

Configurar la replicación sincrónica con NetApp SnapMirror Active Sync y clústeres extendidos de Microsoft
 Sugerir cambios
Sugerir cambios
Utilice SnapMirror Active Sync para configurar la replicación sincrónica y bidireccional entre clústeres de conmutación por error extendidos de Microsoft. Este procedimiento incluye la instalación de un clúster de conmutación por error extendido, la creación de intercambio de tráfico entre clústeres, la configuración de un mediador con ONTAP, la habilitación de la protección activa/activa simétrica y la realización de pruebas de validación de conmutación por error del clúster.
Introducción
A partir de ONTAP 9.15.1, la sincronización activa de SnapMirror admite implementaciones activas/activas simétricas, lo que permite operaciones de E/S de lectura y escritura desde ambas copias de un LUN protegido con replicación sincrónica bidireccional. Un Windows Stretch Cluster es una extensión de la función Windows Failover Cluster que abarca múltiples ubicaciones geográficas para brindar alta disponibilidad y recuperación ante desastres. Con la sincronización activa simétrica activa/activa de SnapMirror y aplicaciones agrupadas en clústeres como la agrupación en clústeres de conmutación por error de Windows, podemos lograr una disponibilidad continua para las aplicaciones críticas de negocio de Microsoft Hyper-V para alcanzar RTO y RPO cero durante incidentes inesperados. Esta solución ofrece los siguientes beneficios:
-
Pérdida de datos cero: garantiza que los datos se repliquen de forma sincrónica, logrando un Objetivo de punto de recuperación (RPO) cero.
-
Alta disponibilidad y equilibrio de carga: Ambos sitios pueden manejar solicitudes de forma activa, proporcionando equilibrio de carga y alta disponibilidad.
-
Continuidad del negocio: Implemente una configuración activa/activa simétrica para garantizar que ambos centros de datos presten servicio activamente a las aplicaciones y puedan tomar el control sin problemas en caso de una falla.
-
Mejorar el rendimiento: utilice una configuración activa/activa simétrica para distribuir la carga entre múltiples sistemas de almacenamiento, lo que mejora los tiempos de respuesta y el rendimiento general del sistema.
Este documento documenta la replicación bidireccional sincrónica de la tecnología de sincronización activa SnapMirror entre clústeres de conmutación por error extendidos de Microsoft, lo que permite que los datos de aplicaciones de múltiples sitios, por ejemplo MSSQL y Oracle, sean accesibles de forma activa y estén sincronizados en ambos sitios. Si ocurre una falla, las aplicaciones se redirigen inmediatamente al sitio activo restante, sin pérdida de datos ni pérdida de acceso, lo que proporciona alta disponibilidad, recuperación ante desastres y redundancia geográfica.
Casos de uso
En caso de una interrupción, como un ciberataque, un corte de energía o un desastre natural, un entorno empresarial conectado globalmente exige una recuperación rápida de los datos de aplicaciones críticas para el negocio con cero pérdida de datos. Estas exigencias se acentúan en áreas como las finanzas y aquellas que se adhieren a mandatos regulatorios como el Reglamento General de Protección de Datos (GDPR). Implemente una configuración activa/activa simétrica para replicar datos entre ubicaciones geográficamente dispersas, brindando acceso local a los datos y garantizando la continuidad en caso de interrupciones regionales.
La sincronización activa de SnapMirror ofrece los siguientes casos de uso:
En una implementación de sincronización activa de SnapMirror , tienes un clúster principal y uno espejo. Una LUN en el clúster principal (L1P) tiene un espejo (L1S) en el secundario; las lecturas y escrituras son atendidas por el sitio local a los hosts según las configuraciones de proximidad activa.
La conmutación por error de aplicación transparente (TAF) se basa en la conmutación por error de ruta basada en software MPIO del host para lograr un acceso sin interrupciones al almacenamiento. Ambas copias de LUN (por ejemplo, la copia principal (L1P) y la copia reflejada (L1S) tienen la misma identidad (número de serie) y se informan al host como de lectura y escritura.
Las aplicaciones agrupadas en clústeres, incluidos VMware vSphere Metro Storage Cluster (vMSC), Oracle RAC y Windows Failover Clustering con SQL, requieren acceso simultáneo para que las máquinas virtuales puedan conmutar por error al otro sitio sin ninguna sobrecarga de rendimiento. SnapMirror active sync symmetric active/active sirve IO localmente con replicación bidireccional para satisfacer los requisitos de las aplicaciones en clúster.
Replicar sincrónicamente múltiples volúmenes para una aplicación entre sitios en ubicaciones geográficamente dispersas. Puede conmutar automáticamente por error a la copia secundaria en caso de interrupción en la copia principal, lo que permite la continuidad del negocio para aplicaciones de nivel uno.
La sincronización activa de SnapMirror brinda flexibilidad con granularidad a nivel de aplicación fácil de usar y conmutación por error automática para lograr una alta disponibilidad de datos y una rápida replicación de datos para sus aplicaciones críticas para el negocio, como Oracle, Microsoft SQL Server, etc., en entornos físicos y virtuales.
Arquitectura de la solución
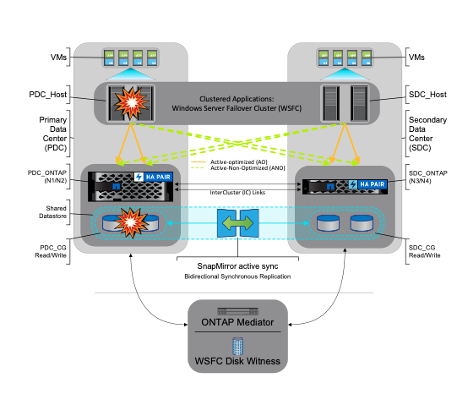
El clúster extendido de Microsoft tiene dos nodos Hyper-V en cada sitio. Estos dos nodos comparten almacenamiento NetApp y utilizan SnapMirror active sync symmetric active-active para replicar los volúmenes entre los dos sitios. Un grupo de consistencia garantiza que todos los volúmenes de un conjunto de datos se inactiven y luego se instale en el mismo momento. Esto proporciona un punto de restauración consistente con los datos en todos los volúmenes que admiten el conjunto de datos. El mediador de ONTAP recibe información sobre el estado de los clústeres y nodos de ONTAP emparejados, organiza la comunicación entre ambos y determina si cada nodo o clúster se encuentra en buen estado y en funcionamiento.
Componentes de la solución:
-
Dos sistemas de almacenamiento NetApp ONTAP 9.15.1: primer y segundo dominio de fallo
-
Una máquina virtual Redhat 8.7 para el mediador ONTAP
-
Tres clústeres de conmutación por error de Hyper-V en Windows 2022:
-
sitio1, sitio 2 para las aplicaciones
-
sitio 3 para mediador
-
-
VM en Hyper-V: Controlador de dominio de Microsoft, instancia de clúster de conmutación por error Always On de MSSQL, Mediador de ONTAP
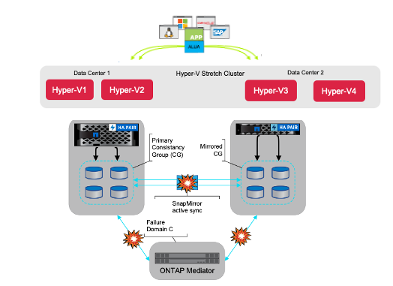
Instalar un clúster de conmutación por error de Microsoft Stretch
Puede usar el Centro de administración de Windows, PowerShell o la consola del Administrador del servidor para instalar la función de clústeres de conmutación por error y sus cmdlets de PowerShell asociados. Para obtener detalles sobre los requisitos previos y los pasos, consulte crear un clúster de conmutación por error.
A continuación se muestra una guía paso a paso para configurar un clúster Stretch de Windows:
-
Instalar Windows 2022 en los cuatro servidores hyperv1, hyperv2, hyperv3 y hyperv4
-
Unir los cuatro servidores al mismo dominio de Active Directory: hyperv.local.
-
Instalar las funciones de conmutación por error de Windows, Hyper-V, Hyper-V_Powershell y MPIO en cada servidor.
Install-WindowsFeature –Name "Failover-Clustering", "Hyper-V", "Hyper-V-Powershell", "MPIO" –IncludeManagementTools -
Configurar MPIO, agregar soporte para dispositivos iSCSI.
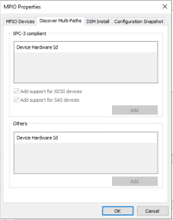
-
En el almacenamiento de ONTAP del sitio 1 y del sitio 2, cree dos LUN iSCSI (SQLdata y SQLlog) y asígnelos al grupo iqn de servidores de Windows. Utilice el iniciador de software iSCSI de Microsoft para conectar los LUN. Para más detalles, consulte"Configuración de iSCSI para Windows" .
-
Ejecute el informe de validación de clúster para detectar errores o advertencias.
Test-Cluster –Node hyperv1, hyperv2, hyperv3, hyperv4 -
Cree un clúster de conmutación por error, asigne una dirección IP estática,
New-Cluster –Name <clustername> –Node hyperv1, hyperv2, hyperv3, hyperv4, StaticAddress <IPaddress>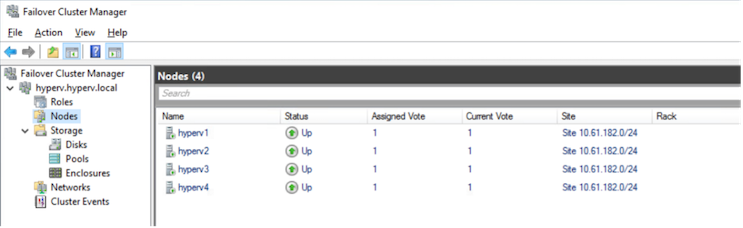
-
Agregue los almacenamientos iSCSI asignados al clúster de conmutación por error.
-
Para configurar un testigo para el quórum, haga clic con el botón derecho en el clúster → Más acciones → Configurar ajustes de quórum del clúster, seleccione testigo de disco.
El siguiente diagrama muestra cuatro LUN compartidos agrupados: dos sitios sqldata y sqllog y un testigo de disco en quórum.
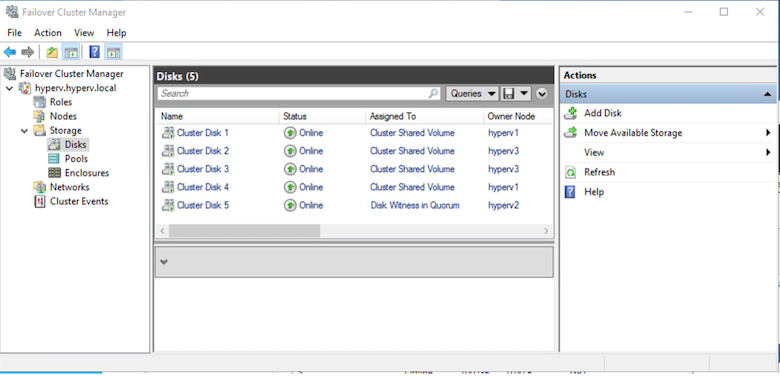
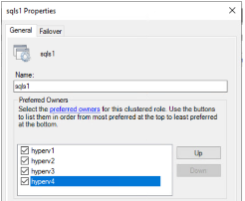
Una instancia de clúster de conmutación por error siempre activa (FCI) es una instancia de SQL Server que se instala en todos los nodos con almacenamiento en disco compartido SAN en un WSFC. Durante una conmutación por error, el servicio WSFC transfiere la propiedad de los recursos de la instancia a un nodo de conmutación por error designado. Luego, la instancia de SQL Server se reinicia en el nodo de conmutación por error y las bases de datos se recuperan como de costumbre. Para obtener más detalles sobre la configuración, consulte Agrupamiento en clústeres de conmutación por error de Windows con SQL. Cree dos máquinas virtuales Hyper-V SQL FCI en cada sitio y establezca la prioridad. Utilice hyperv1 e hyperv2 como propietarios preferidos para las máquinas virtuales del sitio 1 y hyperv3 e hyperv4 como propietarios preferidos para las máquinas virtuales del sitio 2.
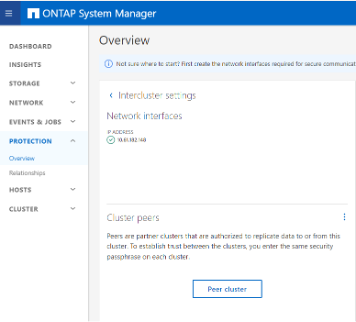
Crear peering entre clústeres
Debe crear relaciones de pares entre los clústeres de origen y destino antes de poder replicar copias de instantáneas mediante SnapMirror.
-
Agregar interfaces de red entre clústeres en ambos clústeres
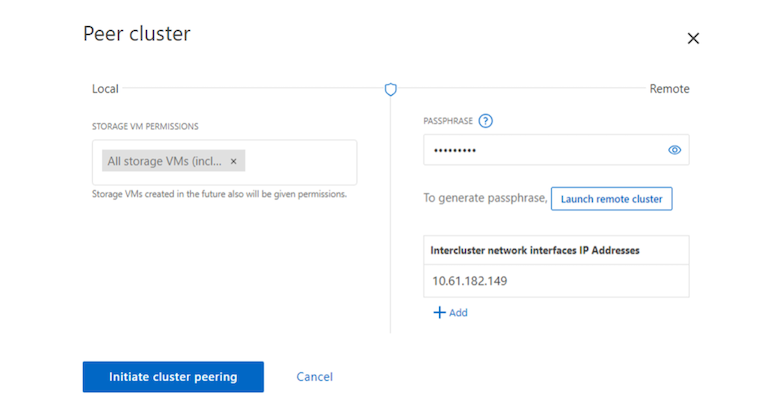
-
Puede utilizar el comando cluster peer create para crear una relación de pares entre un clúster local y remoto. Una vez creada la relación entre pares, puede ejecutar cluster peer create en el clúster remoto para autenticarlo en el clúster local.
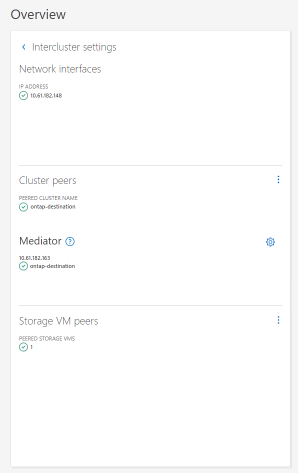
Configurar Mediator con ONTAP
El mediador de ONTAP recibe información sobre el estado de los clústeres y nodos de ONTAP emparejados, organiza la comunicación entre ambos y determina si cada nodo o clúster se encuentra en buen estado y en funcionamiento. SM-as permite que los datos se repliquen en el destino tan pronto como se escriben en el volumen de origen. El mediador debe implementarse en el tercer dominio de falla. Prerrequisitos
-
Especificaciones de hardware: 8 GB de RAM, CPU de 2 x 2 GHz, red de 1 Gb (<125 ms RTT)
-
Sistema operativo Red Hat 8.7 instalado, comprobar"Versión de ONTAP Mediator y versión de Linux compatible" .
-
Configurar el host Mediator Linux: configuración de red y puertos de firewall 31784 y 3260
-
Instalar el paquete yum-utils
-
"Registrar una clave de seguridad cuando el Arranque seguro UEFI esté habilitado"
-
Descargue el paquete de instalación de Mediator desde"Página de descarga de ONTAP Mediator" .
-
Verificar la firma del código del Mediador ONTAP .
-
Ejecute el instalador y responda a las indicaciones según sea necesario:
./ontap-mediator-1.8.0/ontap-mediator-1.8.0 -y -
Cuando el Arranque seguro está habilitado, debe realizar pasos adicionales para registrar la clave de seguridad después de la instalación:
-
Siga las instrucciones del archivo README para firmar el módulo del kernel SCST:
/opt/netapp/lib/ontap_mediator/ontap_mediator/SCST_mod_keys/README.module-signing -
Localice las claves necesarias:
/opt/netapp/lib/ontap_mediator/ontap_mediator/SCST_mod_keys
-
-
Verificar la instalación
-
Confirmar los procesos:
systemctl status ontap_mediator mediator-scst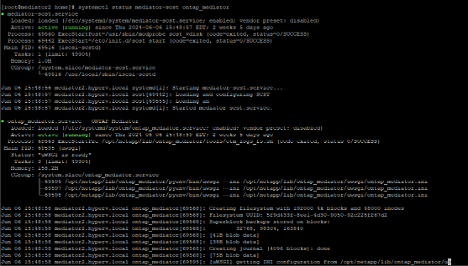
-
Confirme los puertos que utiliza el servicio ONTAP Mediator:

-
-
Inicialice el mediador de ONTAP para la sincronización activa de SnapMirror mediante certificados autofirmados
-
Busque el certificado CA de ONTAP Mediator en la ubicación de instalación del software de host/máquina virtual Linux de ONTAP Mediator cd /opt/netapp/lib/ontap_mediator/ontap_mediator/server_config.
-
Agregue el certificado CA de ONTAP Mediator a un clúster de ONTAP .
security certificate install -type server-ca -vserver <vserver_name>
-
-
Agregue el mediador, vaya al Administrador del sistema, proteger>Descripción general>Mediador, ingrese la dirección IP del mediador, el nombre de usuario (el usuario API predeterminado es mediatoradmin), la contraseña y el puerto 31784.
El siguiente diagrama muestra la interfaz de red entre clústeres, los pares del clúster, el mediador y los pares SVM configurados.
Configurar la protección activa/activa simétrica
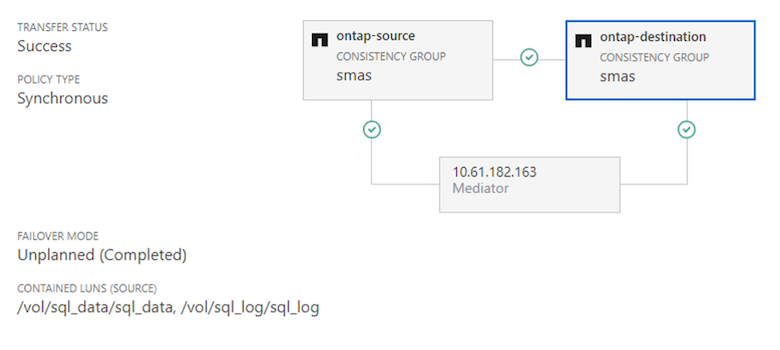
Los grupos de consistencia facilitan la administración de la carga de trabajo de las aplicaciones, brindando políticas de protección locales y remotas fácilmente configurables y copias instantáneas simultáneas consistentes con las aplicaciones o ante fallos de una colección de volúmenes en un punto en el tiempo. Para más detalles consulte"descripción general del grupo de consistencia" . Utilizamos una configuración uniforme para esta configuración.
-
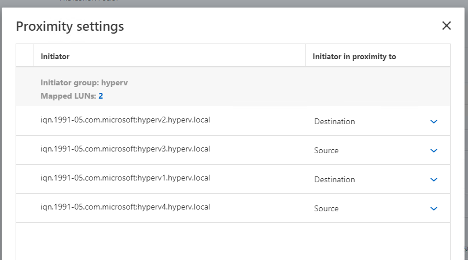
Al crear el grupo de consistencia, especifique los iniciadores de host para crear igroups.
-
Seleccione la casilla de verificación para Habilitar SnapMirror y luego elija la política AutomatedFailoverDuplex.
-
En el cuadro de diálogo que aparece, seleccione la casilla de verificación Replicar grupos de iniciadores para replicar igroups. En Editar configuración proximal, configure las SVM proximales para sus hosts.
-
Seleccionar Guardar
La relación de protección se establece entre la fuente y el destino.
Realizar una prueba de validación de conmutación por error del clúster
Le recomendamos que realice pruebas de conmutación por error planificadas para hacer una verificación de validación del clúster, las bases de datos SQL o cualquier software agrupado en ambos sitios (el sitio principal o reflejado debe seguir siendo accesible durante las pruebas).
Los requisitos del clúster de conmutación por error de Hyper-V incluyen:
-
La relación de sincronización activa de SnapMirror debe estar sincronizada.
-
No se puede iniciar una conmutación por error planificada cuando hay una operación no disruptiva en proceso. Las operaciones no disruptivas incluyen movimientos de volumen, reubicaciones de agregados y conmutaciones por error de almacenamiento.
-
El mediador de ONTAP debe estar configurado, conectado y en quórum.
-
Al menos dos nodos de clúster Hyper-V en cada sitio con procesadores de CPU pertenecen a la misma familia de CPU para optimizar el proceso de migración de VM. Las CPU deben ser CPU con soporte para virtualización asistida por hardware y prevención de ejecución de datos (DEP) basada en hardware.
-
Los nodos del clúster Hyper-V deben ser los mismos miembros del dominio de Active Directory para garantizar la resiliencia.
-
Los nodos del clúster Hyper-V y los nodos de almacenamiento NetApp deben estar conectados mediante redes redundantes para evitar un único punto de falla.
-
Almacenamiento compartido, al que pueden acceder todos los nodos del clúster a través del protocolo iSCSI, Fibre Channel o SMB 3.0.
Escenarios de prueba
Hay muchas formas de provocar una conmutación por error en un host, un almacenamiento o una red.
-
Error de nodo Un nodo de un clúster de conmutación por error puede hacerse cargo de la carga de trabajo de un nodo fallido, un proceso conocido como conmutación por error. Acción: Apagar un nodo Hyper-V Resultado esperado: El otro nodo del clúster se hará cargo de la carga de trabajo. Las máquinas virtuales se migrarán al otro nodo.
-
Error en un sitio También podemos hacer fallar todo el sitio y activar la conmutación por error del sitio principal al sitio espejo: Acción: apague ambos nodos Hyper-V en un sitio. Resultado esperado: las máquinas virtuales en el sitio principal migrarán al clúster Hyper-V del sitio espejo porque la sincronización activa/activa simétrica de SnapMirror sirve IO localmente con replicación bidireccional, sin impacto en la carga de trabajo con RPO cero y RTO cero.
-
Detener una SVM en el sitio principal Acción: detener la SVM iSCSI Resultados esperados: el clúster principal de Hyper-V ya se ha conectado al sitio reflejado y con la sincronización activa de SnapMirror simétrica activa/activa, no hay impacto en la carga de trabajo con RPO cero y RTO cero.
Durante las pruebas, observe lo siguiente:
-
Observe el comportamiento del clúster y asegúrese de que los servicios se transfieran a los nodos restantes.
-
Verifique si hay errores o interrupciones del servicio.
-
Asegúrese de que el clúster pueda manejar fallas de almacenamiento y continuar funcionando.
-
Verificar que los datos de la base de datos permanezcan accesibles y que los servicios continúen funcionando.
-
Verificar que se mantenga la integridad de los datos de la base de datos.
-
Validar que aplicaciones específicas puedan conmutar por error a otro nodo sin afectar al usuario.
-
Verifique que el clúster pueda equilibrar la carga y mantener el rendimiento durante y después de una conmutación por error.
Resumen
La sincronización activa de SnapMirror puede ayudar a que los datos de aplicaciones de múltiples sitios, por ejemplo, MSSQL y Oracle, sean accesibles de forma activa y estén sincronizados en ambos sitios. Si ocurre una falla, las aplicaciones se redirigen inmediatamente al sitio activo restante, sin pérdida de datos ni pérdida de acceso.