

ONTAP Select HA mejora la protección de datos
 Sugerir cambios
Sugerir cambios
La alta disponibilidad (HA) mediante latidos de disco, buzón HA, latidos HA, conmutación por error HA y Giveback funcionan para mejorar la protección de datos.
Latido del disco
Aunque la arquitectura ONTAP Select HA aprovecha muchas de las rutas de código utilizadas por los arreglos FAS tradicionales, existen algunas excepciones. Una de estas excepciones es la implementación del mecanismo de latido basado en disco, un método de comunicación independiente de la red que utilizan los nodos del clúster para evitar que el aislamiento de la red provoque un comportamiento de split-brain. Un escenario de split-brain es el resultado de la partición del clúster, generalmente causada por fallas de red, en la que cada lado cree que el otro está inactivo e intenta tomar el control de los recursos del clúster.
Las implementaciones de HA de nivel empresarial deben gestionar este tipo de escenario de forma eficiente. ONTAP hace esto mediante un método personalizado de latido basado en disco. Esta es la función del buzón de HA, una ubicación en el almacenamiento físico que utilizan los nodos del clúster para pasar mensajes de latido. Esto ayuda al clúster a determinar la conectividad y, por lo tanto, a definir el quórum en caso de una conmutación por error.
En los sistemas FAS, que utilizan una arquitectura de almacenamiento compartido de alta disponibilidad, ONTAP resuelve los problemas de split-brain de las siguientes maneras:
-
Reservas persistentes SCSI
-
Metadatos HA persistentes
-
Estado HA enviado a través de la interconexión de alta disponibilidad
Sin embargo, en la arquitectura sin almacenamiento compartido de un clúster ONTAP Select, un nodo solo puede ver su propio almacenamiento local y no el del socio de alta disponibilidad. Por lo tanto, cuando el particionamiento de red aísla cada lado de un par de alta disponibilidad, los métodos anteriores para determinar el quórum del clúster y el comportamiento de conmutación por error no están disponibles.
Aunque no se puede utilizar el método actual de detección y prevención de split-brain, sigue siendo necesario un método de mediación que se ajuste a las limitaciones de un entorno sin recursos compartidos. ONTAP Select amplía la infraestructura de buzón existente, permitiéndole actuar como método de mediación en caso de partición de red. Dado que el almacenamiento compartido no está disponible, la mediación se realiza mediante el acceso a los discos del buzón a través de NAS. Estos discos se distribuyen por todo el clúster, incluido el mediador en un clúster de dos nodos, utilizando el protocolo iSCSI. Por lo tanto, un nodo del clúster puede tomar decisiones de conmutación por error inteligentes en función del acceso a estos discos. Si un nodo puede acceder a los discos del buzón de otros nodos fuera de su socio de alta disponibilidad, es probable que esté operativo y funcionando correctamente.

|
La arquitectura de buzón y el método de latido basado en disco para resolver los problemas de quórum del clúster y de cerebro dividido son las razones por las que la variante multinodo de ONTAP Select requiere cuatro nodos separados o un mediador para un clúster de dos nodos. |
Publicación en el buzón de HA
La arquitectura de buzones de alta disponibilidad utiliza un modelo de envío de mensajes. A intervalos regulares, los nodos del clúster envían mensajes a todos los demás discos de buzón del clúster, incluido el mediador, indicando que el nodo está activo y funcionando. En un clúster en buen estado, en cualquier momento, un único disco de buzón en un nodo del clúster recibe mensajes de todos los demás nodos del clúster.
A cada nodo del clúster Select se le adjunta un disco virtual que se utiliza específicamente para el acceso compartido al buzón. Este disco se denomina disco de buzón mediador, porque su función principal es actuar como un método de mediación del clúster en caso de fallos de nodos o particionamiento de red. Este disco de buzón contiene particiones para cada nodo del clúster y es montado a través de una red iSCSI por otros nodos del clúster Select. Periódicamente, estos nodos publican estados de salud en la partición correspondiente del disco de buzón. El uso de discos de buzón accesibles por red distribuidos en todo el clúster te permite inferir el estado de los nodos mediante una matriz de accesibilidad. Por ejemplo, los nodos del clúster A y B pueden publicar en el buzón del nodo del clúster D, pero no en el buzón del nodo C. Además, el nodo del clúster D no puede publicar en el buzón del nodo C, así que probablemente el nodo C esté caído o aislado de la red y debería ser tomado por otro nodo.
Latidos de HA
Al igual que con las plataformas FAS de NetApp, ONTAP Select envía periódicamente mensajes de latido de alta disponibilidad a través de la interconexión de alta disponibilidad. Dentro del clúster de ONTAP Select, esto se realiza mediante una conexión de red TCP/IP que existe entre los socios de alta disponibilidad. Además, se envían mensajes de latido basados en disco a todos los discos de buzón de alta disponibilidad, incluidos los discos de buzón del mediador. Estos mensajes se envían cada pocos segundos y se leen periódicamente. La frecuencia con la que se envían y reciben permite que el clúster de ONTAP Select detecte eventos de fallo de alta disponibilidad en aproximadamente 15 segundos, el mismo intervalo disponible en las plataformas FAS. Cuando los mensajes de latido dejan de leerse, se activa un evento de conmutación por error.
La siguiente figura muestra el proceso de envío y recepción de mensajes de latido a través de la interconexión de alta disponibilidad y los discos mediadores desde la perspectiva de un único nodo del clúster ONTAP Select, el nodo C.
|
|
Los latidos de red se envían a través de la interconexión de alta disponibilidad al partner de alta disponibilidad, el nodo D, mientras que los latidos de disco usan discos de buzón en todos los nodos del clúster, A, B, C y D. |
HA funcionando en un clúster de cuatro nodos: estado estable 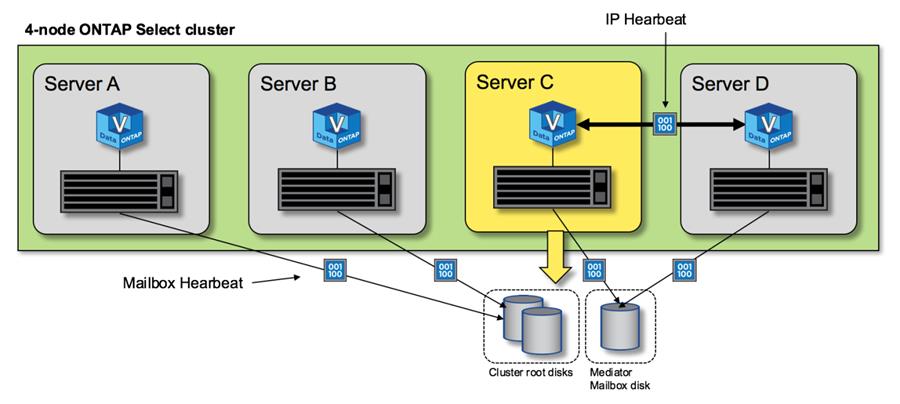
Conmutación por error y devolución de alta disponibilidad
Durante una operación de conmutación por error, el nodo superviviente asume las responsabilidades de servicio de datos de su nodo par utilizando la copia local de los datos de su socio de alta disponibilidad. Las operaciones de E/S del cliente pueden continuar sin interrupciones, pero los cambios en estos datos deben replicarse antes de que se pueda realizar la devolución. Ten en cuenta que ONTAP Select no admite la devolución forzada, ya que esto provoca la pérdida de los cambios almacenados en el nodo superviviente.
La operación de sincronización inversa se activa automáticamente cuando el nodo reiniciado se reincorpora al clúster. El tiempo necesario para la sincronización inversa depende de varios factores. Estos factores incluyen la cantidad de cambios que deben replicarse, la latencia de red entre los nodos y la velocidad de los subsistemas de disco en cada nodo. Es posible que el tiempo requerido para la sincronización inversa supere el intervalo de devolución automática de 10 minutos. En este caso, se requiere una devolución manual después de la sincronización inversa. El progreso de la sincronización inversa se puede supervisar mediante el siguiente comando:
storage aggregate status -r -aggregate <aggregate name>