

Sustituya un módulo I/o - AFF A700 y FAS9000
 Sugerir cambios
Sugerir cambios
Para reemplazar un módulo de E/S, debe realizar una secuencia específica de tareas.
-
Puede utilizar este procedimiento con todas las versiones de ONTAP admitidas por el sistema
-
Todos los demás componentes del sistema deben funcionar correctamente; si no es así, debe ponerse en contacto con el soporte técnico.
Paso 1: Apague el controlador dañado
Puede apagar o hacerse cargo de la controladora dañada siguiendo diferentes procedimientos, en función de la configuración del hardware del sistema de almacenamiento.
Toma el control y detén el controlador dañado para que el controlador sano continúe sirviendo datos desde el almacenamiento del controlador dañado. Para hacer esto, suprimes la creación automática de casos en AutoSupport, deshabilitas la devolución automática y llevas el controlador dañado al prompt LOADER. El prompt LOADER es el estado detenido seguro desde el cual puedes reemplazar la FRU.
-
Si dispone de un sistema SAN, debe haber comprobado los mensajes de evento
cluster kernel-service show) para el blade SCSI de la controladora dañada. `cluster kernel-service show`El comando (desde el modo avanzado priv) muestra el nombre del nodo, "estado del quórum" de ese nodo, el estado de disponibilidad de ese nodo y el estado operativo de ese nodo.Cada proceso SCSI-blade debe quórum con los otros nodos del clúster. Todos los problemas deben resolverse antes de continuar con el reemplazo.
-
Si tiene un clúster con más de dos nodos, debe estar en quórum. Si el clúster no tiene quórum o si una controladora en buen estado muestra falso según su condición, debe corregir el problema antes de apagar la controladora dañada; consulte "Sincronice un nodo con el clúster".
-
Si AutoSupport está habilitado, elimine la creación automática de casos invocando un mensaje de AutoSupport:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hEsto evita que se abran casos de soporte automático durante tu ventana de mantenimiento planificada. La duración máxima de la supresión es de 72 horas. Si tu mantenimiento termina antes de tiempo, puedes volver a habilitar la creación de casos invocando un mensaje AutoSupport con
MAINT=END. Para más información, consulta "Cómo suprimir la creación automática de casos durante las ventanas de mantenimiento programadas".El siguiente mensaje de AutoSupport suprime la creación automática de casos durante dos horas:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Desactivar devolución automática:
-
Ingrese el siguiente comando desde la consola del controlador en buen estado:
storage failover modify -node impaired_node_name -auto-giveback false -
Ingresar
ycuando vea el mensaje "¿Desea desactivar la devolución automática?"
-
-
Lleve la controladora dañada al aviso DEL CARGADOR:
Si el controlador dañado está mostrando… Realice lo siguiente… El aviso del CARGADOR
Vaya al paso siguiente.
Esperando devolución…
Pulse Ctrl-C y, a continuación, responda
ycuando se le solicite.Solicitud del sistema o solicitud de contraseña
Retome o detenga el controlador dañado del controlador en buen estado:
storage failover takeover -ofnode impaired_node_name -halt trueEl parámetro -halt true lleva al símbolo del sistema de Loader.
Para apagar el controlador dañado, debe determinar el estado del controlador y, si es necesario, cambiar el controlador para que el controlador correcto siga sirviendo datos del almacenamiento del controlador dañado.
-
Debe dejar las fuentes de alimentación encendidas al final de este procedimiento para proporcionar alimentación a la controladora en buen estado.
-
Compruebe el estado de MetroCluster para determinar si el controlador dañado ha cambiado automáticamente al controlador en buen estado:
metrocluster show -
En función de si se ha producido una conmutación automática, proceda según la siguiente tabla:
Si el controlador está dañado… Realice lo siguiente… Se ha cambiado automáticamente
Continúe con el próximo paso.
No se ha cambiado automáticamente
Realice una operación de conmutación de sitios planificada desde el controlador en buen estado:
metrocluster switchoverNo se ha cambiado automáticamente, ha intentado efectuar una conmutación con el
metrocluster switchovery se vetó la conmutaciónRevise los mensajes de veto y, si es posible, resuelva el problema e inténtelo de nuevo. Si no puede resolver el problema, póngase en contacto con el soporte técnico.
-
Resincronice los agregados de datos ejecutando el
metrocluster heal -phase aggregatescomando del clúster superviviente.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Si la curación es vetada, usted tiene la opción de reemitir el
metrocluster healcon el-override-vetoesparámetro. Si utiliza este parámetro opcional, el sistema anula cualquier vetoo suave que impida la operación de reparación. -
Compruebe que se ha completado la operación con el comando MetroCluster operation show.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Compruebe el estado de los agregados mediante
storage aggregate showcomando.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Repare los agregados raíz mediante el
metrocluster heal -phase root-aggregatescomando.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Si la curación es vetada, usted tiene la opción de reemitir el
metrocluster healcomando con el parámetro -override-vetoes. Si utiliza este parámetro opcional, el sistema anula cualquier vetoo suave que impida la operación de reparación. -
Compruebe que la operación reparar se ha completado mediante el
metrocluster operation showcomando en el clúster de destino:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
En el módulo del controlador dañado, desconecte las fuentes de alimentación.
Paso 2: Sustituya los módulos de E/S.
Para sustituir un módulo de E/S, búsquelo dentro del chasis y siga la secuencia específica de pasos.
-
Si usted no está ya conectado a tierra, correctamente tierra usted mismo.
-
Desconecte todos los cables asociados al módulo de E/S de destino.
Asegúrese de etiquetar los cables para saber de dónde proceden.
-
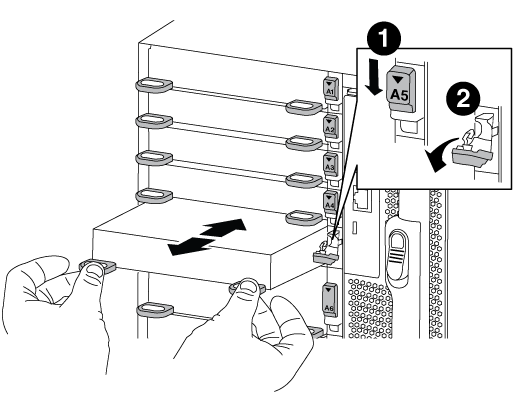
Extraiga el módulo de I/o de destino del chasis:
-
Pulse el botón de leva numerado y con letras.
El botón de leva se aleja del chasis.
-
Gire el pestillo de la leva hacia abajo hasta que esté en posición horizontal.
El módulo de E/S se desacopla del chasis y se mueve aproximadamente 1/2 pulgadas fuera de la ranura de E/S.
-
Extraiga el módulo de E/S del chasis tirando de las lengüetas de tiro de los lados de la cara del módulo.
Asegúrese de realizar un seguimiento de la ranura en la que se encontraba el módulo de E/S.

Pestillo de leva de E/S numerado y con letras

Pestillo de leva de E/S completamente desbloqueado
-
-
Coloque el módulo de E/S a un lado.
-
Instale el módulo de E/S de repuesto en el chasis deslizando suavemente el módulo de E/S en la ranura hasta que el pestillo de la leva de E/S con letras y numerado comience a acoplarse con el pasador de leva de E/S y, a continuación, empuje el pestillo de leva de E/S hasta que bloquee el módulo en su lugar.
-
Recuperar el módulo de E/S, según sea necesario.
Paso 3: Reinicie el controlador después de sustituir el módulo de I/O.
Después de sustituir un módulo de I/o, debe reiniciar el módulo de la controladora.

|
Si el nuevo módulo de E/S no es el mismo modelo que el módulo con errores, primero debe reiniciar el BMC. |
-
Reinicie el BMC si el módulo de sustitución no es el mismo modelo que el módulo antiguo:
-
Desde el aviso DEL CARGADOR, cambie al modo de privilegio avanzado:
priv set advanced -
Reinicie el BMC:
sp reboot
-
-
Desde el aviso del CARGADOR, reinicie el nodo:
bye
Esto reinicializa las tarjetas PCIe y otros componentes y reinicia el nodo. -
Si el sistema está configurado para admitir la interconexión de clúster de 10 GbE y conexiones de datos en NIC de 40 GbE o puertos integrados, convierta estos puertos a conexiones de 10 GbE mediante el
nicadmin convertComando del modo de mantenimiento.
Asegúrese de salir del modo de mantenimiento después de completar la conversión. -
Devolver al nodo a su funcionamiento normal:
storage failover giveback -ofnode impaired_node_name -
Si la devolución automática está desactivada, vuelva a habilitarla:
storage failover modify -node local -auto-giveback true
Si su sistema está en una configuración MetroCluster de dos nodos, debe volver a los agregados como se describe en el siguiente paso.
Paso 4: Vuelva a cambiar los agregados en una configuración MetroCluster de dos nodos
Esta tarea solo se aplica a configuraciones MetroCluster de dos nodos.
-
Compruebe que todos los nodos estén en el
enabledprovincia:metrocluster node showcluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
Compruebe que la resincronización se haya completado en todas las SVM:
metrocluster vserver show -
Compruebe que las migraciones LIF automáticas que realizan las operaciones de reparación se han completado correctamente:
metrocluster check lif show -
Lleve a cabo la conmutación de estado mediante el
metrocluster switchbackcomando desde cualquier nodo del clúster superviviente. -
Compruebe que la operación de conmutación de estado ha finalizado:
metrocluster showLa operación de conmutación de estado ya está en ejecución cuando un clúster está en el
waiting-for-switchbackprovincia:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
La operación de conmutación de estado se completa cuando los clústeres están en el
normalestado:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
Si una conmutación de regreso tarda mucho tiempo en terminar, puede comprobar el estado de las líneas base en curso utilizando el
metrocluster config-replication resync-status showcomando. -
Restablecer cualquier configuración de SnapMirror o SnapVault.
Paso 5: Devuelva la pieza que falló a NetApp
Devuelva la pieza que ha fallado a NetApp, como se describe en las instrucciones de RMA que se suministran con el kit. Consulte "Devolución de piezas y sustituciones" la página para obtener más información.