

Logre un objetivo de punto de recuperación de cero con StorageGRID: Una guía completa para la replicación multisitio
 Sugerir cambios
Sugerir cambios
Este informe técnico proporciona una guía completa para implementar estrategias de replicación de StorageGRID para lograr un Objetivo de Punto de Recuperación (RPO) de cero en caso de una falla del sitio. El documento detalla varias opciones de implementación para StorageGRID, incluyendo la replicación síncrona multisitio y la replicación asíncrona multigrid. Explica cómo se pueden configurar las políticas de gestión del ciclo de vida de la información (ILM) de StorageGRID para garantizar la durabilidad y disponibilidad de los datos en múltiples ubicaciones. Además, el informe abarca consideraciones de rendimiento, escenarios de fallos y procesos de recuperación para mantener las operaciones de los clientes sin interrupciones. El objetivo de este documento es proporcionar información para garantizar que los datos permanezcan accesibles y coherentes, incluso en caso de un fallo total del sitio, mediante el uso de técnicas de replicación tanto síncronas como asíncronas.
Información general de StorageGRID
NetApp StorageGRID es un sistema de almacenamiento basado en objetos compatible con la API estándar del sector Amazon Simple Storage Service (Amazon S3).
StorageGRID proporciona un espacio de nombres único en varias ubicaciones, con niveles variables de servicio basados en políticas de gestión del ciclo de vida de la información (ILM). Con estas políticas de ciclo de vida puede optimizar dónde residen sus datos a lo largo de su ciclo de vida.
StorageGRID permite la durabilidad y disponibilidad configurables de sus datos en soluciones locales y distribuidas geográficamente. Ya sea que sus datos estén en las instalaciones o en una nube pública, los flujos de trabajo de nube híbrida integrados permiten que su empresa aproveche servicios de nube como Amazon Simple Notification Service (Amazon SNS), Google Cloud, Microsoft Azure Blob, Amazon S3 Glacier, Elasticsearch y más.
StorageGRID Scale
Una implementación mínima de StorageGRID consta de un nodo de administración y 3 nodos de almacenamiento en un único sitio. Una sola cuadrícula puede crecer hasta 220 nodos. StorageGRID se puede implementar como un solo sitio o extenderse a 16 sitios.
El nodo de administración contiene la interfaz de gestión, un punto central para las métricas y el registro, y mantiene la configuración de los componentes de StorageGRID . El nodo de administración también contiene un balanceador de carga integrado para el acceso a la API S3.
StorageGRID se puede implementar solo como software, como dispositivos de máquinas virtuales VMware o como dispositivos diseñados específicamente para ese fin.
Un nodo de almacenamiento se puede implementar como:
-
Un nodo de solo metadatos que maximiza el recuento de objetos
-
Un nodo de almacenamiento de objetos únicamente que maximiza el espacio de los objetos
-
Un nodo combinado de almacenamiento de objetos y metadatos que agrega tanto el recuento de objetos como el espacio de objetos
Cada nodo de almacenamiento puede escalar a una capacidad de varios petabytes para el almacenamiento de objetos, lo que permite un único espacio de nombres en cientos de petabytes. StorageGRID también proporciona un equilibrador de carga integrado para las operaciones de API S3 llamado nodo de puerta de enlace.
StorageGRID consta de una colección de nodos ubicados en una topología de sitio. Un sitio en StorageGRID puede ser una ubicación física única o residir en una ubicación física compartida como otros sitios en la red como una construcción lógica. Un sitio StorageGRID no debe abarcar varias ubicaciones físicas. Un sitio representa una infraestructura de red de área local (LAN) compartida y un dominio de falla.
StorageGRID y dominios de fallos
StorageGRID contiene varias capas de dominios de fallo a tener en cuenta para decidir cómo diseñar su solución, cómo almacenar sus datos y dónde deben almacenarse para mitigar los riesgos de fallos.
-
Nivel de cuadrícula: Una cuadrícula formada por varios sitios puede tener fallos de sitio o aislamiento y los sitios accesibles pueden seguir funcionando como la cuadrícula.
-
Nivel de sitio: Los fallos dentro de un sitio pueden afectar a las operaciones de ese sitio, pero no afectarán al resto del grid.
-
Nivel de nodo: Un fallo de nodo no afectará al funcionamiento del sitio.
-
Nivel de disco: Un error de disco no afectará al funcionamiento del nodo.
Datos y metadatos de objeto
Con el almacenamiento de objetos, la unidad de almacenamiento es un objeto, en lugar de un archivo o un bloque. A diferencia de la jerarquía de árbol de un sistema de archivos o almacenamiento basado en bloques, el almacenamiento de objetos organiza los datos en un diseño plano y sin estructura. El almacenamiento de objetos separa la ubicación física de los datos del método utilizado para almacenar y recuperar esos datos.
Cada objeto de un sistema de almacenamiento basado en objetos tiene dos partes: Datos de objetos y metadatos de objetos.
-
Los datos de objeto representan los datos subyacentes reales, por ejemplo, una fotografía, una película o un historial médico.
-
Los metadatos de objetos son cualquier información que describa un objeto.
StorageGRID utiliza metadatos de objetos para realizar un seguimiento de las ubicaciones de todos los objetos en el grid y gestionar el ciclo de vida de cada objeto a lo largo del tiempo.
Los metadatos de objetos incluyen información como la siguiente:
-
Metadatos del sistema, incluido un ID único para cada objeto, el nombre del objeto, el nombre del bucket S3, el nombre o ID de la cuenta del inquilino, el tamaño lógico del objeto, la fecha y hora en que se creó el objeto por primera vez y la fecha y hora en que se modificó el objeto por última vez.
-
La ubicación de almacenamiento actual de la copia replicada o el fragmento codificado para borrado de cada objeto.
-
Todos los pares de valor de clave de metadatos de usuario personalizados asociados con el objeto.
-
En el caso de los objetos S3, todas las parejas clave-valor de etiqueta de objeto asociadas con el objeto
-
Para objetos segmentados y objetos multipartes, identificadores de segmento y tamaños de datos.
Los metadatos de objetos son personalizables y ampliables, por lo que es flexible para las aplicaciones. Para obtener información detallada sobre cómo y dónde StorageGRID almacena los metadatos de objetos, vaya a "Gestione el almacenamiento de metadatos de objetos".
El sistema de gestión de la vida útil de la información (ILM) de StorageGRID se usa para orquestar la ubicación, la duración y el comportamiento de ingesta de todos los datos de objetos del sistema StorageGRID. Las reglas de ILM determinan la forma en que StorageGRID almacena objetos a lo largo del tiempo mediante réplicas de los objetos o el código de borrado del objeto en nodos y sitios. Este sistema ILM es responsable de la consistencia de los datos de objetos dentro de una cuadrícula.
Codificación de borrado
StorageGRID proporciona la capacidad de borrar datos de código a nivel de nodo y de unidad. Con los dispositivos StorageGRID , borramos con código los datos almacenados en cada nodo en todas las unidades dentro del nodo, brindando protección local contra múltiples fallas de disco que provoquen pérdida o interrupciones de datos. Las reconstrucciones a partir de fallas de unidad son locales en el nodo y no requieren que los datos se repliquen en la red.
Además, los dispositivos StorageGRID utilizan esquemas de codificación de borrado para almacenar datos de objetos en todos los nodos dentro de un sitio o distribuidos en 3 o más sitios en el sistema StorageGRID a través de las reglas ILM de StorageGRID que protegen contra fallas de nodos.
La codificación de borrado proporciona un diseño de almacenamiento resistente a fallos de nodos y sitios con una sobrecarga menor que la replicación. Todos los esquemas de codificación de borrado de StorageGRID se pueden implementar en un solo sitio siempre que se cumpla el número mínimo de nodos necesarios para almacenar los fragmentos de datos. Esto significa que para un esquema EC de 4+2 se necesita un mínimo de 6 nodos disponibles para recibir los datos.
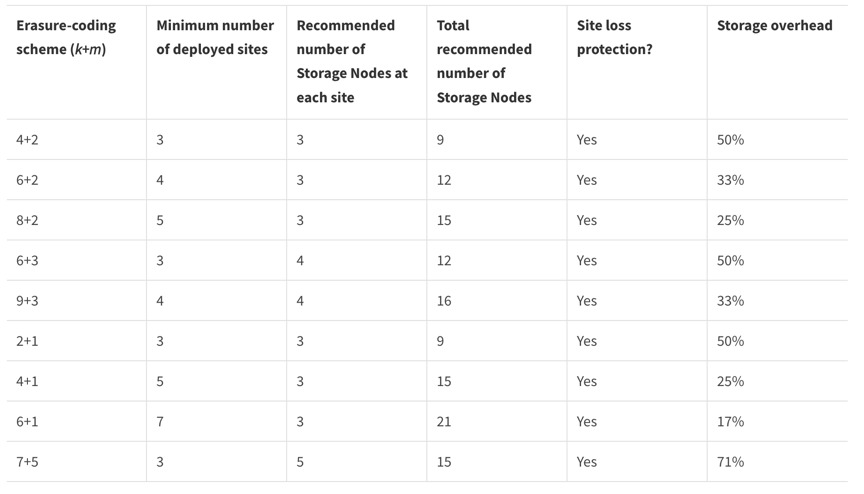
Consistencia de metadatos
En StorageGRID, los metadatos suelen almacenarse con tres réplicas por sitio para asegurar la consistencia y la disponibilidad. Esta redundancia ayuda a mantener la integridad de los datos y la accesibilidad incluso en caso de fallo.
La consistencia predeterminada se define en un nivel de cuadrícula. Los usuarios pueden cambiar la consistencia en el nivel del depósito en cualquier momento.
Las opciones de coherencia de bloques disponibles en StorageGRID son:
-
Todo: Proporciona el más alto nivel de consistencia. Todos los nodos del grid reciben los datos inmediatamente o la solicitud fallará.
-
Global fuerte:
-
Legacy Strong Global: Garantiza la consistencia de lectura después de escritura para todas las solicitudes de clientes en todos los sitios.
-
Este es el comportamiento predeterminado para todos los sistemas actualizados de la versión 11.9 o anterior a la versión 12.0 sin cambiar manualmente al nuevo Quorum Strong Global.
-
-
Quorum Strong-global: garantiza la consistencia de lectura tras escritura para todas las solicitudes de clientes en todos los sitios. Ofrece consistencia para múltiples nodos o incluso en caso de falla del sitio si se puede lograr el quórum de réplica de metadatos.
-
Este es el comportamiento predeterminado para todos los sistemas recién instalados en la versión 12.0 o superior.
-
La consistencia de QUORUM se define como un quórum de réplicas de metadatos del nodo de almacenamiento, donde cada sitio tiene 3 réplicas de metadatos. Se puede calcular de la siguiente manera: 1+((N*3)/2) donde N es el número total de sitios.
-
Por ejemplo, se debe realizar un mínimo de 5 réplicas a partir de una cuadrícula de 3 sitios con un máximo de 3 réplicas dentro de un sitio.
-
-
-
Strong-site: Garantiza la consistencia de lectura después de escritura para todas las solicitudes de los clientes dentro de un sitio.
-
Read-after-new-write(default): Proporciona consistencia de lectura después de escritura para nuevos objetos y consistencia eventual para las actualizaciones de objetos. Ofrece garantías de alta disponibilidad y protección de datos. Recomendado para la mayoría de los casos.
-
Disponible: Proporciona consistencia eventual tanto para nuevos objetos como para actualizaciones de objetos. Para los cubos S3, utilice solo según sea necesario (por ejemplo, para un depósito que contiene valores de registro que rara vez se leen, o para operaciones HEAD u GET en claves que no existen). No se admite para bloques de FabricPool S3.
Coherencia de datos de objetos
Aunque los metadatos se replican automáticamente en y entre sitios, las decisiones sobre ubicación de almacenamiento de datos de objetos dependen de usted. Los datos de objetos se pueden almacenar en réplicas dentro de y entre sitios, códigos de borrado dentro o entre sitios o una combinación o réplicas y esquemas de almacenamiento codificados de borrado. Las reglas de ILM se pueden aplicar a todos los objetos o se pueden filtrar para que solo se apliquen a ciertos objetos, bloques o inquilinos. Las reglas de ILM definen cómo se almacenan los objetos, las réplicas o el código de borrado, el tiempo que los objetos se almacenan en esas ubicaciones, si el número de réplicas o el esquema de código de borrado debería cambiar o las ubicaciones deberían cambiar con el tiempo.
Cada regla de ILM se configurará con uno de estos tres comportamientos de procesamiento para proteger los objetos: Doble registro, equilibrada o estricta.
La opción de confirmación dual realizará inmediatamente dos copias en dos nodos de almacenamiento diferentes cualesquiera de la cuadrícula y devolverá al cliente la solicitud como exitosa. La selección del nodo se intentará dentro del sitio de la solicitud, pero en algunas circunstancias puede utilizar nodos de otro sitio. El objeto se añade a la cola ILM para ser evaluado y colocado de acuerdo con las reglas ILM.
La opción balanceada evalúa el objeto de acuerdo con la política ILM inmediatamente y coloca el objeto de forma síncrona antes de devolver la solicitud al cliente para que se haya realizado correctamente. Si la regla ILM no puede cumplirse de inmediato debido a una interrupción del servicio o a una capacidad de almacenamiento insuficiente para cumplir con los requisitos de ubicación, entonces se utilizará la confirmación dual. Una vez resuelto el problema, ILM colocará automáticamente el objeto según la regla definida.
La opción estricta evalúa el objeto de acuerdo con la política ILM inmediatamente y coloca el objeto de forma síncrona antes de devolver la solicitud al cliente para que se haya realizado correctamente. Si la regla ILM no se puede cumplir de inmediato debido a una interrupción del servicio o a un almacenamiento insuficiente para cumplir con los requisitos de ubicación, la solicitud fallará y el cliente deberá volver a intentarlo.
Balanceo de carga
StorageGRID se puede poner en marcha con acceso de cliente a través de los nodos de puerta de enlace integrada, un equilibrador de carga de 3rd partes externo, una operación por turnos de DNS o directamente en un nodo de almacenamiento. Pueden ponerse en marcha varios nodos de puerta de enlace en un sitio y configurarse en grupos de alta disponibilidad proporcionando conmutación por error automatizada y recuperación tras fallos en caso de interrupción del nodo de puerta de enlace. Puede combinar métodos de equilibrio de carga en una solución para proporcionar un único punto de acceso a todos los sitios de una solución.
Los nodos de puerta de enlace equilibrarán la carga entre los nodos de almacenamiento en el sitio donde reside el nodo de puerta de enlace de forma predeterminada. StorageGRID se puede configurar para permitir que los nodos de puerta de enlace equilibren la carga utilizando nodos de múltiples sitios. Esta configuración añadiría la latencia entre esos sitios a la latencia de respuesta a las solicitudes del cliente. Esto solo debe configurarse si la latencia total es aceptable para los clientes.
Se puede lograr un RTO de cero mediante una combinación de equilibrio de carga local y global. Para garantizar un acceso ininterrumpido a los clientes, es necesario equilibrar la carga de las solicitudes de los clientes. Una solución StorageGRID puede contener muchos nodos de puerta de enlace y grupos de alta disponibilidad en cada sitio. Para proporcionar acceso ininterrumpido a los clientes en cualquier sitio, incluso en caso de fallo del sitio, debe configurar una solución de equilibrio de carga externa en combinación con los nodos de StorageGRID Gateway. Configure grupos de alta disponibilidad de nodos de puerta de enlace que gestionen la carga dentro de cada sitio y utilice el balanceador de carga externo para equilibrar la carga entre los grupos de alta disponibilidad. El balanceador de carga externo debe configurarse para realizar una comprobación de estado que garantice que las solicitudes se envíen únicamente a los sitios operativos. Para obtener más información sobre el equilibrio de carga con StorageGRID, consulte la "Informe técnico del equilibrador de carga de StorageGRID".
Requisitos para RPO cero con StorageGRID
Para lograr un objetivo de punto de recuperación (RPO) cero en un sistema de almacenamiento de objetos, es crucial que en el momento del fallo:
-
Tanto los metadatos como el contenido de los objetos se sincronizan y se consideran consistentes
-
Se seguirá accediendo al contenido del objeto a pesar de producirse un error.
Para una implementación de múltiples sitios, Quorum Strong Global es el modelo de consistencia preferido para garantizar que los metadatos estén sincronizados en todos los sitios, lo que lo hace esencial para cumplir con el requisito de RPO cero.
Los objetos del sistema de almacenamiento se almacenan según las reglas de Gestión del Ciclo de Vida de la Información (ILM), que dictan cómo y dónde se almacenan los datos a lo largo de su ciclo de vida. Para la replicación síncrona, se puede considerar entre la ejecución estricta o la ejecución balanceada.
-
Es necesaria una estricta ejecución de estas reglas de ILM para un objetivo de punto de recuperación cero porque garantiza que los objetos se coloquen en las ubicaciones definidas sin ningún retraso ni retroceso, de modo que se mantenga la disponibilidad y la coherencia de los datos.
-
El comportamiento de procesamiento de ILM Balance de StorageGRID proporciona un equilibrio entre alta disponibilidad y resiliencia, lo que permite que los usuarios sigan procesando datos incluso en caso de un fallo del sitio.
Puestas en marcha síncronas en varios sitios
Soluciones multisitio: StorageGRID le permite replicar objetos en múltiples sitios dentro de la red de forma sincrónica. Al configurar reglas de Gestión del ciclo de vida de la información (ILM) con equilibrio o comportamiento estricto, los objetos se colocan inmediatamente en las ubicaciones especificadas. Configurar el nivel de consistencia del bucket en Quorum Strong Global también garantizará la replicación sincrónica de metadatos. StorageGRID utiliza un único espacio de nombres global que almacena las ubicaciones de los objetos como metadatos, de modo que cada nodo sabe dónde se encuentran todas las copias o piezas codificadas de borrado. Si no se puede recuperar un objeto del sitio donde se realizó la solicitud, se recuperará automáticamente de un sitio remoto sin necesidad de procedimientos de conmutación por error.
Una vez resuelto el fallo, no es necesario realizar ningún esfuerzo manual de conmutación por recuperación. El rendimiento de la replicación depende del sitio con el rendimiento de red más bajo, la máxima latencia y el menor rendimiento. El rendimiento de un sitio se basa en el número de nodos, la velocidad y el número de núcleos de CPU, la memoria, la cantidad de unidades y los tipos de unidades.
Soluciones multigrid: StorageGRID puede replicar inquilinos, usuarios y buckets entre múltiples sistemas StorageGRID usando la replicación entre redes cruzadas (CGR). CGR puede ampliar los datos seleccionados a más de 16 sitios, aumentar la capacidad utilizable del almacén de objetos y proporcionar recuperación ante desastres. La replicación de buckets con CGR incluye objetos, versiones de objetos y metadatos, y puede ser bidireccional o unidireccional. El objetivo de punto de recuperación (RPO) depende del rendimiento de cada sistema StorageGRID y de las conexiones de red entre ellos.
Resumen:
-
La replicación dentro del grid incluye replicación síncrona y asíncrona, configurable mediante el comportamiento de ingesta de ILM y el control de coherencia de metadatos.
-
La replicación entre grid es solo asíncrona.
Una implementación de varios sitios de Grid único
En los siguientes escenarios, las soluciones StorageGRID están configuradas con un balanceador de carga externo opcional que gestiona las solicitudes a los grupos de alta disponibilidad del balanceador de carga integrado. Esto permitirá alcanzar un RTO de cero, además de un RPO de cero. ILM está configurado con protección de ingesta balanceada para la colocación síncrona. Cada bucket está configurado con la versión Quorum del modelo de consistencia global fuerte para cuadrículas de 3 o más sitios y la versión Legacy de consistencia global fuerte para 2 sitios.
Escenario 1:
En una solución StorageGRID de dos sitios, existen al menos dos réplicas de cada objeto y 6 réplicas de todos los metadatos. Tras la recuperación tras el fallo, las actualizaciones posteriores a la interrupción se sincronizarán automáticamente con el sitio/nodos recuperados. Con solo 2 sitios, es poco probable que se logre un RPO cero en escenarios de falla más allá de la pérdida total de un sitio.
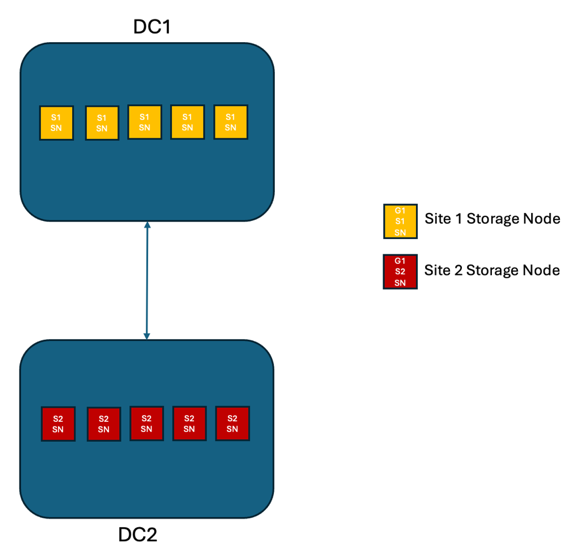
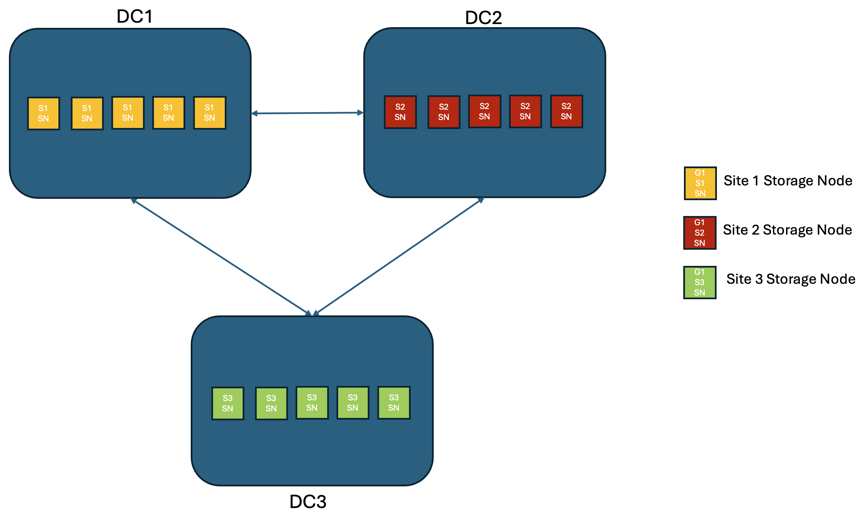
Escenario 2:
En una solución StorageGRID de tres o más sitios, hay al menos 3 réplicas o 3 fragmentos EC de cada objeto y 9 réplicas de todos los metadatos. Tras la recuperación tras el fallo, las actualizaciones posteriores a la interrupción se sincronizarán automáticamente con el sitio/nodos recuperados. Con tres o más sitios es posible lograr un RPO cero.
Escenarios de fallo en varios sitios
| Fallo | Resultado en 2 sitios + Legado Fuerte Global | Resultado de 3 o más sitios + Quorum Strong Global |
|---|---|---|
Fallo de unidad de nodo único |
Cada dispositivo utiliza varios grupos de discos y puede mantener al menos 1 unidades por grupo sin interrupciones ni pérdida de datos. |
Cada dispositivo utiliza varios grupos de discos y puede mantener al menos 1 unidades por grupo sin interrupciones ni pérdida de datos. |
Fallo de un nodo en un sitio |
Sin interrupción de las operaciones ni pérdida de datos. |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo de varios nodos en un sitio |
Interrupción de las operaciones del cliente dirigidas a este sitio, pero sin pérdida de datos. Las operaciones dirigidas al otro sitio permanecen sin interrupciones y sin pérdida de datos. |
Las operaciones se dirigen a todos los demás sitios y permanecen sin interrupciones y sin pérdida de datos. |
Fallo de un único nodo en múltiples sitios |
Sin interrupción ni pérdida de datos si:
Las operaciones interrumpidas y el riesgo de pérdida de datos si:
|
Sin interrupción ni pérdida de datos si:
Las operaciones interrumpidas y el riesgo de pérdida de datos si:
|
Fallo de un sitio único |
Algunas operaciones del cliente se verán interrumpidas hasta que se resuelva el fallo. Las operaciones GET y HEAD continuarán sin interrupción. Reduzca la consistencia del bucket a lectura después de nueva escritura o a un nivel inferior para continuar las operaciones sin interrupciones en este estado de fallo. |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallos de un único sitio más nodo único |
Algunas operaciones del cliente se verán interrumpidas hasta que se resuelva el fallo. Las operaciones de HEAD continuarán sin interrupción. Las operaciones GET continuarán sin interrupción si existe una copia replicada o suficientes fragmentos EC. Reduzca la consistencia del bucket a lectura después de nueva escritura o a un nivel inferior para continuar las operaciones sin interrupciones en este estado de fallo. |
Sin interrupción de las operaciones ni pérdida de datos. Posible pérdida de datos dependiendo del número de copias replicadas. La codificación de borrado local puede prevenir la pérdida de datos. |
Sitio único y nodo de cada sitio restante |
Solo existen dos sitios. Ver: Sitio único más un nodo único. |
Las operaciones se verán interrumpidas si no se puede alcanzar el quórum de réplicas de metadatos. Reduzca la consistencia del bucket a lectura después de nueva escritura o a un nivel inferior para continuar las operaciones sin interrupciones en este estado de fallo. Posible pérdida de datos por fallo permanente dependiendo del número de copias replicadas. La codificación de borrado local puede prevenir la pérdida de datos. |
Fallo de varios sitios |
No quedan centros operativos. Se perderán los datos si no se puede recuperar al menos un sitio en su totalidad. |
Las operaciones se verán interrumpidas si no se puede alcanzar el quórum de réplicas de metadatos. Reduzca la consistencia del bucket a lectura después de nueva escritura o a un nivel inferior para continuar las operaciones sin interrupciones en este estado de fallo. Posible pérdida de datos por fallo permanente si no quedan suficientes fragmentos codificados para borrado. La codificación de borrado local o las copias de seguridad pueden prevenir la pérdida de datos. |
Aislamiento de red de un sitio |
Las operaciones del cliente se interrumpirán hasta que se resuelva el fallo. Reduzca la consistencia del bucket a lectura después de nueva escritura o a un nivel inferior para continuar las operaciones sin interrupciones en este estado de fallo. Sin pérdida de datos |
Las operaciones se verán interrumpidas en el sitio aislado, pero no habrá pérdida de datos. Reduzca la consistencia del bucket a lectura después de nueva escritura o a un nivel inferior para continuar las operaciones sin interrupciones en este estado de fallo. No se han producido interrupciones en las operaciones en los sitios restantes ni pérdida de datos. |
Una implementación multi-grid en varios sitios
Para agregar una capa adicional de redundancia, este escenario empleará dos clústeres StorageGRID y usará replicación entre redes para mantenerlos sincronizados. Para esta solución, cada clúster StorageGRID tendrá tres sitios. Se utilizarán dos sitios para el almacenamiento de objetos y metadatos, mientras que el tercer sitio se utilizará únicamente para metadatos. Ambos sistemas se configurarán con una regla ILM equilibrada para almacenar sincrónicamente los objetos utilizando codificación de borrado en cada uno de los dos sitios de datos. Los buckets se configurarán con el modelo de consistencia global Quorum Strong. Cada cuadrícula se configurará con replicación entre cuadrículas bidireccional en cada segmento. Esto proporciona la replicación asincrónica entre las regiones. Opcionalmente, se puede implementar un balanceador de carga global para administrar las solicitudes a los grupos de alta disponibilidad del balanceador de carga integrado de ambos sistemas StorageGRID para lograr un RPO cero.
La solución utilizará cuatro ubicaciones igualmente divididas en dos regiones. La región 1 contendrá los 2 sitios de almacenamiento de grid 1 como cuadrícula principal de la región y el sitio de metadatos de grid 2. La región 2 contendrá los 2 sitios de almacenamiento de grid 2 como cuadrícula principal de la región y el sitio de metadatos de grid 1. En cada región, la misma ubicación puede alojar el sitio de almacenamiento de la cuadrícula principal de la región, así como el sitio de metadatos de la cuadrícula de otras regiones. El uso de nodos de metadatos como el tercer sitio proporcionará la consistencia necesaria para los metadatos y no duplicará el almacenamiento de los objetos en esa ubicación.
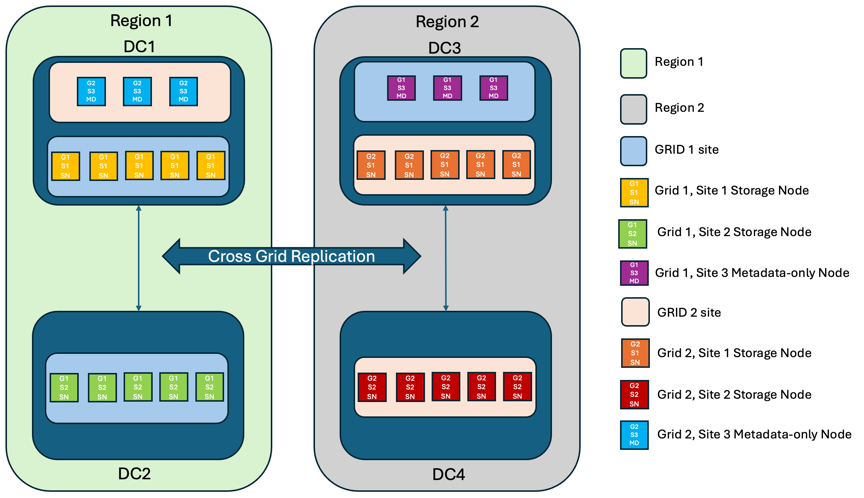
Esta solución con cuatro ubicaciones independientes proporciona una redundancia completa de dos sistemas StorageGRID independientes que mantienen un objetivo de punto de recuperación de 0 RPO y utilizará replicación síncrona multisitio y replicación asíncrona multi-grid. Todo sitio puede fallar sin interrumpir las operaciones de cliente en ambos sistemas StorageGRID.
En esta solución, existen cuatro copias con código de borrado de cada objeto y 18 réplicas de todos los metadatos. Esto permite el caso de múltiples escenarios de fallo sin afectar a las operaciones del cliente. En caso de que se produzcan fallos, las actualizaciones de recuperación de la interrupción se sincronizarán automáticamente con el sitio o los nodos que hayan fallado.
Escenarios de fallos de varios grid y varios sitios
| Fallo | Resultado |
|---|---|
Fallo de unidad de nodo único |
Cada dispositivo utiliza varios grupos de discos y puede mantener al menos 1 unidades por grupo sin interrupciones ni pérdida de datos. |
Fallo de un nodo en un sitio de un grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo de un solo nodo en un sitio en cada grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo de varios nodos en un sitio de un grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo de varios nodos en un sitio en cada grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo de un único nodo en varios sitios de un grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo de un único nodo en varios sitios en cada grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo de sitio único en un grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo de un único sitio en cada grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallos de un sitio único más nodo en un grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Sitio único más un nodo de cada sitio restante en un único grid |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo de ubicación única |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo en una ubicación única en cada cuadrícula DC1 y DC3 |
Las operaciones se interrumpirán hasta que se resuelva el fallo o se reduzca la coherencia de los bloques; cada grid pierde 2 sitios Todos los datos siguen existiendo en 2 ubicaciones |
Fallo en una ubicación única en cada cuadrícula DC1 y DC4 o DC2 y DC3 |
Sin interrupción de las operaciones ni pérdida de datos. |
Fallo en una ubicación única en cada cuadrícula DC2 y DC4 |
Sin interrupción de las operaciones ni pérdida de datos. |
Aislamiento de red de un sitio |
Las operaciones se interrumpirán en el sitio aislado, pero no se perderán datos Sin interrupciones en las operaciones de los sitios restantes ni pérdida de datos. |
Conclusión
Lograr un objetivo de punto de recuperación cero (RPO) con StorageGRID es un objetivo fundamental para garantizar la durabilidad y disponibilidad de los datos en caso de fallo del sitio. Al aprovechar las sólidas estrategias de replicación de StorageGRID, incluida la replicación síncrona de varios sitios y la replicación asíncrona de varios grid, las organizaciones pueden mantener operaciones de cliente sin interrupciones y garantizar la coherencia de los datos entre varias ubicaciones. La implementación de las políticas de gestión de la vida útil de la información (ILM) y el uso de nodos solo de metadatos mejoran aún más la resiliencia y el rendimiento del sistema. Con StorageGRID, las empresas pueden gestionar sus datos con total confianza y con la tranquilidad de saber que siguen siendo accesibles y coherentes, incluso cuando se producen fallos complejos. Este enfoque integral de la replicación y la gestión de datos subraya la importancia de una planificación y ejecución meticulosas para lograr un RPO cero y proteger la información valiosa.