

TR-5000: Copia de seguridad, recuperación y clonación de bases de datos PostgreSQL en ONTAP con SnapCenter
 Sugerir cambios
Sugerir cambios
Allen Cao, Niyaz Mohamed, NetApp
La solución proporciona una descripción general y detalles para la copia de seguridad, la recuperación y la clonación de bases de datos PostgreSQL en el almacenamiento ONTAP en la nube pública o en las instalaciones a través de la herramienta de interfaz de usuario de administración de bases de datos NetApp SnapCenter .
Objetivo
El software NetApp SnapCenter software es una plataforma empresarial fácil de usar para coordinar y administrar de forma segura la protección de datos en aplicaciones, bases de datos y sistemas de archivos. Simplifica la gestión del ciclo de vida de las copias de seguridad, la restauración y la clonación al delegar estas tareas a los propietarios de las aplicaciones sin sacrificar la capacidad de supervisar y regular la actividad en los sistemas de almacenamiento. Al aprovechar la gestión de datos basada en almacenamiento, se permite un mayor rendimiento y disponibilidad, así como una reducción de los tiempos de prueba y desarrollo.
En esta documentación, mostramos la protección y la gestión de bases de datos PostgreSQL en el almacenamiento NetApp ONTAP en la nube pública o en las instalaciones con una herramienta de interfaz de usuario SnapCenter muy fácil de usar.
Esta solución aborda los siguientes casos de uso:
-
Copia de seguridad y recuperación de bases de datos PostgreSQL implementadas en el almacenamiento NetApp ONTAP en la nube pública o en las instalaciones.
-
Administre instantáneas de bases de datos PostgreSQL y copias de clones para acelerar el desarrollo de aplicaciones y mejorar la gestión del ciclo de vida de los datos.
Audiencia
Esta solución está destinada a las siguientes personas:
-
Un administrador de bases de datos que desea implementar bases de datos PostgreSQL en el almacenamiento NetApp ONTAP .
-
Un arquitecto de soluciones de bases de datos que desea probar cargas de trabajo de PostgreSQL en el almacenamiento NetApp ONTAP .
-
Un administrador de almacenamiento que desee implementar y administrar bases de datos PostgreSQL en el almacenamiento NetApp ONTAP .
-
Un propietario de una aplicación que desea instalar una base de datos PostgreSQL en el almacenamiento NetApp ONTAP .
Entorno de prueba y validación de soluciones
Las pruebas y la validación de esta solución se realizaron en un entorno de laboratorio que podría no coincidir con el entorno de implementación final. Ver la secciónFactores clave a considerar en la implementación Para más información.
Arquitectura
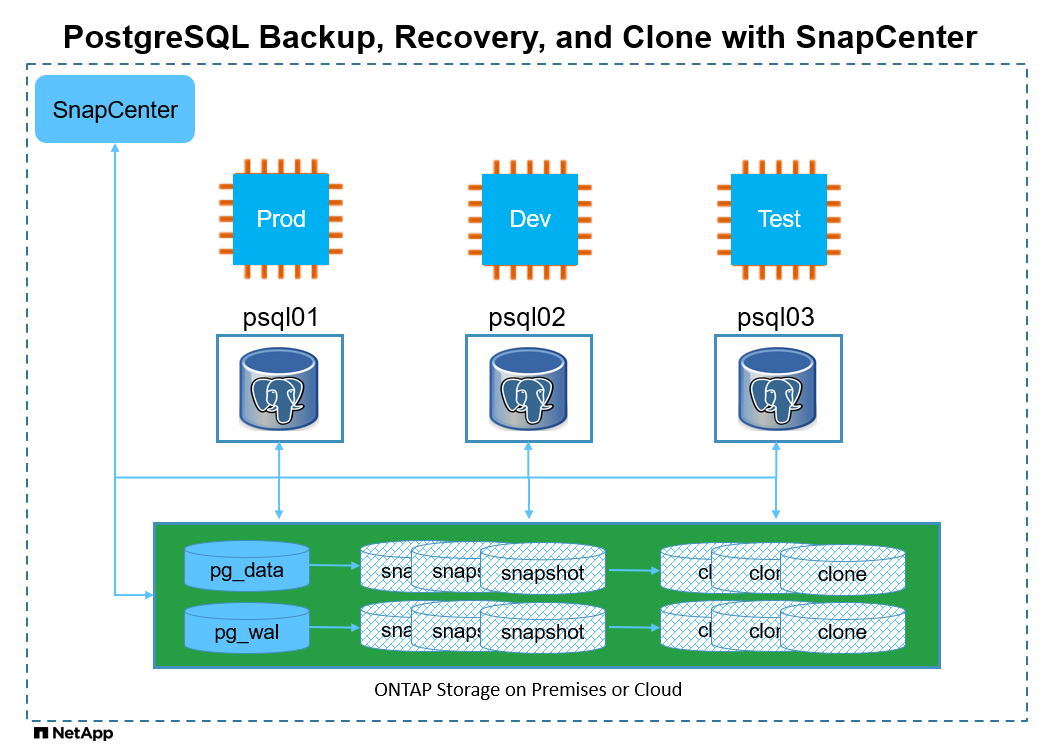
Componentes de hardware y software
Hardware |
||
NetApp AFF A220 |
Versión 9.12.1P2 |
Estante de discos DS224-12, módulo IOM12E, 24 discos / capacidad de 12 TiB |
Clúster de VMware vSphere |
Versión 6.7 |
4 nodos ESXi de cómputo NetApp HCI H410C |
Software |
||
Red Hat Linux |
RHEL Linux 8.6 (LVM) - x64 Gen2 |
Se implementó una suscripción a RedHat para realizar pruebas |
Servidor de Windows |
Centro de datos 2022; Hotpatch de AE - x64 Gen2 |
Alojamiento del servidor SnapCenter |
Base de datos PostgreSQL |
Versión 14.13 |
Clúster de bases de datos PostgreSQL poblado con el esquema tpcc de HammerDB |
Servidor SnapCenter |
Versión 6.0 |
Implementación de grupos de trabajo |
Abrir JDK |
Versión java-11-openjdk |
Requisito del complemento SnapCenter en las máquinas virtuales de base de datos |
Sistema Nacional de Archivos |
Versión 3.0 |
Separar datos y registros en diferentes puntos de montaje |
Ansible |
núcleo 2.16.2 |
Python 3.6.8 |
Configuración de la base de datos PostgreSQL en el entorno de laboratorio
Servidor |
Base de datos |
Almacenamiento de base de datos |
psql01 |
Servidor de base de datos principal |
/pgdata, /pglogs montajes de volumen NFS en almacenamiento ONTAP |
psql02 |
Clonar servidor de base de datos |
/pgdata_clone, /pglogs_clone El volumen de clon delgado de NFS se monta en el almacenamiento ONTAP |
Factores clave a considerar en la implementación
-
* Implementación de SnapCenter . * SnapCenter se puede implementar en un dominio de Windows o en un entorno de grupo de trabajo. Para la implementación basada en dominio, la cuenta de usuario del dominio debe ser una cuenta de administrador de dominio, o el usuario del dominio debe pertenecer al grupo de administradores locales en el servidor de alojamiento de SnapCenter .
-
Resolución de nombres. El servidor SnapCenter necesita resolver el nombre a la dirección IP para cada host del servidor de base de datos de destino administrado. Cada host del servidor de base de datos de destino debe resolver el nombre del servidor SnapCenter en la dirección IP. Si un servidor DNS no está disponible, agregue nombres a los archivos del host local para su resolución.
-
Configuración del grupo de recursos. El grupo de recursos en SnapCenter es una agrupación lógica de recursos similares que pueden respaldarse juntos. De esta forma, se simplifica y reduce el número de trabajos de backup en un entorno de bases de datos grandes.
-
Copia de seguridad independiente del registro de archivo y de la base de datos completa. La copia de seguridad completa de la base de datos incluye volúmenes de datos y volúmenes de registro, instantáneas de grupo consistentes. Una instantánea completa de base de datos frecuente implica un mayor consumo de almacenamiento, pero mejora el RTO. Una alternativa es realizar instantáneas de bases de datos completas con menos frecuencia y copias de seguridad de registros de archivo con mayor frecuencia, lo que consume menos almacenamiento y mejora el RPO, pero puede extender el RTO. Tenga en cuenta sus objetivos de RTO y RPO al configurar el esquema de respaldo. También hay un límite (1023) en la cantidad de copias de seguridad de instantáneas en un volumen.
-
Delegación de Privileges . Aproveche el control de acceso basado en roles integrado en la interfaz de usuario de SnapCenter para delegar privilegios a los equipos de aplicaciones y bases de datos si lo desea.
Implementación de la solución
Las siguientes secciones proporcionan procedimientos paso a paso para la implementación, configuración y copia de seguridad, recuperación y clonación de bases de datos PostgreSQL de SnapCenter en el almacenamiento de NetApp ONTAP en la nube pública o en las instalaciones locales.
Requisitos previos para la implementación
Details
-
La implementación requiere dos bases de datos PostgreSQL existentes que se ejecuten en el almacenamiento ONTAP , una como servidor de base de datos principal y la otra como servidor de base de datos clonado. Para obtener una referencia sobre la implementación de la base de datos PostgreSQL en ONTAP, consulte TR-4956:"Implementación automatizada de alta disponibilidad y recuperación ante desastres de PostgreSQL en AWS FSx/EC2" , buscando el manual de implementación automatizada de PostgreSQL en la instancia principal.
-
Aprovisione un servidor Windows para ejecutar la herramienta de interfaz de usuario SnapCenter de NetApp con la última versión. Consulte el siguiente enlace para obtener más detalles:"Instalar el servidor SnapCenter" .
Instalación y configuración de SnapCenter
Details
Recomendamos hacerlo online."Documentación del software SnapCenter" antes de continuar con la instalación y configuración de SnapCenter : . A continuación se proporciona un resumen de alto nivel de los pasos para la instalación y configuración del SnapCenter software para PostgreSQL en ONTAP.
-
Desde el servidor Windows de SnapCenter , descargue e instale el último JDK de Java desde"Obtenga Java para aplicaciones de escritorio" . Desactive el firewall de Windows.
-
Desde el servidor Windows de SnapCenter , descargue e instale o actualice los requisitos previos de SnapCenter 6.0 para Windows: PowerShell: PowerShell-7.4.3-win-x64.msi y el paquete de alojamiento .Net: dotnet-hosting-8.0.6-win.
-
Desde el servidor Windows de SnapCenter , descargue e instale la última versión (actualmente 6.0) del ejecutable de instalación de SnapCenter desde el sitio de soporte de NetApp :"NetApp | Soporte" .
-
Desde las máquinas virtuales de la base de datos, habilite la autenticación sin contraseña ssh para el usuario administrador
adminy sus privilegios de sudo sin contraseña. -
Desde las máquinas virtuales de la base de datos DB, detenga y deshabilite el demonio del firewall de Linux. Instalar java-11-openjdk.
-
Desde el servidor Windows de SnapCenter , inicie el navegador para iniciar sesión en SnapCenter con el usuario administrador local de Windows o las credenciales de usuario de dominio a través del puerto 8146.
-
Revisar
Get StartedMenú en línea.
-
En
Settings-Global Settings, controlarHypervisor Settingsy haga clic en Actualizar.
-
Si es necesario, ajuste
Session Timeoutpara la interfaz de usuario de SnapCenter en el intervalo deseado.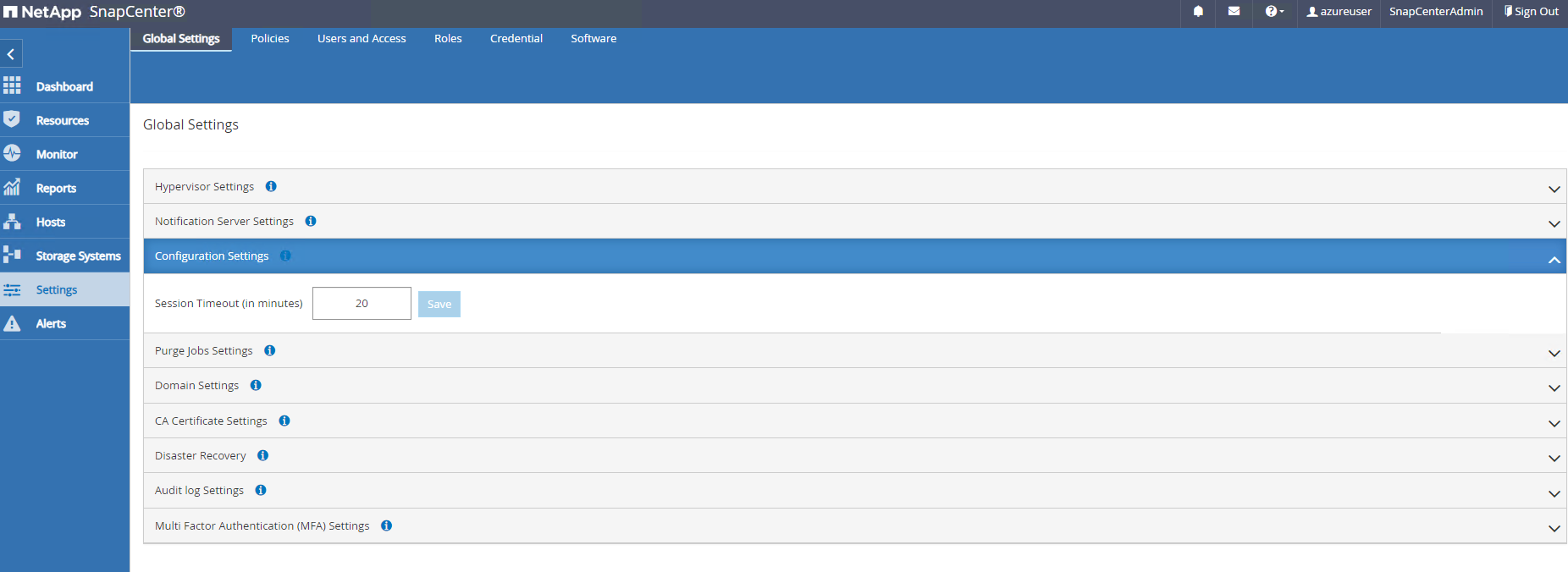
-
Agregue usuarios adicionales a SnapCenter si es necesario.
-
El
RolesLista de pestañas que enumeran los roles integrados que se pueden asignar a diferentes usuarios de SnapCenter . Los usuarios administradores también pueden crear roles personalizados con los privilegios deseados.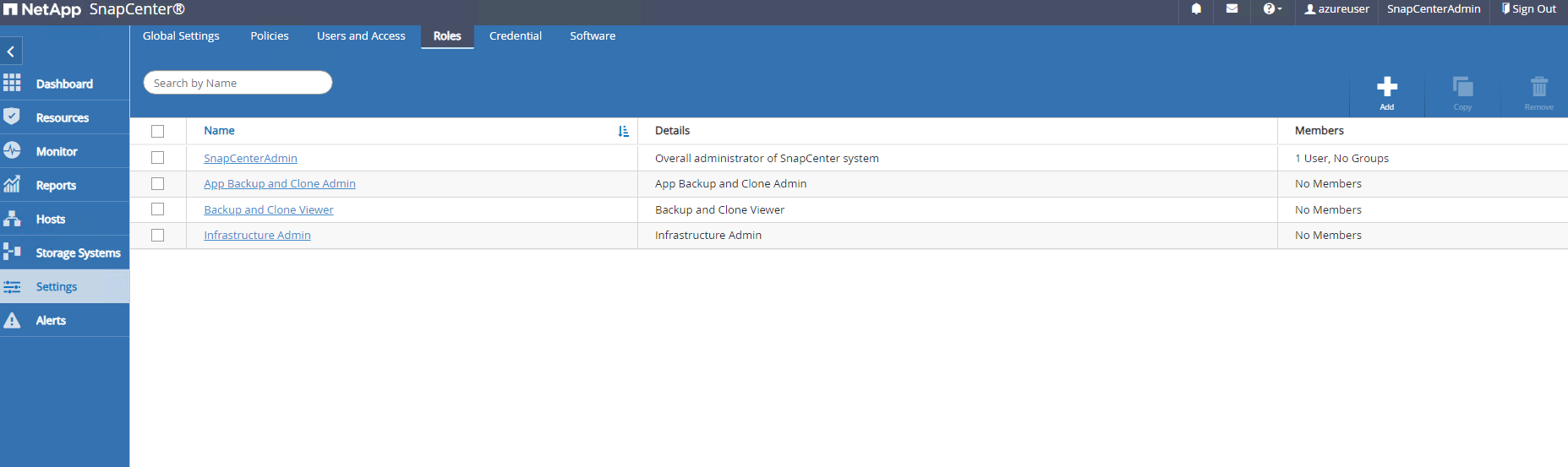
-
De
Settings-Credential, crea credenciales para los objetivos de administración de SnapCenter . En este caso de uso de demostración, son el usuario administrador de Linux para iniciar sesión en la máquina virtual del servidor de base de datos y las credenciales de Postgres para el acceso a PostgreSQL.

Restablecer la contraseña postgres del usuario PostgreSQL antes de crear la credencial. -
De
Storage Systemspestaña, agregarONTAP clustercon credenciales de administrador de clúster ONTAP . Para Azure NetApp Files, deberá crear una credencial específica para el acceso al grupo de capacidad.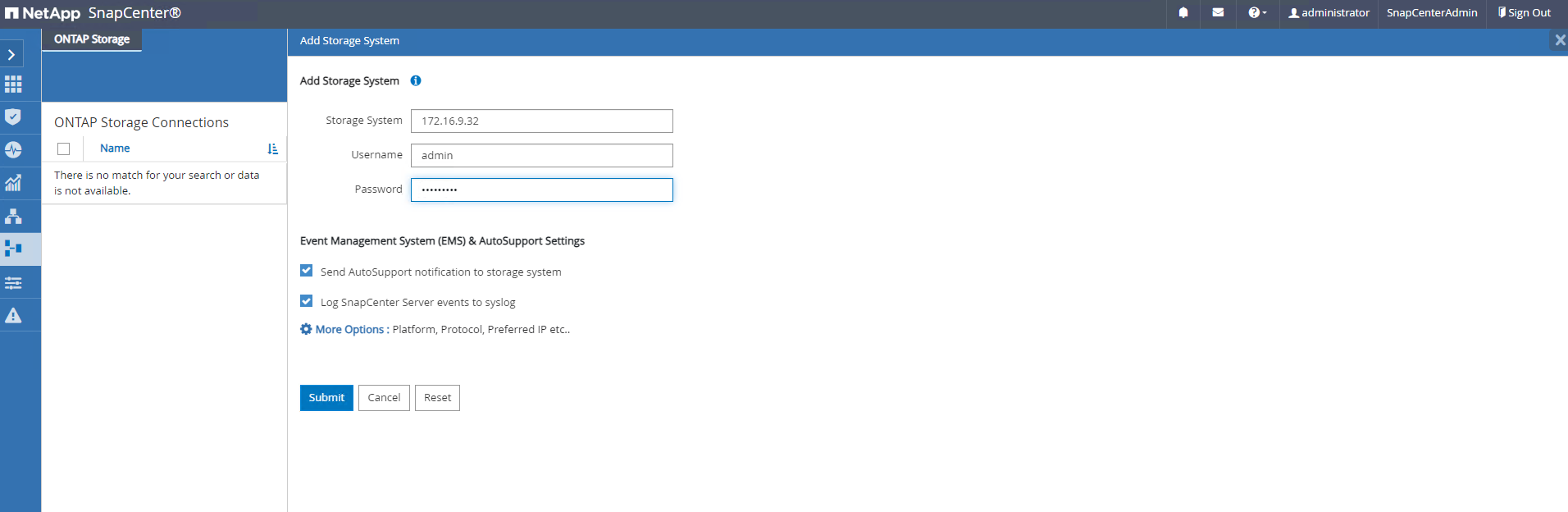
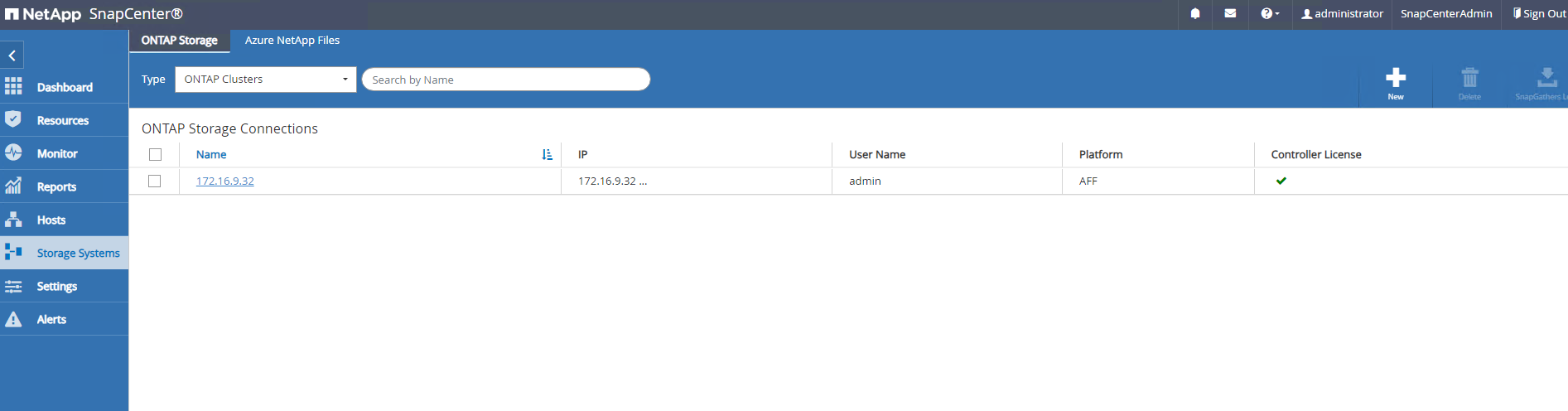
-
De
Hostspestaña, agregue máquinas virtuales de base de datos PostgreSQL, que instala el complemento SnapCenter para PostgreSQL en Linux.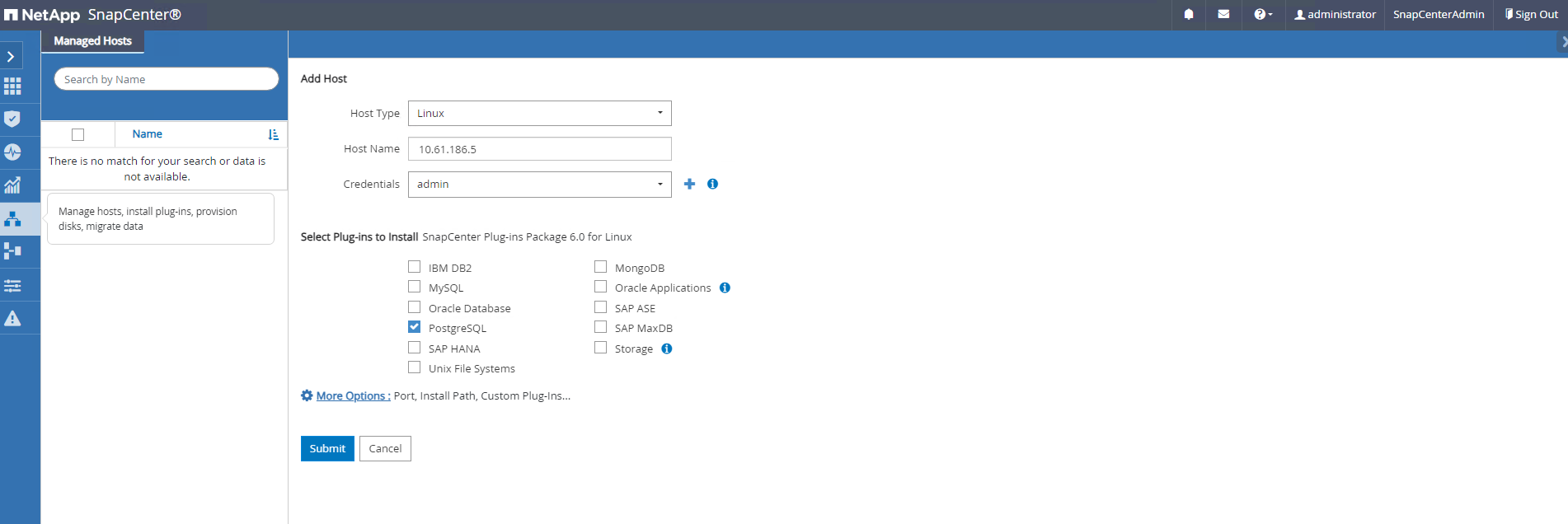
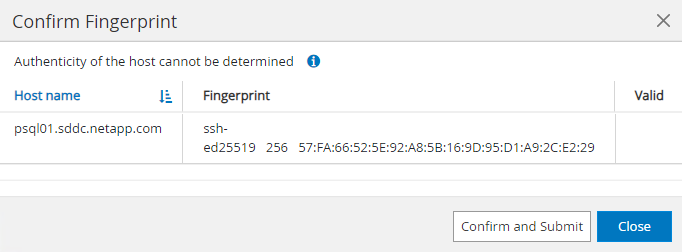
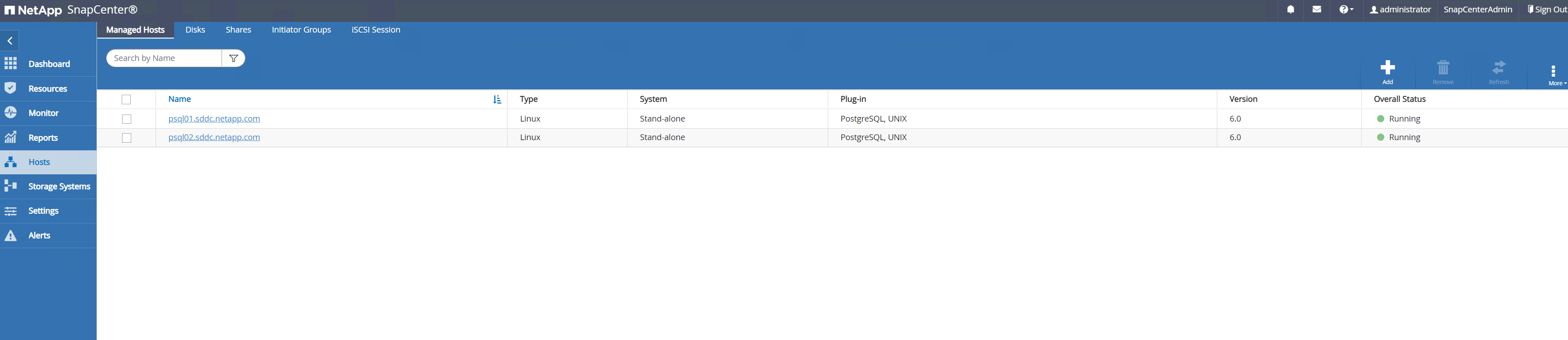
-
Una vez que el complemento de host está instalado en la máquina virtual del servidor de base de datos, las bases de datos en el host se descubren automáticamente y son visibles en
Resourcespestaña.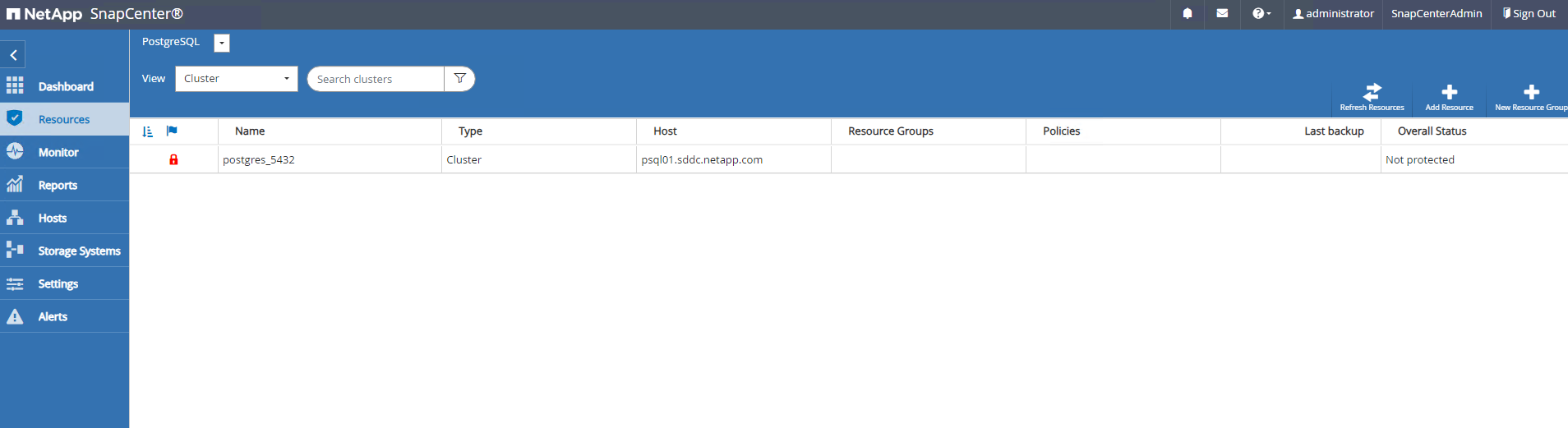
Copia de seguridad de la base de datos
Details
El clúster PostgreSQL autodescubierto inicial muestra un candado rojo junto a su nombre de clúster. Debe desbloquearse utilizando las credenciales de base de datos PostgreSQL creadas durante la configuración de SnapCenter en la sección anterior. Luego, debe crear y aplicar una política de respaldo para proteger la base de datos. Por último, ejecute la copia de seguridad manualmente o mediante un programador para crear una copia de seguridad SnapShot. La siguiente sección demuestra los procedimientos paso a paso.
-
Desbloquear el clúster PostgreSQL.
-
Navegando a
Resourcespestaña, que enumera el clúster PostgreSQL descubierto después de instalar el complemento SnapCenter en la máquina virtual de la base de datos. Inicialmente está bloqueado y elOverall Statusdel clúster de base de datos se muestra comoNot protected. -
Haga clic en el nombre del clúster y luego,
Configure Credentialspara abrir la página de configuración de credenciales.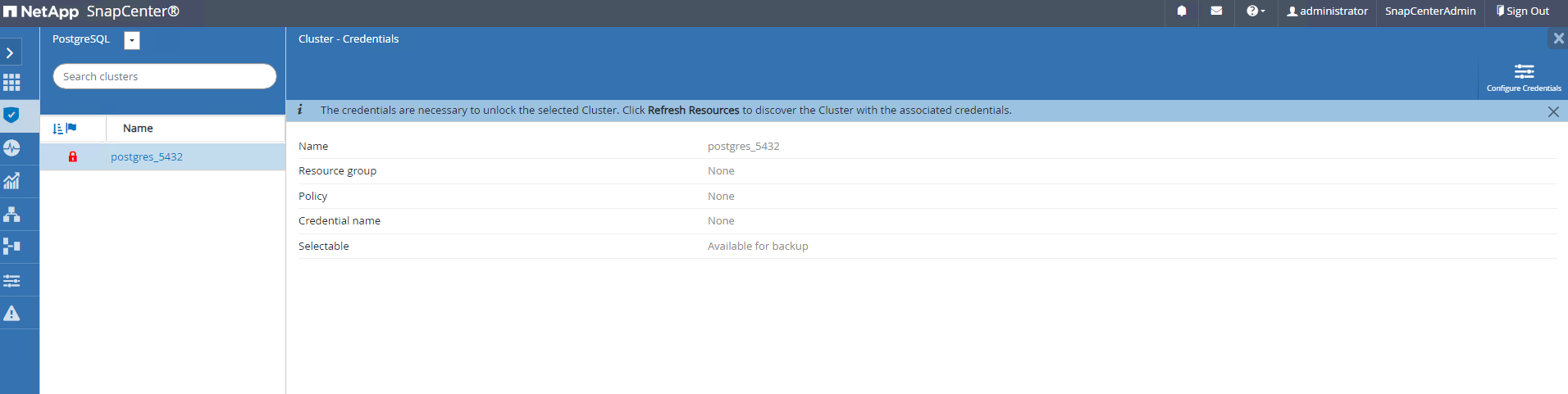
-
Elegir
postgrescredencial creada durante la configuración anterior de SnapCenter .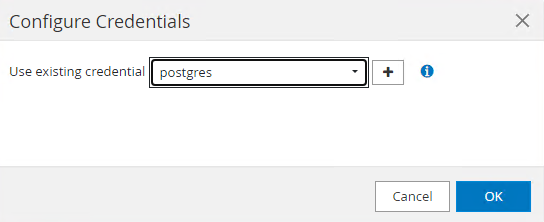
-
Una vez aplicada la credencial, el clúster se desbloqueará.

-
-
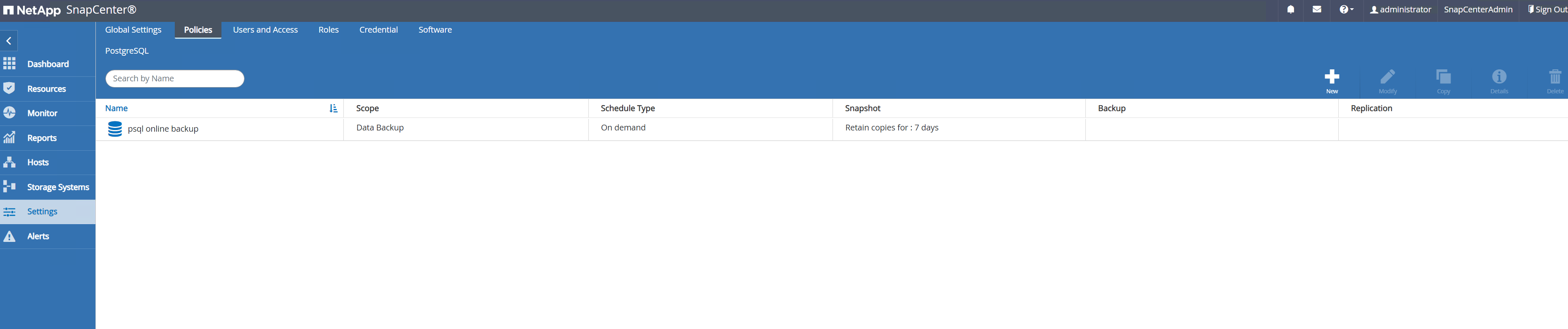
Crear una política de copia de seguridad de PostgreSQL.
-
Navegar a
Setting-Policesy haga clic enNewpara crear una política de respaldo.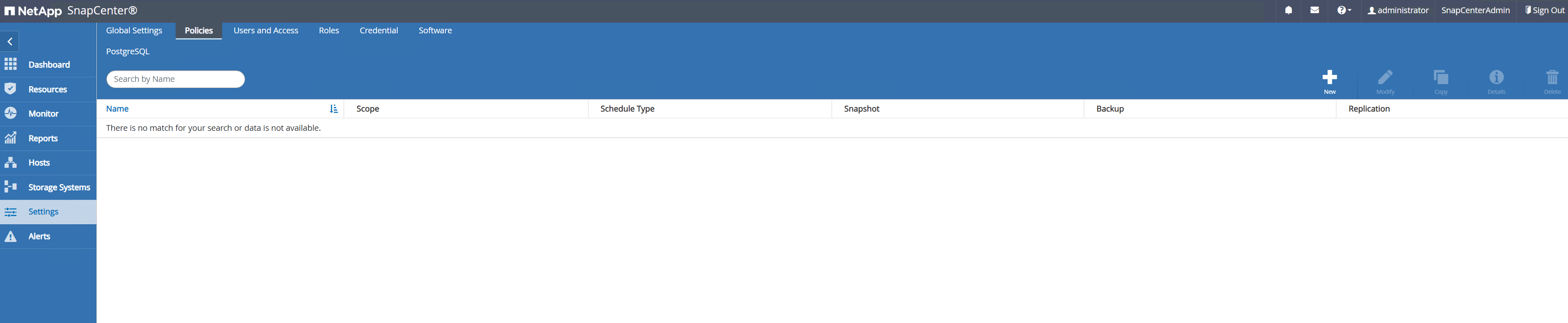
-
Nombra la política de respaldo.
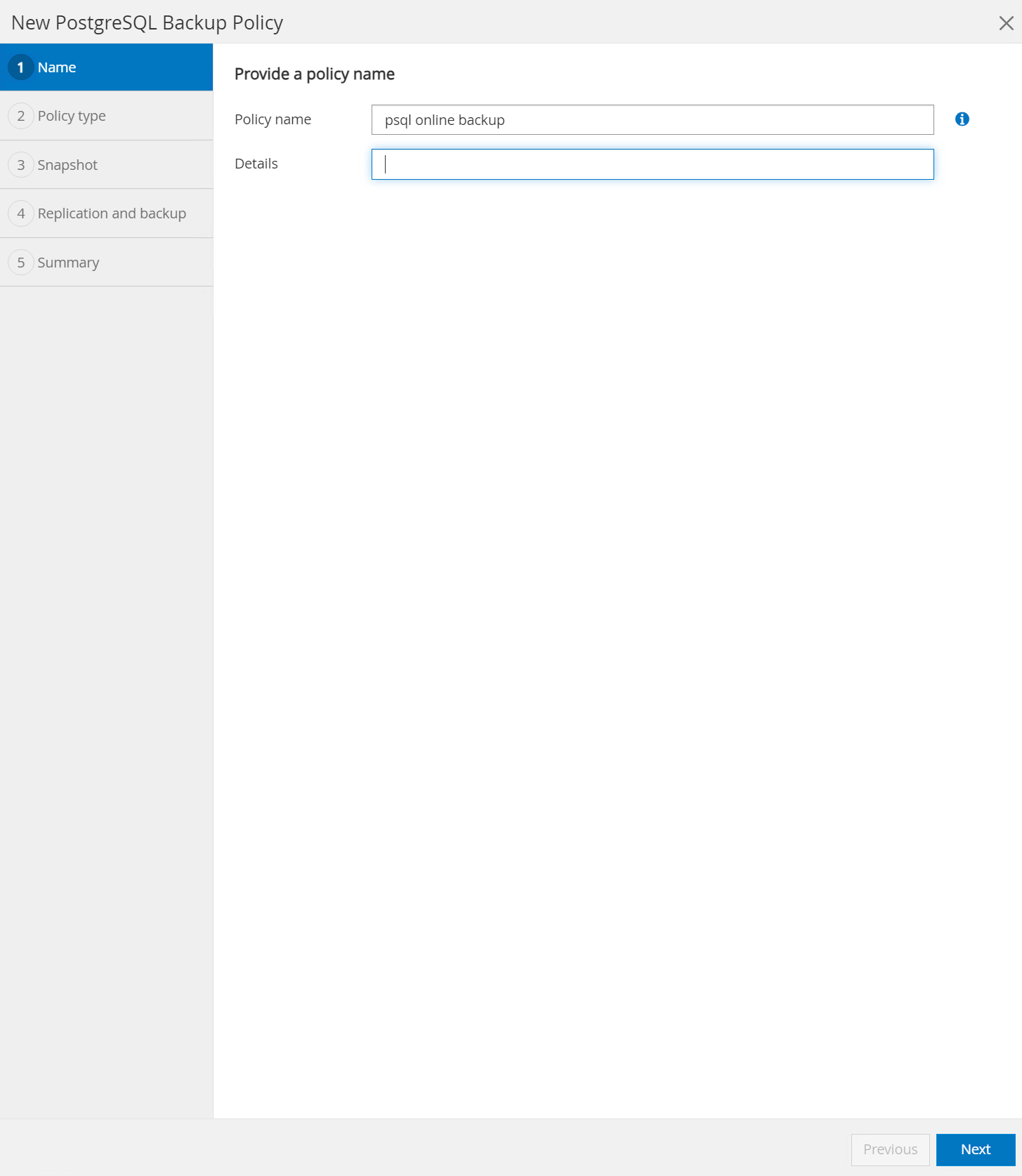
-
Elija el tipo de almacenamiento. La configuración de copia de seguridad predeterminada debería funcionar bien para la mayoría de los escenarios.
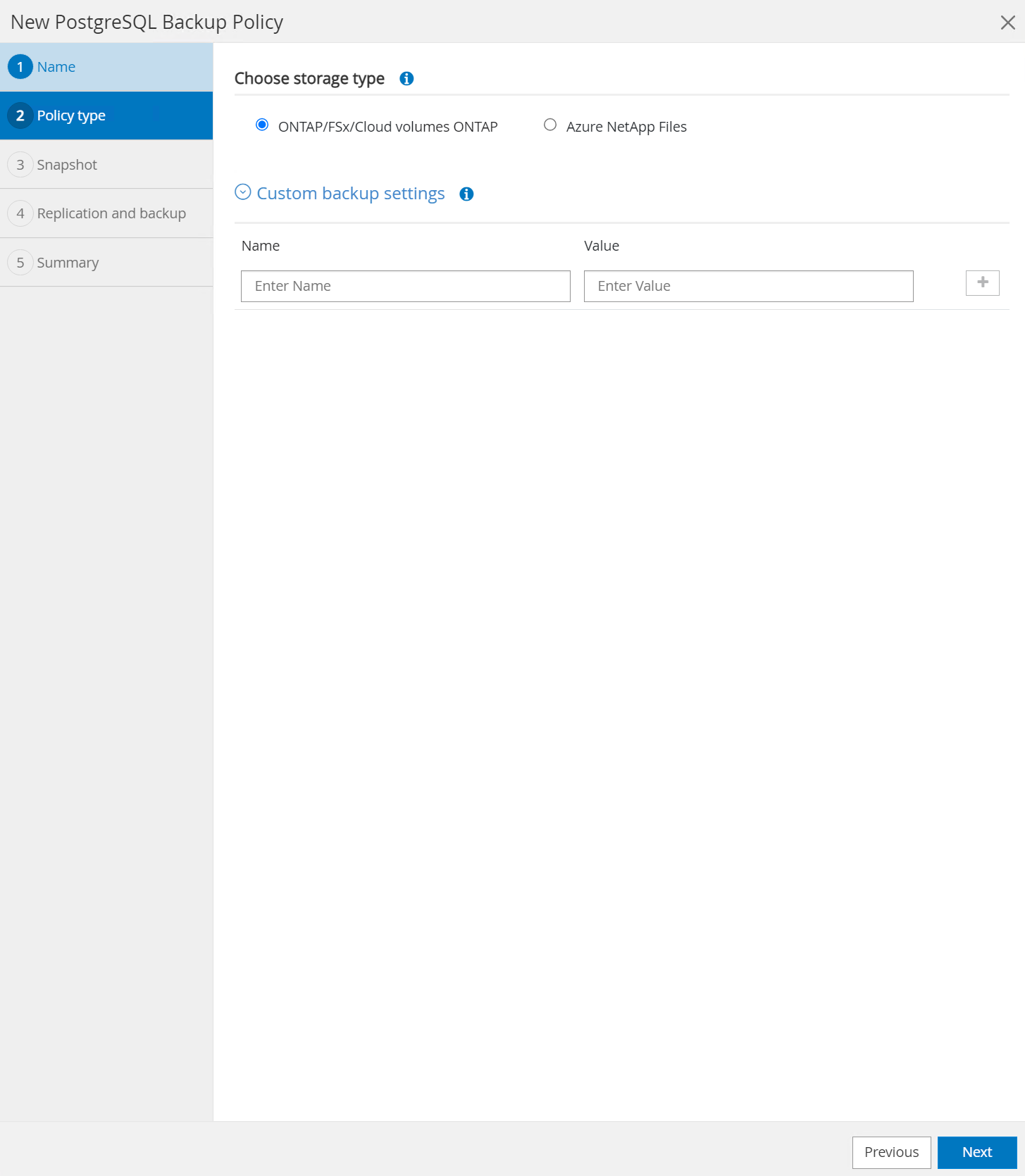
-
Defina la frecuencia de las copias de seguridad y la retención de SnapShot.
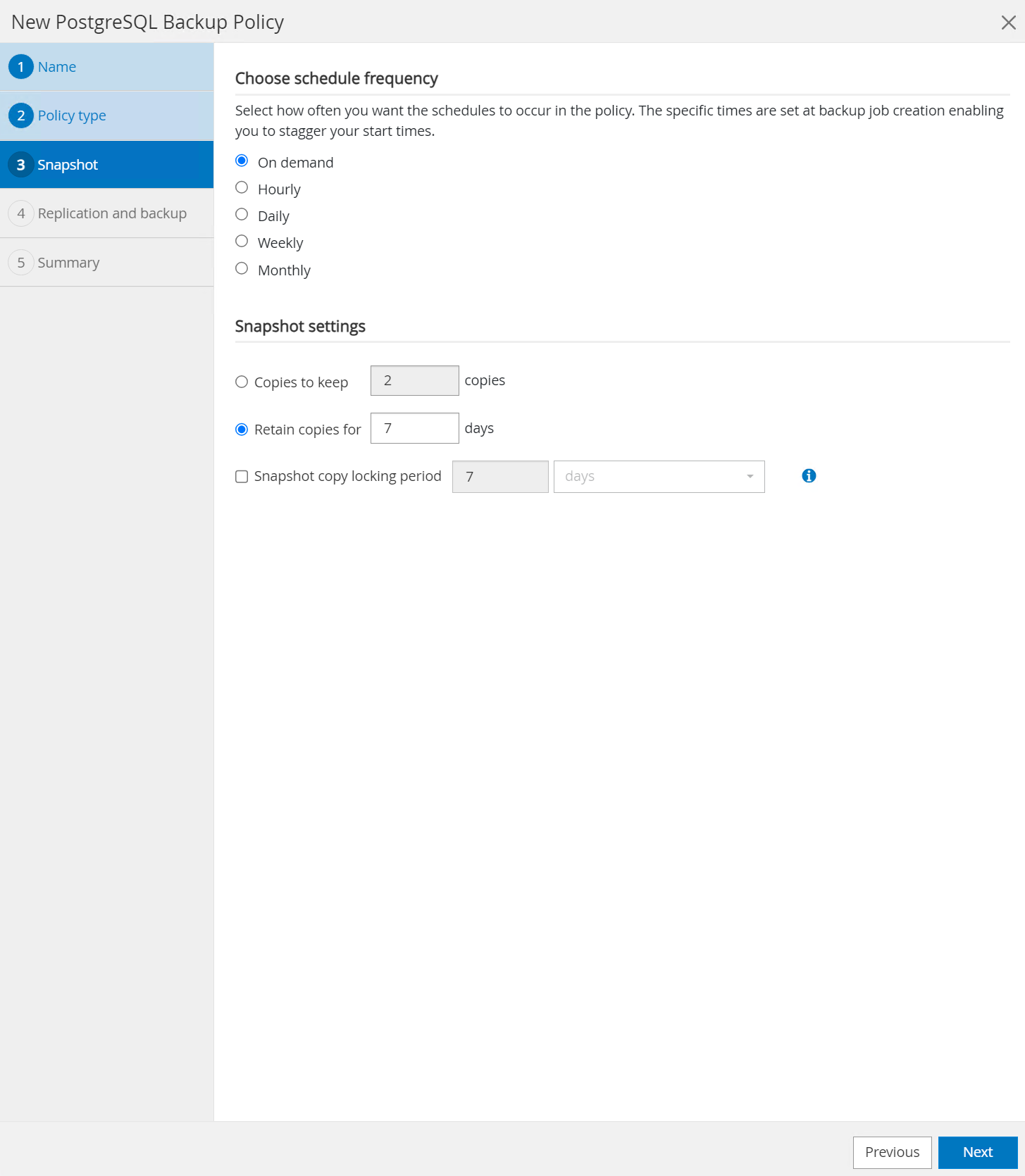
-
Opción para seleccionar la replicación secundaria si los volúmenes de la base de datos se replican en una ubicación secundaria.
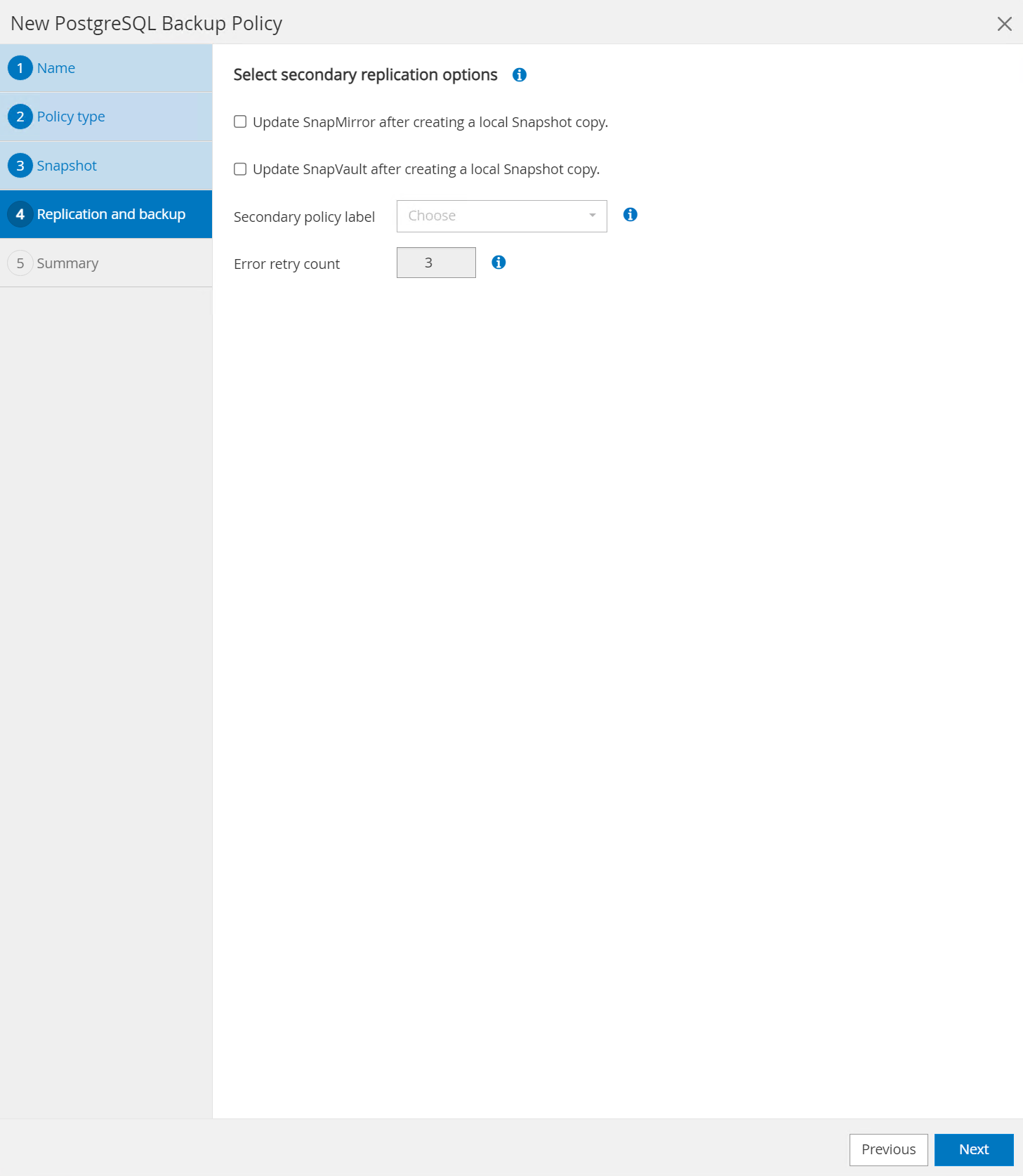
-
Revise el resumen y
Finishpara crear la política de respaldo.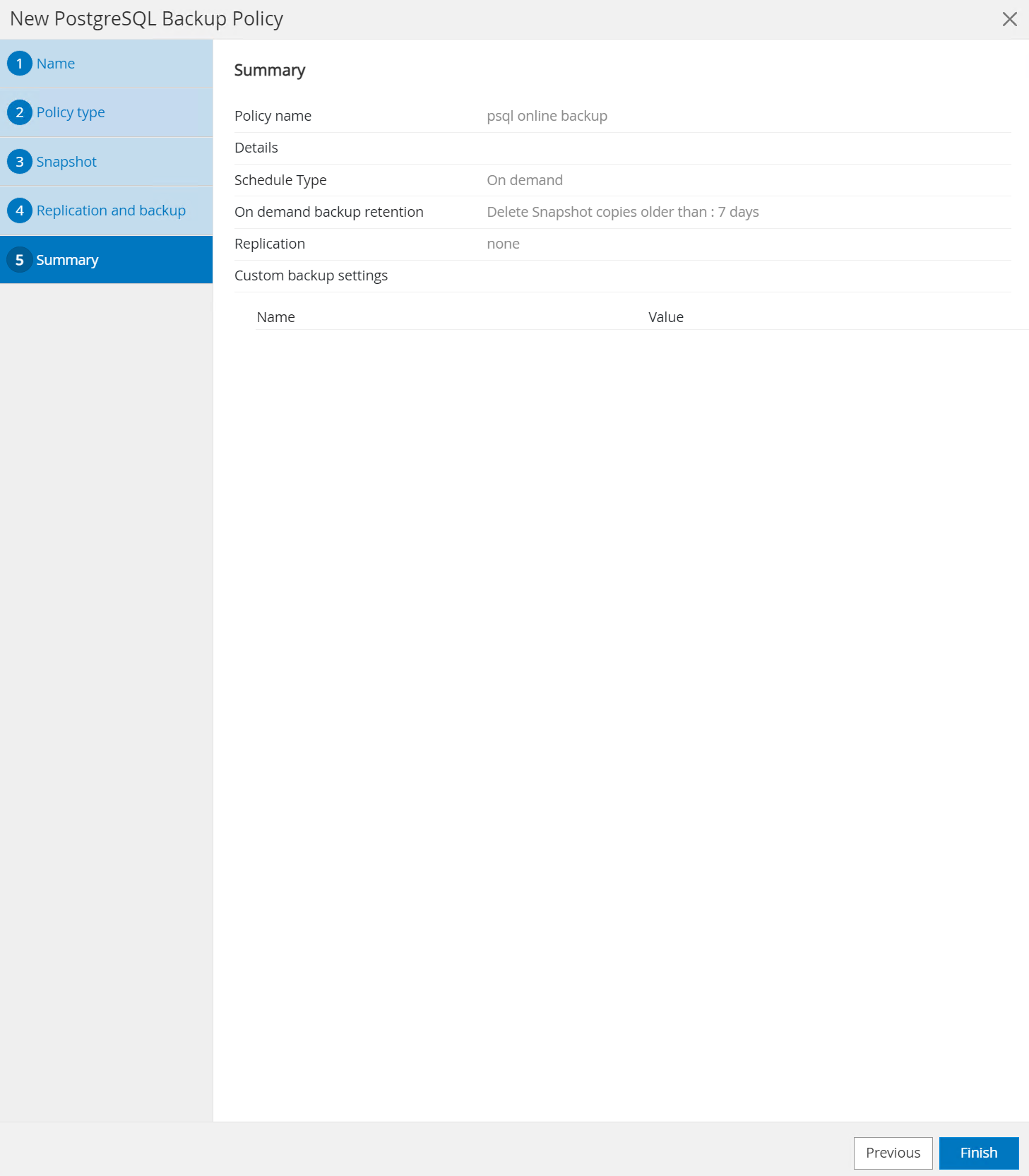
-
-
Aplicar la política de respaldo para proteger la base de datos PostgreSQL.
-
Navegar de regreso a
ResourcePestaña, haga clic en el nombre del clúster para iniciar el flujo de trabajo de protección del clúster PostgreSQL.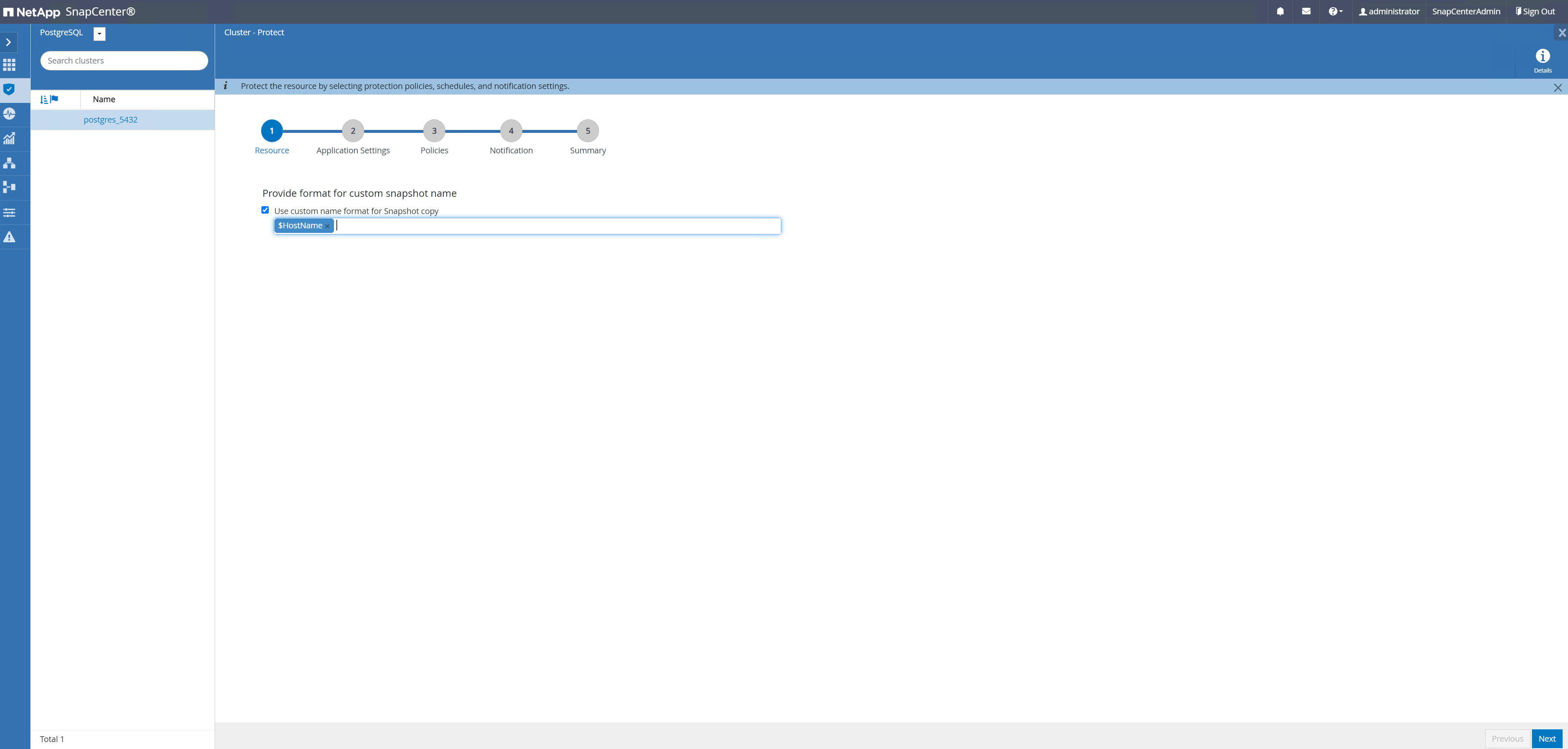
-
Aceptar predeterminado
Application Settings. Muchas de las opciones de esta página no se aplican al objetivo descubierto automáticamente.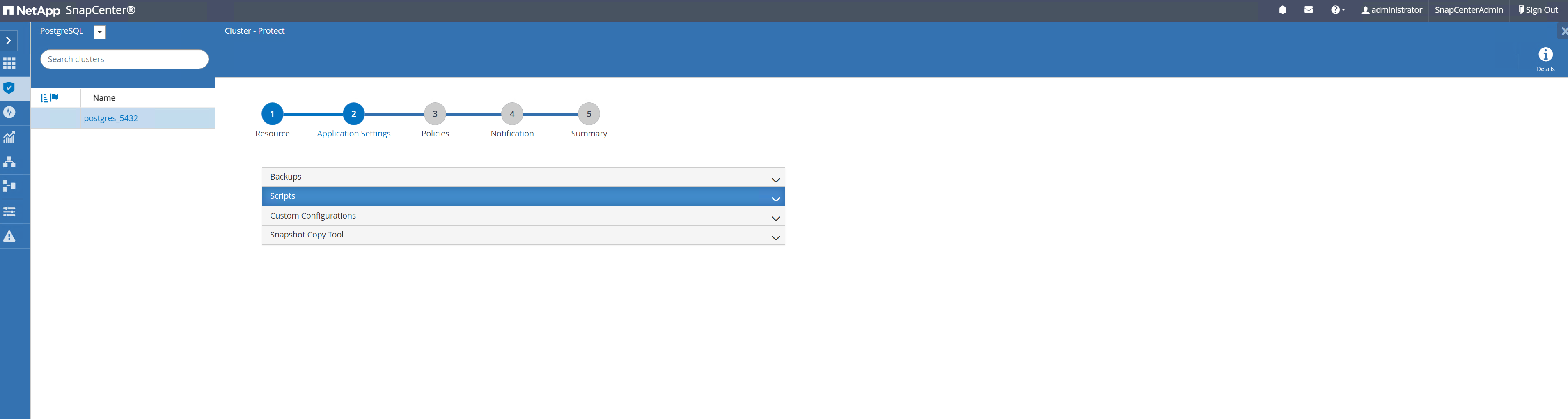
-
Aplicar la política de copia de seguridad recién creada. Agregue un programa de respaldo si es necesario.
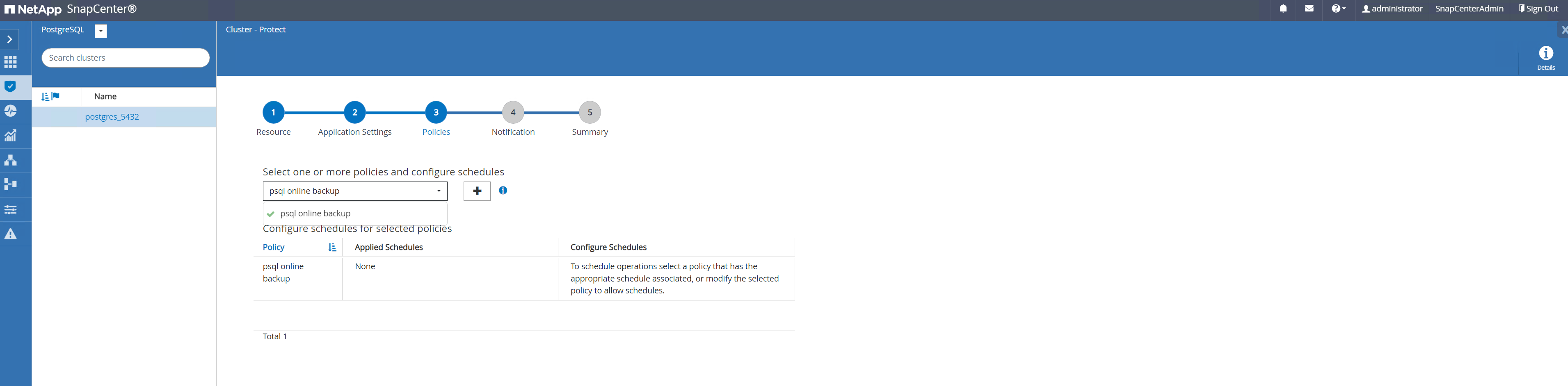
-
Proporcionar configuración de correo electrónico si se requiere notificación de respaldo.
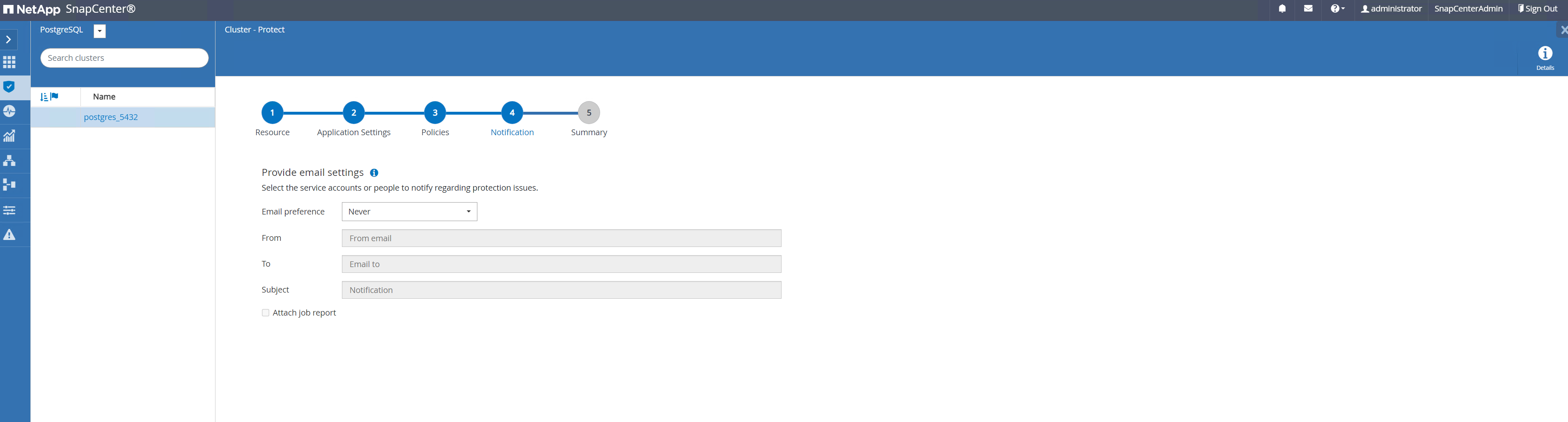
-
Resumen de la revisión y
Finishpara implementar la política de respaldo. Ahora el clúster PostgreSQL está protegido.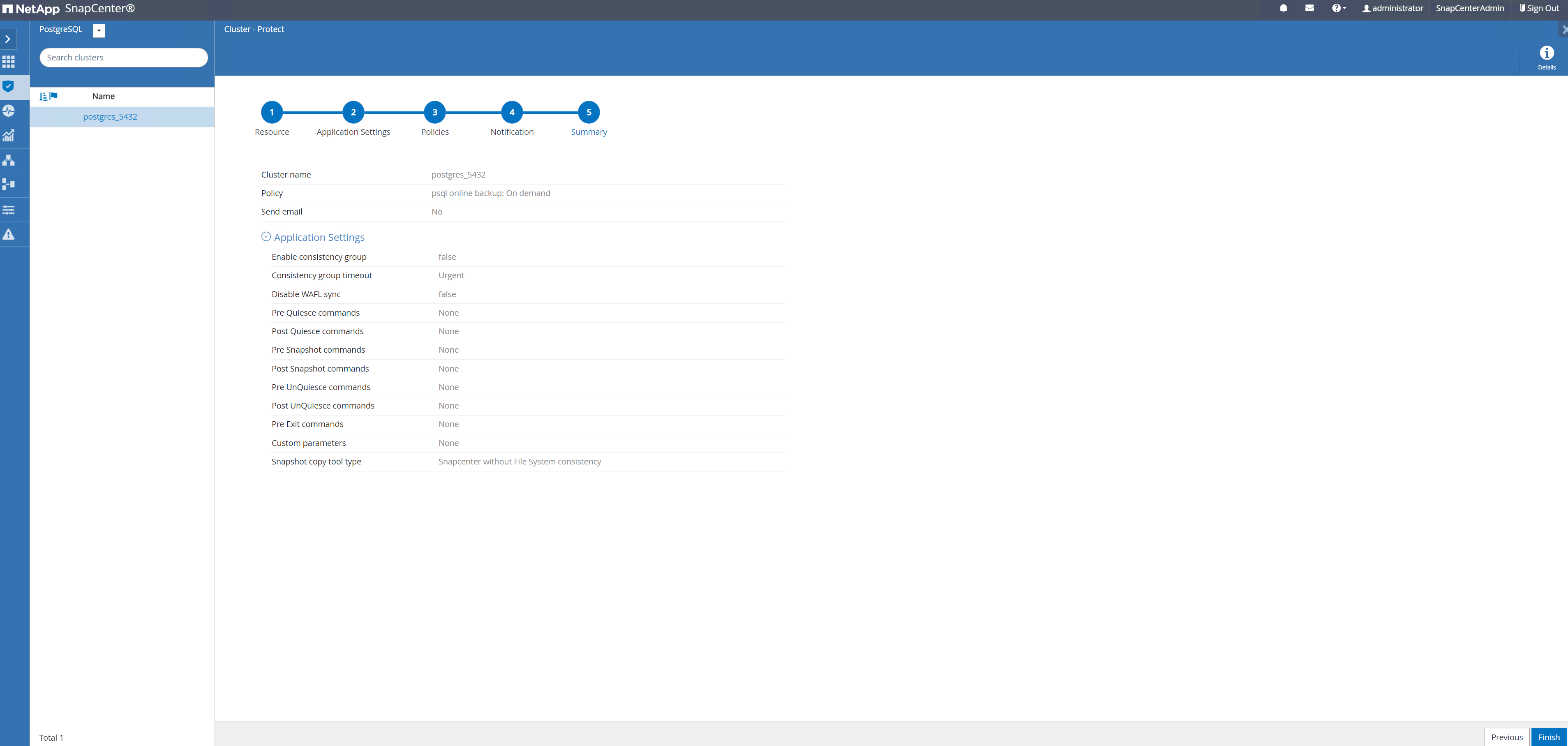
-
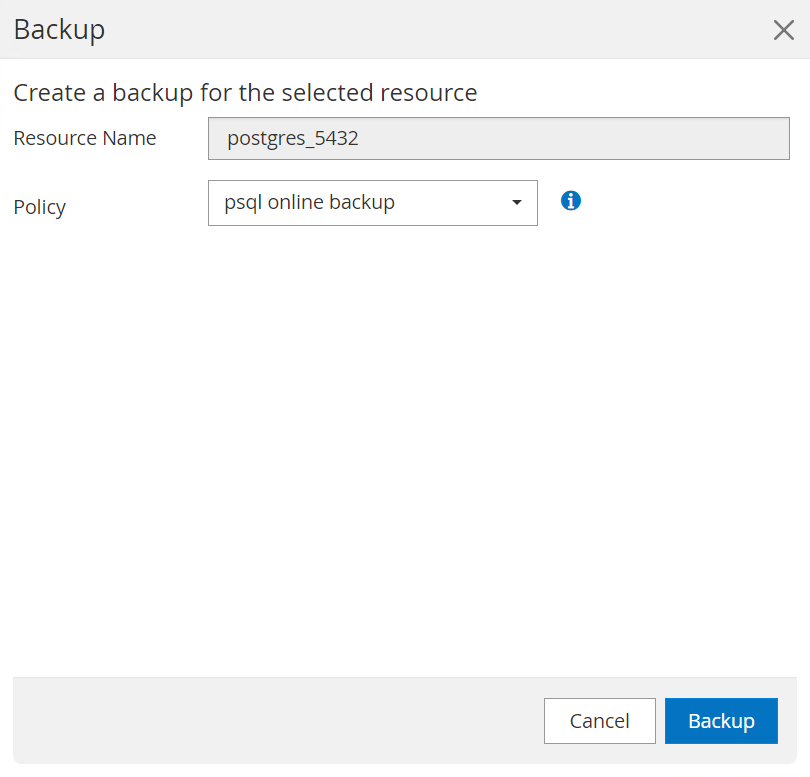
La copia de seguridad se ejecuta según el programa de copia de seguridad o desde la topología de copia de seguridad del clúster, haga clic en
Backup Nowpara activar una copia de seguridad manual a pedido.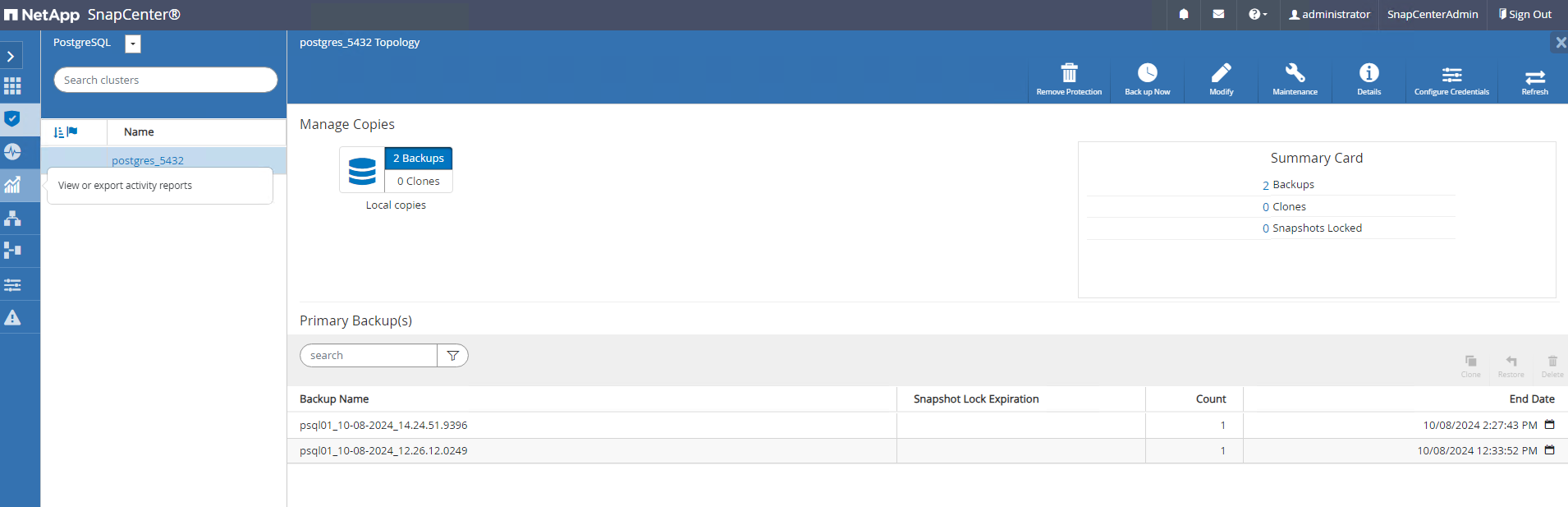
-
Supervisar el trabajo de respaldo desde
Monitorpestaña. Generalmente, se necesitan unos minutos para realizar una copia de seguridad de una base de datos grande y, en nuestro caso de prueba, tomó alrededor de 4 minutos realizar una copia de seguridad de volúmenes de bases de datos cercanos a 1 TB.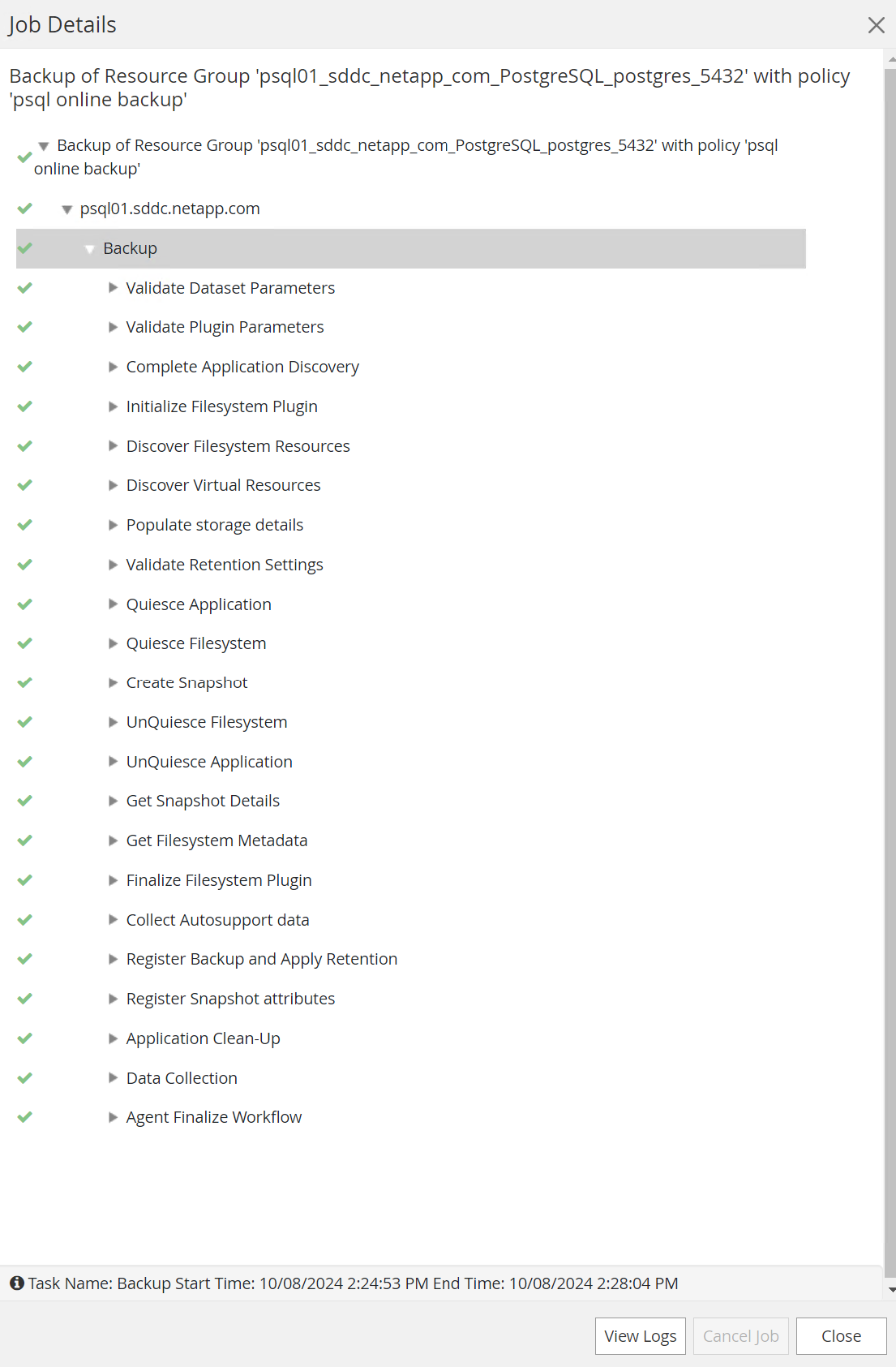
-
Recuperación de base de datos
Details
En esta demostración de recuperación de base de datos, mostramos una recuperación en un punto en el tiempo del clúster de base de datos PostgreSQL. Primero, cree una copia de seguridad SnapShot del volumen de la base de datos en el almacenamiento ONTAP usando SnapCenter. Luego, inicie sesión en la base de datos, cree una tabla de prueba, anote la marca de tiempo y elimine la tabla de prueba. Ahora inicie una recuperación desde la copia de seguridad hasta la marca de tiempo cuando se creó la tabla de prueba para recuperar la tabla eliminada. A continuación, se capturan los detalles del flujo de trabajo y la validación de la recuperación de un punto en el tiempo de la base de datos PostgreSQL con la interfaz de usuario de SnapCenter .
-
Inicie sesión en PostgreSQL como
postgresusuario. Cree y luego elimine una tabla de prueba.postgres=# \dt Did not find any relations. postgres=# create table test (id integer, dt timestamp, event varchar(100)); CREATE TABLE postgres=# \dt List of relations Schema | Name | Type | Owner --------+------+-------+---------- public | test | table | postgres (1 row) postgres=# insert into test values (1, now(), 'test PostgreSQL point in time recovery with SnapCenter'); INSERT 0 1 postgres=# select * from test; id | dt | event ----+----------------------------+-------------------------------------------------------- 1 | 2024-10-08 17:55:41.657728 | test PostgreSQL point in time recovery with SnapCenter (1 row) postgres=# drop table test; DROP TABLE postgres=# \dt Did not find any relations. postgres=# select current_time; current_time -------------------- 17:59:20.984144+00 -
De
Resourcespestaña, abra la página de copia de seguridad de la base de datos. Seleccione la copia de seguridad SnapShot que desea restaurar. Luego, haga clic enRestoreBotón para iniciar el flujo de trabajo de recuperación de la base de datos. Tenga en cuenta la marca de tiempo de la copia de seguridad al realizar una recuperación en un punto en el tiempo.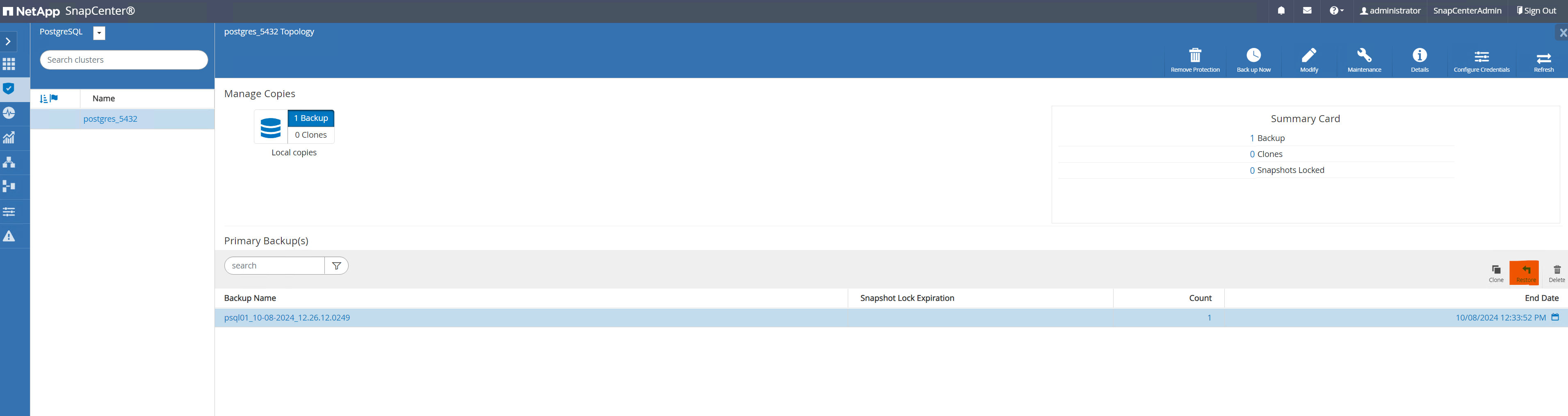
-
Seleccionar
Restore scope. En este momento, un recurso completo es la única opción.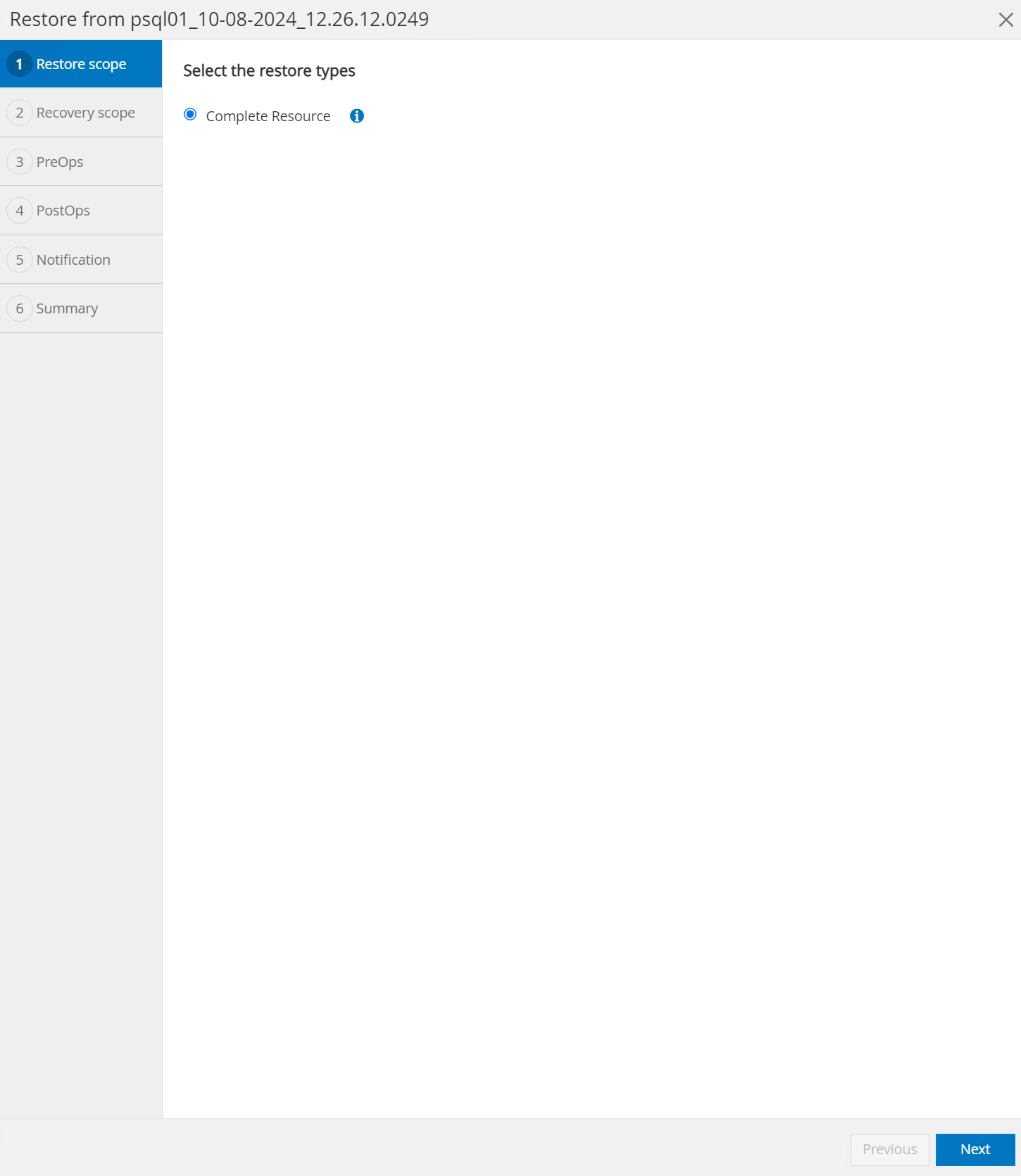
-
Para
Recovery Scope, elegirRecover to point in timee ingrese la marca de tiempo hasta la cual se realiza la recuperación.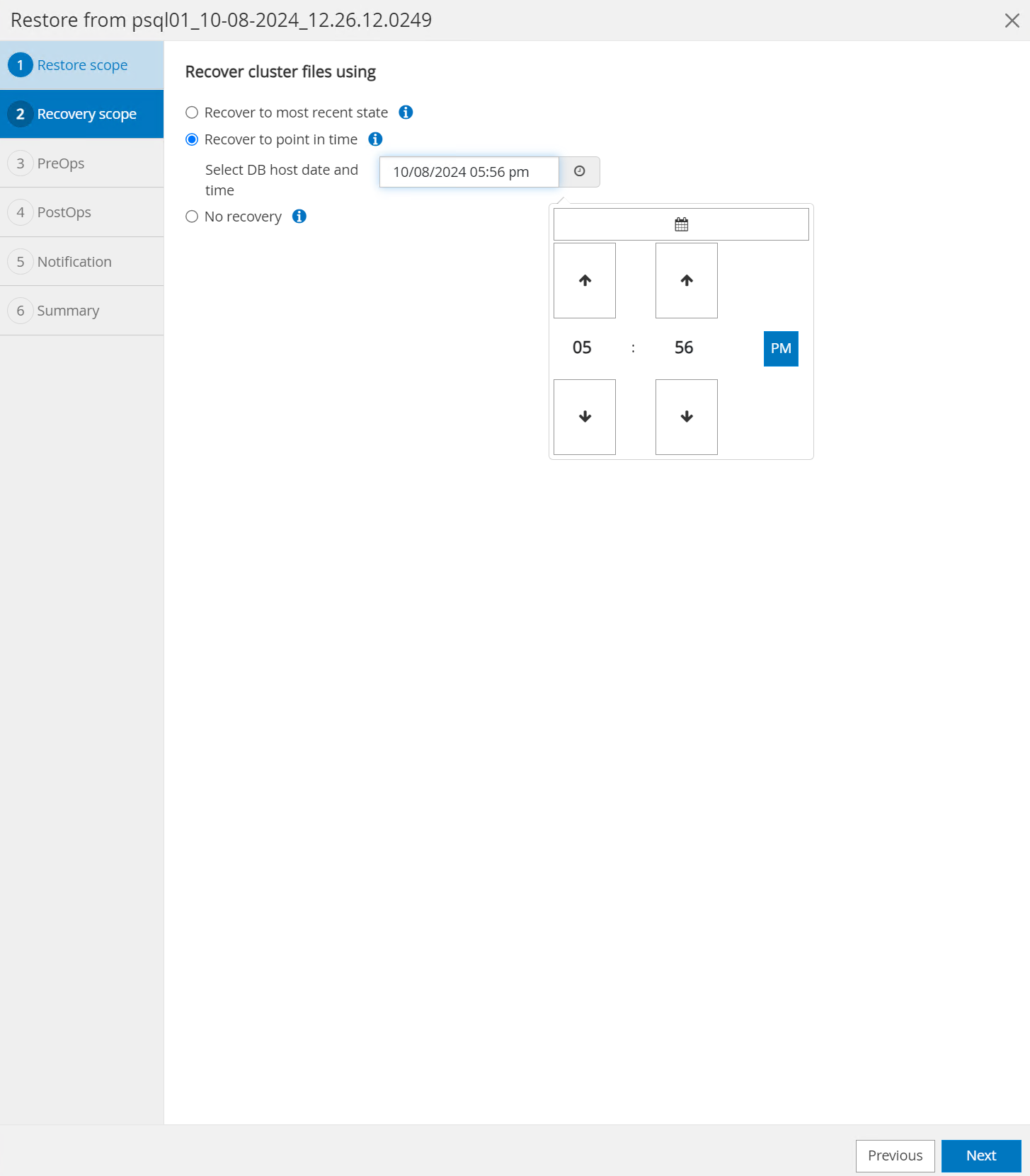
-
El
PreOpspermite la ejecución de scripts contra la base de datos antes de la operación de restauración/recuperación o simplemente dejarlo en negro.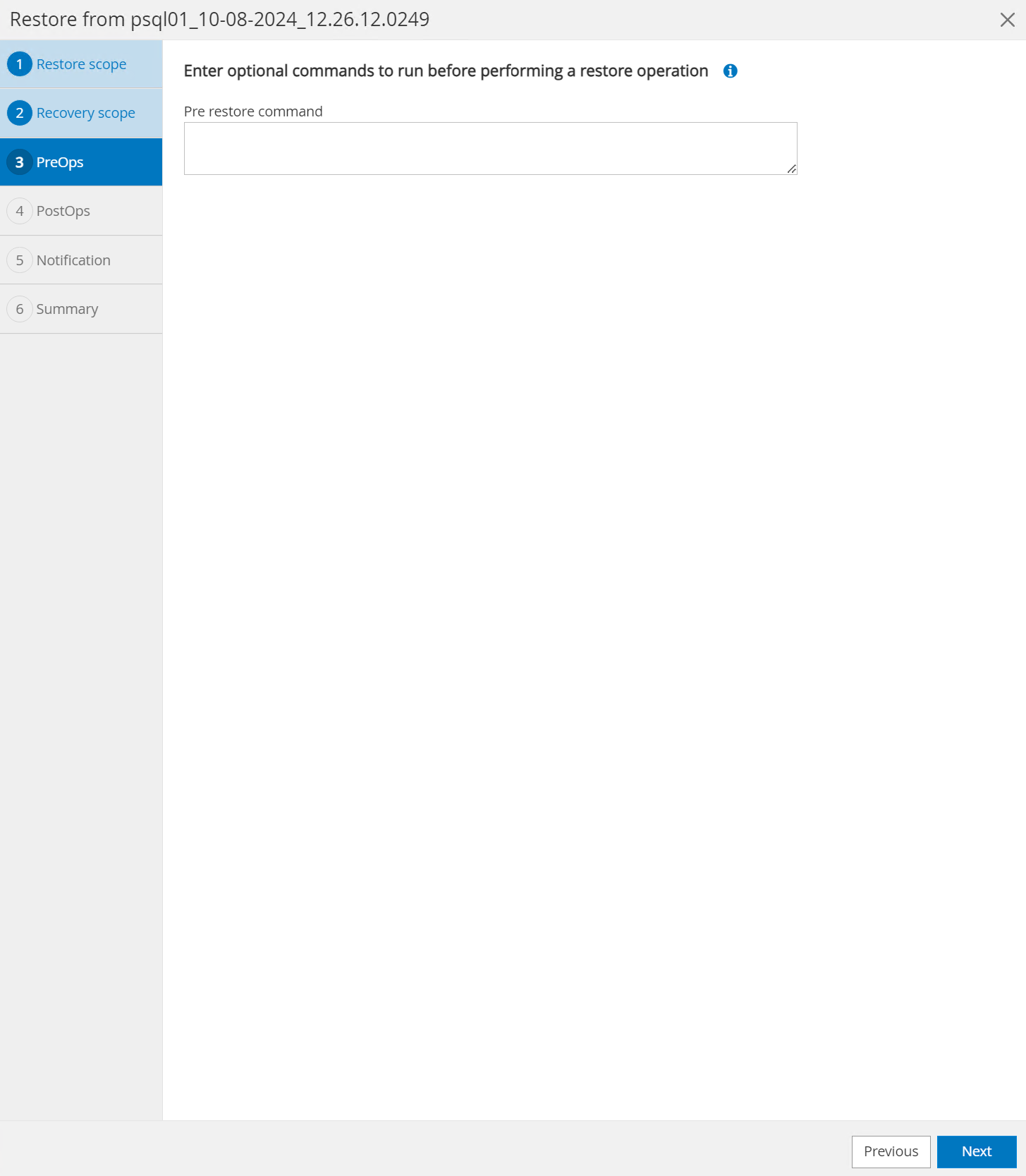
-
El
PostOpspermite la ejecución de scripts contra la base de datos después de la operación de restauración/recuperación o simplemente dejarlo en negro.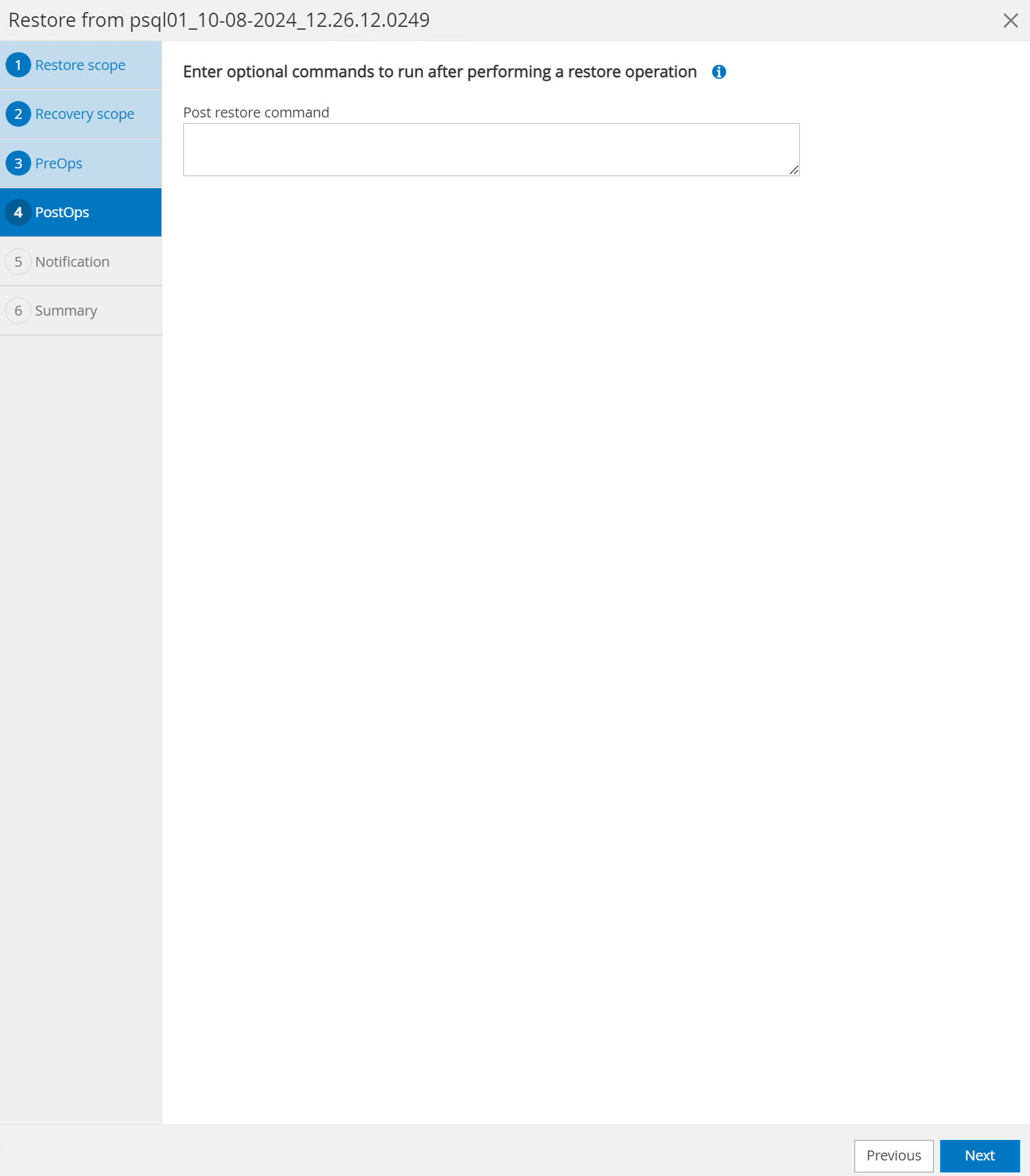
-
Notificación vía correo electrónico si lo desea.
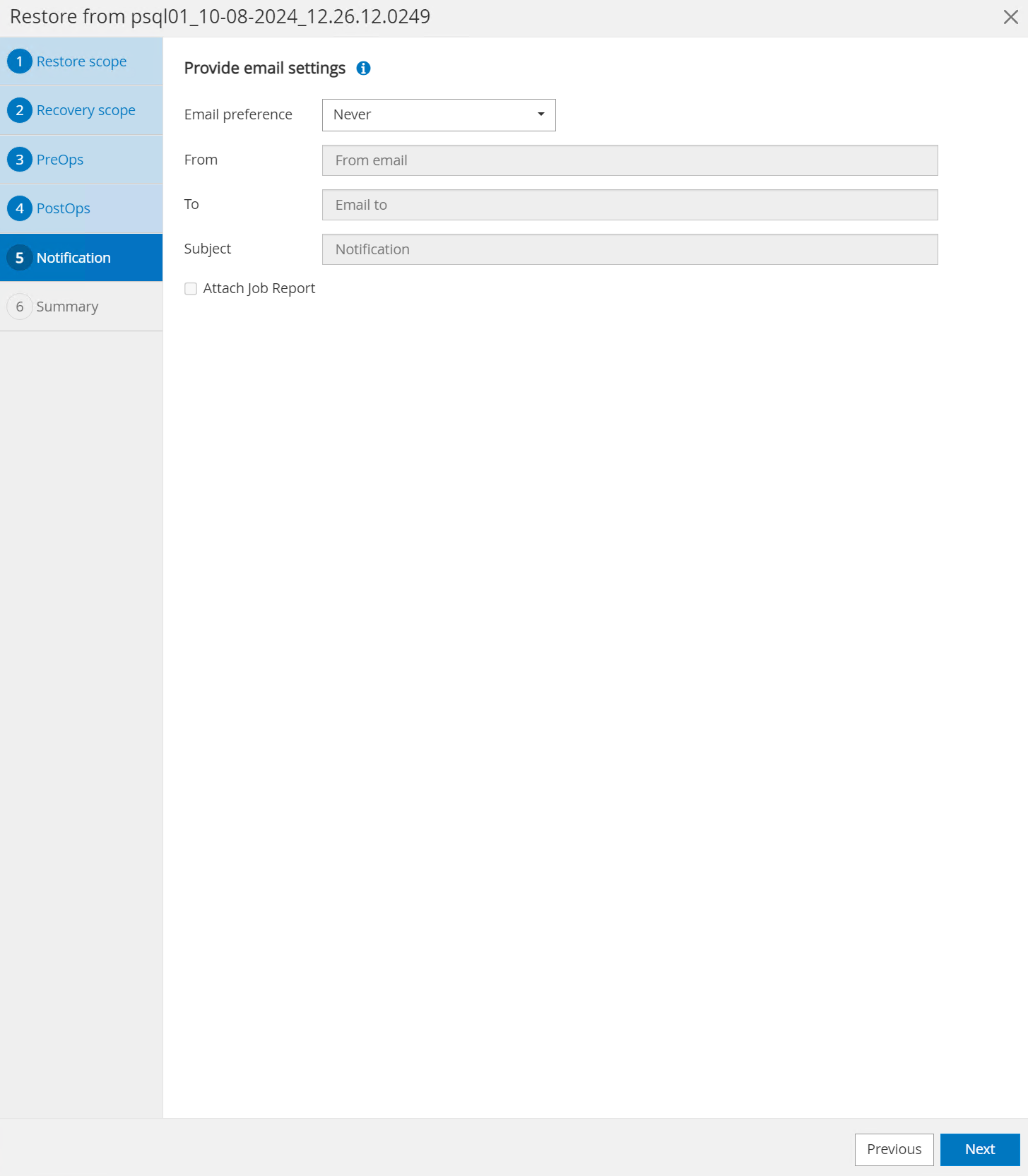
-
Revisar el resumen del trabajo y
Finishpara iniciar el trabajo de restauración.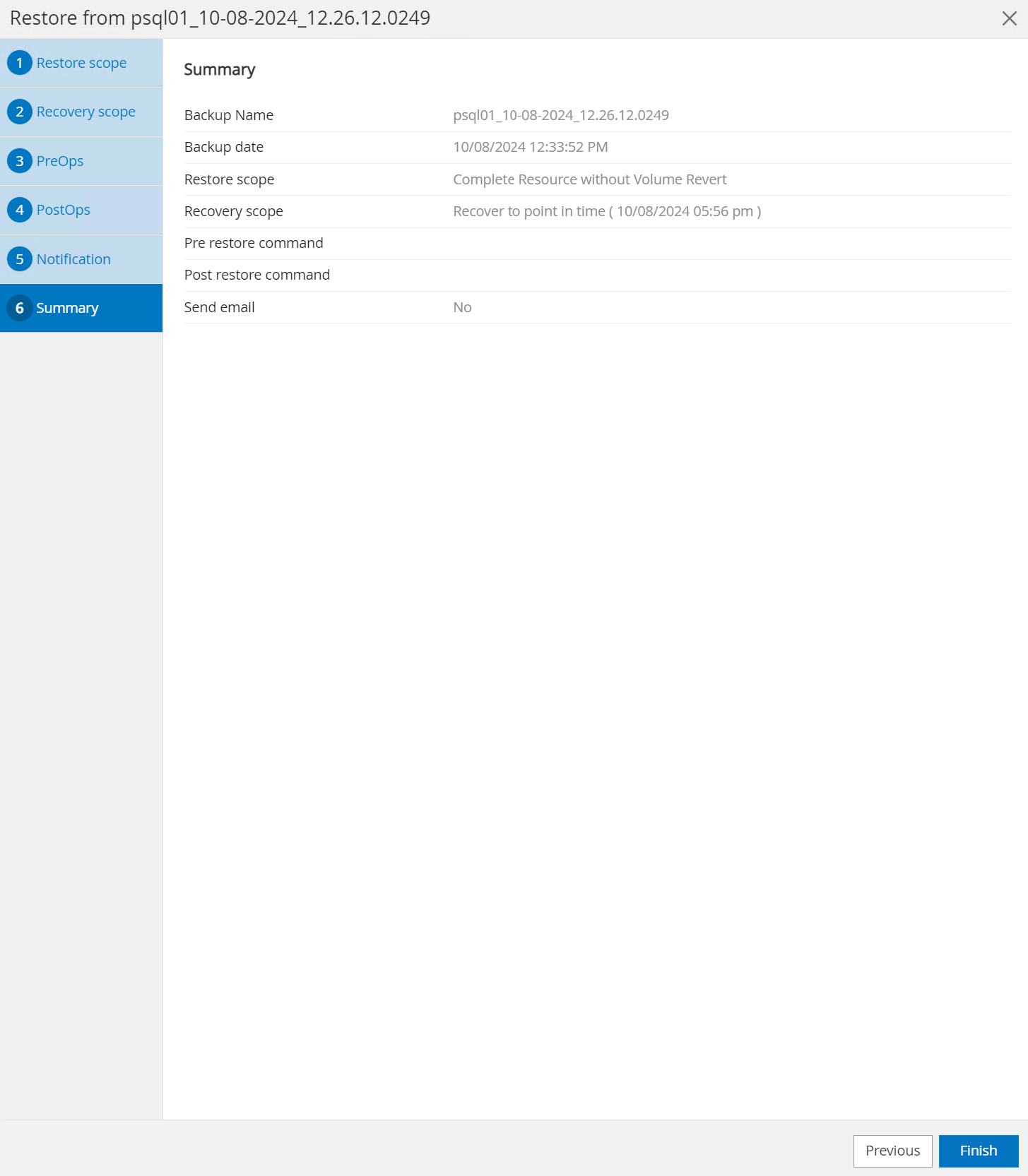
-
Haga clic en el trabajo en ejecución para abrirlo
Job Detailsventana. El estado del trabajo también se puede abrir y ver desde elMonitorpestaña.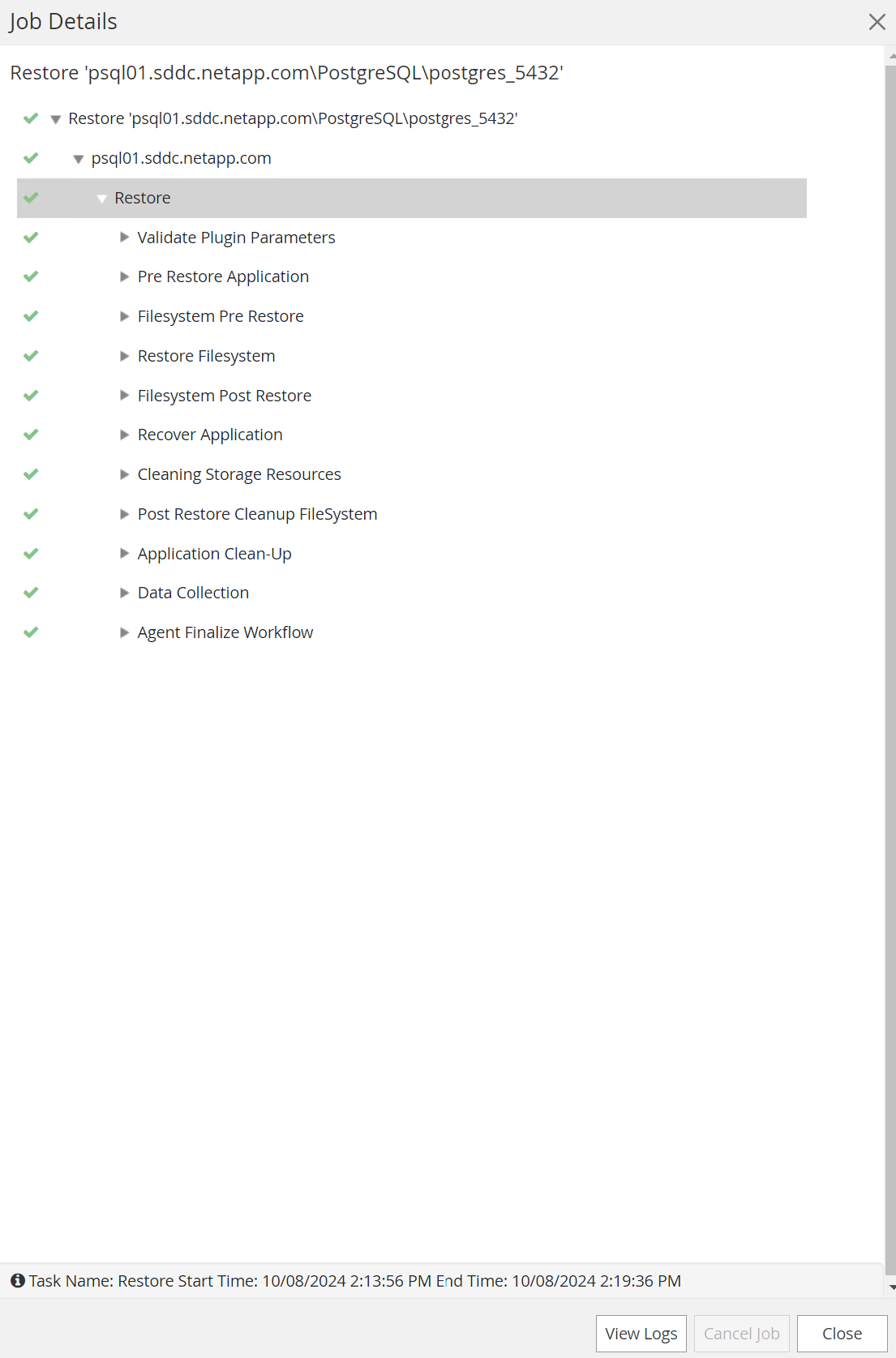
-
Inicie sesión en PostgreSQL como
postgresusuario y validar que se ha recuperado la tabla de prueba.[postgres@psql01 ~]$ psql psql (14.13) Type "help" for help. postgres=# \dt List of relations Schema | Name | Type | Owner --------+------+-------+---------- public | test | table | postgres (1 row) postgres=# select * from test; id | dt | event ----+----------------------------+-------------------------------------------------------- 1 | 2024-10-08 17:55:41.657728 | test PostgreSQL point in time recovery with SnapCenter (1 row) postgres=# select now(); now ------------------------------- 2024-10-08 18:22:33.767208+00 (1 row)
Clon de base de datos
Details
La clonación de un clúster de base de datos PostgreSQL a través de SnapCenter crea un nuevo volumen clonado delgado a partir de una copia de seguridad instantánea de un volumen de datos de la base de datos de origen. Lo que es más importante, es rápido (unos pocos minutos) y eficiente en comparación con otros métodos para hacer una copia clonada de la base de datos de producción para respaldar el desarrollo o las pruebas. De esta forma, se reducen drásticamente los costes de almacenamiento y se mejora la gestión del ciclo de vida de las aplicaciones de base de datos. La siguiente sección demuestra el flujo de trabajo de la clonación de la base de datos PostgreSQL con la interfaz de usuario de SnapCenter .
-
Para validar el proceso de clonación. Nuevamente, inserte una fila en la tabla de prueba. Luego, ejecute una copia de seguridad para capturar los datos de prueba.
postgres=# insert into test values (2, now(), 'test PostgreSQL clone to a different DB server host'); INSERT 0 1 postgres=# select * from test; id | dt | event ----+----------------------------+----------------------------------------------------- 2 | 2024-10-11 20:15:04.252868 | test PostgreSQL clone to a different DB server host (1 row)
-
De
Resourcespestaña, abra la página de copia de seguridad del clúster de base de datos. Seleccione la instantánea de la copia de seguridad de la base de datos que contiene los datos de prueba. Luego, haga clic encloneBotón para iniciar el flujo de trabajo de clonación de base de datos.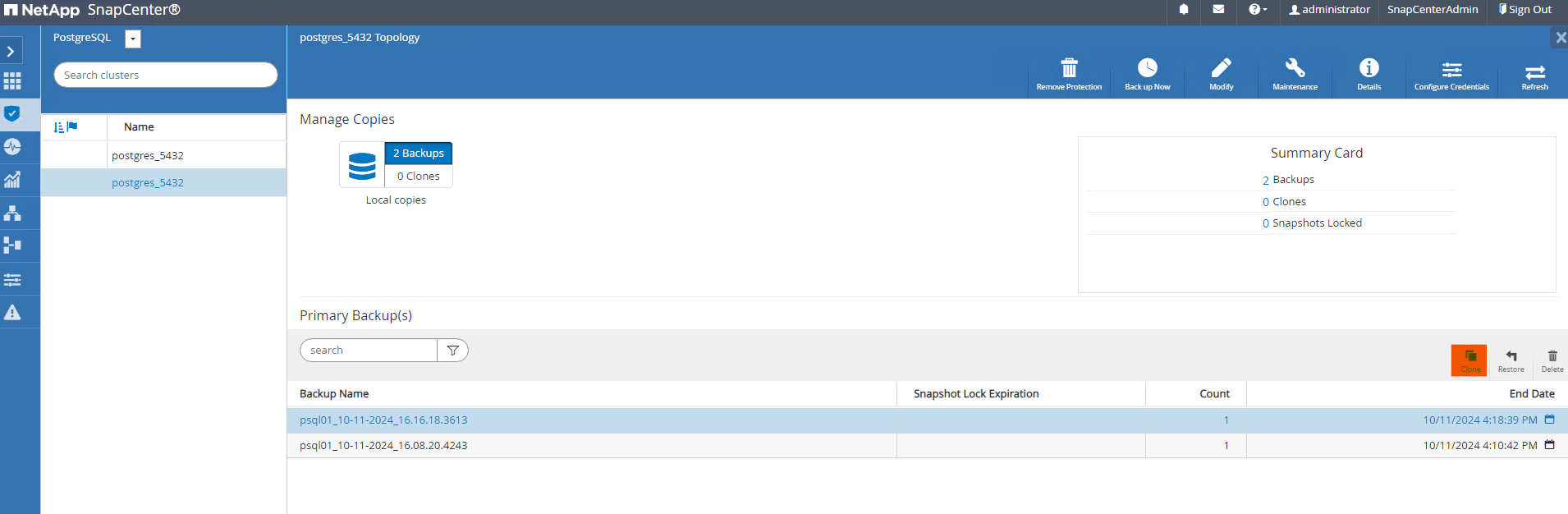
-
Seleccione un host de servidor de base de datos diferente al servidor de base de datos de origen. Elija un puerto TCP 543x no utilizado en el host de destino.
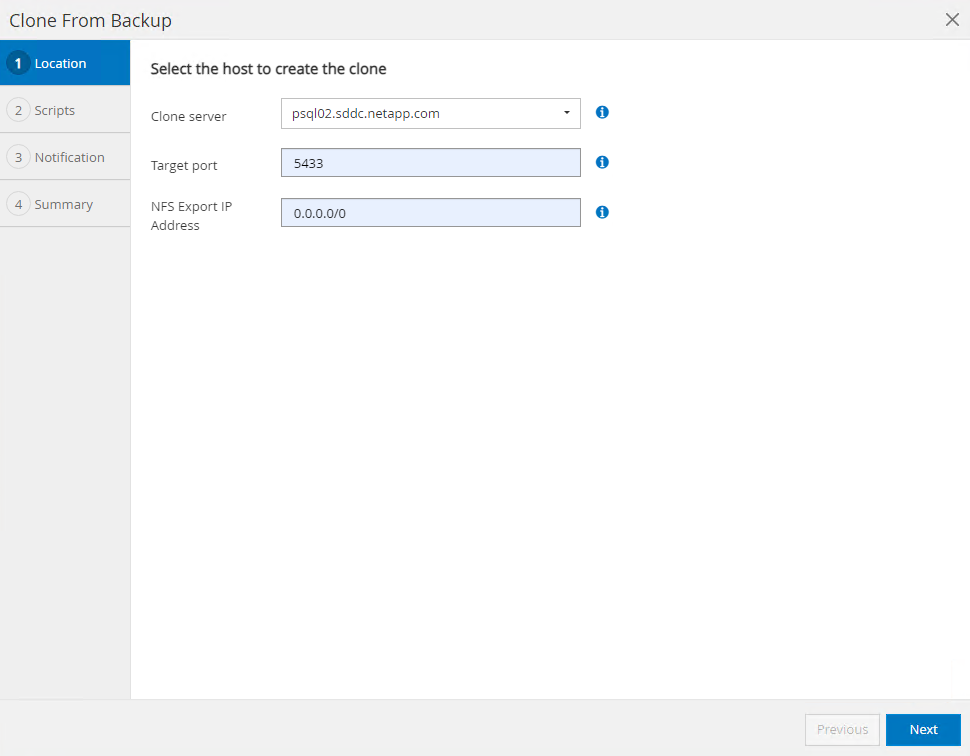
-
Ingrese cualquier script para ejecutar antes o después de la operación de clonación.
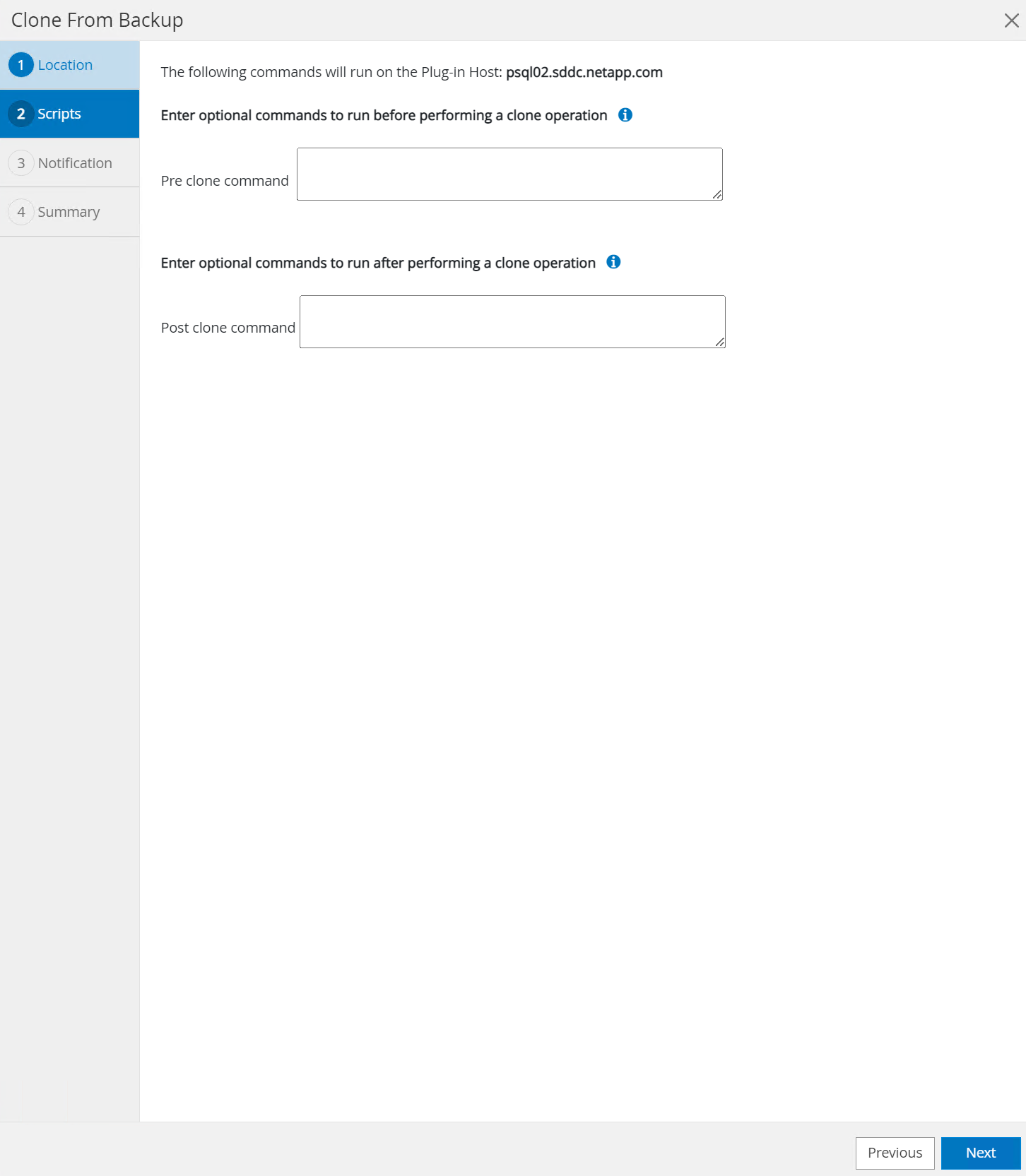
-
Notificación vía correo electrónico si lo desea.
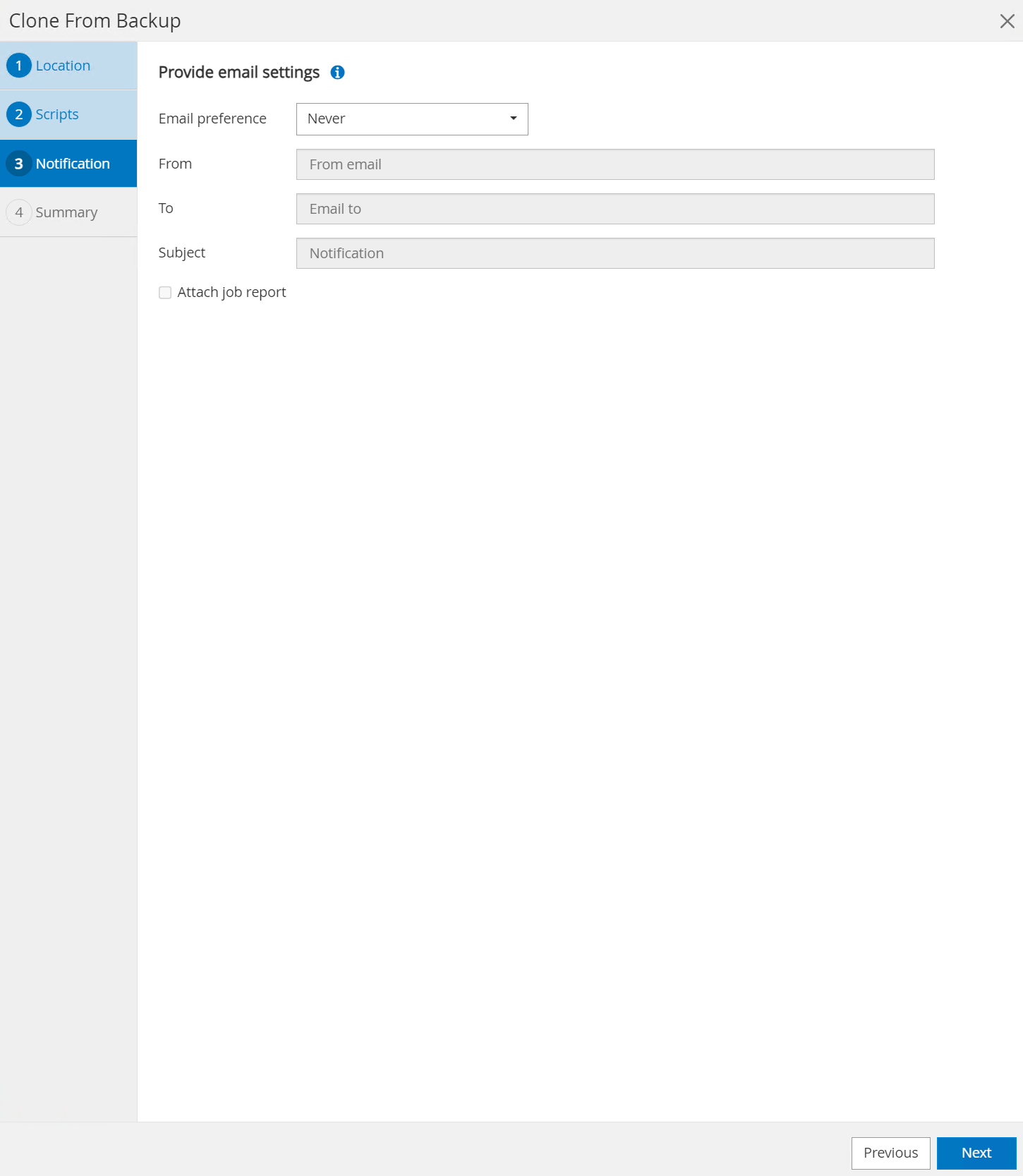
-
Resumen de la revisión y
Finishpara iniciar el proceso de clonación.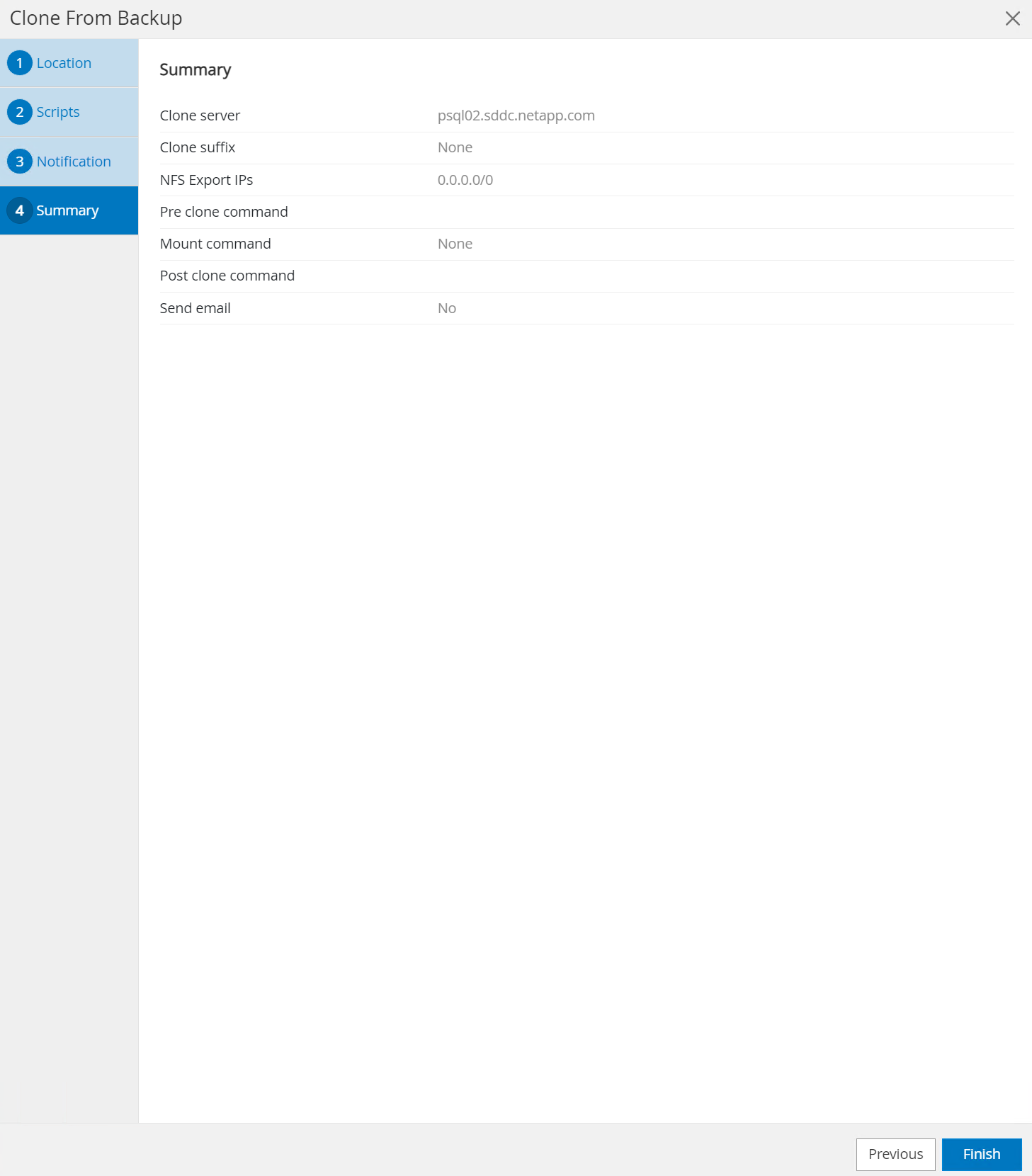
-
Haga clic en el trabajo en ejecución para abrirlo
Job Detailsventana. El estado del trabajo también se puede abrir y ver desde elMonitorpestaña.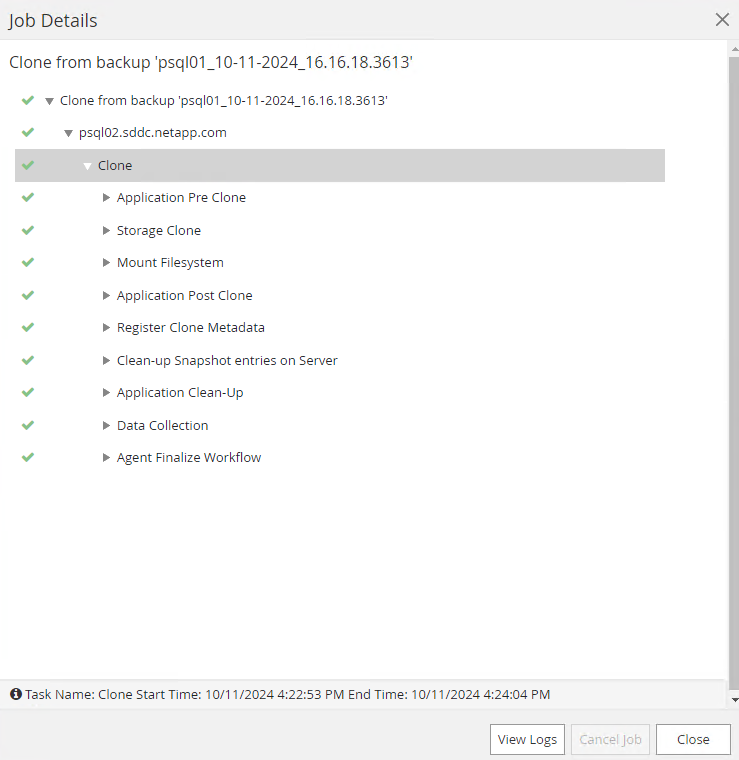
-
La base de datos clonada se registra en SnapCenter inmediatamente.
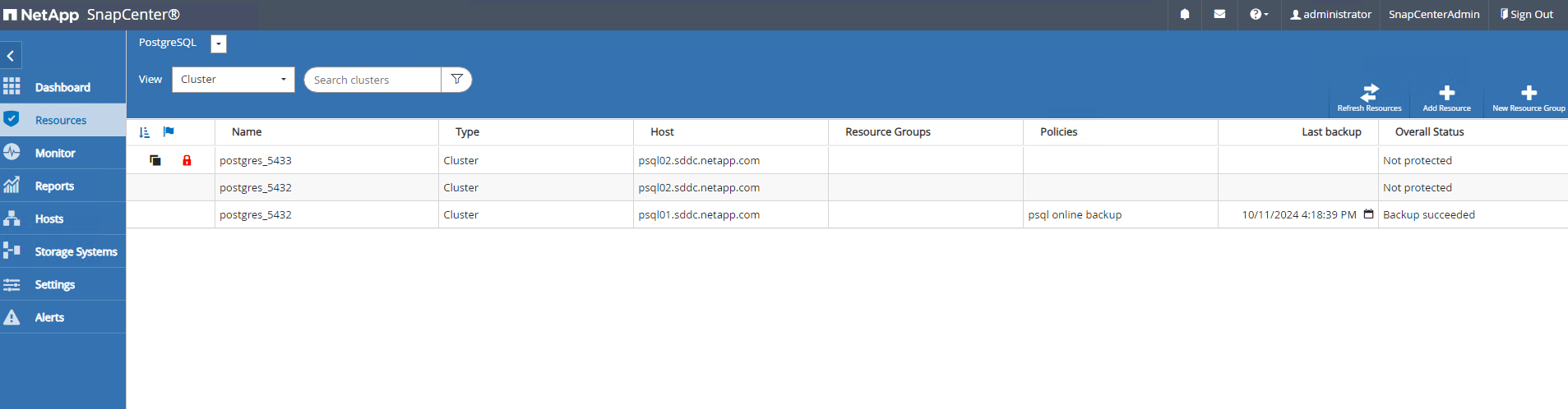
-
Validar el clúster de base de datos clonado en el host del servidor de base de datos de destino.
[postgres@psql01 ~]$ psql -d postgres -h 10.61.186.7 -U postgres -p 5433 Password for user postgres: psql (14.13) Type "help" for help. postgres=# select * from test; id | dt | event ----+----------------------------+----------------------------------------------------- 2 | 2024-10-11 20:15:04.252868 | test PostgreSQL clone to a different DB server host (1 row) postgres=# select pg_read_file('/etc/hostname') as hostname; hostname ---------- psql02 + (1 row)
Dónde encontrar información adicional
Para obtener más información sobre la información descrita en este documento, revise los siguientes documentos y/o sitios web:
-
Documentación del software SnapCenter
-
TR-4956: Implementación automatizada de alta disponibilidad y recuperación ante desastres de PostgreSQL en AWS FSx/EC2