

Utilice el conector Hadoop S3A de Cloudera con StorageGRID
 Sugerir cambios
Sugerir cambios
Por Angela Cheng
Hadoop ha sido el favorito de los científicos de datos desde hace algún tiempo. Hadoop permite el procesamiento distribuido de grandes conjuntos de datos a través de clusters de ordenadores utilizando marcos de programación simples. Hadoop se diseñó para escalar verticalmente de un solo servidor a miles de máquinas, mientras que cada máquina poseía almacenamiento e informática local.
¿Por qué utilizar S3A para los flujos de trabajo de Hadoop?
A medida que el volumen de datos crece con el tiempo, el método de añadir nuevos equipos con sus propios recursos informáticos y de almacenamiento resulta ineficiente. Escalar de forma lineal crea retos para usar los recursos de forma eficiente y gestionar la infraestructura.
Para abordar estos retos, el cliente Hadoop S3A ofrece I/o de alto rendimiento frente al almacenamiento de objetos S3. Implementar un flujo de trabajo de Hadoop con S3A le ayuda a aprovechar el almacenamiento de objetos como repositorio de datos y le permite separar los recursos informáticos y de almacenamiento, lo que, a su vez, le permite escalar la computación y el almacenamiento de forma independiente. La disociación de la computación y el almacenamiento también le permite dedicar la cantidad adecuada de recursos a sus tareas informáticas y proporcionar capacidad en función del tamaño del conjunto de datos. Por lo tanto, es posible reducir el TCO general para los flujos de trabajo de Hadoop.
Configurar el conector S3A para usar StorageGRID
Requisitos previos
-
Una URL de extremo de StorageGRID S3, una clave de acceso de inquilino s3 y una clave secreta para las pruebas de conexión Hadoop S3A.
-
Un clúster Cloudera y permiso root o sudo para cada host del clúster para instalar el paquete Java.
A partir de abril de 2022, se había probado Java 11.0.14 con Cloudera 7.1.7 frente a StorageGRID 11.5 y 11.6. Sin embargo, el número de versión de Java puede ser diferente en el momento de una instalación nueva.
Instale el paquete Java
-
Consulta la "Matriz de compatibilidad de Cloudera" para conocer la versión de JDK compatible.
-
Descargue el "Paquete Java 11.x." Que coincidan con el sistema operativo del clúster Cloudera. Copie este paquete en cada host del clúster. En este ejemplo, el paquete rpm se utiliza para CentOS.
-
Inicie sesión en cada host como raíz o utilice una cuenta con permiso sudo. Realice los siguientes pasos en cada host:
-
Instale el paquete:
$ sudo rpm -Uvh jdk-11.0.14_linux-x64_bin.rpm
-
Compruebe dónde está instalado Java. Si se instalan varias versiones, establezca la versión recién instalada como predeterminada:
alternatives --config java There are 2 programs which provide 'java'. Selection Command ----------------------------------------------- +1 /usr/java/jre1.8.0_291-amd64/bin/java 2 /usr/java/jdk-11.0.14/bin/java Enter to keep the current selection[+], or type selection number: 2
-
Agregue esta línea al final de
/etc/profile. La ruta debe coincidir con la ruta de la selección anterior:export JAVA_HOME=/usr/java/jdk-11.0.14
-
Ejecute el siguiente comando para que el perfil surta efecto:
source /etc/profile
-
Configuración de Cloudera HDFS S3A
-
Pasos*
-
En la interfaz gráfica de usuario de Cloudera Manager, seleccione Clusters > HDFS y seleccione Configuration.
-
En CATEGORÍA, seleccione Avanzado y desplácese hacia abajo para localizar
Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml. -
Haga clic en el signo (+) y agregue los siguientes pares de valor.
Nombre Valor fs.s3a.access.key
<clave de acceso de inquilino s3 de StorageGRID>
fs.s3a.secret.key
<clave secreta de inquilino s3 de StorageGRID>
fs.s3a.connection.ssl.enabled
[verdadero o falso] (el valor predeterminado es https si falta esta entrada)
fs.s3a.endpoint
<StorageGRID S3 endpoint:Port>
fs.s3a.impl
Org.apache.hadoop.fs.s3a.S3AFileSystem
fs.s3a.path.style.access
[verdadero o falso] (el estilo de host virtual es el predeterminado si falta esta entrada)
Captura de pantalla de ejemplo
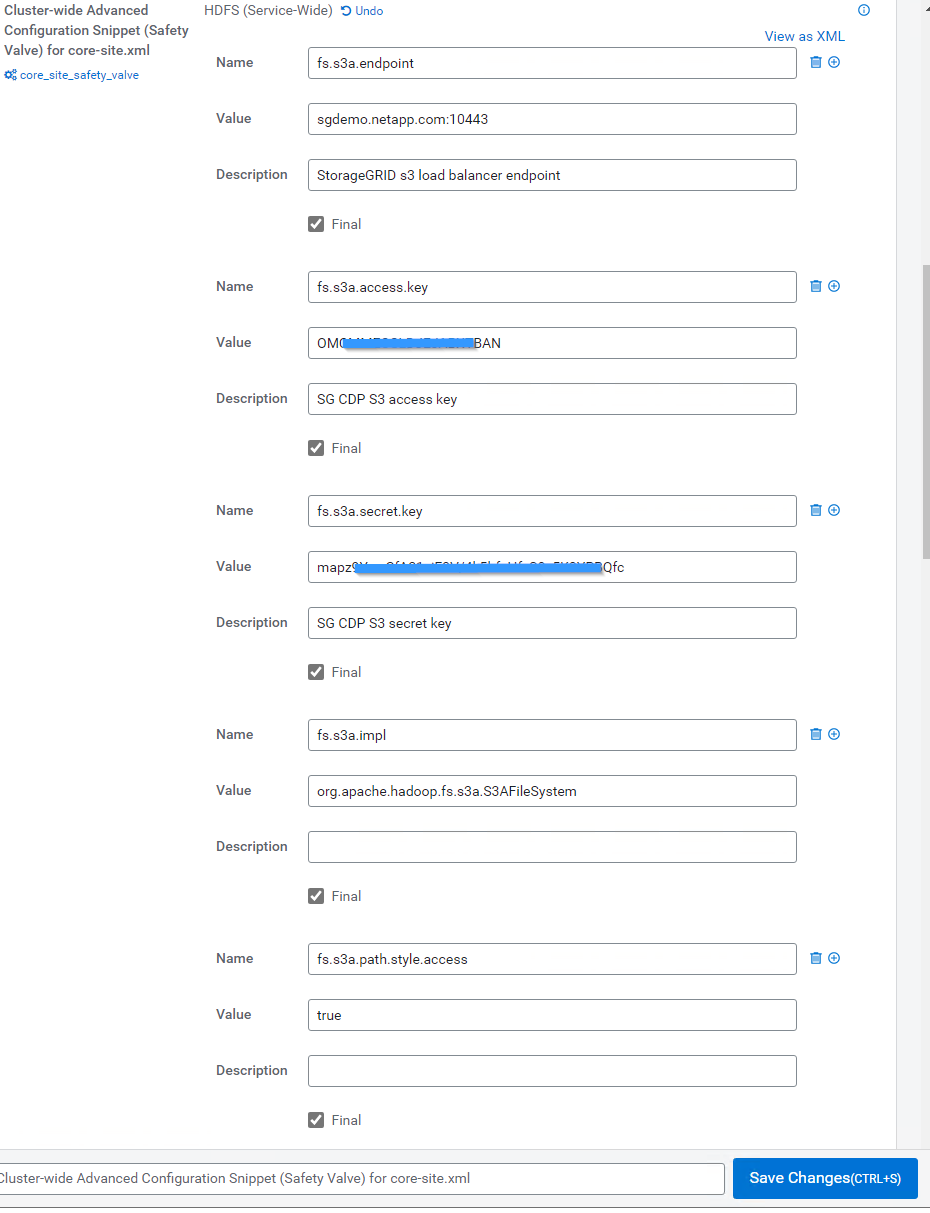
-
Haga clic en el botón Save Changes. Seleccione el icono Configuración obsoleta en la barra de menús de HDFS, seleccione Reiniciar servicios obsoletos en la página siguiente y seleccione Reiniciar ahora.
-
Probar la conexión S3A a StorageGRID
Realizar una prueba de conexión básica
Inicie sesión en uno de los hosts del clúster Cloudera y escriba hadoop fs -ls s3a://<bucket-name>/.
En el siguiente ejemplo se utiliza el sistema de ruta con un cubo de prueba hdfs preexistente y un objeto de prueba.
[root@ce-n1 ~]# hadoop fs -ls s3a://hdfs-test/ 22/02/15 18:24:37 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties 22/02/15 18:24:37 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 22/02/15 18:24:37 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started 22/02/15 18:24:37 INFO Configuration.deprecation: No unit for fs.s3a.connection.request.timeout(0) assuming SECONDS Found 1 items -rw-rw-rw- 1 root root 1679 2022-02-14 16:03 s3a://hdfs-test/test 22/02/15 18:24:38 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system... 22/02/15 18:24:38 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped. 22/02/15 18:24:38 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete.
Resolución de problemas
Situación 1
Utilice una conexión HTTPS a StorageGRID y obtenga una handshake_failure error tras un tiempo de espera de 15 minutos.
Razón: Versión antigua de JRE/JDK utilizando un conjunto de cifrado TLS obsoleto o no compatible para la conexión con StorageGRID.
Mensaje de error de muestra
[root@ce-n1 ~]# hadoop fs -ls s3a://hdfs-test/ 22/02/15 18:52:34 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties 22/02/15 18:52:34 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 22/02/15 18:52:34 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started 22/02/15 18:52:35 INFO Configuration.deprecation: No unit for fs.s3a.connection.request.timeout(0) assuming SECONDS 22/02/15 19:04:51 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system... 22/02/15 19:04:51 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped. 22/02/15 19:04:51 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete. 22/02/15 19:04:51 WARN fs.FileSystem: Failed to initialize fileystem s3a://hdfs-test/: org.apache.hadoop.fs.s3a.AWSClientIOException: doesBucketExistV2 on hdfs: com.amazonaws.SdkClientException: Unable to execute HTTP request: Received fatal alert: handshake_failure: Unable to execute HTTP request: Received fatal alert: handshake_failure ls: doesBucketExistV2 on hdfs: com.amazonaws.SdkClientException: Unable to execute HTTP request: Received fatal alert: handshake_failure: Unable to execute HTTP request: Received fatal alert: handshake_failure
Resolución: Asegúrese de que JDK 11.x o posterior esté instalado y establecido en la biblioteca Java predeterminada. Consulte la Instale el paquete Java para obtener más información.
Situación 2:
Error al conectarse a StorageGRID con mensaje de error Unable to find valid certification path to requested target.
Razón: el programa Java no confía en el certificado del servidor de extremo StorageGRID S3.
Mensaje de error de muestra:
[root@hdp6 ~]# hadoop fs -ls s3a://hdfs-test/ 22/03/11 20:58:12 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties 22/03/11 20:58:13 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 22/03/11 20:58:13 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started 22/03/11 20:58:13 INFO Configuration.deprecation: No unit for fs.s3a.connection.request.timeout(0) assuming SECONDS 22/03/11 21:12:25 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system... 22/03/11 21:12:25 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped. 22/03/11 21:12:25 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete. 22/03/11 21:12:25 WARN fs.FileSystem: Failed to initialize fileystem s3a://hdfs-test/: org.apache.hadoop.fs.s3a.AWSClientIOException: doesBucketExistV2 on hdfs: com.amazonaws.SdkClientException: Unable to execute HTTP request: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target: Unable to execute HTTP request: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
Resolución: NetApp recomienda el uso de un certificado de servidor emitido por una autoridad pública de firma de certificación conocida para garantizar la seguridad de la autenticación. También puede agregar un certificado de servidor o CA personalizado al almacén de confianza de Java.
Complete los siguientes pasos para agregar una CA personalizada de StorageGRID o un certificado de servidor al almacén de confianza de Java.
-
Realice una copia de seguridad del archivo Cacits de Java predeterminado existente.
cp -ap $JAVA_HOME/lib/security/cacerts $JAVA_HOME/lib/security/cacerts.orig
-
Importe el certificado de extremo de StorageGRID S3 al almacén de confianza de Java.
keytool -import -trustcacerts -keystore $JAVA_HOME/lib/security/cacerts -storepass changeit -noprompt -alias sg-lb -file <StorageGRID CA or server cert in pem format>
Consejos para la solución de problemas
-
Aumente el nivel de registro de hadoop para DEPURAR.
export HADOOP_ROOT_LOGGER=hadoop.root.logger=DEBUG,console -
Ejecute el comando y dirija los mensajes del registro a error.log.
hadoop fs -ls s3a://<bucket-name>/ &>error.log
Por Angela Cheng