

Apagar y encender un sitio único en una configuración IP de MetroCluster
 Sugerir cambios
Sugerir cambios
Si necesita realizar el mantenimiento del sitio o reubicar un solo sitio en una configuración IP de MetroCluster, debe saber cómo apagar y encender el sitio.
Si necesita reubicar y reconfigurar un sitio (por ejemplo, si necesita ampliar un clúster de cuatro nodos a uno de ocho nodos), no podrá completar estas tareas al mismo tiempo. Este procedimiento sólo cubre los pasos necesarios para realizar el mantenimiento del sitio o para reubicar un sitio sin cambiar su configuración.
El siguiente diagrama muestra una configuración de MetroCluster. El Cluster_B se apaga para realizar tareas de mantenimiento.
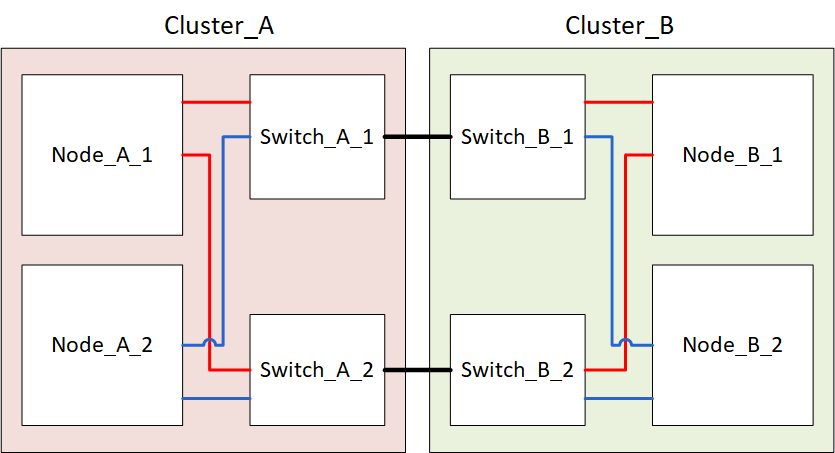
Apagar un sitio MetroCluster
Debe apagar un sitio y todo el equipo antes de que pueda comenzar el mantenimiento o la reubicación del sitio.
Todos los comandos de los siguientes pasos se emiten desde el sitio que permanece encendido.
-
Antes de comenzar, compruebe que los agregados no reflejados del sitio no están desconectados.
-
Compruebe el funcionamiento de la configuración de MetroCluster en ONTAP:
-
Compruebe si el sistema es multivía:
node run -node node-name sysconfig -a -
Compruebe si hay alertas de estado en ambos clústeres:
system health alert show -
Confirme la configuración del MetroCluster y que el modo operativo es normal:
metrocluster show -
Realice una comprobación de MetroCluster:
metrocluster check run -
Mostrar los resultados de la comprobación de MetroCluster:
metrocluster check show -
Compruebe si hay alertas de estado en los switches (si existen):
storage switch show -
Ejecute Config Advisor.
-
Después de ejecutar Config Advisor, revise el resultado de la herramienta y siga las recomendaciones del resultado para solucionar los problemas detectados.
-
-
Desde el sitio que desea mantener activo, implemente la conmutación de sitios:
metrocluster switchovercluster_A::*> metrocluster switchover
La operación puede tardar varios minutos en completarse.
-
Supervise y verifique que se haya completado la conmutación:
metrocluster operation showcluster_A::*> metrocluster operation show Operation: Switchover Start time: 10/4/2012 19:04:13 State: in-progress End time: - Errors: cluster_A::*> metrocluster operation show Operation: Switchover Start time: 10/4/2012 19:04:13 State: successful End time: 10/4/2012 19:04:22 Errors: - -
Si tiene una configuración IP de MetroCluster que ejecuta ONTAP 9.6 o posterior, espere a que los complejos del sitio de recuperación ante desastres se conecten y las operaciones de reparación se completen automáticamente.
En configuraciones IP de MetroCluster que ejecutan ONTAP 9,5 o una versión anterior, los nodos del sitio de recuperación ante desastres no arrancan automáticamente en ONTAP y los complejos permanecen sin conexión.
-
Mueva todos los volúmenes y LUN que pertenecen a los agregados no reflejados sin conexión.
-
Mueva los volúmenes sin conexión.
cluster_A::* volume offline <volume name>
-
Desconecte las LUN.
cluster_A::* lun offline lun_path <lun_path>
-
-
Mover agregados no reflejados sin conexión:
storage aggregate offlinecluster_A*::> storage aggregate offline -aggregate <aggregate-name>
-
En función de su configuración y versión de ONTAP, identifique y mueva los complejos afectados sin conexión que se encuentren en la ubicación ante desastres (Cluster_B).
Debe mover los siguientes complejos sin conexión:
-
Complejos no reflejados que residen en discos ubicados en el sitio de recuperación ante desastres.
Si no mueve los complejos no reflejados en el sitio de recuperación ante desastres sin conexión, se puede producir una interrupción del servicio cuando el sitio de recuperación ante desastres se apague más tarde.
-
Plexes reflejados que residen en discos ubicados en el centro de recuperación ante desastres para el mirroring de agregados. Una vez que se han movido fuera de línea, no se puede acceder a los complejos.
-
Identifique los complejos afectados.
Los complejos que son propiedad de nodos en el sitio superviviente consisten en discos de la piscina 1. Los complejos que son propiedad de nodos en el sitio de desastre consisten en discos de la piscina 0.
Cluster_A::> storage aggregate plex show -fields aggregate,status,is-online,Plex,pool aggregate plex status is-online pool ------------ ----- ------------- --------- ---- Node_B_1_aggr0 plex0 normal,active true 0 Node_B_1_aggr0 plex1 normal,active true 1 Node_B_2_aggr0 plex0 normal,active true 0 Node_B_2_aggr0 plex5 normal,active true 1 Node_B_1_aggr1 plex0 normal,active true 0 Node_B_1_aggr1 plex3 normal,active true 1 Node_B_2_aggr1 plex0 normal,active true 0 Node_B_2_aggr1 plex1 normal,active true 1 Node_A_1_aggr0 plex0 normal,active true 0 Node_A_1_aggr0 plex4 normal,active true 1 Node_A_1_aggr1 plex0 normal,active true 0 Node_A_1_aggr1 plex1 normal,active true 1 Node_A_2_aggr0 plex0 normal,active true 0 Node_A_2_aggr0 plex4 normal,active true 1 Node_A_2_aggr1 plex0 normal,active true 0 Node_A_2_aggr1 plex1 normal,active true 1 14 entries were displayed. Cluster_A::>
Los plex afectados son los que son remotos al clúster A. La siguiente tabla muestra si los discos son locales o remotos en relación con el clúster A:
Nodo
Discos en el pool
¿Los discos se deben establecer sin conexión?
Ejemplo de complejos que se van a mover fuera de línea
Nodo _A_1 y nodo _A_2
Discos en el pool 0
No Los discos son locales para el clúster A.
-
Discos en el pool 1
Sí. Los discos son remotos para el clúster A.
Node_A_1_aggr0/plex4
Node_A_1_aggr1/plex1
Node_A_2_aggr0/plex4
Node_A_2_aggr1/plex1
Nodo _B_1 y nodo _B_2
Discos en el pool 0
Sí. Los discos son remotos para el clúster A.
Node_B_1_aggr1/plex0
Node_B_1_aggr0/plex0
Node_B_2_aggr0/plex0
Node_B_2_aggr1/plex0
Discos en el pool 1
-
Mueva los complejos afectados sin conexión:
storage aggregate plex offline
storage aggregate plex offline -aggregate Node_B_1_aggr0 -plex plex0
+

Realice este paso para todos los plexes que tengan discos remotos para Cluster_A. -
-
Desconecta de forma persistente los puertos del switch ISL según el tipo de switch.
-
Detenga los nodos ejecutando el siguiente comando en cada nodo:
node halt -inhibit-takeover true -skip-lif-migration true -node <node-name> -
Apague el equipo en el sitio de desastre.
Debe apagar el siguiente equipo en el orden indicado:
-
Controladoras de almacenamiento: Las controladoras de almacenamiento actualmente deben estar en
LOADERaviso, debe apagarlos por completo. -
Switches IP de MetroCluster
-
Bandejas de almacenamiento
-
Reubicación del sitio de alimentación fuera del MetroCluster
Una vez apagado el sitio, puede comenzar a realizar tareas de mantenimiento. Este procedimiento es el mismo, tanto si se reubican los componentes de MetroCluster dentro del mismo centro de datos como si se reubican a otro centro de datos.
-
El hardware debe cablearse del mismo modo que el sitio anterior.
-
Si la velocidad, longitud o número del enlace entre switches (ISL) ha cambiado, todos ellos deben volver a configurarse.
-
Verifique que el cableado de todos los componentes se registre con cuidado para poder volver a conectarlo correctamente en la nueva ubicación.
-
Reubicar físicamente todo el hardware, controladores de almacenamiento, conmutadores IP y estantes de almacenamiento.
-
Configure los puertos ISL y compruebe la conectividad entre sitios.
-
Encienda los interruptores IP.
No encienda ningún otro equipo.
-
-
Utilice herramientas en los switches (según estén disponibles) para verificar la conectividad entre sitios.
Solo debe continuar si los enlaces están correctamente configurados y estables. -
Vuelva a desactivar los vínculos si se encuentran estables.
Encienda la configuración de MetroCluster y vuelva al funcionamiento normal
Tras completar el mantenimiento o mover el sitio, debe encender el sitio y restablecer la configuración de MetroCluster.
Todos los comandos de los pasos siguientes se emiten en el sitio que se enciende.
-
Encienda los switches.
Primero debe encender los interruptores. Es posible que se hayan encendido durante el paso anterior si se reubicó el sitio.
-
Vuelva a configurar el enlace entre switches (ISL) si es necesario o si no se ha completado como parte de la reubicación.
-
Habilite el ISL si se ha completado la delimitación.
-
Verifique el ISL.
-
-
Encienda las controladoras de almacenamiento y espere hasta que vea el
LOADERprompt. Las controladoras no deben arrancarse por completo.Si el inicio automático está activado, pulse
Ctrl+Cpara detener el arranque automático de las controladoras.
No encienda las bandejas antes de encender las controladoras. De este modo se evita que las controladoras realicen un arranque no intencionado en ONTAP. -
Encienda las bandejas teniendo tiempo suficiente para que se enciendan por completo.
-
Verifique que el almacenamiento sea visible desde el modo de mantenimiento.
-
Arrancar en modo de mantenimiento:
boot_ontap maint -
Compruebe que el almacenamiento está visible en el sitio superviviente.
-
Verifica que el almacenamiento local y remoto sea visible desde el nodo en modo de mantenimiento:
disk show -v
-
-
Detenga los nodos:
halt -
Restablezca la configuración de MetroCluster.
Siga las instrucciones de "Verificación de que su sistema está listo para una conmutación de estado" Para llevar a cabo operaciones de reparación y conmutación de estado de acuerdo con su configuración de MetroCluster.