
Trazabilidad de conjunto de datos a modelo con NetApp y MLflow
 Sugerir cambios
Sugerir cambios
Se "Kit de herramientas Data OPS de NetApp para Kubernetes" puede utilizar junto con las capacidades de seguimiento de experimentos de MLflow para implementar la trazabilidad de código a conjunto de datos, conjunto de datos a modelo o espacio de trabajo a modelo.
En el cuaderno de ejemplo se utilizaron las siguientes bibliotecas:
Requisitos previos
Para implementar la trazabilidad de modelo de conjunto de datos de código o de espacio de trabajo a modelo, simplemente cree una instantánea de su conjunto de datos o volumen de espacio de trabajo utilizando el kit de herramientas de DataOps como parte de su ciclo de entrenamiento, como se muestra en el siguiente fragmento de código de ejemplo. Este código guardará el nombre del volumen de datos y el nombre de la instantánea como etiquetas asociadas a la ejecución de entrenamiento específica que está registrando en el servidor de seguimiento de experimentos MLflow.
...
from netapp_dataops.k8s import cloneJupyterLab, createJupyterLab, deleteJupyterLab, \
listJupyterLabs, createJupyterLabSnapshot, listJupyterLabSnapshots, restoreJupyterLabSnapshot, \
cloneVolume, createVolume, deleteVolume, listVolumes, createVolumeSnapshot, \
deleteVolumeSnapshot, listVolumeSnapshots, restoreVolumeSnapshot
mlflow.set_tracking_uri("<your_tracking_server_uri>>:<port>>")
os.environ['MLFLOW_HTTP_REQUEST_TIMEOUT'] = '500' # Increase to 500 seconds
mlflow.set_experiment(experiment_id)
with mlflow.start_run() as run:
latest_run_id = run.info.run_id
start_time = datetime.now()
# Preprocess the data
preprocess(input_pdf_file_path, to_be_cleaned_input_file_path)
# Print out sensitive data (passwords, SECRET_TOKEN, API_KEY found)
check_pretrain(to_be_cleaned_input_file_path)
# Tokenize the input file
pretrain_tokenization(to_be_cleaned_input_file_path, model_name, tokenized_output_file_path)
# Load the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set the pad token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# Encode, generate, and decode the text
with open(tokenized_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
encode_generate_decode(content, decoded_output_file_path, tokenizer=tokenizer, model=model)
# Save the model
model.save_pretrained(model_save_path)
tokenizer.save_pretrained(model_save_path)
# Finetuning here
with open(decoded_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
model.finetune(content, tokenizer=tokenizer, model=model)
# Evaluate the model using NLTK
output_set = Dataset.from_dict({"text": [content]})
test_set = Dataset.from_dict({"text": [content]})
scores = nltk_evaluation_gpt(output_set, test_set, model=model, tokenizer=tokenizer)
print(f"Scores: {scores}")
# End time and elapsed time
end_time = datetime.now()
elapsed_time = end_time - start_time
elapsed_minutes = elapsed_time.total_seconds() // 60
elapsed_seconds = elapsed_time.total_seconds() % 60
# Create DOTK snapshots for code, dataset, and model
snapshot = createVolumeSnapshot(pvcName="model-pvc", namespace="default", printOutput=True)
#Log snapshot IDs to MLflow
mlflow.log_param("code_snapshot_id", snapshot)
mlflow.log_param("dataset_snapshot_id", snapshot)
mlflow.log_param("model_snapshot_id", snapshot)
# Log parameters and metrics to MLflow
mlflow.log_param("wf_start_time", start_time)
mlflow.log_param("wf_end_time", end_time)
mlflow.log_param("wf_elapsed_time_minutes", elapsed_minutes)
mlflow.log_param("wf_elapsed_time_seconds", elapsed_seconds)
mlflow.log_artifact(decoded_output_file_path.rsplit('/', 1)[0]) # Remove the filename to log the directory
mlflow.log_artifact(model_save_path) # log the model save path
print(f"Experiment ID: {experiment_id}")
print(f"Run ID: {latest_run_id}")
print(f"Elapsed time: {elapsed_minutes} minutes and {elapsed_seconds} seconds")El fragmento de código anterior registra los ID de instantánea en el servidor de seguimiento de experimentos MLflow, que se puede utilizar para rastrear el conjunto de datos y el modelo específicos que se utilizaron para entrenar el modelo. Esto le permitirá rastrear el conjunto de datos y el modelo específicos que se utilizaron para entrenar el modelo, así como el código específico que se utilizó para preprocesar los datos, tokenizar el archivo de entrada, cargar el tokenizador y el modelo, codificar, generar y descodificar el texto, guardar el modelo, afinar el modelo, evaluar el modelo utilizando "NLTK"puntuaciones de perplejidad y registrar los hiperparámetros y métricas para fluir. Por ejemplo, la siguiente figura muestra el error medio cuadrado (MSE) de un modelo scikit-learn para diferentes ejecuciones de experimentos:

Es sencillo para el análisis de datos, los propietarios de líneas de negocio y los ejecutivos comprender e inferir qué modelo funciona mejor bajo sus restricciones particulares, configuraciones, período de tiempo y otras circunstancias. Para obtener más detalles sobre cómo preprocesar, tokenizar, cargar, codificar, generar, decodificar, guardar, ajustar y evaluar el modelo, consulte el dotk-mlflow ejemplo de Python empaquetado en el netapp_dataops.k8s repositorio.
Para obtener más información sobre cómo crear instantáneas de su conjunto de datos o espacio de trabajo JupyterLab, consulte la "Kit de herramientas de DataOps de NetApp".
En cuanto a los modelos que fueron entrenados, se utilizaron los siguientes modelos en el cuaderno dotk-mlflow:
Modelos
-
"GPT2LMHeadModel": El transformador modelo GPT2 con una cabeza de modelado de lenguaje en la parte superior (capa lineal con pesos atados a las incrustaciones de entrada). Es un modelo de transformador que ha sido pre-entrenado en un gran corpus de datos de texto y finetuned en un conjunto de datos específico. Utilizamos el modelo GPT2 predeterminado "máscara de atención"para procesar por lotes secuencias de entrada con el tokenizador correspondiente para su modelo de elección.
-
"PHI-2"Phi-2 es un transformador con 2,7 mil millones de parámetros. Se entrenó utilizando las mismas fuentes de datos que Phi-1,5, aumentada con una nueva fuente de datos que consta de varios textos sintéticos de NLP y sitios web filtrados (por seguridad y valor educativo).
-
"XLNet (modelo de tamaño basado)": Modelo XLNet pre-entrenado en idioma inglés. Fue introducido en el artículo "XLNet: Preentrenamiento autorregresivo generalizado para la comprensión del lenguaje" por Yang et al. Y publicado por primera vez en este "repositorio".
El resultado "Registro de modelos en MLflow"contendrá los siguientes modelos, versiones y etiquetas de bosque aleatorio:
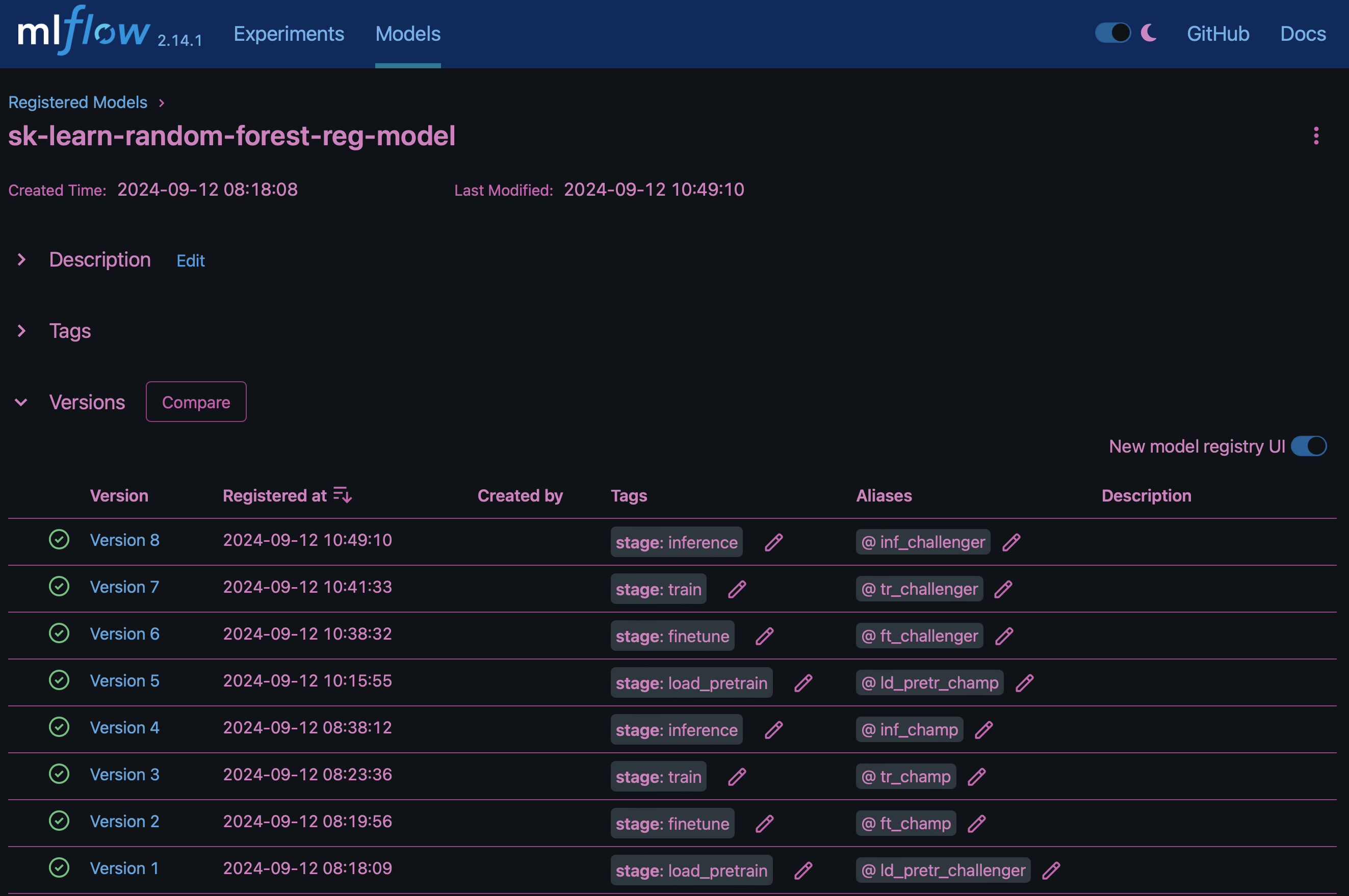
Para implementar el modelo en un servidor de inferencia a través de Kubernetes, simplemente ejecute el siguiente Jupyter Notebook. Tenga en cuenta que en este ejemplo dotk-mlflow, en lugar de usar el paquete, estamos modificando la arquitectura del modelo de regresión forestal aleatoria para minimizar el error medio-cuadrado (MSE) en el modelo inicial, y por lo tanto creamos múltiples versiones de dicho modelo en nuestro Registro de Modelos.
from mlflow.models import Model
mlflow.set_tracking_uri("http://<tracking_server_URI_with_port>")
experiment_id='<your_specified_exp_id>'
# Alternatively, you can load the Model object from a local MLmodel file
# model1 = Model.load("~/path/to/my/MLmodel")
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
from mlflow.models import infer_signature
# Create a new experiment and get its ID
experiment_id = mlflow.create_experiment(experiment_id)
# Or fetch the ID of the existing experiment
# experiment_id = mlflow.get_experiment_by_name("<your_specified_exp_id>").experiment_id
with mlflow.start_run(experiment_id=experiment_id) as run:
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
params = {"max_depth": 2, "random_state": 42}
model = RandomForestRegressor(**params)
model.fit(X_train, y_train)
# Infer the model signature
y_pred = model.predict(X_test)
signature = infer_signature(X_test, y_pred)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_metrics({"mse": mean_squared_error(y_test, y_pred)})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="sklearn-model",
signature=signature,
registered_model_name="sk-learn-random-forest-reg-model",
)El resultado de la ejecución de su celda Jupyter Notebook debe ser similar al siguiente, con el modelo registrado como versión 3 en el Registro de modelos:
Registered model 'sk-learn-random-forest-reg-model' already exists. Creating a new version of this model... 2024/09/12 15:23:36 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: sk-learn-random-forest-reg-model, version 3 Created version '3' of model 'sk-learn-random-forest-reg-model'.
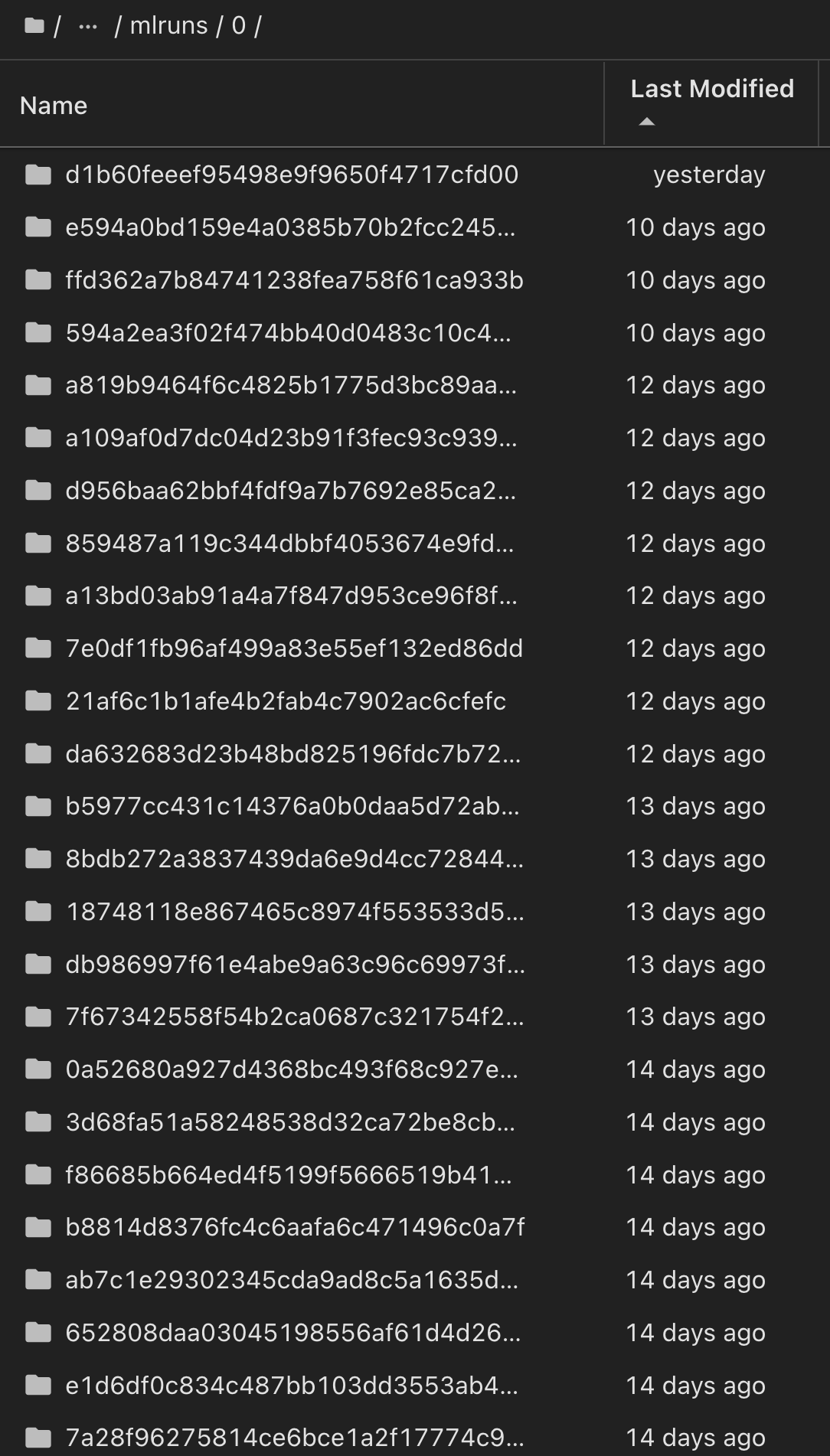
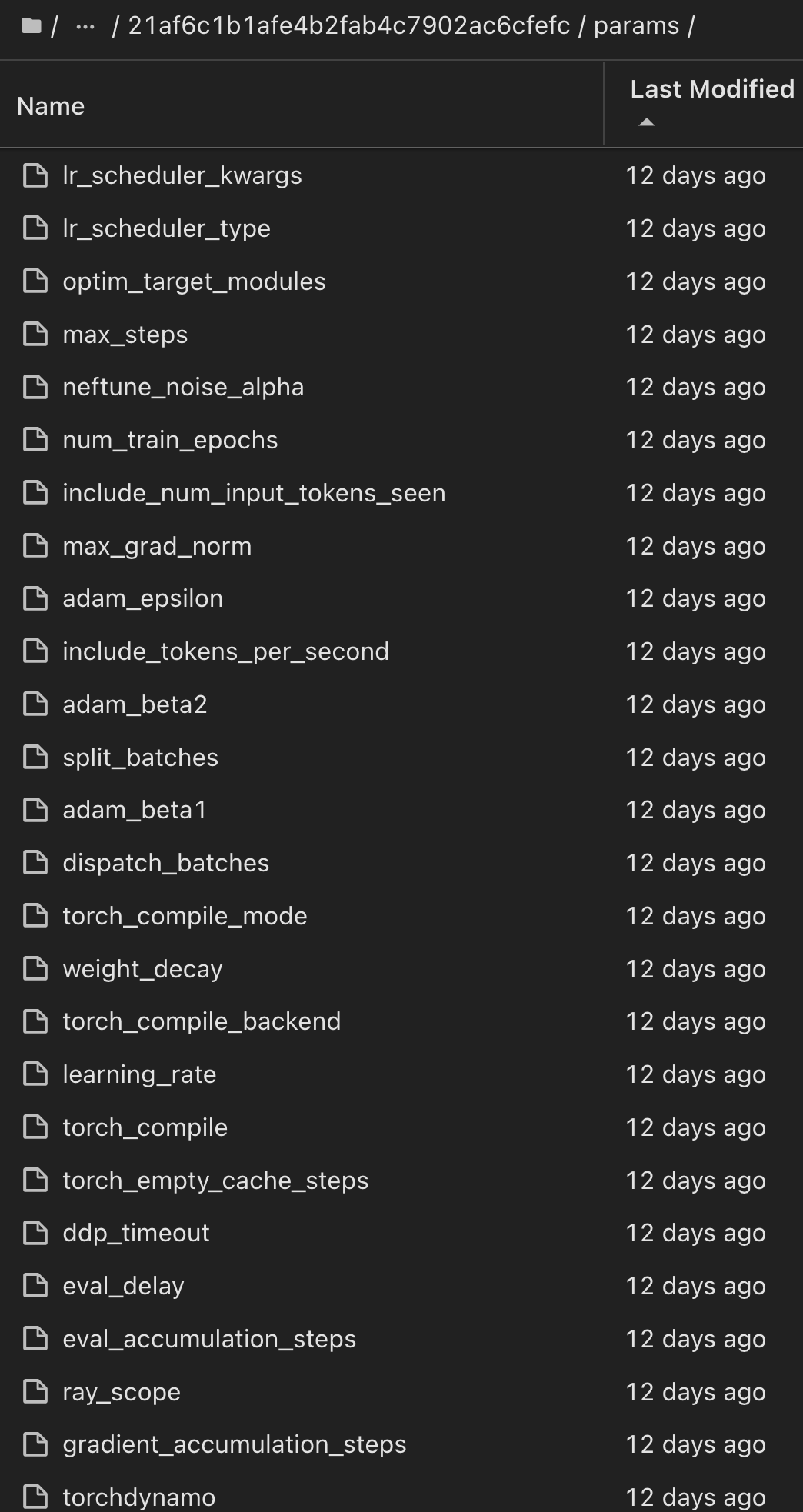
En el registro de modelos, después de guardar los modelos, versiones y etiquetas deseados, es posible rastrear el conjunto de datos, el modelo y el código específicos que se utilizaron para entrenar el modelo, así como el código específico que se utilizó para procesar los datos, cargar el tokenizador y el modelo, codificar, generar y descodificar el texto, guardar el modelo, finalizar el modelo, evaluar el modelo utilizando las métricas de perplexity snapshot_id's and your chosen metrics to MLflow by choosing the corerct experiment under `mlrun del menú activo, las pestañas de NLTK y perplexity correspondientes:
Del mismo modo, para nuestros phi-2_finetuned_model cuyos pesos cuantificados se calcularon a través de GPU o vGPU utilizando la torch biblioteca, podemos inspeccionar los siguientes artefactos intermedios, lo que permitiría la optimización del rendimiento, la escalabilidad (rendimiento/gaurantee SLA) y la reducción de costos de todo el flujo de trabajo:
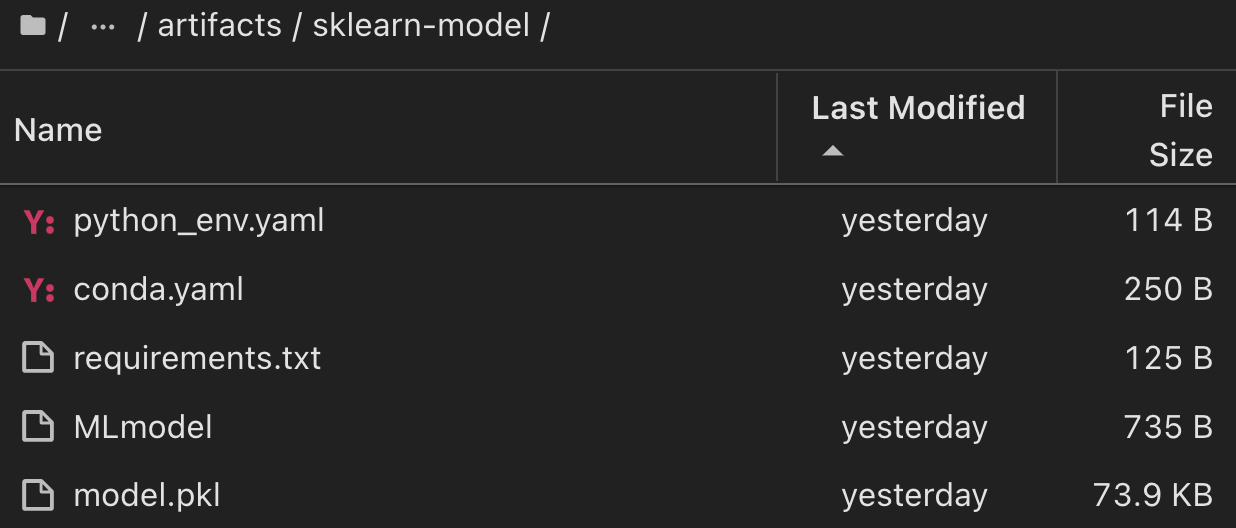
Para una sola ejecución de experimento con Scikit-learn y MLflow, la siguiente figura muestra los artefactos generados, conda entorno, MLmodel archivo y MLmodel directorio:
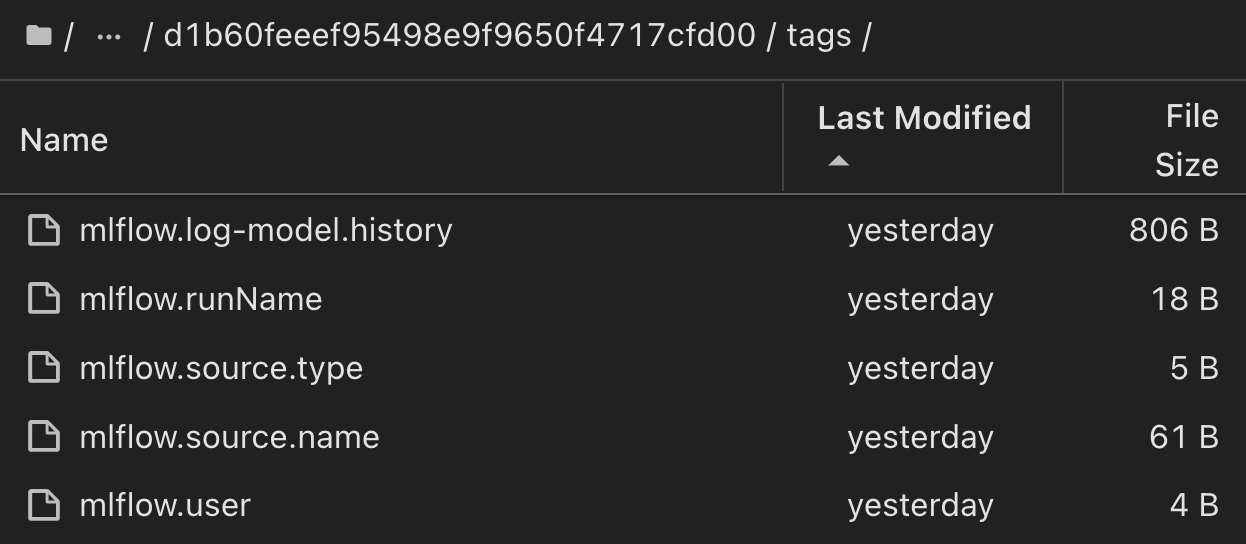
Los clientes pueden especificar etiquetas, por ejemplo, «predeterminada», «etapa», «proceso» o «cuello de botella» para organizar distintas características de sus ejecuciones de flujo de trabajo de IA, tomar nota de sus últimos resultados o contributors establecer un seguimiento del progreso de los desarrolladores del equipo de ciencia de datos. Si para la etiqueta por defecto ' ', su guardado mlflow.log-model.history, , , , mlflow.runName mlflow.source.type mlflow.source.name y mlflow.user en la pestaña JupyterHub del navegador de archivos activo actualmente:
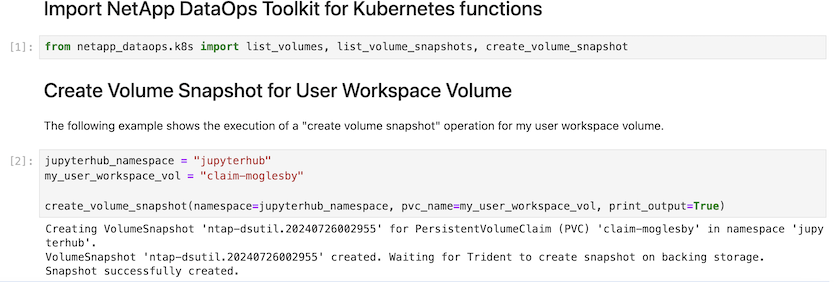
Por último, los usuarios tienen su propio Jupyter Workspace especificado, que se versiona y almacena en una reclamación de volumen persistente (PVC) en el clúster de Kubernetes. En la siguiente figura se muestra el espacio de trabajo Jupyter, que contiene el netapp_dataops.k8s paquete Python, y los resultados de una VolumeSnapshot :
Nuestra tecnología probada en la industria Snapshot® y otras tecnologías se utilizaron para garantizar la protección de datos a nivel empresarial, el movimiento y la compresión eficiente. Para otros casos prácticos de IA, consulte "AIPod de NetApp"la documentación.