

Analyse d'un événement de performances dynamiques sur un cluster dans une configuration MetroCluster
 Suggérer des modifications
Suggérer des modifications
Vous pouvez utiliser Unified Manager pour analyser le cluster dans une configuration MetroCluster sur laquelle un événement de performances a été détecté. Vous pouvez identifier le nom du cluster, le temps de détection des événements et les charges de travail tyran et victime impliquées.
Ce dont vous aurez besoin
-
Vous devez avoir le rôle opérateur, administrateur d'applications ou administrateur de stockage.
-
Dans une configuration MetroCluster, il doit y avoir de nouveaux événements de performances, confirmés ou obsolètes.
-
Les deux clusters de la configuration MetroCluster doivent être surveillés par la même instance de Unified Manager.
-
Affichez la page Détails de l'événement pour afficher des informations sur l'événement.
-
Consultez la description de l'événement pour connaître les noms des charges de travail impliquées et le nombre de charges de travail impliquées.
Dans cet exemple, l'icône Ressources MetroCluster est rouge, indiquant que les ressources MetroCluster sont en conflit. Vous placez le curseur sur l'icône pour afficher une description de l'icône.

-
Notez le nom du cluster et l'heure de détection des événements. Ces informations peuvent être utilisées pour analyser les événements de performances sur le cluster partenaire.
-
Dans les graphiques, examinez les charges de travail victime pour vérifier que leurs temps de réponse sont supérieurs au seuil de performance.
Dans cet exemple, la charge de travail victime est affichée dans le texte du curseur de la souris. Les graphiques latence affichent, à un modèle de latence cohérent et général, pour les charges de travail victimes impliquées. Bien que la latence anormale des charges de travail victimes ait déclenché l'événement, un modèle de latence cohérent peut indiquer que les workloads fonctionnent dans la plage prévue, mais qu'un pic d'E/S a augmenté la latence et déclenché l'événement.
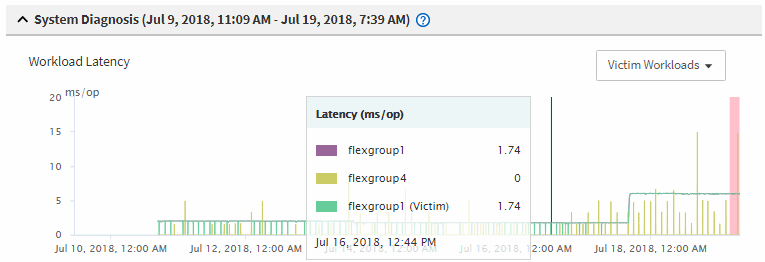
Si vous avez récemment installé une application sur un client qui accède à ces charges de travail de volume et que cette application y envoie une quantité importante d'E/S, vous envisagez peut-être d'augmenter la latence. Si la latence des charges de travail renvoie dans la plage attendue, l'état d'événement devient obsolète et reste dans cet état pendant plus de 30 minutes, vous pouvez sans doute ignorer la situation. Si l'événement est en cours et reste dans le nouvel état, vous pouvez l'étudier davantage pour déterminer si d'autres problèmes ont causé l'événement.
-
Dans le graphique débit des charges de travail, sélectionnez charges de travail bulles pour afficher les charges de travail dominantes.
La présence de charges de travail dominantes indique que l'événement peut avoir été causé par un ou plusieurs workloads sur le cluster local qui utilisent les ressources MetroCluster. Les workloads dominants ont un débit d'écriture élevé en exemple (Mbit/s).
Ce graphique présente le modèle de débit d'écriture (Mbit/s) élevé des charges de travail. Vous pouvez examiner le modèle de Mo/s d'écriture pour identifier un débit anormal, ce qui peut indiquer qu'une charge de travail surutilise les ressources MetroCluster.
Si aucune charge de travail dominante n'est impliquée dans l'événement, l'événement peut avoir été provoqué par un problème de santé lié à la liaison entre les clusters ou à un problème de performance sur le cluster partenaire. Vous pouvez utiliser Unified Manager pour vérifier l'état de santé des deux clusters dans une configuration MetroCluster. Vous pouvez également utiliser Unified Manager pour vérifier et analyser les événements de performance sur le cluster partenaire.