

TR-4998: Oracle HA en AWS EC2 con Pacemaker Clustering y FSx ONTAP
 Sugerir cambios
Sugerir cambios
Allen Cao, Niyaz Mohamed, NetApp
Esta solución proporciona una descripción general y detalles para habilitar la alta disponibilidad (HA) de Oracle en AWS EC2 con agrupación en clústeres Pacemaker en Redhat Enterprise Linux (RHEL) y Amazon FSx ONTAP para la alta disponibilidad (HA) de almacenamiento de bases de datos a través del protocolo NFS.
Objetivo
Muchos clientes que se esfuerzan por autogestionar y ejecutar Oracle en la nube pública necesitan superar algunos desafíos. Uno de esos desafíos es permitir una alta disponibilidad para la base de datos Oracle. Tradicionalmente, los clientes de Oracle confían en una característica de base de datos de Oracle denominada "Real Application Cluster" o RAC para el soporte de transacciones activas-activas en múltiples nodos del clúster. Un nodo fallido no detendría el procesamiento de la aplicación. Lamentablemente, la implementación de Oracle RAC no está disponible ni es compatible con muchas nubes públicas populares como AWS EC2. Al aprovechar la agrupación en clústeres Pacemaker (PCS) integrada en RHEL y Amazon FSx ONTAP, los clientes pueden lograr una alternativa viable sin el costo de la licencia de Oracle RAC para la agrupación en clústeres activo-pasivo tanto en computación como en almacenamiento para respaldar la carga de trabajo de base de datos Oracle de misión crítica en la nube de AWS.
Esta documentación demuestra los detalles de la configuración de la agrupación en clústeres de Pacemaker en RHEL, la implementación de la base de datos Oracle en EC2 y Amazon FSx ONTAP con el protocolo NFS, la configuración de los recursos de Oracle en Pacemaker para HA y el cierre de la demostración con la validación en los escenarios de HA más frecuentes. La solución también proporciona información sobre cómo realizar copias de seguridad, restaurar y clonar rápidamente bases de datos de Oracle con la herramienta de interfaz de usuario SnapCenter de NetApp .
Esta solución aborda los siguientes casos de uso:
-
Configuración y configuración de agrupación en clústeres de Pacemaker HA en RHEL.
-
Implementación de HA de base de datos Oracle en AWS EC2 y Amazon FSx ONTAP.
Audiencia
Esta solución está destinada a las siguientes personas:
-
Un DBA que desea implementar Oracle en AWS EC2 y Amazon FSx ONTAP.
-
Un arquitecto de soluciones de base de datos que desea probar cargas de trabajo de Oracle en AWS EC2 y Amazon FSx ONTAP.
-
Un administrador de almacenamiento que desee implementar y administrar una base de datos Oracle en AWS EC2 y Amazon FSx ONTAP.
-
Un propietario de una aplicación que desea configurar una base de datos Oracle en AWS EC2 y Amazon FSx ONTAP.
Entorno de prueba y validación de soluciones
Las pruebas y la validación de esta solución se realizaron en un entorno de laboratorio que podría no coincidir con el entorno de implementación final. Ver la secciónFactores clave a considerar en la implementación Para más información.
Arquitectura
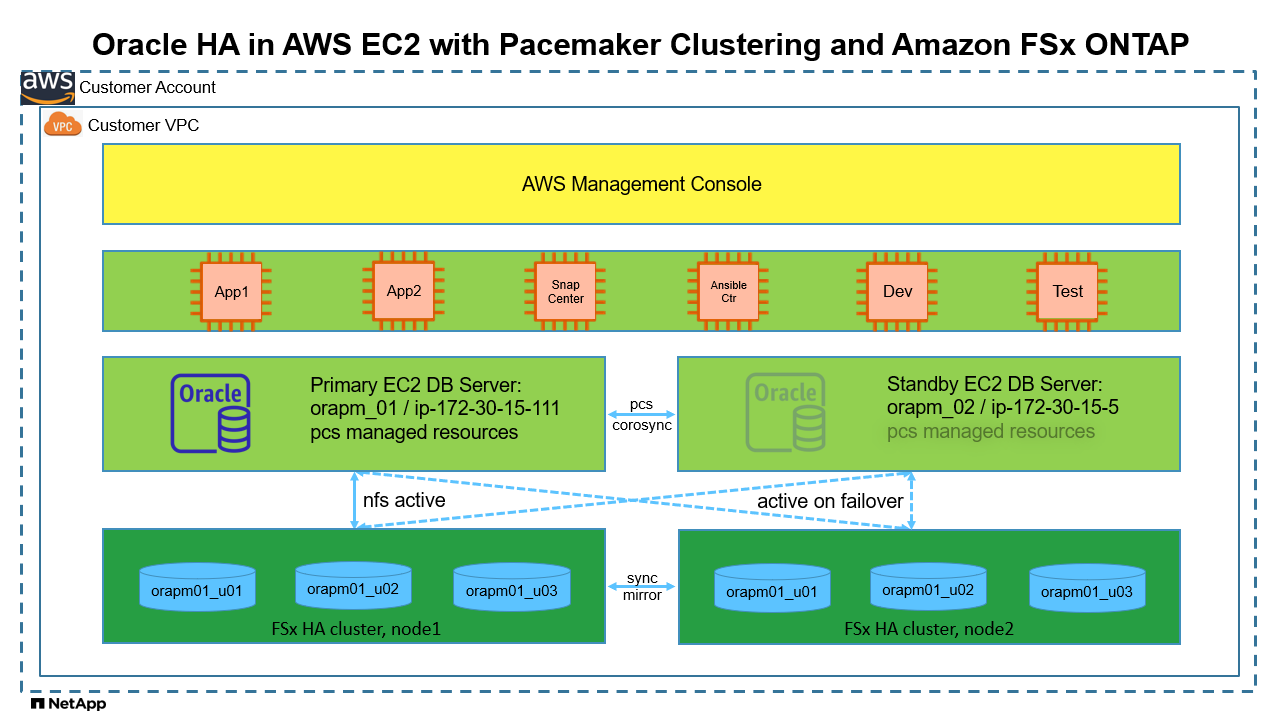
Componentes de hardware y software
Hardware |
||
Almacenamiento de Amazon FSx ONTAP |
Versión actual ofrecida por AWS |
Single-AZ en us-east-1, capacidad de 1024 GiB, rendimiento de 128 MB/s |
Instancias EC2 para el servidor de base de datos |
t2.xlarge/4vCPU/16G |
Dos instancias EC2 T2 xlarge, una como servidor de base de datos principal y la otra como servidor de base de datos en espera |
VM para el controlador Ansible |
4 vCPU, 16 GiB de RAM |
Una máquina virtual Linux para ejecutar el aprovisionamiento automatizado de AWS EC2/FSx y la implementación de Oracle en NFS |
Software |
||
Red Hat Linux |
RHEL Linux 8.6 (LVM) - x64 Gen2 |
Se implementó una suscripción a RedHat para realizar pruebas |
Base de datos Oracle |
Versión 19.18 |
Parche RU aplicado p34765931_190000_Linux-x86-64.zip |
Oracle OPatch |
Versión 12.2.0.1.36 |
Último parche p6880880_190000_Linux-x86-64.zip |
Marcapasos |
Versión 0.10.18 |
Complemento de alta disponibilidad para RHEL 8.0 de RedHat |
Sistema Nacional de Archivos |
Versión 3.0 |
Oracle dNFS habilitado |
Ansible |
núcleo 2.16.2 |
Python 3.6.8 |
Configuración activa/pasiva de la base de datos Oracle en el entorno de laboratorio de AWS EC2/FSx
Servidor |
Base de datos |
Almacenamiento de base de datos |
nodo principal: orapm01/ip-172.30.15.111 |
NTAP(NTAP_PDB1,NTAP_PDB2,NTAP_PDB3) |
/u01, /u02, /u03 Montajes NFS en volúmenes de Amazon FSx ONTAP |
nodo en espera: orapm02/ip-172.30.15.5 |
NTAP(NTAP_PDB1,NTAP_PDB2,NTAP_PDB3) en caso de conmutación por error |
/u01, /u02, /u03 NFS se monta durante la conmutación por error |
Factores clave a considerar en la implementación
-
* Amazon FSx ONTAP HA.* Amazon FSx ONTAP se aprovisiona en un par de controladores de almacenamiento de alta disponibilidad en zonas de disponibilidad individuales o múltiples de manera predeterminada. Proporciona redundancia de almacenamiento de forma activa/pasiva para cargas de trabajo de bases de datos de misión crítica. La conmutación por error del almacenamiento es transparente para el usuario final. No se requiere la intervención del usuario en caso de una conmutación por error del almacenamiento.
-
Grupo de recursos PCS y ordenamiento de recursos. Un grupo de recursos permite que varios recursos con dependencia se ejecuten en el mismo nodo del clúster. El orden de recursos aplica el orden de inicio de los recursos y el orden de apagado a la inversa.
-
Nodo preferido. El clúster Pacemaker se implementa deliberadamente en clústeres activos/pasivos (no es un requisito de Pacemaker) y está sincronizado con la agrupación en clústeres de FSx ONTAP . La instancia EC2 activa se configura como un nodo preferido para los recursos de Oracle cuando está disponible con una restricción de ubicación.
-
Retraso de valla en el nodo en espera. En un clúster PCS de dos nodos, el quórum se establece artificialmente en 1. En el caso de un problema de comunicación entre los nodos del clúster, cualquiera de los nodos podría intentar bloquear al otro nodo, lo que potencialmente puede causar corrupción en los datos. Configurar un retraso en el nodo en espera mitiga el problema y permite que el nodo principal continúe brindando servicios mientras el nodo en espera está protegido.
-
Consideración de implementación Multi-AZ. La solución se implementa y valida en una única zona de disponibilidad. Para la implementación multi-az, se necesitan recursos de red de AWS adicionales para mover la IP flotante de PCS entre las zonas de disponibilidad.
-
Disposición del almacenamiento de la base de datos Oracle. En esta demostración de solución, aprovisionamos tres volúmenes de bases de datos para la base de datos de prueba NTAP para alojar datos binarios, registros y datos de Oracle. Los volúmenes se montan en el servidor Oracle DB como /u01 - binario, /u02 - datos y /u03 - registro a través de NFS. Los archivos de control dual se configuran en los puntos de montaje /u02 y /u03 para redundancia.
-
Configuración de dNFS. Al utilizar dNFS (disponible desde Oracle 11g), una base de datos Oracle que se ejecuta en una máquina virtual DB puede generar significativamente más E/S que el cliente NFS nativo. La implementación automatizada de Oracle configura dNFS en NFSv3 de forma predeterminada.
-
Copia de seguridad de la base de datos. NetApp ofrece un paquete de SnapCenter software para realizar copias de seguridad, restaurar y clonar bases de datos con una interfaz de usuario fácil de usar. NetApp recomienda implementar una herramienta de gestión de este tipo para lograr una copia de seguridad de instantáneas rápida (en menos de un minuto), una restauración de base de datos rápida (en minutos) y una clonación de base de datos.
Implementación de la solución
Las siguientes secciones proporcionan procedimientos paso a paso para la implementación y configuración de Oracle Database HA en AWS EC2 con agrupación en clústeres Pacemaker y Amazon FSx ONTAP para la protección del almacenamiento de la base de datos.
Requisitos previos para la implementación
Details
La implementación requiere los siguientes requisitos previos.
-
Se ha configurado una cuenta de AWS y se han creado los segmentos de red y VPC necesarios dentro de su cuenta de AWS.
-
Aprovisione una máquina virtual Linux como nodo controlador de Ansible con la última versión de Ansible y Git instalada. Consulte el siguiente enlace para obtener más detalles:"Introducción a la automatización de soluciones de NetApp " en la sección -
Setup the Ansible Control Node for CLI deployments on RHEL / CentOSo
Setup the Ansible Control Node for CLI deployments on Ubuntu / Debian.Habilite la autenticación de clave pública/privada ssh entre el controlador Ansible y las máquinas virtuales de base de datos de la instancia EC2.
Aprovisionar instancias EC2 y clúster de almacenamiento Amazon FSx ONTAP
Details
Si bien la instancia EC2 y Amazon FSx ONTAP se pueden aprovisionar manualmente desde la consola de AWS, se recomienda utilizar el kit de herramientas de automatización basado en NetApp Terraform para automatizar el aprovisionamiento de las instancias EC2 y el clúster de almacenamiento FSx ONTAP . A continuación se detallan los procedimientos.
-
Desde la máquina virtual del controlador AWS CloudShell o Ansible, clone una copia del kit de herramientas de automatización para EC2 y FSx ONTAP.
git clone https://bitbucket.ngage.netapp.com/scm/ns-bb/na_aws_fsx_ec2_deploy.git
Si el kit de herramientas no se ejecuta desde AWS CloudShell, se requiere la autenticación de AWS CLI con su cuenta de AWS mediante el par de claves secretas/acceso a la cuenta de usuario de AWS. -
Revise el archivo READme.md incluido en el kit de herramientas. Revise main.tf y los archivos de parámetros asociados según sea necesario para los recursos de AWS requeridos.
An example of main.tf: resource "aws_instance" "orapm01" { ami = var.ami instance_type = var.instance_type subnet_id = var.subnet_id key_name = var.ssh_key_name root_block_device { volume_type = "gp3" volume_size = var.root_volume_size } tags = { Name = var.ec2_tag1 } } resource "aws_instance" "orapm02" { ami = var.ami instance_type = var.instance_type subnet_id = var.subnet_id key_name = var.ssh_key_name root_block_device { volume_type = "gp3" volume_size = var.root_volume_size } tags = { Name = var.ec2_tag2 } } resource "aws_fsx_ontap_file_system" "fsx_01" { storage_capacity = var.fs_capacity subnet_ids = var.subnet_ids preferred_subnet_id = var.preferred_subnet_id throughput_capacity = var.fs_throughput fsx_admin_password = var.fsxadmin_password deployment_type = var.deployment_type disk_iops_configuration { iops = var.iops mode = var.iops_mode } tags = { Name = var.fsx_tag } } resource "aws_fsx_ontap_storage_virtual_machine" "svm_01" { file_system_id = aws_fsx_ontap_file_system.fsx_01.id name = var.svm_name svm_admin_password = var.vsadmin_password } -
Validar y ejecutar el plan Terraform. Una ejecución exitosa crearía dos instancias EC2 y un clúster de almacenamiento FSx ONTAP en la cuenta de AWS de destino. La salida de automatización muestra la dirección IP de la instancia EC2 y los puntos finales del clúster FSx ONTAP .
terraform plan -out=main.planterraform apply main.plan
Esto completa el aprovisionamiento de instancias EC2 y FSx ONTAP para Oracle.
Configuración del clúster de marcapasos
Details
El complemento de alta disponibilidad para RHEL es un sistema en clúster que brinda confiabilidad, escalabilidad y disponibilidad a servicios de producción críticos, como los servicios de base de datos de Oracle. En esta demostración de caso de uso, se instala y configura un clúster Pacemaker de dos nodos para soportar la alta disponibilidad de una base de datos Oracle en un escenario de agrupamiento activo/pasivo.
Inicie sesión en las instancias EC2 como usuario EC2 y complete las siguientes tareas en both Instancias EC2:
-
Eliminar el cliente de AWS Red Hat Update Infrastructure (RHUI).
sudo -i yum -y remove rh-amazon-rhui-client* -
Registre las máquinas virtuales de la instancia EC2 con Red Hat.
sudo subscription-manager register --username xxxxxxxx --password 'xxxxxxxx' --auto-attach -
Habilitar rpms de alta disponibilidad de RHEL.
sudo subscription-manager config --rhsm.manage_repos=1sudo subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms -
Instalar marcapasos y vallado.
sudo yum update -ysudo yum install pcs pacemaker fence-agents-aws -
Cree una contraseña para el usuario hacluster en todos los nodos del clúster. Utilice la misma contraseña para todos los nodos.
sudo passwd hacluster -
Inicie el servicio pcs y habilítelo para que se inicie durante el arranque.
sudo systemctl start pcsd.servicesudo systemctl enable pcsd.service -
Validar el servicio pcsd.
sudo systemctl status pcsd[ec2-user@ip-172-30-15-5 ~]$ sudo systemctl status pcsd ● pcsd.service - PCS GUI and remote configuration interface Loaded: loaded (/usr/lib/systemd/system/pcsd.service; enabled; vendor preset: disabled) Active: active (running) since Tue 2024-09-10 18:50:22 UTC; 33s ago Docs: man:pcsd(8) man:pcs(8) Main PID: 65302 (pcsd) Tasks: 1 (limit: 100849) Memory: 24.0M CGroup: /system.slice/pcsd.service └─65302 /usr/libexec/platform-python -Es /usr/sbin/pcsd Sep 10 18:50:21 ip-172-30-15-5.ec2.internal systemd[1]: Starting PCS GUI and remote configuration interface... Sep 10 18:50:22 ip-172-30-15-5.ec2.internal systemd[1]: Started PCS GUI and remote configuration interface. -
Agregar nodos de clúster a los archivos de host.
sudo vi /etc/hosts[ec2-user@ip-172-30-15-5 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 # cluster nodes 172.30.15.111 ip-172-30-15-111.ec2.internal 172.30.15.5 ip-172-30-15-5.ec2.internal
-
Instalar y configurar awscli para la conectividad a la cuenta de AWS.
sudo yum install awsclisudo aws configure[ec2-user@ip-172-30-15-111 ]# sudo aws configure AWS Access Key ID [None]: XXXXXXXXXXXXXXXXX AWS Secret Access Key [None]: XXXXXXXXXXXXXXXX Default region name [None]: us-east-1 Default output format [None]: json
-
Instale el paquete resource-agents si aún no está instalado.
sudo yum install resource-agents
En only one del nodo del clúster, complete las siguientes tareas para crear el clúster de PC.
-
Autenticar el usuario pcs hacluster.
sudo pcs host auth ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal[ec2-user@ip-172-30-15-111 ~]$ sudo pcs host auth ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal Username: hacluster Password: ip-172-30-15-111.ec2.internal: Authorized ip-172-30-15-5.ec2.internal: Authorized
-
Crear el clúster de pcs.
sudo pcs cluster setup ora_ec2nfsx ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal[ec2-user@ip-172-30-15-111 ~]$ sudo pcs cluster setup ora_ec2nfsx ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal No addresses specified for host 'ip-172-30-15-5.ec2.internal', using 'ip-172-30-15-5.ec2.internal' No addresses specified for host 'ip-172-30-15-111.ec2.internal', using 'ip-172-30-15-111.ec2.internal' Destroying cluster on hosts: 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal'... ip-172-30-15-5.ec2.internal: Successfully destroyed cluster ip-172-30-15-111.ec2.internal: Successfully destroyed cluster Requesting remove 'pcsd settings' from 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal' ip-172-30-15-111.ec2.internal: successful removal of the file 'pcsd settings' ip-172-30-15-5.ec2.internal: successful removal of the file 'pcsd settings' Sending 'corosync authkey', 'pacemaker authkey' to 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal' ip-172-30-15-111.ec2.internal: successful distribution of the file 'corosync authkey' ip-172-30-15-111.ec2.internal: successful distribution of the file 'pacemaker authkey' ip-172-30-15-5.ec2.internal: successful distribution of the file 'corosync authkey' ip-172-30-15-5.ec2.internal: successful distribution of the file 'pacemaker authkey' Sending 'corosync.conf' to 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal' ip-172-30-15-111.ec2.internal: successful distribution of the file 'corosync.conf' ip-172-30-15-5.ec2.internal: successful distribution of the file 'corosync.conf' Cluster has been successfully set up.
-
Habilitar el cluster.
sudo pcs cluster enable --all[ec2-user@ip-172-30-15-111 ~]$ sudo pcs cluster enable --all ip-172-30-15-5.ec2.internal: Cluster Enabled ip-172-30-15-111.ec2.internal: Cluster Enabled
-
Iniciar y validar el cluster.
sudo pcs cluster start --allsudo pcs status[ec2-user@ip-172-30-15-111 ~]$ sudo pcs status Cluster name: ora_ec2nfsx WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Wed Sep 11 15:43:23 2024 on ip-172-30-15-111.ec2.internal * Last change: Wed Sep 11 15:43:06 2024 by hacluster via hacluster on ip-172-30-15-111.ec2.internal * 2 nodes configured * 0 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Esto completa la configuración inicial y la configuración del clúster Pacemaker.
Configuración de cercado de clúster de marcapasos
Details
La configuración de cercas de marcapasos es obligatoria para un clúster de producción. Garantiza que un nodo que funciona mal en su clúster AWS EC2 se aísle automáticamente, lo que evita que el nodo consuma los recursos del clúster, comprometa la funcionalidad del clúster o corrompa los datos compartidos. Esta sección demuestra la configuración del cercado de clúster mediante el agente de cercado fence_aws.
-
Como usuario raíz, ingrese la siguiente consulta de metadatos de AWS para obtener el ID de instancia de cada nodo de instancia EC2.
echo $(curl -s http://169.254.169.254/latest/meta-data/instance-id)[root@ip-172-30-15-111 ec2-user]# echo $(curl -s http://169.254.169.254/latest/meta-data/instance-id) i-0d8e7a0028371636f or just get instance-id from AWS EC2 console
-
Introduzca el siguiente comando para configurar el dispositivo de cerca. Utilice el comando pcmk_host_map para asignar el nombre de host de RHEL al ID de instancia. Utilice la clave de acceso de AWS y la clave de acceso secreta de AWS de la cuenta de usuario de AWS que utilizó anteriormente para la autenticación de AWS.
sudo pcs stonith \ create clusterfence fence_aws access_key=XXXXXXXXXXXXXXXXX secret_key=XXXXXXXXXXXXXXXXXX \ region=us-east-1 pcmk_host_map="ip-172-30-15-111.ec2.internal:i-0d8e7a0028371636f;ip-172-30-15-5.ec2.internal:i-0bc54b315afb20a2e" \ power_timeout=240 pcmk_reboot_timeout=480 pcmk_reboot_retries=4 -
Validar la configuración del cercado.
pcs status[root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Wed Sep 11 21:17:18 2024 on ip-172-30-15-111.ec2.internal * Last change: Wed Sep 11 21:16:40 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 1 resource instance configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
-
Establezca stonith-action en apagado en lugar de reiniciar en el nivel de clúster.
pcs property set stonith-action=off[root@ip-172-30-15-111 ec2-user]# pcs property config Cluster Properties: cluster-infrastructure: corosync cluster-name: ora_ec2nfsx dc-version: 2.1.7-5.1.el8_10-0f7f88312 have-watchdog: false last-lrm-refresh: 1726257586 stonith-action: off
Con stonith-action configurado como desactivado, el nodo del clúster cercado se apagará inicialmente. Después del período definido en stonith power_timeout (240 segundos), el nodo cercado se reiniciará y se volverá a unir al clúster. -
Establezca el retraso de la cerca en 10 segundos para el nodo en espera.
pcs stonith update clusterfence pcmk_delay_base="ip-172-30-15-111.ec2.internal:0;ip-172-30-15-5.ec2.internal:10s"[root@ip-172-30-15-111 ec2-user]# pcs stonith config Resource: clusterfence (class=stonith type=fence_aws) Attributes: clusterfence-instance_attributes access_key=XXXXXXXXXXXXXXXX pcmk_delay_base=ip-172-30-15-111.ec2.internal:0;ip-172-30-15-5.ec2.internal:10s pcmk_host_map=ip-172-30-15-111.ec2.internal:i-0d8e7a0028371636f;ip-172-30-15-5.ec2.internal:i-0bc54b315afb20a2e pcmk_reboot_retries=4 pcmk_reboot_timeout=480 power_timeout=240 region=us-east-1 secret_key=XXXXXXXXXXXXXXXX Operations: monitor: clusterfence-monitor-interval-60s interval=60s
|
|
Ejecutar pcs stonith refresh Comando para actualizar el agente de valla de stonith detenido o borrar acciones de recursos de stonith fallidas.
|
Implementar la base de datos Oracle en el clúster PCS
Details
Recomendamos aprovechar el manual de Ansible proporcionado por NetApp para ejecutar tareas de instalación y configuración de bases de datos con parámetros predefinidos en el clúster PCS. Para esta implementación automatizada de Oracle, tres archivos de parámetros definidos por el usuario necesitan la entrada del usuario antes de la ejecución del libro de estrategias.
-
hosts: define los objetivos contra los cuales se ejecuta el libro de estrategias de automatización.
-
vars/vars.yml: el archivo de variables globales que define las variables que se aplican a todos los objetivos.
-
host_vars/host_name.yml: el archivo de variables locales que define las variables que se aplican solo a un destino nombrado. En nuestro caso de uso, estos son los servidores Oracle DB.
Además de estos archivos de variables definidos por el usuario, hay varios archivos de variables predeterminados que contienen parámetros predeterminados que no requieren cambios a menos que sea necesario. A continuación se muestran los detalles de la implementación automatizada de Oracle en AWS EC2 y FSx ONTAP en una configuración de agrupamiento de PCS.
-
Desde el directorio de inicio del usuario administrador del controlador Ansible, clone una copia del kit de herramientas de automatización de implementación de Oracle de NetApp para NFS.
git clone https://bitbucket.ngage.netapp.com/scm/ns-bb/na_oracle_deploy_nfs.git
El controlador Ansible puede estar ubicado en la misma VPC que la instancia EC2 de la base de datos o en las instalaciones locales siempre que haya conectividad de red entre ellos. -
Complete los parámetros definidos por el usuario en los archivos de parámetros de hosts. A continuación se muestran ejemplos de configuración típica de archivo de host.
[admin@ansiblectl na_oracle_deploy_nfs]$ cat hosts #Oracle hosts [oracle] orapm01 ansible_host=172.30.15.111 ansible_ssh_private_key_file=ec2-user.pem orapm02 ansible_host=172.30.15.5 ansible_ssh_private_key_file=ec2-user.pem
-
Complete los parámetros definidos por el usuario en los archivos de parámetros vars/vars.yml. A continuación se muestran ejemplos de configuración típica del archivo vars.yml.
[admin@ansiblectl na_oracle_deploy_nfs]$ cat vars/vars.yml ###################################################################### ###### Oracle 19c deployment user configuration variables ###### ###### Consolidate all variables from ONTAP, linux and oracle ###### ###################################################################### ########################################### ### ONTAP env specific config variables ### ########################################### # Prerequisite to create three volumes in NetApp ONTAP storage from System Manager or cloud dashboard with following naming convention: # db_hostname_u01 - Oracle binary # db_hostname_u02 - Oracle data # db_hostname_u03 - Oracle redo # It is important to strictly follow the name convention or the automation will fail. ########################################### ### Linux env specific config variables ### ########################################### redhat_sub_username: xxxxxxxx redhat_sub_password: "xxxxxxxx" #################################################### ### DB env specific install and config variables ### #################################################### # Database domain name db_domain: ec2.internal # Set initial password for all required Oracle passwords. Change them after installation. initial_pwd_all: "xxxxxxxx"
-
Complete los parámetros definidos por el usuario en los archivos de parámetros host_vars/host_name.yml. A continuación se muestran ejemplos de configuración típica del archivo host_vars/host_name.yml.
[admin@ansiblectl na_oracle_deploy_nfs]$ cat host_vars/orapm01.yml # User configurable Oracle host specific parameters # Database SID. By default, a container DB is created with 3 PDBs within the CDB oracle_sid: NTAP # CDB is created with SGA at 75% of memory_limit, MB. Consider how many databases to be hosted on the node and # how much ram to be allocated to each DB. The grand total of SGA should not exceed 75% available RAM on node. memory_limit: 8192 # Local NFS lif ip address to access database volumes nfs_lif: 172.30.15.95
La dirección nfs_lif se puede recuperar de los puntos finales del clúster FSx ONTAP resultantes de la implementación automatizada de EC2 y FSx ONTAP en la sección anterior. -
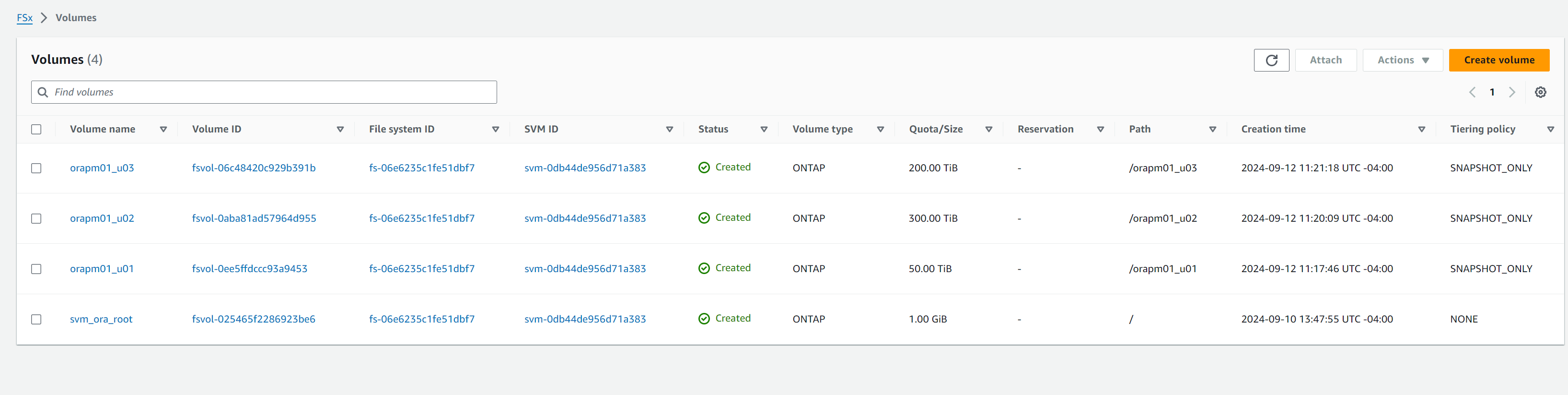
Cree volúmenes de bases de datos desde la consola de AWS FSx. Asegúrese de utilizar el nombre de host del nodo principal de PCS (orapm01) como prefijo para los volúmenes como se muestra a continuación.
-
Etapa siguiente de los archivos de instalación de Oracle 19c en el directorio ip-172-30-15-111.ec2.internal /tmp/archive de la instancia EC2 del nodo primario de PCS con permiso 777.
installer_archives: - "LINUX.X64_193000_db_home.zip" - "p34765931_190000_Linux-x86-64.zip" - "p6880880_190000_Linux-x86-64.zip"
-
Ejecutar playbook para la configuración de Linux para
all nodes.ansible-playbook -i hosts 2-linux_config.yml -u ec2-user -e @vars/vars.yml[admin@ansiblectl na_oracle_deploy_nfs]$ ansible-playbook -i hosts 2-linux_config.yml -u ec2-user -e @vars/vars.yml PLAY [Linux Setup and Storage Config for Oracle] **************************************************************************************************************************************************************************************************************************************************************************** TASK [Gathering Facts] ****************************************************************************************************************************************************************************************************************************************************************************************************** ok: [orapm01] ok: [orapm02] TASK [linux : Configure RedHat 7 for Oracle DB installation] **************************************************************************************************************************************************************************************************************************************************************** skipping: [orapm01] skipping: [orapm02] TASK [linux : Configure RedHat 8 for Oracle DB installation] **************************************************************************************************************************************************************************************************************************************************************** included: /home/admin/na_oracle_deploy_nfs/roles/linux/tasks/rhel8_config.yml for orapm01, orapm02 TASK [linux : Register subscriptions for RedHat Server] ********************************************************************************************************************************************************************************************************************************************************************* ok: [orapm01] ok: [orapm02] . . .
-
Ejecutar playbook para la configuración de Oracle
only on primary node(comentar el nodo en espera en el archivo de hosts).ansible-playbook -i hosts 4-oracle_config.yml -u ec2-user -e @vars/vars.yml --skip-tags "enable_db_start_shut"[admin@ansiblectl na_oracle_deploy_nfs]$ ansible-playbook -i hosts 4-oracle_config.yml -u ec2-user -e @vars/vars.yml --skip-tags "enable_db_start_shut" PLAY [Oracle installation and configuration] ******************************************************************************************************************************************************************************************************************************************************************************** TASK [Gathering Facts] ****************************************************************************************************************************************************************************************************************************************************************************************************** ok: [orapm01] TASK [oracle : Oracle software only install] ******************************************************************************************************************************************************************************************************************************************************************************** included: /home/admin/na_oracle_deploy_nfs/roles/oracle/tasks/oracle_install.yml for orapm01 TASK [oracle : Create mount points for NFS file systems / Mount NFS file systems on Oracle hosts] *************************************************************************************************************************************************************************************************************************** included: /home/admin/na_oracle_deploy_nfs/roles/oracle/tasks/oracle_mount_points.yml for orapm01 TASK [oracle : Create mount points for NFS file systems] ******************************************************************************************************************************************************************************************************************************************************************** changed: [orapm01] => (item=/u01) changed: [orapm01] => (item=/u02) changed: [orapm01] => (item=/u03) . . .
-
Una vez implementada la base de datos, comente los montajes /u01, /u02, /u03 en /etc/fstab en el nodo principal ya que los puntos de montaje serán administrados solo por PCS.
sudo vi /etc/fstab[root@ip-172-30-15-111 ec2-user]# cat /etc/fstab UUID=eaa1f38e-de0f-4ed5-a5b5-2fa9db43bb38 / xfs defaults 0 0 /mnt/swapfile swap swap defaults 0 0 #172.30.15.95:/orapm01_u01 /u01 nfs rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 0 0 #172.30.15.95:/orapm01_u02 /u02 nfs rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 0 0 #172.30.15.95:/orapm01_u03 /u03 nfs rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 0 0
-
Copie /etc/oratab /etc/oraInst.loc, /home/oracle/.bash_profile al nodo en espera. Asegúrese de mantener la propiedad y los permisos adecuados de los archivos.
-
Apagar la base de datos, el escucha y desmontar /u01, /u02, /u03 en el nodo principal.
[root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Wed Sep 18 16:51:02 UTC 2024 [oracle@ip-172-30-15-111 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Wed Sep 18 16:51:16 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> shutdown immediate; SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 [oracle@ip-172-30-15-111 ~]$ lsnrctl stop listener.ntap [oracle@ip-172-30-15-111 ~]$ exit logout [root@ip-172-30-15-111 ec2-user]# umount /u01 [root@ip-172-30-15-111 ec2-user]# umount /u02 [root@ip-172-30-15-111 ec2-user]# umount /u03
-
Cree puntos de montaje en el nodo en espera ip-172-30-15-5.
mkdir /u01 mkdir /u02 mkdir /u03 -
Monte los volúmenes de base de datos de FSx ONTAP en el nodo en espera ip-172-30-15-5.
mount -t nfs 172.30.15.95:/orapm01_u01 /u01 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536mount -t nfs 172.30.15.95:/orapm01_u02 /u02 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536mount -t nfs 172.30.15.95:/orapm01_u03 /u03 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536[root@ip-172-30-15-5 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.7G 33M 7.7G 1% /dev/shm tmpfs 7.7G 17M 7.7G 1% /run tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup /dev/xvda2 50G 21G 30G 41% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 844G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 844G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 844G 100% /u03
-
Cambiado al usuario de Oracle, volver a vincular el binario.
[root@ip-172-30-15-5 ec2-user]# su - oracle Last login: Thu Sep 12 18:09:03 UTC 2024 on pts/0 [oracle@ip-172-30-15-5 ~]$ env | grep ORA ORACLE_SID=NTAP ORACLE_HOME=/u01/app/oracle/product/19.0.0/NTAP [oracle@ip-172-30-15-5 ~]$ cd $ORACLE_HOME/bin [oracle@ip-172-30-15-5 bin]$ ./relink writing relink log to: /u01/app/oracle/product/19.0.0/NTAP/install/relinkActions2024-09-12_06-21-40PM.log
-
Copie la biblioteca dnfs a la carpeta odm. Al volver a vincular se podría perder el archivo de biblioteca dfns.
[oracle@ip-172-30-15-5 odm]$ cd /u01/app/oracle/product/19.0.0/NTAP/rdbms/lib/odm [oracle@ip-172-30-15-5 odm]$ cp ../../../lib/libnfsodm19.so .
-
Iniciar base de datos para validar en el nodo en espera ip-172-30-15-5.
[oracle@ip-172-30-15-5 odm]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Thu Sep 12 18:30:04 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to an idle instance. SQL> startup; ORACLE instance started. Total System Global Area 6442449688 bytes Fixed Size 9177880 bytes Variable Size 1090519040 bytes Database Buffers 5335154688 bytes Redo Buffers 7598080 bytes Database mounted. Database opened. SQL> select name, open_mode from v$database; NAME OPEN_MODE --------- -------------------- NTAP READ WRITE SQL> show pdbs CON_ID CON_NAME OPEN MODE RESTRICTED ---------- ------------------------------ ---------- ---------- 2 PDB$SEED READ ONLY NO 3 NTAP_PDB1 READ WRITE NO 4 NTAP_PDB2 READ WRITE NO 5 NTAP_PDB3 READ WRITE NO -
Apagar la base de datos y conmutar por recuperación la base de datos al nodo principal ip-172-30-15-111.
SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. SQL> exit [root@ip-172-30-15-5 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.7G 33M 7.7G 1% /dev/shm tmpfs 7.7G 17M 7.7G 1% /run tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup /dev/xvda2 50G 21G 30G 41% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 844G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 844G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 844G 100% /u03 [root@ip-172-30-15-5 ec2-user]# umount /u01 [root@ip-172-30-15-5 ec2-user]# umount /u02 [root@ip-172-30-15-5 ec2-user]# umount /u03 [root@ip-172-30-15-111 ec2-user]# mount -t nfs 172.30.15.95:/orapm01_u01 /u01 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. [root@ip-172-30-15-111 ec2-user]# mount -t nfs 172.30.15.95:/orapm01_u02 /u02 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. [root@ip-172-30-15-111 ec2-user]# mount -t nfs 172.30.15.95:/orapm01_u03 /u03 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. [root@ip-172-30-15-111 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.8G 48M 7.7G 1% /dev/shm tmpfs 7.8G 33M 7.7G 1% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/xvda2 50G 29G 22G 58% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 844G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 844G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 844G 100% /u03 [root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Thu Sep 12 18:13:34 UTC 2024 on pts/1 [oracle@ip-172-30-15-111 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Thu Sep 12 18:38:46 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to an idle instance. SQL> startup; ORACLE instance started. Total System Global Area 6442449688 bytes Fixed Size 9177880 bytes Variable Size 1090519040 bytes Database Buffers 5335154688 bytes Redo Buffers 7598080 bytes Database mounted. Database opened. SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 [oracle@ip-172-30-15-111 ~]$ lsnrctl start listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 12-SEP-2024 18:39:17 Copyright (c) 1991, 2022, Oracle. All rights reserved. Starting /u01/app/oracle/product/19.0.0/NTAP/bin/tnslsnr: please wait... TNSLSNR for Linux: Version 19.0.0.0.0 - Production System parameter file is /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Log messages written to /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=ip-172-30-15-111.ec2.internal)(PORT=1521))) Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=ip-172-30-15-111.ec2.internal)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias listener.ntap Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 12-SEP-2024 18:39:17 Uptime 0 days 0 hr. 0 min. 0 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=ip-172-30-15-111.ec2.internal)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) The listener supports no services The command completed successfully
Configurar recursos de Oracle para la administración de PCS
Details
El objetivo de configurar la agrupación en clústeres de Pacemaker es configurar una solución de alta disponibilidad activa/pasiva para ejecutar Oracle en el entorno AWS EC2 y FSx ONTAP con una mínima intervención del usuario en caso de falla. A continuación se muestra la configuración de recursos de Oracle para la administración de PCS.
-
Como usuario root en la instancia EC2 principal ip-172-30-15-111, cree una dirección IP privada secundaria con una dirección IP privada no utilizada en el bloque CIDR de VPC como IP flotante. En el proceso, cree un grupo de recursos de Oracle al que pertenecerá la dirección IP privada secundaria.
pcs resource create privip ocf:heartbeat:awsvip secondary_private_ip=172.30.15.33 --group oracle[root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 16:25:35 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 16:25:23 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 2 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-5.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Si la privip se crea en un nodo de clúster en espera, muévala al nodo principal como se muestra a continuación. -
Mover un recurso entre nodos del clúster.
pcs resource move privip ip-172-30-15-111.ec2.internal[root@ip-172-30-15-111 ec2-user]# pcs resource move privip ip-172-30-15-111.ec2.internal Warning: A move constraint has been created and the resource 'privip' may or may not move depending on other configuration [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx WARNINGS: Following resources have been moved and their move constraints are still in place: 'privip' Run 'pcs constraint location' or 'pcs resource clear <resource id>' to view or remove the constraints, respectively Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 16:26:38 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 16:26:27 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 2 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal (Monitoring) Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled -
Cree una IP virtual (vip) para Oracle. La IP virtual flotará entre el nodo principal y el nodo en espera según sea necesario.
pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.30.15.33 cidr_netmask=25 nic=eth0 op monitor interval=10s --group oracle[root@ip-172-30-15-111 ec2-user]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.30.15.33 cidr_netmask=25 nic=eth0 op monitor interval=10s --group oracle [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx WARNINGS: Following resources have been moved and their move constraints are still in place: 'privip' Run 'pcs constraint location' or 'pcs resource clear <resource id>' to view or remove the constraints, respectively Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 16:27:34 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 16:27:24 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 3 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled -
Como usuario de Oracle, actualice los archivos listener.ora y tnsnames.ora para que apunten a la dirección VIP. Reiniciar el oyente. Rebota la base de datos si es necesario para que la base de datos se registre con el oyente.
vi $ORACLE_HOME/network/admin/listener.oravi $ORACLE_HOME/network/admin/tnsnames.ora[oracle@ip-172-30-15-111 admin]$ cat listener.ora # listener.ora Network Configuration File: /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora # Generated by Oracle configuration tools. LISTENER.NTAP = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.30.15.33)(PORT = 1521)) (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521)) ) ) [oracle@ip-172-30-15-111 admin]$ cat tnsnames.ora # tnsnames.ora Network Configuration File: /u01/app/oracle/product/19.0.0/NTAP/network/admin/tnsnames.ora # Generated by Oracle configuration tools. NTAP = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.30.15.33)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = NTAP.ec2.internal) ) ) LISTENER_NTAP = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.30.15.33)(PORT = 1521)) [oracle@ip-172-30-15-111 admin]$ lsnrctl status listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 13-SEP-2024 18:28:17 Copyright (c) 1991, 2022, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.30.15.33)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias listener.ntap Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 13-SEP-2024 18:15:51 Uptime 0 days 0 hr. 12 min. 25 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=172.30.15.33)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcps)(HOST=ip-172-30-15-111.ec2.internal)(PORT=5500))(Security=(my_wallet_directory=/u01/app/oracle/product/19.0.0/NTAP/admin/NTAP/xdb_wallet))(Presentation=HTTP)(Session=RAW)) Services Summary... Service "21f0b5cc1fa290e2e0636f0f1eacfd43.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b74445329119e0636f0f1eacec03.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b83929709164e0636f0f1eacacc3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAP.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAPXDB.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb1.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb2.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... The command completed successfully **Oracle listener now listens on vip for database connection** -
Agregue los puntos de montaje /u01, /u02, /u03 al grupo de recursos de Oracle.
pcs resource create u01 ocf:heartbeat:Filesystem device='172.30.15.95:/orapm01_u01' directory='/u01' fstype='nfs' options='rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536' --group oraclepcs resource create u02 ocf:heartbeat:Filesystem device='172.30.15.95:/orapm01_u02' directory='/u02' fstype='nfs' options='rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536' --group oraclepcs resource create u03 ocf:heartbeat:Filesystem device='172.30.15.95:/orapm01_u03' directory='/u03' fstype='nfs' options='rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536' --group oracle -
Cree un ID de usuario de monitor PCS en Oracle DB.
[root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Fri Sep 13 18:12:24 UTC 2024 on pts/0 [oracle@ip-172-30-15-111 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 19:08:41 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> CREATE USER c##ocfmon IDENTIFIED BY "XXXXXXXX"; User created. SQL> grant connect to c##ocfmon; Grant succeeded. SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0
-
Agregar base de datos al grupo de recursos de Oracle.
pcs resource create ntap ocf:heartbeat:oracle sid='NTAP' home='/u01/app/oracle/product/19.0.0/NTAP' user='oracle' monuser='C##OCFMON' monpassword='XXXXXXXX' monprofile='DEFAULT' --group oracle -
Agregar un escucha de base de datos al grupo de recursos de Oracle.
pcs resource create listener ocf:heartbeat:oralsnr sid='NTAP' listener='listener.ntap' --group=oracle -
Actualice todas las restricciones de ubicación de recursos en el grupo de recursos de Oracle al nodo principal como nodo preferido.
pcs constraint location privip prefers ip-172-30-15-111.ec2.internal pcs constraint location vip prefers ip-172-30-15-111.ec2.internal pcs constraint location u01 prefers ip-172-30-15-111.ec2.internal pcs constraint location u02 prefers ip-172-30-15-111.ec2.internal pcs constraint location u03 prefers ip-172-30-15-111.ec2.internal pcs constraint location ntap prefers ip-172-30-15-111.ec2.internal pcs constraint location listener prefers ip-172-30-15-111.ec2.internal[root@ip-172-30-15-111 ec2-user]# pcs constraint config Location Constraints: Resource: listener Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: ntap Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: privip Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: u01 Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: u02 Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: u03 Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: vip Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Ordering Constraints: Colocation Constraints: Ticket Constraints: -
Validar la configuración de los recursos de Oracle.
pcs status[root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 19:25:32 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 19:23:40 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * ntap (ocf::heartbeat:oracle): Started ip-172-30-15-111.ec2.internal * listener (ocf::heartbeat:oralsnr): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Validación de alta disponibilidad posterior a la implementación
Details
Después de la implementación, es vital ejecutar algunas pruebas y validaciones para garantizar que el clúster de conmutación por error de la base de datos Oracle de PCS esté configurado correctamente y funcione como se espera. La validación de la prueba incluye conmutación por error administrada y simulación de fallas inesperadas de recursos y recuperación mediante el mecanismo de protección del clúster.
-
Valide el cercado del nodo activando manualmente el cercado del nodo en espera y observe que el nodo en espera se desconectó y se reinició después de un tiempo de espera.
pcs stonith fence <standbynodename>[root@ip-172-30-15-111 ec2-user]# pcs stonith fence ip-172-30-15-5.ec2.internal Node: ip-172-30-15-5.ec2.internal fenced [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 21:58:45 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 21:55:12 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-111.ec2.internal ] * OFFLINE: [ ip-172-30-15-5.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * ntap (ocf::heartbeat:oracle): Started ip-172-30-15-111.ec2.internal * listener (ocf::heartbeat:oralsnr): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled -
Simule una falla del escucha de la base de datos eliminando el proceso del escucha y observe que PCS monitoreó la falla del escucha y lo reinició en unos segundos.
[root@ip-172-30-15-111 ec2-user]# ps -ef | grep lsnr oracle 154895 1 0 18:15 ? 00:00:00 /u01/app/oracle/product/19.0.0/NTAP/bin/tnslsnr listener.ntap -inherit root 217779 120186 0 19:36 pts/0 00:00:00 grep --color=auto lsnr [root@ip-172-30-15-111 ec2-user]# kill -9 154895 [root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Thu Sep 19 14:58:54 UTC 2024 [oracle@ip-172-30-15-111 ~]$ lsnrctl status listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 13-SEP-2024 19:36:51 Copyright (c) 1991, 2022, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.30.15.33)(PORT=1521))) TNS-12541: TNS:no listener TNS-12560: TNS:protocol adapter error TNS-00511: No listener Linux Error: 111: Connection refused Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC1521))) TNS-12541: TNS:no listener TNS-12560: TNS:protocol adapter error TNS-00511: No listener Linux Error: 111: Connection refused [oracle@ip-172-30-15-111 ~]$ lsnrctl status listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 19-SEP-2024 15:00:10 Copyright (c) 1991, 2022, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.30.15.33)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias listener.ntap Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 16-SEP-2024 14:00:14 Uptime 3 days 0 hr. 59 min. 56 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=172.30.15.33)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcps)(HOST=ip-172-30-15-111.ec2.internal)(PORT=5500))(Security=(my_wallet_directory=/u01/app/oracle/product/19.0.0/NTAP/admin/NTAP/xdb_wallet))(Presentation=HTTP)(Session=RAW)) Services Summary... Service "21f0b5cc1fa290e2e0636f0f1eacfd43.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b74445329119e0636f0f1eacec03.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b83929709164e0636f0f1eacacc3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAP.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAPXDB.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb1.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb2.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... The command completed successfully
-
Simule una falla de la base de datos eliminando el proceso pmon y observe que PCS monitoreó la falla de la base de datos y la reinició en unos segundos.
**Make a remote connection to ntap database** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 15:42:42 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Thu Sep 12 2024 13:37:28 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-111.ec2.internal SQL> **Kill ntap pmon process to simulate a failure** [root@ip-172-30-15-111 ec2-user]# ps -ef | grep pmon oracle 159247 1 0 18:27 ? 00:00:00 ora_pmon_NTAP root 230595 120186 0 19:44 pts/0 00:00:00 grep --color=auto pmon [root@ip-172-30-15-111 ec2-user]# kill -9 159247 **Observe the DB failure** SQL> / select instance_name, host_name from v$instance * ERROR at line 1: ORA-03113: end-of-file on communication channel Process ID: 227424 Session ID: 396 Serial number: 4913 SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 **Reconnect to DB after reboot** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 15:47:24 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Sep 13 2024 15:42:47 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-111.ec2.internal SQL>
-
Valide una conmutación por error de base de datos administrada del nodo principal al nodo en espera colocando el nodo principal en modo de espera para conmutar por error los recursos de Oracle al nodo en espera.
pcs node standby <nodename>**Stopping Oracle resources on primary node in reverse order** [root@ip-172-30-15-111 ec2-user]# pcs node standby ip-172-30-15-111.ec2.internal [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:01:16 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:01:08 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Node ip-172-30-15-111.ec2.internal: standby (with active resources) * Online: [ ip-172-30-15-5.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Stopping ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Stopped * u03 (ocf::heartbeat:Filesystem): Stopped * ntap (ocf::heartbeat:oracle): Stopped * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **Starting Oracle resources on standby node in sequencial order** [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:01:34 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:01:08 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Node ip-172-30-15-111.ec2.internal: standby * Online: [ ip-172-30-15-5.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-5.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-5.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-5.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-5.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-5.ec2.internal * ntap (ocf::heartbeat:oracle): Starting ip-172-30-15-5.ec2.internal * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **NFS mount points mounted on standby node** [root@ip-172-30-15-5 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.7G 33M 7.7G 1% /dev/shm tmpfs 7.7G 17M 7.7G 1% /run tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup /dev/xvda2 50G 21G 30G 41% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 840G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 840G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 840G 100% /u03 tmpfs 1.6G 0 1.6G 0% /run/user/54321 **Database opened on standby node** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 16:34:08 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Sep 13 2024 15:47:28 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select name, open_mode from v$database; NAME OPEN_MODE --------- -------------------- NTAP READ WRITE SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-5.ec2.internal SQL> -
Valide una conmutación por error de una base de datos administrada desde un nodo en espera a uno principal desactivando el nodo principal y observe que los recursos de Oracle se recuperan automáticamente debido a la configuración del nodo preferido.
pcs node unstandby <nodename>**Stopping Oracle resources on standby node for failback to primary** [root@ip-172-30-15-111 ec2-user]# pcs node unstandby ip-172-30-15-111.ec2.internal [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:41:30 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:41:18 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Stopping ip-172-30-15-5.ec2.internal * vip (ocf::heartbeat:IPaddr2): Stopped * u01 (ocf::heartbeat:Filesystem): Stopped * u02 (ocf::heartbeat:Filesystem): Stopped * u03 (ocf::heartbeat:Filesystem): Stopped * ntap (ocf::heartbeat:oracle): Stopped * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **Starting Oracle resources on primary node for failback** [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:41:45 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:41:18 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * ntap (ocf::heartbeat:oracle): Starting ip-172-30-15-111.ec2.internal * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **Database now accepts connection on primary node** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 16:46:07 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Sep 13 2024 16:34:12 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-111.ec2.internal SQL>
Esto completa la validación de Oracle HA y la demostración de la solución en AWS EC2 con agrupación en clústeres Pacemaker y Amazon FSx ONTAP como backend de almacenamiento de base de datos.
Copia de seguridad, restauración y clonación de Oracle con SnapCenter
Details
NetApp recomienda la herramienta de interfaz de usuario SnapCenter para administrar la base de datos Oracle implementada en AWS EC2 y Amazon FSx ONTAP. Consulte TR-4979"Oracle simplificado y autogestionado en VMware Cloud on AWS con FSx ONTAP montado como invitado" sección Oracle backup, restore, and clone with SnapCenter para obtener detalles sobre la configuración de SnapCenter y la ejecución de los flujos de trabajo de copia de seguridad, restauración y clonación de bases de datos.
Dónde encontrar información adicional
Para obtener más información sobre la información descrita en este documento, revise los siguientes documentos y/o sitios web: