

Solucionar problemas de red, hardware y plataforma
 Sugerir cambios
Sugerir cambios
Existen varias tareas que puede realizar para ayudar a determinar el origen de los problemas relacionados con la red, el hardware y la plataforma de StorageGRID.
“422: Entidad no procesable” errores
El error 422: Entidad no procesable puede ocurrir por diferentes razones. Compruebe el mensaje de error para determinar la causa del problema.
Si ve uno de los mensajes de error de la lista, realice la acción recomendada.
| Mensaje de error | Causa raíz y acción correctiva |
|---|---|
422: Unprocessable Entity Validation failed. Please check the values you entered for errors. Test connection failed. Please verify your configuration. Unable to authenticate, please verify your username and password: LDAP Result Code 8 "Strong Auth Required": 00002028: LdapErr: DSID-0C090256, comment: The server requires binds to turn on integrity checking if SSL\TLS are not already active on the connection, data 0, v3839 |
Este mensaje puede aparecer si selecciona la opción no utilizar TLS para Seguridad de la capa de transporte (TLS) al configurar la federación de identidades mediante Active Directory de Windows (AD). El uso de la opción no usar TLS no es compatible con servidores AD que aplican la firma LDAP. Debe seleccionar la opción Use STARTTLS o la opción Use LDAPS para TLS. |
422: Unprocessable Entity
Validation failed. Please check
the values you entered for
errors. Test connection failed.
Please verify your
configuration.Unable to
begin TLS, verify your
certificate and TLS
configuration: LDAP Result
Code 200 "Network Error":
TLS handshake failed
(EOF)
|
Este mensaje aparece si intenta utilizar un cifrado no compatible para establecer una conexión TLS (Seguridad de la capa de transporte) desde StorageGRID a un sistema externo utilizado para identificar los grupos de almacenamiento de la federación o de la nube. Compruebe los códigos que ofrece el sistema externo. El sistema debe utilizar uno de los "Cifrados compatibles con StorageGRID" Para conexiones TLS salientes, como se muestra en las instrucciones para administrar StorageGRID. |
Alerta de discrepancia de MTU de red de cuadrícula
La alerta Red Grid MTU mismatch se activa cuando la configuración de la unidad de transmisión máxima (MTU) para la interfaz Red Grid (eth0) difiere significativamente entre los nodos de la cuadrícula.
Las diferencias en la configuración de MTU podrían indicar que algunas redes eth0, pero no todas, están configuradas para tramas gigantes. Un error de coincidencia del tamaño de MTU de más de 1000 puede provocar problemas de rendimiento de la red.
-
Enumere la configuración de MTU para eth0 en todos los nodos.
-
Utilice la consulta proporcionada en Grid Manager.
-
Vaya a.
primary Admin Node IP address/metrics/graphe introduzca la siguiente consulta:node_network_mtu_bytes{interface='eth0'}
-
-
"Modifique la configuración de MTU" Según sea necesario para garantizar que son iguales para la interfaz de red de grid (eth0) en todos los nodos.
-
Para los nodos basados en Linux y VMware, use el siguiente comando:
/usr/sbin/change-ip.py [-h] [-n node] mtu network [network...]Ejemplo:
change-ip.py -n node 1500 grid adminNota: En los nodos basados en Linux, si el valor de MTU deseado para la red en el contenedor supera el valor ya configurado en la interfaz del host, primero debe configurar la interfaz del host para que tenga el valor de MTU deseado y luego utilice
change-ip.pyScript para cambiar el valor MTU de la red en el contenedor.Use los siguientes argumentos para modificar la MTU en los nodos basados en Linux o VMware.
Argumentos posicionales Descripción mtuLa MTU que se va a establecer. Debe estar entre 1280 y 9216.
networkLas redes a las que se va a aplicar la MTU. Incluya uno o varios de los siguientes tipos de red:
-
cuadrícula
-
admin
-
cliente
+
Argumentos opcionales Descripción -h, – helpMuestra el mensaje de ayuda y sale.
-n node, --node nodeEl nodo. El valor predeterminado es el nodo local.
-
Alarma de error de recepción de red (NRER)
Las alarmas de error de recepción de red (NRER) pueden deberse a problemas de conectividad entre StorageGRID y el hardware de red. En algunos casos, los errores del NRER pueden aclararse sin intervención manual. Si los errores no se borran, realice las acciones recomendadas.
Las alarmas NRER pueden deberse a los siguientes problemas de hardware de red que se conecta a StorageGRID:
-
Se requiere corrección de errores de reenvío (FEC) y no se utiliza
-
Discrepancia entre el puerto del switch y la MTU de NIC
-
Índices altos de errores de enlace
-
Desbordamiento del búfer de anillo NIC
-
Siga los pasos de solución de problemas para todas las posibles causas de la alarma NRER dada la configuración de la red.
-
Realice los siguientes pasos en función de la causa del error:
FEC no coincide
Estos pasos sólo se aplican a los errores NRER causados por la discrepancia de FEC en dispositivos StorageGRID. -
Compruebe el estado de FEC del puerto en el interruptor conectado al dispositivo StorageGRID.
-
Compruebe la integridad física de los cables del aparato al interruptor.
-
Si desea cambiar la configuración de FEC para intentar resolver la alarma de NRER, asegúrese primero de que el aparato esté configurado para el modo AUTO en la página Configuración de enlace del instalador de dispositivos StorageGRID (consulte las instrucciones de su aparato:
-
Cambie la configuración de FEC en los puertos del switch. Los puertos del dispositivo StorageGRID ajustarán los ajustes del FEC para que coincidan, si es posible.
No puede configurar los ajustes de FEC en dispositivos StorageGRID. En su lugar, los dispositivos intentan descubrir y duplicar los ajustes de FEC en los puertos de conmutador a los que están conectados. Si los enlaces se ven forzados a velocidades de red de 25-GbE o 100-GbE, es posible que el switch y la NIC no negocien una configuración de FEC común. Sin un ajuste FEC común, la red volverá al modo «'no-FEC». Cuando el FEC no está activado, las conexiones son más susceptibles a errores causados por el ruido eléctrico.
Los dispositivos StorageGRID son compatibles con Firecode (FC) y Reed Solomon (RS) FEC, y sin FEC.
Discrepancia entre el puerto del switch y la MTU de NICSi el error se debe a un error de coincidencia entre un puerto del switch y una MTU de NIC, compruebe que el tamaño de MTU configurado en el nodo sea el mismo que la configuración de MTU para el puerto del switch.
El tamaño de MTU configurado en el nodo puede ser más pequeño que la configuración en el puerto del switch al que está conectado el nodo. Si un nodo StorageGRID recibe una trama de Ethernet mayor que su MTU, lo cual es posible con esta configuración, se podría notificar la alarma NRER. Si cree que esto es lo que está sucediendo, cambie la MTU del puerto del switch para que coincida con la MTU de la interfaz de red de StorageGRID o cambie la MTU de la interfaz de red de StorageGRID para que coincida con el puerto del switch, según sus objetivos o requisitos de MTU completos.

Para obtener el mejor rendimiento de red, todos los nodos deben configurarse con valores MTU similares en sus interfaces de Grid Network. La alerta Red de cuadrícula MTU se activa si hay una diferencia significativa en la configuración de MTU para la Red de cuadrícula en nodos individuales. No es necesario que los valores de MTU sean los mismos para todos los tipos de red. Consulte Solucione problemas de la alerta de discrepancia de MTU de red de cuadrícula si quiere más información.
Consulte también "Cambie la configuración de MTU". Índices altos de errores de enlace-
Active FEC, si aún no está activado.
-
Compruebe que el cableado de red es de buena calidad y que no está dañado o conectado incorrectamente.
-
Si parece que los cables no son el problema, póngase en contacto con el soporte técnico.
Es posible que note altas tasas de error en un entorno con alto nivel de ruido eléctrico.
Desbordamiento del búfer de anillo NICSi el error es un desbordamiento del búfer de anillo NIC, póngase en contacto con el soporte técnico.
El búfer de anillo puede desbordarse cuando el sistema StorageGRID está sobrecargado y no puede procesar eventos de red de forma oportuna.
-
-
Después de resolver el problema subyacente, restablezca el contador de errores.
-
Seleccione SUPPORT > Tools > Topología de cuadrícula.
-
Seleccione site > grid node > SSM > Recursos > Configuración > Principal.
-
Seleccione Restablecer recuento de errores de recepción y haga clic en aplicar cambios.
-
Errores de sincronización de hora
Es posible que observe problemas con la sincronización de la hora en la cuadrícula.
Si tiene problemas de sincronización temporal, compruebe que ha especificado al menos cuatro orígenes NTP externos, cada uno de los cuales proporciona una referencia estratum 3 o mejor, y que sus nodos StorageGRID pueden acceder a todas las fuentes NTP externas con normalidad.
|
|
Cuando "Especificación del origen NTP externo" Para una instalación de StorageGRID en el nivel de producción, no use el servicio Windows Time (W32Time) en una versión de Windows anterior a Windows Server 2016. El servicio de tiempo en versiones anteriores de Windows no es lo suficientemente preciso y no es compatible con Microsoft para su uso en entornos de gran precisión como StorageGRID. |
Linux: Problemas de conectividad de red
Es posible que vea problemas con la conectividad de red para los nodos grid StorageGRID alojados en hosts Linux.
Clonación de direcciones MAC
En algunos casos, los problemas de red se pueden resolver mediante la clonación de direcciones MAC. Si utiliza hosts virtuales, establezca el valor de la clave de clonación de direcciones MAC para cada una de las redes en "true" en el archivo de configuración del nodo. Este ajuste hace que la dirección MAC del contenedor StorageGRID utilice la dirección MAC del host. Para crear archivos de configuración de nodos, consulte las instrucciones de "Red Hat Enterprise Linux o CentOS" o. "Ubuntu o Debian".
|
|
Cree interfaces de red virtual independientes que utilice el sistema operativo del host Linux. Al utilizar las mismas interfaces de red para el sistema operativo host Linux y el contenedor StorageGRID, es posible que no se pueda acceder al sistema operativo del host si no se ha habilitado el modo promiscuo en el hipervisor. |
Para obtener más información sobre la activación de la clonación MAC, consulte las instrucciones de "Red Hat Enterprise Linux o CentOS" o. "Ubuntu o Debian".
Modo promiscuo
Si no desea utilizar la clonación de direcciones MAC y prefiere permitir que todas las interfaces reciban y transmitan datos para direcciones MAC distintas de las asignadas por el hipervisor, Asegúrese de que las propiedades de seguridad en los niveles de conmutador virtual y grupo de puertos estén establecidas en Aceptar para el modo promiscuo, los cambios de dirección MAC y las transmisiones falsificadas. Los valores establecidos en el conmutador virtual pueden ser anulados por los valores en el nivel de grupo de puertos, por lo que asegúrese de que la configuración sea la misma en ambos lugares.
Para obtener más información sobre el uso del modo Promiscuous, consulte las instrucciones de "Red Hat Enterprise Linux o CentOS" o. "Ubuntu o Debian".
Linux: El estado del nodo es «'huérfano'».
Un nodo Linux en estado huérfano suele indicar que el servicio de StorageGRID o el demonio del nodo StorageGRID que controla el contenedor del nodo ha muerto inesperadamente.
Si un nodo de Linux informa de que está en el estado huérfano, debería:
-
Compruebe los registros en busca de errores y mensajes.
-
Intente iniciar de nuevo el nodo.
-
Si es necesario, utilice los comandos del motor de contenedores para detener el contenedor de nodo existente.
-
Reinicie el nodo.
-
Compruebe los registros del demonio de servicio y del nodo huérfano para ver errores o mensajes obvios acerca de salir inesperadamente.
-
Inicie sesión en el host como raíz o utilice una cuenta con permiso sudo.
-
Intente iniciar nuevamente el nodo ejecutando el siguiente comando:
$ sudo storagegrid node start node-name$ sudo storagegrid node start DC1-S1-172-16-1-172
Si el nodo está huérfano, la respuesta es
Not starting ORPHANED node DC1-S1-172-16-1-172
-
Desde Linux, detenga el motor de contenedor y todos los procesos que controlan el nodo storagegrid. Por ejemplo:
sudo docker stop --time secondscontainer-namePara
seconds, introduzca el número de segundos que desea esperar a que se detenga el contenedor (normalmente 15 minutos o menos). Por ejemplo:sudo docker stop --time 900 storagegrid-DC1-S1-172-16-1-172
-
Reinicie el nodo:
storagegrid node start node-namestoragegrid node start DC1-S1-172-16-1-172
Linux: Solucione problemas de compatibilidad con IPv6
Es posible que deba habilitar la compatibilidad de IPv6 en el kernel si ha instalado nodos StorageGRID en hosts Linux y se debe observar que las direcciones IPv6 no se han asignado a los contenedores de nodos según lo esperado.
Puede ver la dirección IPv6 que se ha asignado a un nodo de cuadrícula en las siguientes ubicaciones en Grid Manager:
-
Seleccione NODES y seleccione el nodo. A continuación, seleccione Mostrar más junto a direcciones IP en la ficha Descripción general.
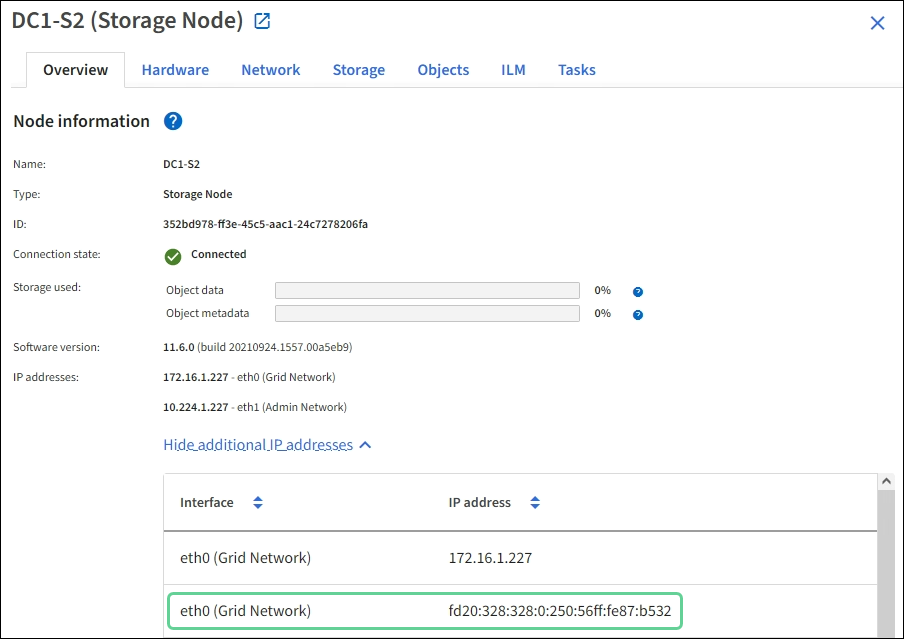
-
Seleccione SUPPORT > Tools > Topología de cuadrícula. A continuación, seleccione node > SSM > Recursos. Si se ha asignado una dirección IPv6, se muestra debajo de la dirección IPv4 en la sección direcciones de red.
Si no se muestra la dirección IPv6 y el nodo está instalado en un host Linux, siga estos pasos para habilitar la compatibilidad de IPv6 en el kernel.
-
Inicie sesión en el host como raíz o utilice una cuenta con permiso sudo.
-
Ejecute el siguiente comando:
sysctl net.ipv6.conf.all.disable_ipv6root@SG:~ # sysctl net.ipv6.conf.all.disable_ipv6
El resultado debe ser 0.
net.ipv6.conf.all.disable_ipv6 = 0
Si el resultado no es 0, consulte la documentación del sistema operativo para realizar el cambio sysctlconfiguración. A continuación, cambie el valor a 0 antes de continuar. -
Introduzca el contenedor de nodo StorageGRID:
storagegrid node enter node-name -
Ejecute el siguiente comando:
sysctl net.ipv6.conf.all.disable_ipv6root@DC1-S1:~ # sysctl net.ipv6.conf.all.disable_ipv6
El resultado debería ser 1.
net.ipv6.conf.all.disable_ipv6 = 1
Si el resultado no es 1, este procedimiento no se aplica. Póngase en contacto con el soporte técnico. -
Salga del contenedor:
exitroot@DC1-S1:~ # exit
-
Como raíz, edite el siguiente archivo:
/var/lib/storagegrid/settings/sysctl.d/net.conf.sudo vi /var/lib/storagegrid/settings/sysctl.d/net.conf
-
Localice las dos líneas siguientes y elimine las etiquetas de comentario. A continuación, guarde y cierre el archivo.
net.ipv6.conf.all.disable_ipv6 = 0
net.ipv6.conf.default.disable_ipv6 = 0
-
Ejecute estos comandos para reiniciar el contenedor de StorageGRID:
storagegrid node stop node-name
storagegrid node start node-name