

TR-4956: Implementación automatizada de alta disponibilidad y recuperación ante desastres de PostgreSQL en AWS FSx/EC2
 Sugerir cambios
Sugerir cambios
Allen Cao, Niyaz Mohamed, NetApp
Esta solución proporciona una descripción general y detalles para la implementación de la base de datos PostgreSQL y la configuración de HA/DR, conmutación por error y resincronización basada en la tecnología NetApp SnapMirror integrada en la oferta de almacenamiento FSx ONTAP y el kit de herramientas de automatización NetApp Ansible en AWS.
Objetivo
PostgreSQL es una base de datos de código abierto ampliamente utilizada que ocupa el puesto número cuatro entre los diez motores de bases de datos más populares."Motores DB" . Por un lado, PostgreSQL obtiene su popularidad de su modelo de código abierto y sin licencia, aunque aún posee características sofisticadas. Por otro lado, debido a que es de código abierto, hay escasez de orientación detallada sobre la implementación de bases de datos de nivel de producción en el área de alta disponibilidad y recuperación ante desastres (HA/DR), particularmente en la nube pública. En general, puede resultar difícil configurar un sistema PostgreSQL HA/DR típico con modo de espera activo y tibio, replicación de transmisión, etc. Probar el entorno de HA/DR promoviendo el sitio en espera y luego volviendo al principal puede interrumpir la producción. Hay problemas de rendimiento bien documentados en el servidor principal cuando se implementan cargas de trabajo de lectura en modo de espera activo de transmisión.
En esta documentación, demostramos cómo puede eliminar una solución de alta disponibilidad y recuperación ante desastres de transmisión de PostgreSQL a nivel de aplicación y crear una solución de alta disponibilidad y recuperación ante desastres de PostgreSQL basada en almacenamiento de AWS FSx ONTAP e instancias de cómputo de EC2 mediante replicación a nivel de almacenamiento. La solución crea un sistema más simple y comparable y ofrece resultados equivalentes en comparación con la replicación de transmisión a nivel de aplicación PostgreSQL tradicional para HA/DR.
Esta solución se basa en la tecnología de replicación a nivel de almacenamiento NetApp SnapMirror probada y madura, que está disponible en el almacenamiento en nube FSX ONTAP nativo de AWS para PostgreSQL HA/DR. Es fácil de implementar con un kit de herramientas de automatización proporcionado por el equipo de Soluciones NetApp . Proporciona una funcionalidad similar a la vez que elimina la complejidad y el bajo rendimiento del sitio principal con la solución HA/DR basada en transmisión a nivel de aplicación. La solución se puede implementar y probar fácilmente sin afectar el sitio principal activo.
Esta solución aborda los siguientes casos de uso:
-
Implementación de alta disponibilidad y recuperación ante desastres de nivel de producción para PostgreSQL en la nube pública de AWS
-
Prueba y validación de una carga de trabajo de PostgreSQL en la nube pública de AWS
-
Prueba y validación de una estrategia de alta disponibilidad y recuperación ante desastres de PostgreSQL basada en la tecnología de replicación SnapMirror de NetApp
Audiencia
Esta solución está destinada a las siguientes personas:
-
El DBA que esté interesado en implementar PostgreSQL con HA/DR en la nube pública de AWS.
-
El arquitecto de soluciones de base de datos que está interesado en probar cargas de trabajo de PostgreSQL en la nube pública de AWS.
-
El administrador de almacenamiento que está interesado en implementar y administrar instancias de PostgreSQL implementadas en el almacenamiento de AWS FSx.
-
El propietario de la aplicación que esté interesado en configurar un entorno PostgreSQL en AWS FSx/EC2.
Entorno de prueba y validación de soluciones
La prueba y validación de esta solución se realizó en un entorno AWS FSx y EC2 que podría no coincidir con el entorno de implementación final. Para más información, consulte la sección Factores clave a considerar en la implementación .
Arquitectura
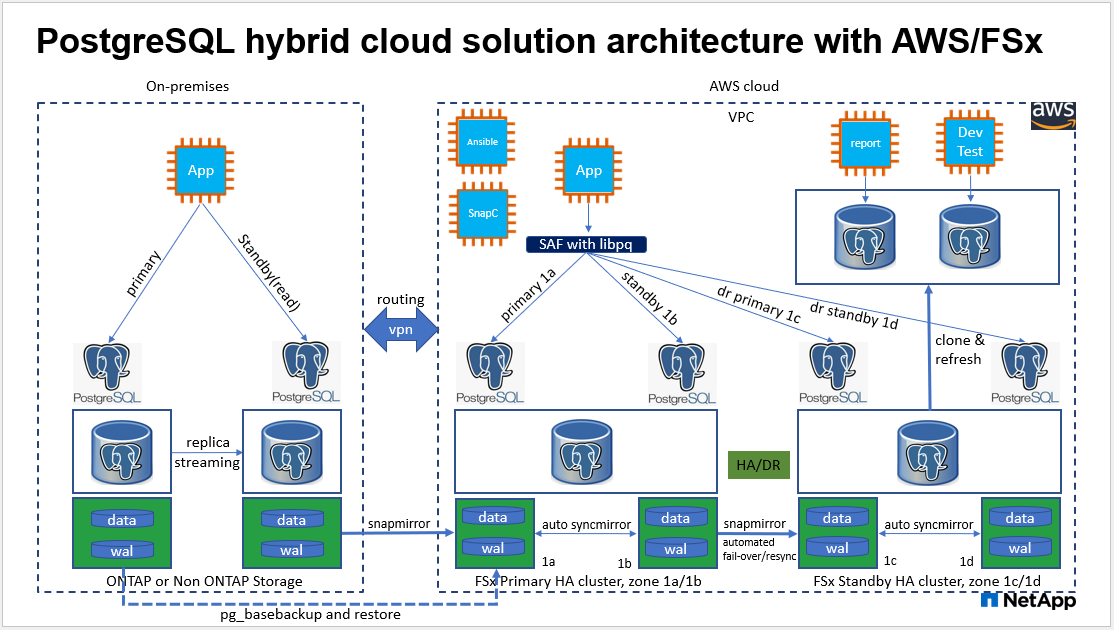
Componentes de hardware y software
Hardware |
||
Almacenamiento de FSx ONTAP |
Versión actual |
Dos pares de HA de FSx en la misma VPC y zona de disponibilidad que los clústeres de HA principal y en espera |
Instancia EC2 para computación |
t2.xlarge/4vCPU/16G |
Dos EC2 T2 xlarge como instancias de cómputo principal y de respaldo |
Controlador Ansible |
máquina virtual Centos local/4 vCPU/8G |
Una máquina virtual para alojar el controlador de automatización de Ansible, ya sea localmente o en la nube |
Software |
||
Red Hat Linux |
RHEL-8.6.0_HVM-20220503-x86_64-2-Hourly2-GP2 |
Se implementó una suscripción a RedHat para realizar pruebas |
Centos Linux |
Versión 8.2.2004 de CentOS Linux (Core) |
Hospedaje del controlador Ansible implementado en el laboratorio local |
PostgreSQL |
Versión 14.5 |
La automatización extrae la última versión disponible de PostgreSQL del repositorio yum postgresql.ora |
Ansible |
Versión 2.10.3 |
Requisitos previos para las colecciones y bibliotecas requeridas instaladas con el manual de requisitos |
Factores clave a considerar en la implementación
-
Copia de seguridad, restauración y recuperación de bases de datos PostgreSQL. Una base de datos PostgreSQL admite varios métodos de respaldo, como un respaldo lógico con pg_dump, un respaldo físico en línea con pg_basebackup o un comando de respaldo del sistema operativo de nivel inferior y instantáneas consistentes a nivel de almacenamiento. Esta solución utiliza instantáneas de grupos de consistencia de NetApp para la copia de seguridad, restauración y recuperación de datos de bases de datos PostgreSQL y volúmenes WAL en el sitio en espera. Las instantáneas de volumen del grupo de consistencia de NetApp secuencian la E/S a medida que se escribe en el almacenamiento y protegen la integridad de los archivos de datos de la base de datos.
-
Instancias de cómputo EC2. En estas pruebas y validaciones, utilizamos el tipo de instancia AWS EC2 t2.xlarge para la instancia de cómputo de la base de datos PostgreSQL. NetApp recomienda utilizar una instancia EC2 de tipo M5 como instancia de cómputo para PostgreSQL en la implementación porque está optimizada para cargas de trabajo de bases de datos. La instancia de cómputo en espera siempre debe implementarse en la misma zona que el sistema de archivos pasivo (en espera) implementado para el clúster FSx HA.
-
Implementación de clústeres de alta disponibilidad de almacenamiento FSx en una o varias zonas. En estas pruebas y validaciones, implementamos un clúster FSx HA en una única zona de disponibilidad de AWS. Para la implementación de producción, NetApp recomienda implementar un par FSx HA en dos zonas de disponibilidad diferentes. Se puede configurar un par de alta disponibilidad (HA) en espera de recuperación ante desastres para la continuidad del negocio en una región diferente si se requiere una distancia específica entre el servidor principal y el de espera. Un clúster FSx HA siempre se aprovisiona en un par de HA que se refleja sincronizado en un par de sistemas de archivos activos-pasivos para proporcionar redundancia a nivel de almacenamiento.
-
Ubicación de datos y registros de PostgreSQL. Las implementaciones típicas de PostgreSQL comparten el mismo directorio raíz o volúmenes para los archivos de datos y registro. En nuestras pruebas y validaciones, hemos separado los datos y registros de PostgreSQL en dos volúmenes separados para mejorar el rendimiento. Se utiliza un enlace suave en el directorio de datos para señalar el directorio de registro o el volumen que aloja los registros WAL de PostgreSQL y los registros WAL archivados.
-
Temporizador de retraso en el inicio del servicio PostgreSQL. Esta solución utiliza volúmenes montados NFS para almacenar el archivo de base de datos PostgreSQL y los archivos de registro WAL. Durante el reinicio del host de una base de datos, es posible que el servicio PostgreSQL intente iniciarse mientras el volumen no esté montado. Esto provoca un error al iniciar el servicio de base de datos. Se necesita un retraso del temporizador de 10 a 15 segundos para que la base de datos PostgreSQL se inicie correctamente.
-
RPO/RTO para la continuidad del negocio. La replicación de datos de FSx desde el servidor principal al servidor en espera para DR se basa en ASYNC, lo que significa que el RPO depende de la frecuencia de las copias de seguridad de Snapshot y de la replicación de SnapMirror . Una mayor frecuencia de copia de Snapshot y de replicación de SnapMirror reduce el RPO. Por lo tanto, existe un equilibrio entre la posible pérdida de datos en caso de desastre y el coste incremental de almacenamiento. Hemos determinado que la copia de instantáneas y la replicación de SnapMirror se pueden implementar en intervalos de tan solo 5 minutos para RPO, y PostgreSQL generalmente se puede recuperar en el sitio de espera de DR en menos de un minuto para RTO.
-
Copia de seguridad de la base de datos. Después de implementar o migrar una base de datos PostgreSQL al almacenamiento de AWS FSx desde un centro de datos local, los datos se sincronizan automáticamente y se reflejan en el par FSx HA para su protección. Los datos están aún más protegidos con un sitio de reserva replicado en caso de desastre. Para la retención de copias de seguridad o la protección de datos a largo plazo, NetApp recomienda usar la utilidad pg_basebackup de PostgreSQL incorporada para ejecutar una copia de seguridad completa de la base de datos que se pueda trasladar al almacenamiento de blobs S3.
Implementación de la solución
La implementación de esta solución se puede completar automáticamente utilizando el kit de herramientas de automatización basado en Ansible de NetApp siguiendo las instrucciones detalladas que se detallan a continuación.
-
Lea las instrucciones en el kit de herramientas de automatización READme.md"na_postgresql_aws_deploy_hadr" .
-
Mire el siguiente video tutorial.
-
Configurar los archivos de parámetros necesarios(
hosts,host_vars/host_name.yml,fsx_vars.yml) introduciendo parámetros específicos del usuario en la plantilla en las secciones correspondientes. Luego use el botón Copiar para copiar archivos al host del controlador Ansible.
Requisitos previos para la implementación automatizada
La implementación requiere los siguientes requisitos previos.
-
Se ha configurado una cuenta de AWS y se han creado los segmentos de red y VPC necesarios dentro de su cuenta de AWS.
-
Desde la consola de AWS EC2, debe implementar dos instancias de EC2 Linux, una como servidor de base de datos PostgreSQL principal en el sitio de recuperación ante desastres principal y otra en el sitio de recuperación ante desastres en espera. Para lograr redundancia computacional en los sitios de recuperación ante desastres principal y en espera, implemente dos instancias EC2 Linux adicionales como servidores de base de datos PostgreSQL en espera. Consulte el diagrama de arquitectura en la sección anterior para obtener más detalles sobre la configuración del entorno. Revise también el"Guía del usuario para instancias de Linux" Para más información.
-
Desde la consola de AWS EC2, implemente dos clústeres de alta disponibilidad de almacenamiento FSx ONTAP para alojar los volúmenes de base de datos PostgreSQL. Si no está familiarizado con la implementación del almacenamiento de FSx, consulte la documentación"Creación de sistemas de archivos FSx ONTAP" para obtener instrucciones paso a paso.
-
Construya una máquina virtual Centos Linux para alojar el controlador Ansible. El controlador Ansible puede ubicarse localmente o en la nube de AWS. Si está ubicado localmente, debe tener conectividad SSH a la VPC, las instancias EC2 de Linux y los clústeres de almacenamiento FSx.
-
Configure el controlador Ansible como se describe en la sección "Configurar el nodo de control Ansible para implementaciones CLI en RHEL/CentOS" desde el recurso"Introducción a la automatización de soluciones de NetApp" .
-
Clone una copia del kit de herramientas de automatización del sitio público de GitHub de NetApp .
git clone https://github.com/NetApp-Automation/na_postgresql_aws_deploy_hadr.git-
Desde el directorio raíz del kit de herramientas, ejecute los playbooks necesarios para instalar las colecciones y bibliotecas necesarias para el controlador Ansible.
ansible-playbook -i hosts requirements.ymlansible-galaxy collection install -r collections/requirements.yml --force --force-with-deps-
Recupere los parámetros de instancia EC2 FSx necesarios para el archivo de variables de host de la base de datos
host_vars/*y el archivo de variables globalesfsx_vars.ymlconfiguración.
Configurar el archivo de hosts
Ingrese la dirección IP de administración del clúster FSx ONTAP principal y los nombres de hosts de las instancias EC2 en el archivo de hosts.
# Primary FSx cluster management IP address [fsx_ontap] 172.30.15.33
# Primary PostgreSQL DB server at primary site where database is initialized at deployment time [postgresql] psql_01p ansible_ssh_private_key_file=psql_01p.pem
# Primary PostgreSQL DB server at standby site where postgresql service is installed but disabled at deployment # Standby DB server at primary site, to setup this server comment out other servers in [dr_postgresql] # Standby DB server at standby site, to setup this server comment out other servers in [dr_postgresql] [dr_postgresql] -- psql_01s ansible_ssh_private_key_file=psql_01s.pem #psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
Configure el archivo host_name.yml en la carpeta host_vars
# Add your AWS EC2 instance IP address for the respective PostgreSQL server host
ansible_host: "10.61.180.15"
# "{{groups.postgresql[0]}}" represents first PostgreSQL DB server as defined in PostgreSQL hosts group [postgresql]. For concurrent multiple PostgreSQL DB servers deployment, [0] will be incremented for each additional DB server. For example, "{{groups.posgresql[1]}}" represents DB server 2, "{{groups.posgresql[2]}}" represents DB server 3 ... As a good practice and the default, two volumes are allocated to a PostgreSQL DB server with corresponding /pgdata, /pglogs mount points, which store PostgreSQL data, and PostgreSQL log files respectively. The number and naming of DB volumes allocated to a DB server must match with what is defined in global fsx_vars.yml file by src_db_vols, src_archivelog_vols parameters, which dictates how many volumes are to be created for each DB server. aggr_name is aggr1 by default. Do not change. lif address is the NFS IP address for the SVM where PostgreSQL server is expected to mount its database volumes. Primary site servers from primary SVM and standby servers from standby SVM.
host_datastores_nfs:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
# Add swap space to EC2 instance, that is equal to size of RAM up to 16G max. Determine the number of blocks by dividing swap size in MB by 128.
swap_blocks: "128"
# Postgresql user configurable parameters
psql_port: "5432"
buffer_cache: "8192MB"
archive_mode: "on"
max_wal_size: "5GB"
client_address: "172.30.15.0/24"Configure el archivo global fsx_vars.yml en la carpeta vars
########################################################################
###### PostgreSQL HADR global user configuration variables ######
###### Consolidate all variables from FSx, Linux, and postgresql ######
########################################################################
###########################################
### Ontap env specific config variables ###
###########################################
####################################################################################################
# Variables for SnapMirror Peering
####################################################################################################
#Passphrase for cluster peering authentication
passphrase: "xxxxxxx"
#Please enter destination or standby FSx cluster name
dst_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter destination or standby FSx cluster management IP
dst_cluster_ip: "172.30.15.90"
#Please enter destination or standby FSx cluster inter-cluster IP
dst_inter_ip: "172.30.15.13"
#Please enter destination or standby SVM name to create mirror relationship
dst_vserver: "dr"
#Please enter destination or standby SVM management IP
dst_vserver_mgmt_lif: "172.30.15.88"
#Please enter destination or standby SVM NFS lif
dst_nfs_lif: "172.30.15.88"
#Please enter source or primary FSx cluster name
src_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter source or primary FSx cluster management IP
src_cluster_ip: "172.30.15.20"
#Please enter source or primary FSx cluster inter-cluster IP
src_inter_ip: "172.30.15.5"
#Please enter source or primary SVM name to create mirror relationship
src_vserver: "prod"
#Please enter source or primary SVM management IP
src_vserver_mgmt_lif: "172.30.15.115"
#####################################################################################################
# Variable for PostgreSQL Volumes, lif - source or primary FSx NFS lif address
#####################################################################################################
src_db_vols:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
src_archivelog_vols:
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
#Names of the Nodes in the ONTAP Cluster
nfs_export_policy: "default"
#####################################################################################################
### Linux env specific config variables ###
#####################################################################################################
#NFS Mount points for PostgreSQL DB volumes
mount_points:
- "/pgdata"
- "/pglogs"
#RedHat subscription username and password
redhat_sub_username: "xxxxx"
redhat_sub_password: "xxxxx"
####################################################
### DB env specific install and config variables ###
####################################################
#The latest version of PostgreSQL RPM is pulled/installed and config file is deployed from a preconfigured template
#Recovery type and point: default as all logs and promote and leave all PITR parameters blankImplementación de PostgreSQL y configuración de HA/DR
Las siguientes tareas implementan el servicio del servidor de base de datos PostgreSQL e inicializan la base de datos en el sitio principal en el host del servidor de base de datos EC2 principal. Luego se configura un servidor host de base de datos EC2 principal en espera en el sitio en espera. Finalmente, la replicación del volumen de base de datos se configura desde el clúster FSx del sitio principal al clúster FSx del sitio en espera para la recuperación ante desastres.
-
Cree volúmenes de base de datos en el clúster FSx principal y configure PostgreSQL en el host de la instancia EC2 principal.
ansible-playbook -i hosts postgresql_deploy.yml -u ec2-user --private-key psql_01p.pem -e @vars/fsx_vars.yml -
Configurar el host de instancia EC2 de DR en espera.
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.yml -
Configurar el emparejamiento de clústeres FSx ONTAP y la replicación del volumen de la base de datos.
ansible-playbook -i hosts fsx_replication_setup.yml -e @vars/fsx_vars.yml -
Consolide los pasos anteriores en una implementación de PostgreSQL de un solo paso y una configuración de HA/DR.
ansible-playbook -i hosts postgresql_hadr_setup.yml -u ec2-user -e @vars/fsx_vars.yml -
Para configurar un host de base de datos PostgreSQL en espera en el sitio principal o en espera, comente todos los demás servidores en la sección del archivo de hosts [dr_postgresql] y luego ejecute el libro de estrategias postgresql_standby_setup.yml con el host de destino respectivo (como psql_01ps o una instancia de cómputo EC2 en espera en el sitio principal). Asegúrese de que exista un archivo de parámetros de host como
psql_01ps.ymlestá configurado bajo elhost_varsdirectorio.[dr_postgresql] -- #psql_01s ansible_ssh_private_key_file=psql_01s.pem psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01ps.pem -e @vars/fsx_vars.ymlCopia de seguridad de instantáneas de bases de datos PostgreSQL y replicación en un sitio en espera
La copia de seguridad y la replicación de la instantánea de la base de datos PostgreSQL en el sitio en espera se pueden controlar y ejecutar en el controlador Ansible con un intervalo definido por el usuario. Hemos validado que el intervalo puede ser tan bajo como 5 minutos. Por lo tanto, en caso de falla en el sitio principal, hay 5 minutos de posible pérdida de datos si la falla ocurre justo antes de la próxima copia de seguridad de instantánea programada.
*/15 * * * * /home/admin/na_postgresql_aws_deploy_hadr/data_log_snap.shConmutación por error al sitio en espera para recuperación ante desastres
Para probar el sistema HA/DR de PostgreSQL como un ejercicio de DR, ejecute la conmutación por error y la recuperación de la base de datos de PostgreSQL en la instancia de base de datos EC2 en espera principal en el sitio en espera ejecutando el siguiente manual. En un escenario de recuperación ante desastres real, ejecute lo mismo para una conmutación por error real al sitio de recuperación ante desastres.
ansible-playbook -i hosts postgresql_failover.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.ymlResincronizar volúmenes de bases de datos replicadas después de la prueba de conmutación por error
Ejecute la resincronización después de la prueba de conmutación por error para restablecer la replicación de SnapMirror del volumen de la base de datos.
ansible-playbook -i hosts postgresql_standby_resync.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.ymlConmutación por error del servidor de base de datos EC2 principal al servidor de base de datos EC2 en espera debido a una falla de la instancia de cómputo de EC2
NetApp recomienda ejecutar una conmutación por error manual o utilizar un clúster de sistema operativo bien establecido que podría requerir una licencia.
Dónde encontrar información adicional
Para obtener más información sobre la información que se describe en este documento, revise los siguientes documentos y/o sitios web:
-
Amazon FSx ONTAP
-
Amazon EC2
-
Automatización de soluciones de NetApp