

Arquitectura
 Sugerir cambios
Sugerir cambios
La puesta en marcha de Microsoft SQL Server con entorno MetroCluster requiere alguna explicación del diseño físico de un sistema MetroCluster.
MetroCluster refleja de forma síncrona los datos y la configuración entre dos clústeres de ONTAP en ubicaciones independientes o en dominios de fallos. MetroCluster proporciona almacenamiento disponible de forma continua para las aplicaciones gestionando automáticamente dos objetivos:
-
Objetivo de punto de recuperación cero (RPO) gracias al mirroring síncrono de los datos escritos en el clúster.
-
Objetivo de tiempo de recuperación (RTO) casi cero mediante el mirroring de la configuración y la automatización del acceso a los datos en el segundo sitio.
MetroCluster proporciona simplicidad con mirroring automático de datos y configuración entre los dos clústeres independientes ubicados en los dos sitios. A medida que se aprovisiona el almacenamiento en un clúster, se replica automáticamente en el segundo clúster del segundo centro. NetApp SyncMirror® proporciona una copia completa de todos los datos con un RPO cero. Esto significa que las cargas de trabajo de un sitio podrían conmutar en cualquier momento al sitio opuesto y seguir proporcionando datos sin pérdida de datos. MetroCluster gestiona el proceso de switchover de proporcionar acceso a los datos NAS y aprovisionados con SAN en el segundo sitio. El diseño de MetroCluster como solución validada contiene el dimensionamiento y la configuración que permiten realizar una conmutación de sitios dentro de períodos de tiempo de espera del protocolo o antes (normalmente menos de 120 segundos). Esto da como resultado un objetivo de punto de recuperación casi cero, y las aplicaciones pueden seguir accediendo a los datos sin incurrir en fallos. El MetroCluster está disponible en varias variaciones definidas en el entramado de almacenamiento del back-end.
MetroCluster está disponible en 3 configuraciones diferentes
-
Pares DE ALTA DISPONIBILIDAD con conectividad IP
-
Pares DE ALTA DISPONIBILIDAD con conectividad FC
-
Controladora única con conectividad FC

|
El término 'conectividad' hace referencia a la conexión de clúster usada para la replicación entre sitios. No hace referencia a los protocolos de host. Todos los protocolos del lado del host se admiten como de costumbre en una configuración de MetroCluster, independientemente del tipo de conexión utilizada para la comunicación entre clústeres. |
IP de MetroCluster
La configuración IP de MetroCluster para pares de alta disponibilidad utiliza dos o cuatro nodos por sitio. Esta opción de configuración aumenta la complejidad y los costes relacionados con la opción de dos nodos, pero ofrece una ventaja importante: La redundancia dentro del sitio. Un simple fallo de una controladora no requiere acceso a los datos a través de la WAN. El acceso a los datos sigue siendo local a través de la controladora local alternativa.
La mayoría de los clientes eligen la conectividad IP porque los requisitos de infraestructura son más simples. En el pasado, la conectividad entre sitios de alta velocidad solía ser más fácil de aprovisionar mediante switches FC y de fibra oscura; sin embargo, hoy en día los circuitos IP de alta velocidad y baja latencia son más fáciles de obtener.
La arquitectura además es más sencilla ya que las únicas conexiones entre sitios son para las controladoras. En MetroCluster conectados a FC SAN, una controladora escribe directamente en las unidades del sitio opuesto y, por lo tanto, requiere conexiones SAN, switches y puentes adicionales. En cambio, una controladora con una configuración IP escribe en las unidades opuestas a través de la controladora.
Para obtener información adicional, consulte la documentación oficial de ONTAP y. "Arquitectura y diseño de la solución MetroCluster IP".
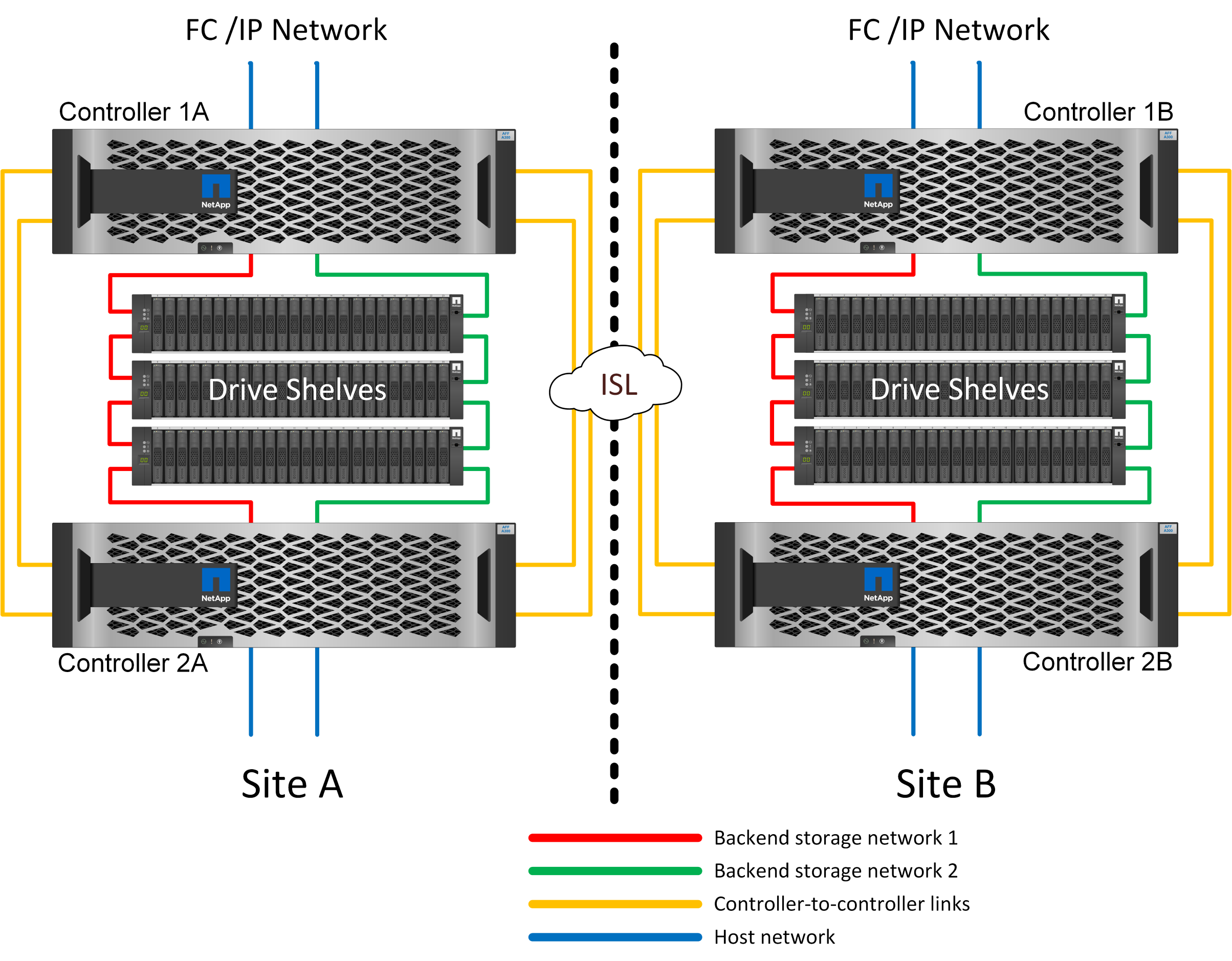
MetroCluster con conexión SAN FC de par de ALTA DISPONIBILIDAD
La configuración MetroCluster FC de par de alta disponibilidad utiliza dos o cuatro nodos por sitio. Esta opción de configuración aumenta la complejidad y los costes relacionados con la opción de dos nodos, pero ofrece una ventaja importante: La redundancia dentro del sitio. Un simple fallo de una controladora no requiere acceso a los datos a través de la WAN. El acceso a los datos sigue siendo local a través de la controladora local alternativa.
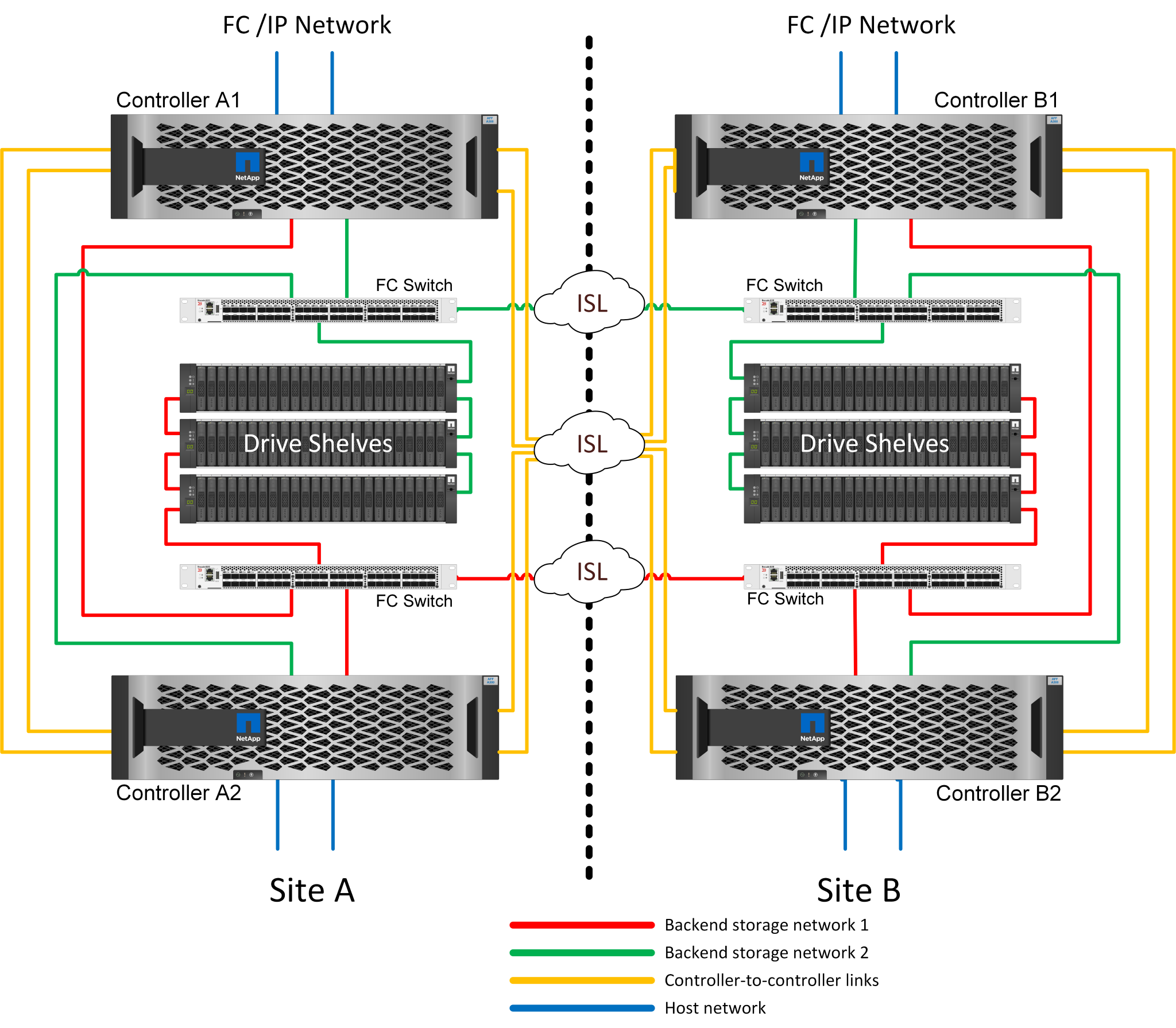
Algunas infraestructuras multisitio no están diseñadas para operaciones activo-activo, sino que se utilizan más como sitio principal y sitio de recuperación de desastres. En esta situación, generalmente es preferible una opción MetroCluster de una pareja de alta disponibilidad por las siguientes razones:
-
Aunque un clúster MetroCluster de dos nodos es un sistema de alta disponibilidad, el fallo inesperado de una controladora o de tareas de mantenimiento planificadas requiere que los servicios de datos deban estar online en el sitio opuesto. Si la conectividad de red entre los sitios no puede soportar el ancho de banda requerido, el rendimiento se ve afectado. La única opción sería también conmutar por error los diversos sistemas operativos host y los servicios asociados a la ubicación alternativa. El clúster MetroCluster de la pareja de alta disponibilidad elimina este problema porque la pérdida de una controladora hace que la conmutación al respaldo sea sencilla dentro del mismo sitio.
-
Algunas topologías de red no están diseñadas para el acceso entre sitios, sino que utilizan subredes diferentes o SAN FC aisladas. En estos casos, el clúster MetroCluster de dos nodos ya no funciona como un sistema de alta disponibilidad porque la controladora alternativa no puede proporcionar datos a los servidores del sitio opuesto. La opción MetroCluster de par de alta disponibilidad es necesaria para ofrecer una redundancia completa.
-
Si se considera una infraestructura de dos sitios como una única infraestructura de alta disponibilidad, la configuración de MetroCluster de dos nodos es adecuada. Sin embargo, si el sistema debe funcionar durante un largo período de tiempo tras el fallo del sitio, se prefiere un par de alta disponibilidad porque sigue proporcionando alta disponibilidad dentro de un único sitio.
MetroCluster FC de dos nodos conectado a SAN
La configuración de MetroCluster de dos nodos solo utiliza un nodo por sitio. Este diseño es más sencillo que la opción de pareja de alta disponibilidad porque hay menos componentes que configurar y mantener. También ha reducido las demandas de infraestructura en términos de cableado y conmutación FC. Por último, reduce los costes.
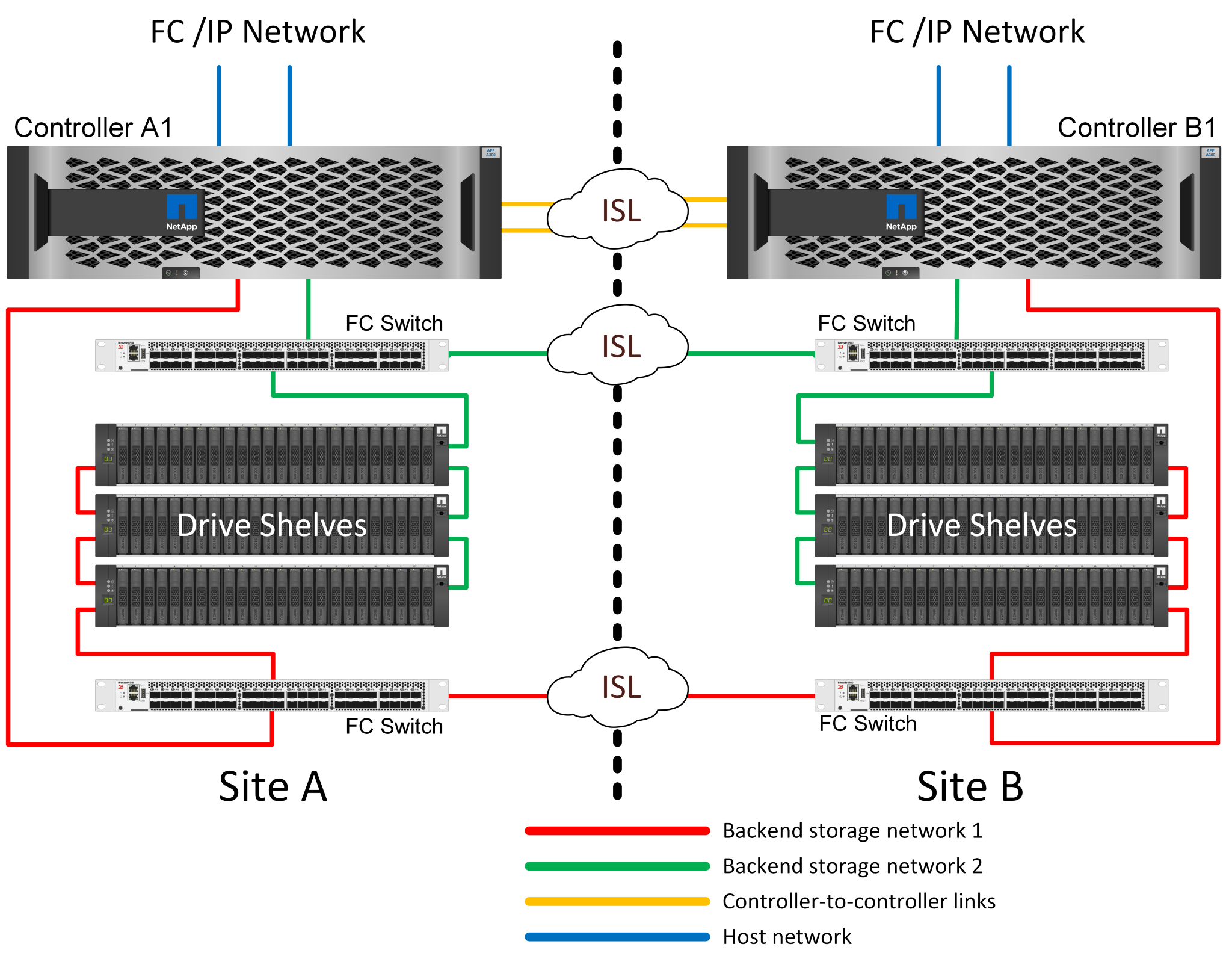
El impacto obvio de este diseño es que el fallo de una controladora en un único sitio significa que los datos están disponibles en el sitio opuesto. Esta restricción no es necesariamente un problema. Muchas empresas tienen operaciones de centros de datos multisitio con redes extendidas de alta velocidad y baja latencia que funcionan básicamente como una única infraestructura. En estos casos, la versión de dos nodos de MetroCluster es la configuración preferida. Varios proveedores de servicios utilizan actualmente sistemas de dos nodos a escala de petabytes.
Funcionalidades de resiliencia de MetroCluster
No hay puntos únicos de error en una solución de MetroCluster:
-
Cada controladora tiene dos rutas independientes a las bandejas de unidades en el sitio local.
-
Cada controladora tiene dos rutas independientes a las bandejas de unidades en el sitio remoto.
-
Cada controladora tiene dos rutas independientes a las controladoras del sitio opuesto.
-
En la configuración de par de alta disponibilidad, cada controladora tiene dos rutas desde su compañero local.
En resumen, puede eliminarse cualquier componente de la configuración sin poner en riesgo la capacidad de MetroCluster para suministrar datos. La única diferencia en términos de flexibilidad entre las dos opciones es que la versión del par de alta disponibilidad sigue siendo un sistema de almacenamiento de alta disponibilidad global tras un fallo del sitio.
SyncMirror
La protección para SQL Server con MetroCluster se basa en SyncMirror, que ofrece una tecnología de mirroring síncrono con escalabilidad horizontal y máximo rendimiento.
Protección de datos con SyncMirror
En el nivel más sencillo, la replicación síncrona implica que se debe realizar cualquier cambio en ambas partes del almacenamiento reflejado antes de que se reconozca. Por ejemplo, si una base de datos está escribiendo un registro o se está aplicando la revisión a un invitado VMware, no se debe perder nunca una escritura. Como nivel de protocolo, el sistema de almacenamiento no debe reconocer la escritura hasta que se haya comprometido a medios no volátiles en ambos sitios. Solo entonces es seguro proceder sin el riesgo de pérdida de datos.
El uso de una tecnología de replicación síncrona es el primer paso para diseñar y gestionar una solución de replicación síncrona. Lo más importante es comprender qué podría suceder durante varios escenarios de fallos planificados y no planificados. No todas las soluciones de replicación síncrona ofrecen las mismas funcionalidades. Si necesita una solución que proporcione un objetivo de punto de recuperación (RPO) de cero, lo que significa cero pérdida de datos, deben tenerse en cuenta todos los escenarios de fallo. En particular, ¿cuál es el resultado esperado cuando la replicación es imposible debido a la pérdida de conectividad entre sitios?
Disponibilidad de datos SyncMirror
La replicación de MetroCluster se basa en la tecnología de NetApp SyncMirror, que se ha diseñado para alternar eficientemente entre el modo síncrono y este se sale de él. Esta funcionalidad satisface los requisitos de los clientes que demandan replicación síncrona pero que también necesitan una alta disponibilidad para sus servicios de datos. Por ejemplo, si la conectividad con un sitio remoto se interrumpe, generalmente es preferible que el sistema de almacenamiento siga funcionando en un estado sin replicar.
Muchas soluciones de replicación síncrona solo pueden funcionar en modo síncrono. Este tipo de replicación compuesta por todos o nada se denomina a veces modo domino. Este tipo de sistemas de almacenamiento dejan de servir datos en lugar de permitir que las copias locales y remotas de datos se dessincronicen. Si la replicación se interrumpe de forma forzada, la resincronización puede requerir mucho tiempo y puede dejar al cliente expuesto a la pérdida de datos durante el tiempo que se restablece el mirroring.
SyncMirror no solo puede salir del modo síncrono sin problemas si no se puede acceder al sitio remoto, sino que también puede volver a sincronizar rápidamente con un estado RPO = 0 cuando se restaura la conectividad. La copia obsoleta de los datos en el sitio remoto también se puede conservar en estado utilizable durante la resincronización, lo que garantiza la existencia de copias locales y remotas de los datos en todo momento.
Cuando se requiere el modo domino, NetApp ofrece SnapMirror síncrono (SM-S). También existen opciones de nivel de aplicación, como Oracle DataGuard o SQL Server, grupos de disponibilidad Always On. El mirroring de discos a nivel de sistema operativo puede ser una opción. Consulte con su equipo de cuentas de partner o de NetApp para obtener más información y opciones.