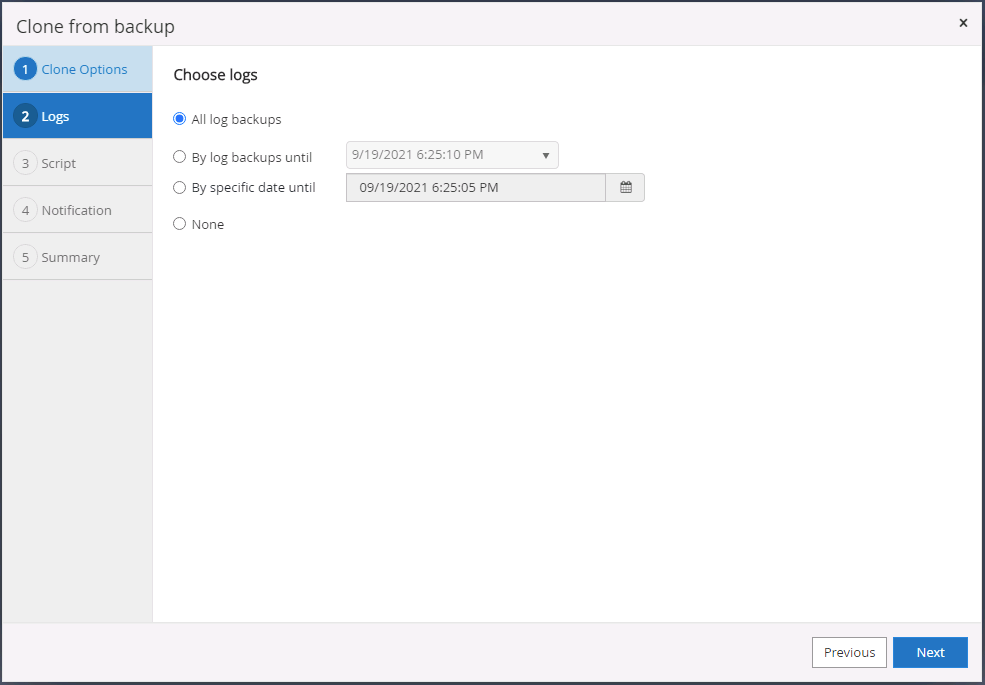
-
Especifique cualquier script opcional para ejecutar antes o después de la clonación.
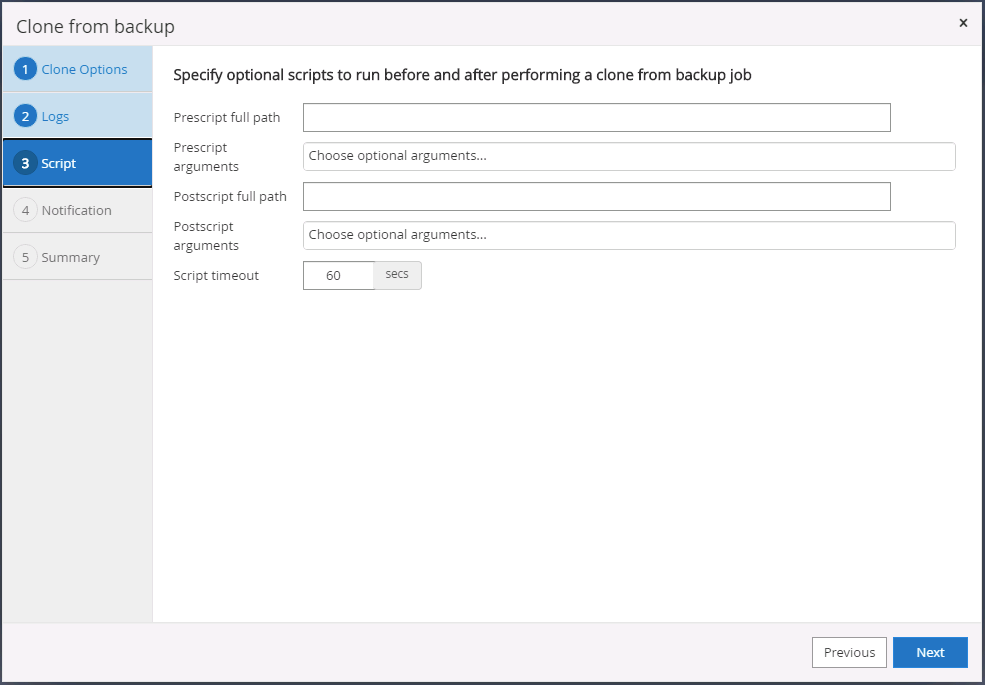
-
Especifique un servidor SMTP si desea recibir notificaciones por correo electrónico.
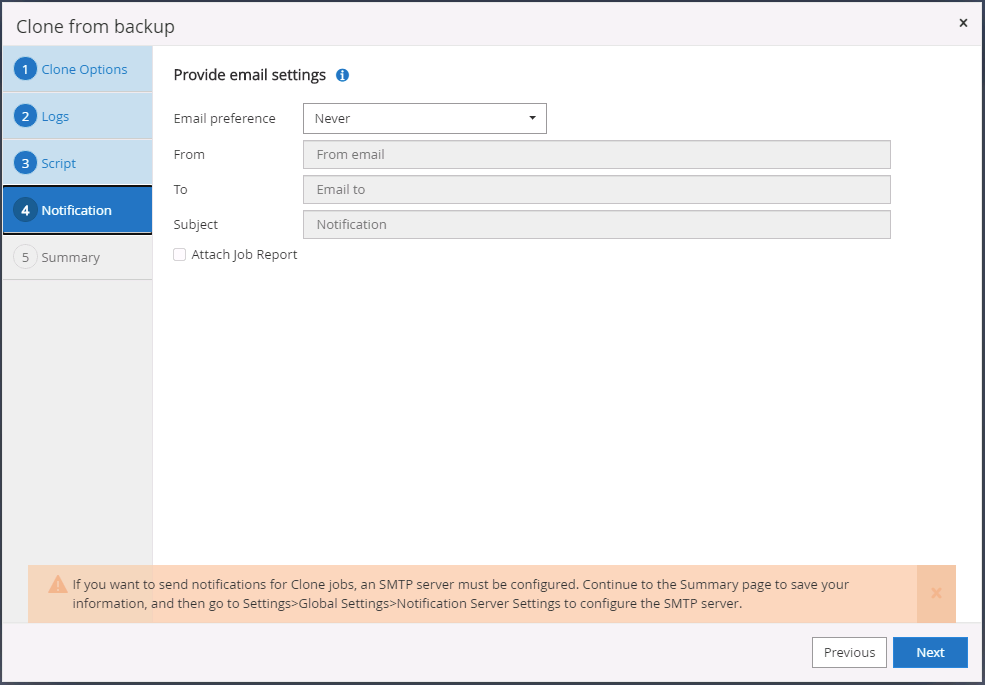
-
Resumen del clon DR. Las bases de datos clonadas se registran inmediatamente en SnapCenter y están disponibles para protección de respaldo.
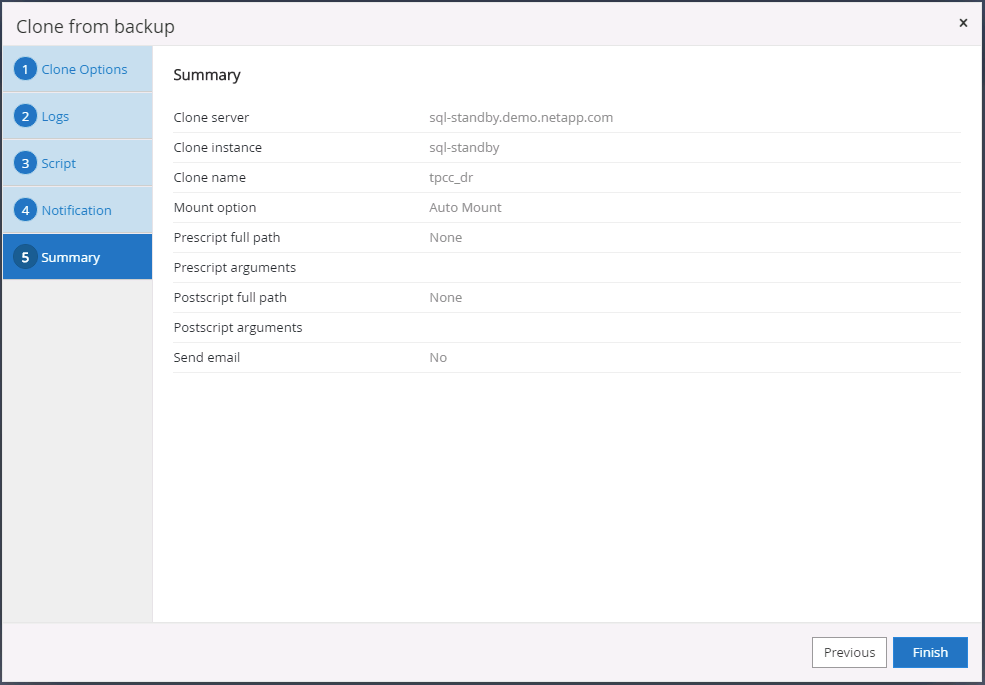
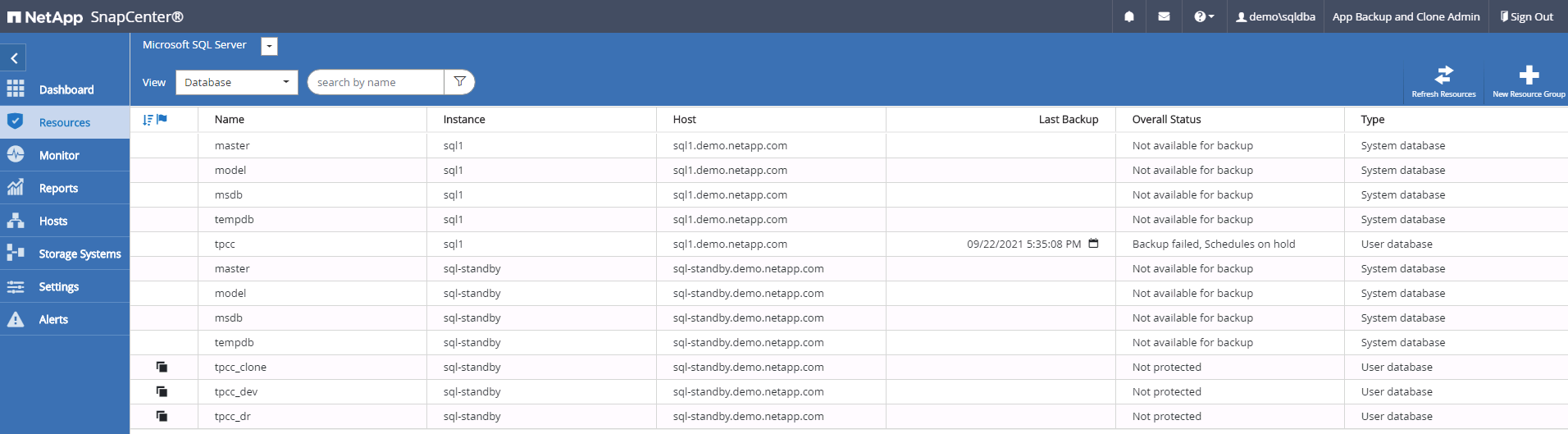
Validación y configuración posterior a la clonación DR para SQL
-
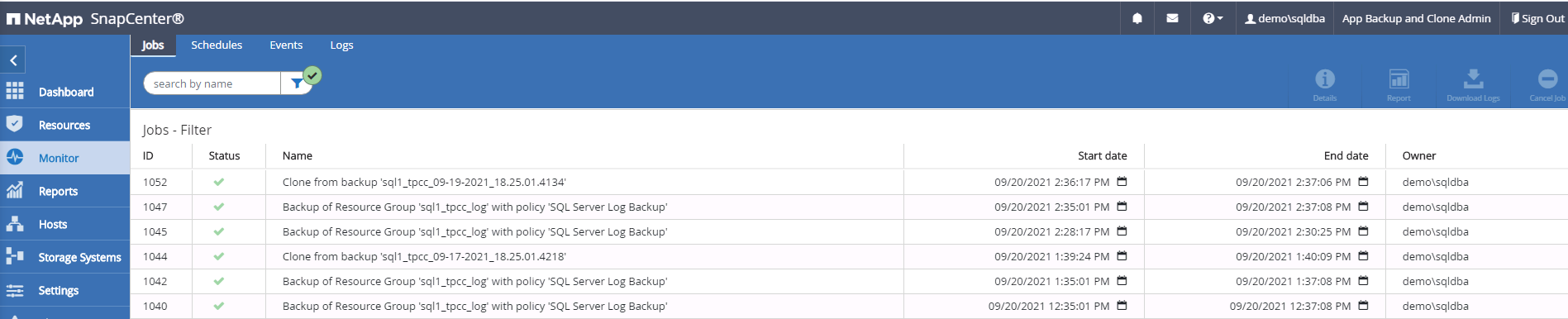
Supervisar el estado del trabajo de clonación.
-
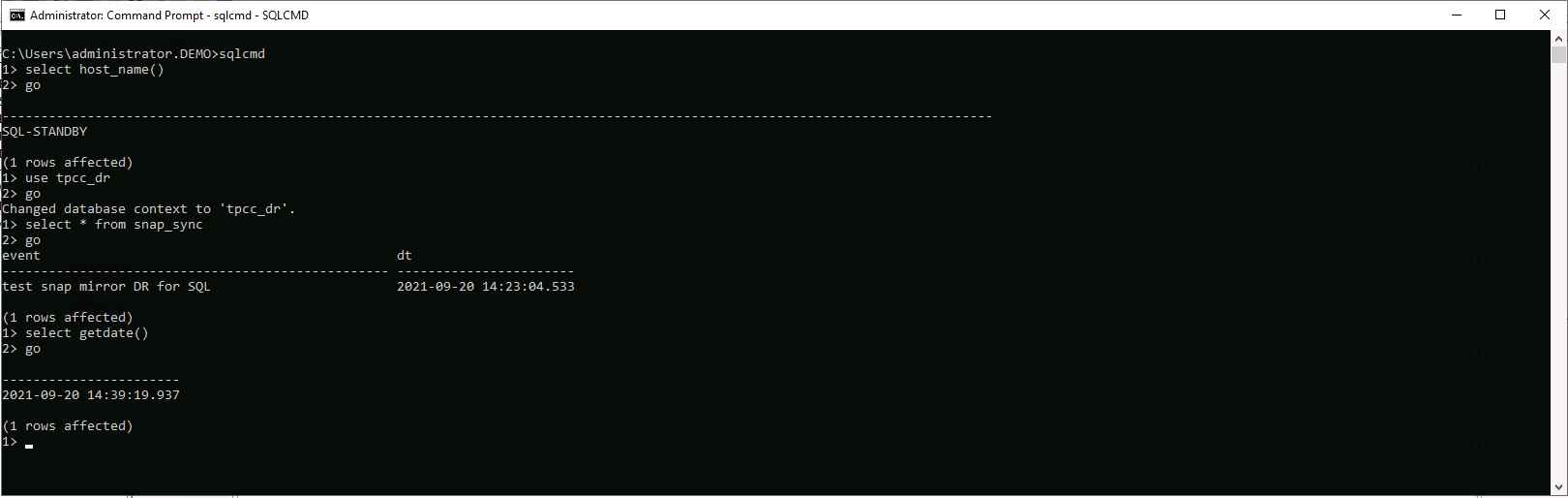
Validar que la última transacción se haya replicado y recuperado con todos los clones y la recuperación de archivos de registro.
-
Configure un nuevo directorio de registro de SnapCenter en el servidor DR para la copia de seguridad del registro de SQL Server.
-
Divida el volumen clonado del volumen de origen replicado.
-
Replicación inversa de la nube a las instalaciones locales y reconstrucción del servidor de base de datos local fallido.
¿A dónde acudir para obtener ayuda?
Si necesita ayuda con esta solución y casos de uso, únase a la"Canal de Slack de soporte de la comunidad de automatización de soluciones de NetApp" y busca el canal de automatización de soluciones para publicar tus dudas o consultas.