

HA añadido más detalles
 Sugerir cambios
Sugerir cambios
Corazón de disco DE ALTA DISPONIBILIDAD, buzón de correo de alta disponibilidad, corazón de alta disponibilidad, conmutación por error de alta disponibilidad y trabajo de restauración para mejorar la protección de datos.
Latido del disco
A pesar de que la arquitectura de alta disponibilidad de ONTAP Select aprovecha muchas de las rutas de código utilizadas por los arrays FAS tradicionales, existen algunas excepciones. Una de estas excepciones es la implementación de la búsqueda de corazón basada en disco, un método de comunicación no basado en red utilizado por los nodos de clúster para evitar que el aislamiento de red cause un comportamiento de cerebro dividido. Una situación de cerebro dividido es el resultado de la partición de los clústeres, normalmente causada por fallos de red, en los que cada lado cree que la otra está inactiva e intenta hacerse cargo de los recursos del clúster.
Las implementaciones de alta disponibilidad para empresas deben gestionar este tipo de escenario sin problemas. ONTAP lo hace a través de un método personalizado basado en disco de latido. Esta es la tarea del buzón de alta disponibilidad, una ubicación en el almacenamiento físico que utilizan los nodos del clúster para pasar mensajes de latido. Esto ayuda al clúster a determinar la conectividad y, por lo tanto, a definir el quórum en caso de una conmutación por error.
En las cabinas FAS, que usan una arquitectura de alta disponibilidad de almacenamiento compartido, ONTAP resuelve los problemas de cerebro dividido de las siguientes maneras:
-
Reservas persistentes de SCSI
-
Metadatos de alta disponibilidad persistente
-
Estado DE ALTA DISPONIBILIDAD enviado a través de la interconexión de alta disponibilidad
Sin embargo, con la arquitectura nada compartida de un clúster de ONTAP Select, un nodo solo puede ver su propio almacenamiento local y no el del partner de alta disponibilidad. Por lo tanto, cuando las particiones de red aíslan cada lado de un par de alta disponibilidad, los métodos anteriores para determinar el quórum del clúster y el comportamiento de la conmutación por error no están disponibles.
Aunque no se puede utilizar el método existente de detección y evitación del cerebro dividido, todavía se requiere un método de mediación, que se ajuste a las limitaciones de un entorno sin compartir. ONTAP Select amplía aún más la infraestructura de buzones existente, lo que le permite actuar como un método de mediación en caso de partición en la red. Debido a que el almacenamiento compartido no está disponible, la mediación se logra a través del acceso a los discos de buzón a través de NAS. Estos discos se distribuyen por el clúster, incluido el mediador en un clúster de dos nodos, utilizando el protocolo iSCSI. Por lo tanto, las decisiones inteligentes sobre conmutación por error pueden tomar un nodo de clústeres en función del acceso a estos discos. Si un nodo puede acceder a los discos de buzón de otros nodos fuera de su compañero de alta disponibilidad, probablemente estará activo y en buen estado.

|
La arquitectura de buzones y el método de latido basado en disco para resolver problemas de quórum de clúster y de cerebro dividido son las razones por las que la variante multinodo de ONTAP Select requiere cuatro nodos independientes o un mediador para un clúster de dos nodos. |
Contabilización DE buzón HA
La arquitectura de buzones de correo de alta disponibilidad utiliza un modelo de post de mensaje. A intervalos repetidos, los nodos del clúster publican mensajes a todos los demás discos del buzón en el clúster, incluido el mediador, indicando que el nodo está activo y en ejecución. Dentro de un clúster en buen estado en cualquier momento, un único disco de buzón de un nodo de clúster tiene mensajes publicados desde todos los demás nodos del clúster.
Conectado a cada nodo de clúster Select es un disco virtual que se utiliza específicamente para el acceso compartido de los buzones. Este disco se conoce como el disco del buzón de correo del mediador, porque su función principal es actuar como método de mediación en cluster en caso de fallos de nodo o partición de red. Este disco de buzón contiene particiones para cada nodo de clúster y es montado a través de una red iSCSI por otros nodos de clúster Select. Periódicamente, estos nodos publican Estados de mantenimiento en la partición adecuada del disco del buzón. El uso de discos de buzón accesibles para la red repartidos por todo el clúster permite inferir el estado de los nodos a través de una matriz de accesibilidad. Por ejemplo, los nodos de clúster A y B pueden publicar en el buzón del nodo D del clúster, pero no en el buzón del nodo C. Además, el nodo D del clúster no puede publicar el buzón del nodo C, por lo que es probable que el nodo C esté inactivo o esté aislado de la red y que deba hacerse cargo.
Ha latido del corazón
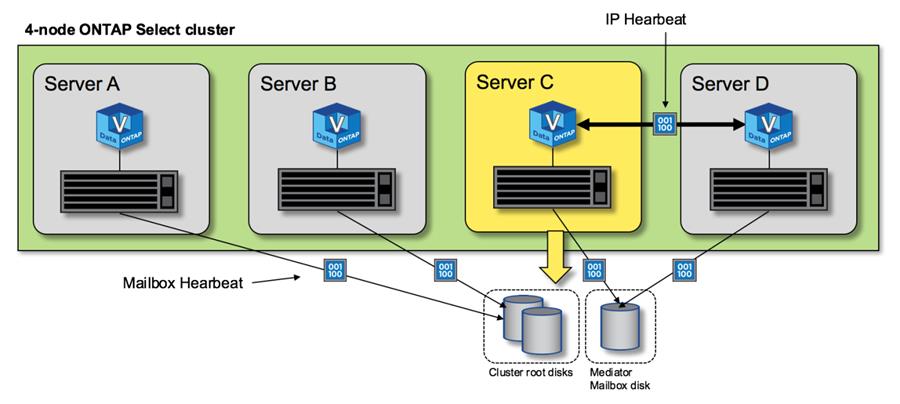
Al igual que sucede con las plataformas FAS de NetApp, ONTAP Select envía periódicamente mensajes de latido de alta disponibilidad a través de la interconexión de alta disponibilidad. En el clúster ONTAP Select, se realiza a través de una conexión de red TCP/IP que existe entre los partners de alta disponibilidad. Además, los mensajes latido de disco se transmiten a todos los discos de buzón de alta disponibilidad, incluido el mediador de discos de buzón. Estos mensajes se transmiten cada pocos segundos y se leen periódicamente. La frecuencia con la que se envían y se reciben estos mensajes permite que el clúster de ONTAP Select detecte eventos de fallo de alta disponibilidad en un plazo aproximado de 15 segundos, es decir, la misma ventana disponible en las plataformas FAS. Cuando ya no se leen mensajes de latido, se activa un evento de conmutación por error.
La figura siguiente muestra el proceso de envío y recepción de mensajes de latido a través de los discos de interconexión y mediador de alta disponibilidad desde la perspectiva de un único nodo de clúster ONTAP Select, nodo C.
|
|
Los latidos de red se envían a través de la interconexión de alta disponibilidad al partner de alta disponibilidad, nodo D, mientras que los latidos del disco usan discos de buzón en todos los nodos del clúster, A, B, C y D. |
Latidos de alta disponibilidad en un cluster de cuatro nodos: Estado estable
Conmutación al nodo primario y al nodo primario DE HA
Durante una operación de recuperación tras fallos, el nodo que aún continúa activo asume la responsabilidad de servir datos para su nodo del mismo nivel mediante la copia local de los datos de su partner de alta disponibilidad. Las operaciones de I/o del cliente pueden continuar sin interrupciones, pero los cambios en estos datos se deben replicar de nuevo antes de que se pueda producir la devolución. Tenga en cuenta que ONTAP Select no admite un retorno de la memoria forzado porque se pierden los cambios almacenados en el nodo superviviente.
La operación de repetición de sincronización se activa automáticamente cuando el nodo reiniciado se vuelve a unir al clúster. El tiempo necesario para la sincronización posterior depende de varios factores. Estos factores incluyen el número de cambios que se deben replicar, la latencia de red entre los nodos y la velocidad de los subsistemas de disco en cada nodo. Es posible que el tiempo necesario para la sincronización posterior supere la ventana de autoretorno de 10 minutos. En este caso, se necesita una devolución manual después de la sincronización. El progreso de la sincronización se puede supervisar con el siguiente comando:
storage aggregate status -r -aggregate <aggregate name>