

Préparez la source et la cible dans NetApp Copy and Sync
 Suggérer des modifications
Suggérer des modifications
Vérifiez que votre source et vos cibles répondent aux exigences suivantes dans NetApp Copy and Sync.
Réseautage
-
La source et la cible doivent disposer d'une connexion réseau au groupe de courtiers de données.
Par exemple, si un serveur NFS se trouve dans votre centre de données et qu'un courtier de données se trouve dans AWS, vous avez besoin d'une connexion réseau (VPN ou Direct Connect) de votre réseau au VPC.
-
NetApp recommande de configurer la source, la cible et les courtiers de données pour utiliser un service NTP (Network Time Protocol). La différence de temps entre les trois composants ne doit pas dépasser 5 minutes.
Répertoire cible
Lorsque vous créez une relation de synchronisation, Copier et synchroniser vous permet de sélectionner un répertoire cible existant, puis éventuellement de créer un nouveau dossier à l'intérieur de ce répertoire. Assurez-vous donc que votre répertoire cible préféré existe déjà.
Autorisations de lecture des répertoires
Afin d'afficher chaque répertoire ou dossier d'une source ou d'une cible, Copy and Sync a besoin d'autorisations de lecture sur le répertoire ou le dossier.
- NFS
-
Les autorisations doivent être définies sur la source/cible avec uid/gid sur les fichiers et les répertoires.
- Stockage d'objets
-
-
Pour AWS et Google Cloud, un courtier de données doit disposer d'autorisations d'objet de liste (ces autorisations sont fournies par défaut si vous suivez les étapes d'installation du courtier de données).
-
Pour Azure, StorageGRID et IBM, les informations d’identification que vous saisissez lors de la configuration d’une relation de synchronisation doivent disposer d’autorisations d’objet de liste.
-
- PME
-
Les informations d’identification SMB que vous saisissez lors de la configuration d’une relation de synchronisation doivent disposer d’autorisations de dossier de liste.

|
Le courtier de données ignore par défaut les répertoires suivants : .snapshot, ~snapshot, .copy-offload |
|
|
Lors de la copie de données SMB dans Cloud Volumes ONTAP à l'aide de la fonction Copier et synchroniser, la propriété des fichiers et des dossiers du système source n'est pas conservée. Ce comportement est dû au fait que Copy and Sync utilise un client SMB Linux, qui attribue la propriété au compte utilisateur ou de service utilisé pour authentifier le transfert. Bien que les listes de contrôle d'accès puissent être conservées, les informations relatives à la propriété et à l'audit peuvent différer du système source. C'est le comportement attendu. |
Exigences du bucket Amazon S3
Assurez-vous que votre compartiment Amazon S3 répond aux exigences suivantes.
Emplacements des courtiers de données pris en charge pour Amazon S3
Les relations de synchronisation qui incluent le stockage S3 nécessitent un courtier de données déployé dans AWS ou sur vos locaux. Dans les deux cas, Copy and Sync vous invite à associer le courtier de données à un compte AWS lors de l'installation.
Régions AWS prises en charge
Toutes les régions sont prises en charge, à l'exception des régions de Chine.
Autorisations requises pour les compartiments S3 dans d'autres comptes AWS
Lors de la configuration d'une relation de synchronisation, vous pouvez spécifier un compartiment S3 qui réside dans un compte AWS qui n'est pas associé à un courtier de données.
"Les autorisations incluses dans ce fichier JSON"doit être appliqué à ce compartiment S3 pour qu'un courtier de données puisse y accéder. Ces autorisations permettent au courtier de données de copier des données vers et depuis le bucket et de répertorier les objets dans le bucket.
Notez les points suivants concernant les autorisations incluses dans le fichier JSON :
-
<BucketName> est le nom du bucket qui réside dans le compte AWS qui n'est pas associé à un courtier de données.
-
<RoleARN> doit être remplacé par l'un des éléments suivants :
-
Si un courtier de données a été installé manuellement sur un hôte Linux, RoleARN doit être l'ARN de l'utilisateur AWS pour lequel vous avez fourni les informations d'identification AWS lors du déploiement d'un courtier de données.
-
Si un courtier de données a été déployé dans AWS à l’aide du modèle CloudFormation, RoleARN doit être l’ARN du rôle IAM créé par le modèle.
Vous pouvez trouver l'ARN du rôle en accédant à la console EC2, en sélectionnant l'instance du courtier de données, puis en sélectionnant le rôle IAM dans l'onglet Description. Vous devriez alors voir la page Résumé dans la console IAM qui contient l’ARN du rôle.

-
Exigences de stockage Azure Blob
Assurez-vous que votre stockage d’objets blob Azure répond aux exigences suivantes.
Emplacements des courtiers de données pris en charge pour Azure Blob
Un courtier de données peut résider à n’importe quel emplacement lorsqu’une relation de synchronisation inclut le stockage Azure Blob.
Régions Azure prises en charge
Toutes les régions sont prises en charge, à l'exception des régions Chine, Gouvernement américain et Département de la Défense américain.
Chaîne de connexion pour les relations qui incluent Azure Blob et NFS/SMB
Lors de la création d'une relation de synchronisation entre un conteneur Azure Blob et un serveur NFS ou SMB, vous devez fournir Copy et Sync avec la chaîne de connexion du compte de stockage :
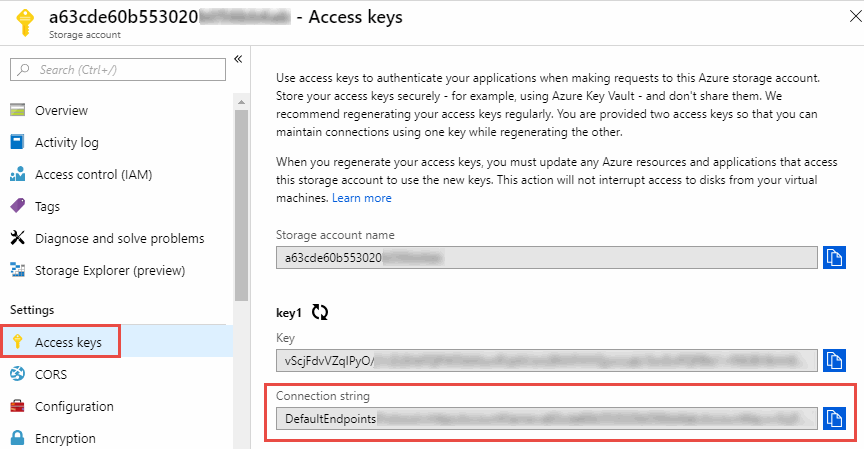
Si vous souhaitez synchroniser des données entre deux conteneurs Azure Blob, la chaîne de connexion doit inclure un "signature d'accès partagé" (SAS). Vous avez également la possibilité d'utiliser un SAS lors de la synchronisation entre un conteneur Blob et un serveur NFS ou SMB.
Le SAS doit autoriser l'accès au service Blob et à tous les types de ressources (Service, Conteneur et Objet). Le SAS doit également inclure les autorisations suivantes :
-
Pour le conteneur Blob source : Lire et Lister
-
Pour le conteneur Blob cible : lecture, écriture, liste, ajout et création
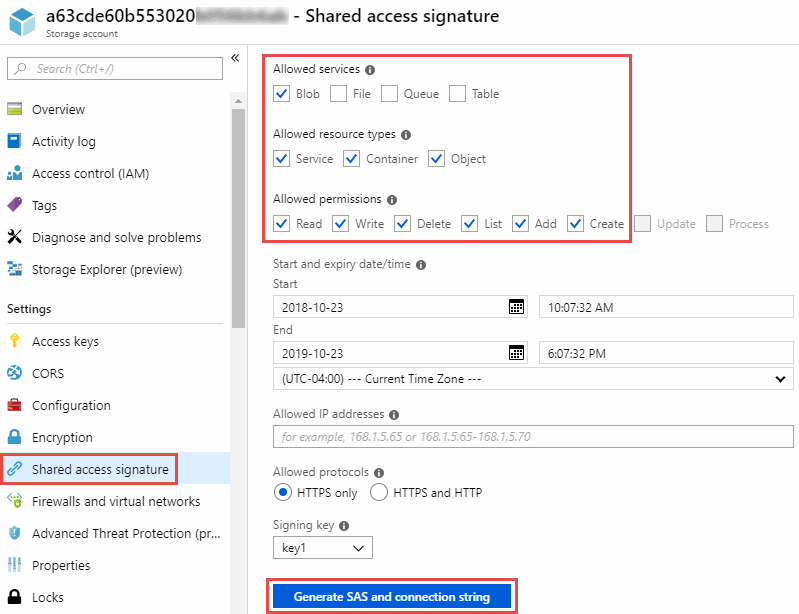
|
|
Si vous choisissez d’implémenter une relation de synchronisation continue qui inclut un conteneur Azure Blob, vous pouvez utiliser une chaîne de connexion standard ou une chaîne de connexion SAS. Si vous utilisez une chaîne de connexion SAS, elle ne doit pas être configurée pour expirer dans un avenir proche. |
Stockage Azure Data Lake Gen2
Lors de la création d’une relation de synchronisation qui inclut Azure Data Lake, vous devez fournir Copie et synchronisation avec la chaîne de connexion du compte de stockage. Il doit s'agir d'une chaîne de connexion régulière et non d'une signature d'accès partagé (SAS).
Exigences relatives aux Azure NetApp Files
Utilisez le niveau de service Premium ou Ultra lorsque vous synchronisez des données vers ou depuis Azure NetApp Files. Vous risquez de rencontrer des échecs et des problèmes de performances si le niveau de service du disque est Standard.

|
Consultez un architecte de solutions si vous avez besoin d’aide pour déterminer le niveau de service approprié. La taille du volume et le niveau de volume déterminent le débit que vous pouvez obtenir. |
Exigences relatives à la boîte
-
Pour créer une relation de synchronisation qui inclut Box, vous devrez fournir les informations d'identification suivantes :
-
ID client
-
Secret client
-
Clé privée
-
ID de clé publique
-
Phrase de passe
-
ID d'entreprise
-
-
Si vous créez une relation de synchronisation d'Amazon S3 vers Box, vous devez utiliser un groupe de courtiers de données doté d'une configuration unifiée où les paramètres suivants sont définis sur 1 :
-
Concurrence des scanners
-
Limite des processus du scanner
-
Concurrence du transféreur
-
Limite des processus de transfert
-
Exigences relatives au bucket Google Cloud Storage
Assurez-vous que votre bucket Google Cloud Storage répond aux exigences suivantes.
Emplacements des courtiers de données pris en charge pour Google Cloud Storage
Les relations de synchronisation qui incluent Google Cloud Storage nécessitent un courtier de données déployé dans Google Cloud ou sur vos locaux. Copy and Sync vous guide tout au long du processus d'installation du courtier de données lorsque vous créez une relation de synchronisation.
Régions Google Cloud prises en charge
Toutes les régions sont prises en charge.
Autorisations pour les buckets dans d'autres projets Google Cloud
Lors de la configuration d'une relation de synchronisation, vous pouvez choisir parmi les buckets Google Cloud dans différents projets, si vous fournissez les autorisations requises au compte de service du courtier de données. "Apprenez à configurer le compte de service" .
Autorisations pour une destination SnapMirror
Si la source d'une relation de synchronisation est une destination SnapMirror (qui est en lecture seule), les autorisations « lecture/liste » sont suffisantes pour synchroniser les données de la source vers une cible.
Chiffrer un bucket Google Cloud
Vous pouvez chiffrer un bucket Google Cloud cible avec une clé KMS gérée par le client ou la clé par défaut gérée par Google. Si le bucket dispose déjà d'un cryptage KMS, il remplacera le cryptage par défaut géré par Google.
Pour ajouter une clé KMS gérée par le client, vous devrez utiliser un courtier de données avec le "autorisations correctes" , et la clé doit être dans la même région que le bucket.
Google Drive
Lorsque vous configurez une relation de synchronisation qui inclut Google Drive, vous devez fournir les éléments suivants :
-
L'adresse e-mail d'un utilisateur qui a accès à l'emplacement Google Drive où vous souhaitez synchroniser les données
-
L'adresse e-mail d'un compte de service Google Cloud disposant des autorisations nécessaires pour accéder à Google Drive
-
Une clé privée pour le compte de service
Pour configurer le compte de service, suivez les instructions de la documentation Google :
Lorsque vous modifiez le champ Étendues OAuth, saisissez les étendues suivantes :
Configuration requise pour le serveur NFS
-
Le serveur NFS peut être un système NetApp ou un système non NetApp .
-
Le serveur de fichiers doit permettre à un hôte de courtier de données d'accéder aux exportations via les ports requis.
-
111 TCP/UDP
-
2049 TCP/UDP
-
5555 TCP/UDP
-
-
Les versions NFS 3, 4.0, 4.1 et 4.2 sont prises en charge.
La version souhaitée doit être activée sur le serveur.
-
Si vous souhaitez synchroniser les données NFS à partir d'un système ONTAP , assurez-vous que l'accès à la liste d'exportation NFS pour un SVM est activé (vserver nfs modify -vserver svm_name -showmount enabled).
Le paramètre par défaut pour showmount est enabled à partir d' ONTAP 9.2.
Exigences ONTAP
Si la relation de synchronisation inclut Cloud Volumes ONTAP ou un cluster ONTAP sur site et que vous avez sélectionné NFSv4 ou une version ultérieure, vous devrez activer les ACL NFSv4 sur le système ONTAP . Ceci est nécessaire pour copier les ACL.
Exigences de stockage ONTAP S3
Lorsque vous configurez une relation de synchronisation qui inclut "Stockage ONTAP S3" , vous devrez fournir les éléments suivants :
-
L'adresse IP du LIF connecté à ONTAP S3
-
La clé d'accès et la clé secrète ONTAP est configuré pour utiliser
Configuration requise pour le serveur SMB
-
Le serveur SMB peut être un système NetApp ou un système non NetApp .
-
Vous devez fournir à Copy and Sync des informations d'identification disposant d'autorisations sur le serveur SMB.
-
Pour un serveur SMB source, les autorisations suivantes sont requises : liste et lecture.
Les membres du groupe Opérateurs de sauvegarde sont pris en charge avec un serveur SMB source.
-
Pour un serveur SMB cible, les autorisations suivantes sont requises : liste, lecture et écriture.
-
-
Le serveur de fichiers doit permettre à un hôte de courtier de données d'accéder aux exportations via les ports requis.
-
139 TCP
-
445 TCP
-
137-138 UDP
-
-
Les versions SMB 1.0, 2.0, 2.1, 3.0 et 3.11 sont prises en charge.
-
Accordez au groupe « Administrateurs » les autorisations « Contrôle total » sur les dossiers source et cible.
Si vous n'accordez pas cette autorisation, le courtier de données risque de ne pas disposer des autorisations suffisantes pour obtenir les ACL sur un fichier ou un répertoire. Si cela se produit, vous recevrez l'erreur suivante : « getxattr error 95 »
Limitation SMB pour les répertoires et fichiers cachés
Une limitation SMB affecte les répertoires et fichiers cachés lors de la synchronisation des données entre les serveurs SMB. Si l’un des répertoires ou fichiers du serveur SMB source a été masqué via Windows, l’attribut masqué n’est pas copié sur le serveur SMB cible.
Comportement de synchronisation SMB en raison de la limitation de l'insensibilité à la casse
Le protocole SMB n'est pas sensible à la casse, ce qui signifie que les lettres majuscules et minuscules sont traitées comme étant identiques. Ce comportement peut entraîner des fichiers écrasés et des erreurs de copie de répertoire, si une relation de synchronisation inclut un serveur SMB et que des données existent déjà sur la cible.
Par exemple, disons qu’il y a un fichier nommé « a » sur la source et un fichier nommé « A » sur la cible. Lorsque Copier et Sync copie le fichier nommé « a » vers la cible, le fichier « A » est écrasé par le fichier « a » de la source.
Dans le cas des répertoires, disons qu'il y a un répertoire nommé « b » sur la source et un répertoire nommé « B » sur la cible. Lorsque Copy and Sync tente de copier le répertoire nommé « b » vers la cible, Copy and Sync reçoit une erreur indiquant que le répertoire existe déjà. Par conséquent, Copy and Sync ne parvient toujours pas à copier le répertoire nommé « b ».
La meilleure façon d’éviter cette limitation est de s’assurer de synchroniser les données dans un répertoire vide.