

Sustituya el módulo NVRAM o los DIMM de NVRAM - FAS9000
 Sugerir cambios
Sugerir cambios
El módulo NVRAM consta de NVRAM10 y DIMM, y hasta dos módulos Flash Cache SSD NVMe (Flash Cache o módulos de almacenamiento en caché) por módulo NVRAM. Puede sustituir un módulo NVRAM con fallos o los DIMM dentro del módulo NVRAM.
Para sustituir un módulo NVRAM con fallos, debe retirarlo del chasis, quitar o módulos de Flash Cache del módulo NVRAM, mover los DIMM al módulo de reemplazo, reinstalar el módulo o los módulos de Flash Cache e instalar el módulo NVRAM de reemplazo en el chasis.
Debido a que el ID del sistema se deriva del módulo NVRAM, si se reemplaza el módulo, los discos que pertenecen al sistema se reasignan al nuevo ID del sistema.
-
Todas las bandejas de discos deben funcionar correctamente.
-
Si su sistema está en un par de alta disponibilidad, el nodo del partner debe poder tomar el control del nodo asociado con el módulo NVRAM que se va a reemplazar.
-
Este procedimiento usa la siguiente terminología:
-
El nodo drinated es el nodo en el que realiza tareas de mantenimiento.
-
El nodo heated es el compañero de alta disponibilidad del nodo dañado.
-
-
Este procedimiento incluye pasos para reasignar discos de manera automática o manual al módulo de controladora asociado al nuevo módulo NVRAM. Debe reasignar los discos cuando se le indique en el procedimiento. Si se completa la reasignación del disco antes de la devolución, pueden producirse problemas.
-
Debe sustituir el componente con errores por un componente FRU de repuesto que haya recibido de su proveedor.
-
No puede cambiar ningún disco o bandeja de discos como parte de este procedimiento.
Paso 1: Apague el controlador dañado
Apague o retome el controlador dañado utilizando una de las siguientes opciones.
Toma el control y detén el controlador dañado para que el controlador sano continúe sirviendo datos desde el almacenamiento del controlador dañado. Para hacer esto, suprimes la creación automática de casos en AutoSupport, deshabilitas la devolución automática y llevas el controlador dañado al prompt LOADER. El prompt LOADER es el estado detenido seguro desde el cual puedes reemplazar la FRU.
-
Si dispone de un sistema SAN, debe haber comprobado los mensajes de evento
cluster kernel-service show) para el blade SCSI de la controladora dañada. `cluster kernel-service show`El comando (desde el modo avanzado priv) muestra el nombre del nodo, "estado del quórum" de ese nodo, el estado de disponibilidad de ese nodo y el estado operativo de ese nodo.Cada proceso SCSI-blade debe quórum con los otros nodos del clúster. Todos los problemas deben resolverse antes de continuar con el reemplazo.
-
Si tiene un clúster con más de dos nodos, debe estar en quórum. Si el clúster no tiene quórum o si una controladora en buen estado muestra falso según su condición, debe corregir el problema antes de apagar la controladora dañada; consulte "Sincronice un nodo con el clúster".
-
Si AutoSupport está habilitado, elimine la creación automática de casos invocando un mensaje de AutoSupport:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hEsto evita que se abran casos de soporte automático durante tu ventana de mantenimiento planificada. La duración máxima de la supresión es de 72 horas. Si tu mantenimiento termina antes de tiempo, puedes volver a habilitar la creación de casos invocando un mensaje AutoSupport con
MAINT=END. Para más información, consulta "Cómo suprimir la creación automática de casos durante las ventanas de mantenimiento programadas".El siguiente mensaje de AutoSupport suprime la creación automática de casos durante dos horas:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Desactivar devolución automática:
-
Ingrese el siguiente comando desde la consola del controlador en buen estado:
storage failover modify -node impaired_node_name -auto-giveback false -
Ingresar
ycuando vea el mensaje "¿Desea desactivar la devolución automática?"
-
-
Lleve la controladora dañada al aviso DEL CARGADOR:
Si el controlador dañado está mostrando… Realice lo siguiente… El aviso del CARGADOR
Vaya al paso siguiente.
Esperando devolución…
Pulse Ctrl-C y, a continuación, responda
ycuando se le solicite.Solicitud del sistema o solicitud de contraseña
Retome o detenga el controlador dañado del controlador en buen estado:
storage failover takeover -ofnode impaired_node_name -halt trueEl parámetro -halt true lleva al símbolo del sistema de Loader.
Para apagar el controlador dañado, debe determinar el estado del controlador y, si es necesario, cambiar el controlador para que el controlador correcto siga sirviendo datos del almacenamiento del controlador dañado.
-
Debe dejar las fuentes de alimentación encendidas al final de este procedimiento para proporcionar alimentación a la controladora en buen estado.
-
Compruebe el estado de MetroCluster para determinar si el controlador dañado ha cambiado automáticamente al controlador en buen estado:
metrocluster show -
En función de si se ha producido una conmutación automática, proceda según la siguiente tabla:
Si el controlador está dañado… Realice lo siguiente… Se ha cambiado automáticamente
Continúe con el próximo paso.
No se ha cambiado automáticamente
Realice una operación de conmutación de sitios planificada desde el controlador en buen estado:
metrocluster switchoverNo se ha cambiado automáticamente, ha intentado efectuar una conmutación con el
metrocluster switchovery se vetó la conmutaciónRevise los mensajes de veto y, si es posible, resuelva el problema e inténtelo de nuevo. Si no puede resolver el problema, póngase en contacto con el soporte técnico.
-
Resincronice los agregados de datos ejecutando el
metrocluster heal -phase aggregatescomando del clúster superviviente.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Si la curación es vetada, usted tiene la opción de reemitir el
metrocluster healcon el-override-vetoesparámetro. Si utiliza este parámetro opcional, el sistema anula cualquier vetoo suave que impida la operación de reparación. -
Compruebe que se ha completado la operación con el comando MetroCluster operation show.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Compruebe el estado de los agregados mediante
storage aggregate showcomando.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Repare los agregados raíz mediante el
metrocluster heal -phase root-aggregatescomando.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Si la curación es vetada, usted tiene la opción de reemitir el
metrocluster healcomando con el parámetro -override-vetoes. Si utiliza este parámetro opcional, el sistema anula cualquier vetoo suave que impida la operación de reparación. -
Compruebe que la operación reparar se ha completado mediante el
metrocluster operation showcomando en el clúster de destino:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
En el módulo del controlador dañado, desconecte las fuentes de alimentación.
Paso 2: Sustituya el módulo NVRAM
Para sustituir el módulo NVRAM, búsquelo en la ranura 6 del chasis y siga la secuencia específica de pasos.
-
Si usted no está ya conectado a tierra, correctamente tierra usted mismo.
-
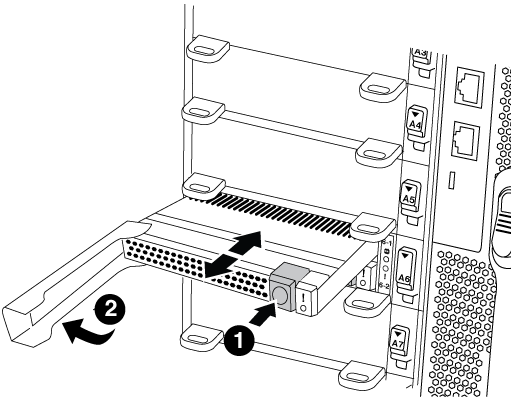
Mueva el módulo Flash Cache del antiguo módulo NVRAM al nuevo módulo NVRAM:

Botón de liberación naranja (gris en módulos Flash Cache vacíos)

Asa de leva Flash Cache
-
Pulse el botón naranja de la parte frontal del módulo Flash Cache.

El botón de liberación de los módulos vacíos de Flash Cache aparece en gris. -
Gire el asa de leva hacia fuera hasta que el módulo empiece a deslizarse fuera del módulo NVRAM antiguo.
-
Sujete el asa de leva del módulo y deslícelo para sacarlo del módulo NVRAM e insértelo en la parte frontal del nuevo módulo NVRAM.
-
Empuje suavemente el módulo Flash Cache hasta el fondo en el módulo NVRAM y, a continuación, gire el asa de la leva hasta que bloquee el módulo en su lugar.
-
-
Quite el módulo NVRAM de destino del chasis:
-
Pulse el botón de leva numerado y con letras.
El botón de leva se aleja del chasis.
-
Gire el pestillo de la leva hacia abajo hasta que esté en posición horizontal.
El módulo NVRAM se desconecta del chasis y se mueve hacia fuera unas pocas pulgadas.
-
Extraiga el módulo NVRAM del chasis tirando de las lengüetas de tiro situadas en los lados de la cara del módulo.
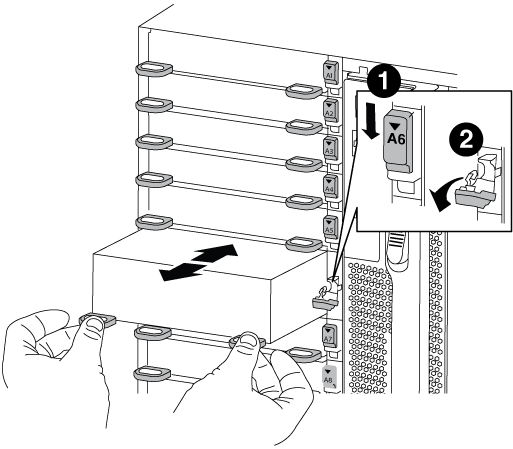
Pestillo de leva de E/S numerado y con letras
Pestillo de I/o completamente desbloqueado
-
-
Coloque el módulo NVRAM en una superficie estable y retire la cubierta del módulo NVRAM presionando el botón azul de bloqueo de la cubierta y, a continuación, mientras mantiene pulsado el botón azul, deslice la tapa fuera del módulo NVRAM.
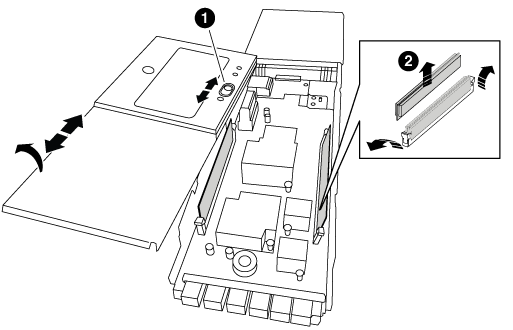
Botón de bloqueo de la cubierta
Lengüetas del expulsor de DIMM y DIMM
-
Extraiga los DIMM, de uno en uno, del módulo NVRAM antiguo e instálelos en el módulo NVRAM de repuesto.
-
Cierre la cubierta del módulo.
-
Instale el módulo NVRAM de repuesto en el chasis:
-
Alinee el módulo con los bordes de la abertura del chasis en la ranura 6.
-
Deslice suavemente el módulo dentro de la ranura hasta que el pestillo de la leva de E/S con letras y numeradas comience a acoplarse con el pasador de leva de E/S y, a continuación, empuje el pestillo de la leva de E/S hasta bloquearlo en su lugar.
-
Paso 3: Sustituya un DIMM de NVRAM
Para sustituir los DIMM de NVRAM en el módulo NVRAM, debe extraer el módulo NVRAM, abrir el módulo y, a continuación, sustituir el DIMM de destino.
-
Si usted no está ya conectado a tierra, correctamente tierra usted mismo.
-
Quite el módulo NVRAM de destino del chasis:
-
Pulse el botón de leva numerado y con letras.
El botón de leva se aleja del chasis.
-
Gire el pestillo de la leva hacia abajo hasta que esté en posición horizontal.
El módulo NVRAM se desconecta del chasis y se mueve hacia fuera unas pocas pulgadas.
-
Extraiga el módulo NVRAM del chasis tirando de las lengüetas de tiro situadas en los lados de la cara del módulo.
Pestillo de leva de E/S numerado y con letras
Pestillo de I/o completamente desbloqueado
-
-
Coloque el módulo NVRAM en una superficie estable y retire la cubierta del módulo NVRAM presionando el botón azul de bloqueo de la cubierta y, a continuación, mientras mantiene pulsado el botón azul, deslice la tapa fuera del módulo NVRAM.
Botón de bloqueo de la cubierta
Lengüetas del expulsor de DIMM y DIMM
-
Localice el DIMM que se va a sustituir dentro del módulo NVRAM y, a continuación, extráigalo presionando las lengüetas de bloqueo del DIMM y extráigalo del zócalo.
-
Instale el módulo DIMM de repuesto alineando el módulo DIMM con el zócalo e empuje suavemente el módulo DIMM hacia el zócalo hasta que las lengüetas de bloqueo queden trabadas en su lugar.
-
Cierre la cubierta del módulo.
-
Instale el módulo NVRAM de repuesto en el chasis:
-
Alinee el módulo con los bordes de la abertura del chasis en la ranura 6.
-
Deslice suavemente el módulo dentro de la ranura hasta que el pestillo de la leva de E/S con letras y numeradas comience a acoplarse con el pasador de leva de E/S y, a continuación, empuje el pestillo de la leva de E/S hasta bloquearlo en su lugar.
-
Paso 4: Reinicie la controladora después de sustituir FRU
Después de sustituir el FRU, debe reiniciar el módulo de la controladora.
-
Para arrancar ONTAP desde el aviso del CARGADOR, introduzca
bye.
Paso 5: Reasignar discos
Dependiendo de si tiene una pareja de alta disponibilidad o una configuración MetroCluster de dos nodos, debe verificar la reasignación de los discos al nuevo módulo de la controladora o reasignar manualmente los discos.
Seleccione una de las siguientes opciones para obtener instrucciones sobre cómo reasignar discos al nuevo controlador.
Debe confirmar el cambio de ID del sistema al arrancar el nodo reboot y, a continuación, comprobar que se ha implementado el cambio.

|
La reasignación de discos solo se necesita al sustituir el módulo NVRAM y no se aplica al reemplazo de DIMM de NVRAM. |
-
Si el nodo de reemplazo está en modo de mantenimiento (se muestra el
*>Salga del modo de mantenimiento y vaya al símbolo del sistema del CARGADOR:halt -
Desde el símbolo del sistema DEL CARGADOR en el nodo de reemplazo, arranque el nodo, introduciendo
ySi se le solicita que anule el ID del sistema debido a que el ID del sistema no coincide.boot_ontap byeEl nodo se reiniciará si está establecido el inicio automático.
-
Espere hasta la
Waiting for giveback…El mensaje se muestra en la consola del nodo regrel y, a continuación, en el nodo en buen estado, compruebe que el nuevo ID de sistema asociado se ha asignado automáticamente:storage failover showEn el resultado del comando, debería ver un mensaje que indica que el ID del sistema ha cambiado en el nodo dañado, mostrando los ID anteriores y los nuevos correctos. En el ejemplo siguiente, el nodo 2 debe ser sustituido y tiene un ID de sistema nuevo de 151759706.
node1> `storage failover show` Takeover Node Partner Possible State Description ------------ ------------ -------- ------------------------------------- node1 node2 false System ID changed on partner (Old: 151759755, New: 151759706), In takeover node2 node1 - Waiting for giveback (HA mailboxes) -
Desde el nodo en buen estado, compruebe que se han guardado los núcleo:
-
Cambie al nivel de privilegio avanzado:
set -privilege advancedUsted puede responder
Ycuando se le solicite que continúe en el modo avanzado. Aparece el símbolo del sistema del modo avanzado (*>). -
Guarde sus núcleo:
system node run -node local-node-name partner savecore -
Espere a que el comando "avecore" se complete antes de emitir la devolución.
Puede introducir el siguiente comando para supervisar el progreso del comando savecoore:
system node run -node local-node-name partner savecore -s -
Vuelva al nivel de privilegio de administrador:
set -privilege admin
-
-
Proporcione al nodo:
-
Desde el nodo en buen estado, vuelva a asignar el almacenamiento del nodo sustituido:
storage failover giveback -ofnode replacement_node_nameEl nodo regrsustituya recupera su almacenamiento y completa el arranque.
Si se le solicita que anule el ID del sistema debido a una falta de coincidencia de ID del sistema, debe introducir
y.
Si el retorno se vetó, puede considerar la sustitución de los vetos.
-
Una vez finalizada la devolución, confirme que el par de alta disponibilidad está en buen estado y que la toma de control es posible:
storage failover showLa salida de
storage failover showel comando no debe incluir elSystem ID changed on partnermensaje.
-
-
Compruebe que los discos se han asignado correctamente:
storage disk show -ownershipLos discos que pertenecen al nodo regrel deberían mostrar el nuevo ID del sistema. En el ejemplo siguiente, los discos propiedad del nodo 1 ahora muestran el nuevo ID del sistema, 1873775277:
node1> `storage disk show -ownership` Disk Aggregate Home Owner DR Home Home ID Owner ID DR Home ID Reserver Pool ----- ------ ----- ------ -------- ------- ------- ------- --------- --- 1.0.0 aggr0_1 node1 node1 - 1873775277 1873775277 - 1873775277 Pool0 1.0.1 aggr0_1 node1 node1 1873775277 1873775277 - 1873775277 Pool0 . . .
-
Si el sistema está en una configuración de MetroCluster, supervise el estado del nodo:
metrocluster node showLa configuración de MetroCluster tarda unos minutos después del reemplazo y vuelve a su estado normal, momento en el que cada nodo mostrará un estado configurado, con mirroring DR habilitado y un modo normal. La
metrocluster node show -fields node-systemidEl resultado del comando muestra el ID del sistema antiguo hasta que la configuración de MetroCluster vuelve a ser un estado normal. -
Si el nodo está en una configuración MetroCluster, según el estado del MetroCluster, compruebe que el campo ID de inicio de recuperación ante desastres muestra el propietario original del disco si el propietario original es un nodo del sitio de desastres.
Esto es necesario si se cumplen las dos opciones siguientes:
-
La configuración de MetroCluster está en estado de conmutación.
-
El nodo regrse es el propietario actual de los discos del sitio de recuperación ante desastres.
-
-
Si su sistema está en una configuración MetroCluster, compruebe que cada nodo esté configurado:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Compruebe que existen volúmenes esperados para cada nodo:
vol show -node node-name -
Si deshabilitó la toma de control automática al reiniciar, habilite esa función desde el nodo en buen estado:
storage failover modify -node replacement-node-name -onreboot true
En una configuración de MetroCluster de dos nodos que ejecuta ONTAP, debe reasignar los discos manualmente al ID del sistema de la nueva controladora antes de devolver el sistema a la condición de funcionamiento normal.
Este procedimiento solo se aplica a sistemas de una configuración MetroCluster de dos nodos que ejecutan ONTAP.
Debe asegurarse de emitir los comandos en este procedimiento en el nodo correcto:
-
El nodo drinated es el nodo en el que realiza tareas de mantenimiento.
-
El nodo regrUSTITUCION es el nuevo nodo que reemplazó al nodo dañado como parte de este procedimiento.
-
El nodo heated es el compañero de recuperación ante desastres del nodo dañado.
-
Si todavía no lo ha hecho, reinicie el nodo regrel, interrumpa el proceso de arranque introduciendo `Ctrl-C`Y, a continuación, seleccione la opción para iniciar el modo de mantenimiento en el menú que se muestra.
Debe entrar
YCuando se le solicite que anule el ID del sistema debido a una discrepancia de ID del sistema. -
Vea los ID del sistema antiguos del nodo en buen estado:
`metrocluster node show -fields node-systemid,dr-partner-systemid'En este ejemplo, Node_B_1 es el nodo antiguo, con el ID de sistema antiguo de 118073209:
dr-group-id cluster node node-systemid dr-partner-systemid ----------- --------------------- -------------------- ------------- ------------------- 1 Cluster_A Node_A_1 536872914 118073209 1 Cluster_B Node_B_1 118073209 536872914 2 entries were displayed.
-
Vea el nuevo ID del sistema en el símbolo del sistema del modo de mantenimiento en el nodo dañado:
disk showEn este ejemplo, el nuevo ID del sistema es 118065481:
Local System ID: 118065481 ... ... -
Reasigne la propiedad de disco (para sistemas FAS) mediante la información de ID de sistema obtenida del comando disk show:
disk reassign -s old system IDEn el caso del ejemplo anterior, el comando es:
disk reassign -s 118073209Usted puede responder
Ycuando se le solicite continuar. -
Compruebe que los discos se han asignado correctamente:
disk show -aCompruebe que los discos que pertenecen al nodo regrisage muestran el nuevo ID del sistema para el nodo regrisage. En el siguiente ejemplo, los discos propiedad del sistema-1 ahora muestran el nuevo ID del sistema, 118065481:
*> disk show -a Local System ID: 118065481 DISK OWNER POOL SERIAL NUMBER HOME ------- ------------- ----- ------------- ------------- disk_name system-1 (118065481) Pool0 J8Y0TDZC system-1 (118065481) disk_name system-1 (118065481) Pool0 J8Y09DXC system-1 (118065481) . . .
-
Desde el nodo en buen estado, compruebe que se han guardado los núcleo:
-
Cambie al nivel de privilegio avanzado:
set -privilege advancedUsted puede responder
Ycuando se le solicite que continúe en el modo avanzado. Aparece el símbolo del sistema del modo avanzado (*>). -
Compruebe que se han guardado los núcleo:
system node run -node local-node-name partner savecoreSi el resultado del comando indica que savecore está en curso, espere a que savecore se complete antes de emitir el retorno. Puede controlar el progreso del savecore mediante el
system node run -node local-node-name partner savecore -s command.</info>. -
Vuelva al nivel de privilegio de administrador:
set -privilege admin
-
-
Si el nodo reader está en modo de mantenimiento (mostrando el símbolo del sistema *>), salga del modo de mantenimiento y vaya al símbolo del sistema DEL CARGADOR:
halt -
Arranque el nodo reboot:
boot_ontap -
Una vez que el nodo reader haya arrancado completamente, lleve a cabo una conmutación de estado:
metrocluster switchback -
Compruebe la configuración de MetroCluster:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Compruebe el funcionamiento de la configuración de MetroCluster en Data ONTAP:
-
Compruebe si hay alertas de estado en ambos clústeres:
system health alert show -
Confirme que el MetroCluster está configurado y en modo normal:
metrocluster show -
Realizar una comprobación de MetroCluster:
metrocluster check run -
Mostrar los resultados de la comprobación de MetroCluster:
metrocluster check show -
Ejecute Config Advisor. Vaya a la página Config Advisor del sitio de soporte de NetApp en "support.netapp.com/NOW/download/tools/config_advisor/".
Después de ejecutar Config Advisor, revise el resultado de la herramienta y siga las recomendaciones del resultado para solucionar los problemas detectados.
-
-
Simular una operación de switchover:
-
Desde el símbolo del sistema de cualquier nodo, cambie al nivel de privilegio avanzado:
set -privilege advancedDebe responder con
ycuando se le solicite que continúe en el modo avanzado y vea el símbolo del sistema del modo avanzado (*>). -
Lleve a cabo la operación de regreso con el parámetro -Simulate:
metrocluster switchover -simulate -
Vuelva al nivel de privilegio de administrador:
set -privilege admin
-
Paso 6: Devuelva la pieza que falló a NetApp
Devuelva la pieza que ha fallado a NetApp, como se describe en las instrucciones de RMA que se suministran con el kit. Consulte "Devolución de piezas y sustituciones" la página para obtener más información.