

Installez NetApp Data Classification sur un hôte disposant d'un accès Internet
 Suggérer des modifications
Suggérer des modifications
Pour déployer NetApp Data Classification sur un hôte Linux de votre réseau ou sur un hôte Linux dans le cloud disposant d'un accès Internet, vous devez déployer manuellement l'hôte Linux sur votre réseau ou dans le cloud.
L'installation sur site est une bonne option si vous préférez analyser les systèmes ONTAP sur site à l'aide d'une instance de classification des données également située sur site. Ce n’est pas une exigence. Le logiciel fonctionne de la même manière quelle que soit la méthode d'installation choisie.
Le script d'installation de la classification des données commence par vérifier si le système et l'environnement répondent aux prérequis requis. Si toutes les conditions préalables sont remplies, l'installation démarre. Si vous souhaitez vérifier les conditions préalables indépendamment de l'exécution de l'installation de la classification des données, vous pouvez télécharger un progiciel distinct qui teste uniquement les conditions préalables. "Découvrez comment vérifier si votre hôte Linux est prêt à installer la classification des données" .

|
Pour les déploiements VMware sur site vSphere, la classification des données prend en charge une version simplifiée "déploiement avec OVA". |
L'installation typique sur un hôte Linux dans vos locaux comporte les composants et connexions suivants.
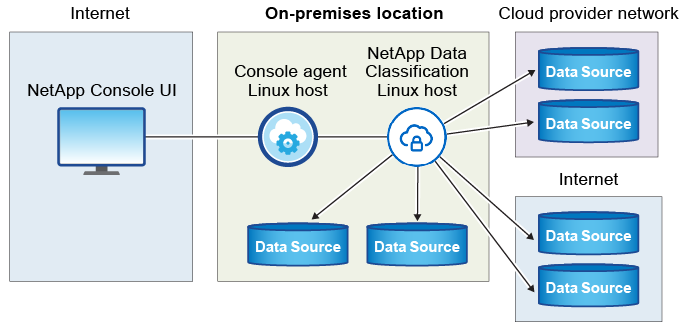
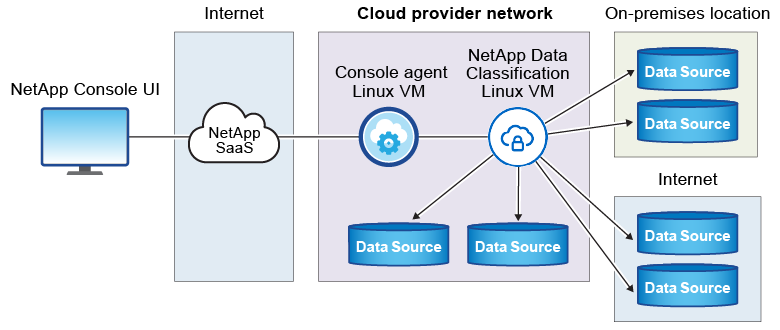
L'installation typique sur un hôte Linux dans le cloud comporte les composants et connexions suivants.
Démarrage rapide
Commencez rapidement en suivant ces étapes ou faites défiler les sections restantes pour obtenir tous les détails.
 Créer un agent de console
Créer un agent de consoleSi vous n'avez pas encore d'agent de console, "déployer l'agent de console sur site" sur un hôte Linux de votre réseau ou sur un hôte Linux dans le cloud.
Vous pouvez également créer un agent de console avec votre fournisseur de cloud. Voir "création d'un agent de console dans AWS" , "création d'un agent de console dans Azure" , ou "création d'un agent de console dans GCP" .
 Réviser les prérequis
Réviser les prérequisAssurez-vous que votre environnement peut répondre aux prérequis. Cela inclut l'accès Internet sortant pour l'instance, la connectivité entre l'agent de console et la classification des données via le port 443, et bien plus encore. Voir la liste complète .
Vous avez également besoin d'un système Linux qui répond auxexigences suivantes .
 Téléchargez et déployez la classification des données
Téléchargez et déployez la classification des donnéesTéléchargez le logiciel Cloud Data Classification à partir du site de support NetApp et copiez le fichier d'installation sur l'hôte Linux que vous prévoyez d'utiliser. Lancez ensuite l’assistant d’installation et suivez les invites pour déployer l’instance de classification des données.
Créer un agent de console
Un agent Console est requis pour installer et utiliser NetApp Data Classification. Dans la plupart des cas, un agent Console sera probablement déjà installé avant que vous n'essayiez d'activer NetApp Data Classification.
Pour en créer un dans votre environnement de fournisseur de cloud, consultez "création d'un agent de console dans AWS" , "création d'un agent de console dans Azure" , ou "création d'un agent de console dans GCP" .
Il existe certains scénarios dans lesquels vous devez utiliser un agent de console déployé chez un fournisseur de cloud spécifique :
-
Lors de l'analyse des données dans Cloud Volumes ONTAP dans AWS ou Amazon FSx for ONTAP, vous utilisez un agent de console dans AWS.
-
Lors de l’analyse des données dans Cloud Volumes ONTAP dans Azure ou dans Azure NetApp Files, vous utilisez un agent de console dans Azure.
Pour Azure NetApp Files, il doit être déployé dans la même région que les volumes que vous souhaitez analyser.
-
Lors de l’analyse des données dans Cloud Volumes ONTAP dans GCP, vous utilisez un agent de console dans GCP.
Les systèmes ONTAP sur site, les partages de fichiers NetApp et les comptes de base de données peuvent être analysés à l’aide de l’un de ces agents de console cloud.
Notez que vous pouvez également "déployer l'agent de console sur site" sur un hôte Linux de votre réseau ou sur un hôte Linux dans le cloud. Certains utilisateurs prévoyant d’installer la classification des données sur site peuvent également choisir d’installer l’agent de console sur site.
Vous aurez besoin de l'adresse IP ou du nom d'hôte du système d'agent de la console lors de l'installation de la classification des données. Vous disposerez de ces informations si vous avez installé l'agent Console dans vos locaux. Si l'agent de la console est déployé dans le cloud, vous pouvez trouver ces informations depuis la console : sélectionnez l'icône Aide puis Support puis Agent de la console.
Préparer le système hôte Linux
Le logiciel de classification des données doit s'exécuter sur un hôte qui répond aux exigences spécifiques du système d'exploitation, aux exigences de RAM, aux exigences logicielles, etc. L'hôte Linux peut être dans votre réseau ou dans le cloud.
Assurez-vous de pouvoir maintenir la classification des données en cours d'exécution. La machine de classification des données doit rester allumée pour analyser en continu vos données.
-
La classification des données doit être hébergée sur un serveur dédié. L'hôte ne peut pas être partagé avec d'autres applications ou logiciels tiers tels que les antivirus.
-
Choisissez la taille qui correspond à l'ensemble de données que vous prévoyez d'analyser avec la classification des données.
Taille du système processeur RAM (la mémoire d'échange doit être désactivée) Disque Extra Large
32 processeurs
128 Go de RAM
-
1 Tio SSD sur /, ou 100 Gio disponibles sur /opt
-
895 Gio disponibles sur /var/lib/docker
-
5 Gio sur /tmp
-
Pour Podman, 30 Go sur /var/tmp
Grand
16 processeurs
64 Go de RAM
-
500 Gio SSD sur /, ou 100 Gio disponibles sur /opt
-
400 Gio disponibles sur /var/lib/docker ou pour Podman /var/lib/containers
-
5 Gio sur /tmp
-
Pour Podman, 30 Go sur /var/tmp
-
-
Lors du déploiement d'une instance de calcul dans le cloud pour votre installation de classification des données, il est recommandé d'utiliser un système qui répond aux exigences système « Large » ci-dessus :
-
Type d'instance Amazon Elastic Compute Cloud (Amazon EC2) : « m6i.4xlarge ». "Voir d'autres types d'instances AWS" .
-
Taille de la machine virtuelle Azure : « Standard_D16_v5 ». "Voir d'autres types d'instances Azure".
-
Type de machine GCP : « n2-standard-16 ». "Voir les types d'instances GCP supplémentaires" .
-
-
Autorisations de dossier UNIX : Les autorisations UNIX minimales suivantes sont requises :
Dossier autorisations minimales /tmp
rwxrwxrwt/opter
rwxr-xr-x/var/lib/docker
rwx------/usr/lib/systemd/système
rwxr-xr-x -
Système opérateur:
-
Les systèmes d’exploitation suivants nécessitent l’utilisation du moteur de conteneur Docker :
-
Red Hat Enterprise Linux versions 7.8 et 7.9
-
Ubuntu 22.04 (nécessite la version 1.23 ou supérieure de Data Classification)
-
Ubuntu 24.04 (nécessite la version 1.23 ou supérieure de Data Classification)
-
-
Les systèmes d'exploitation suivants nécessitent l'utilisation du moteur de conteneur Podman et nécessitent la version 1.30 ou supérieure de Data Classification :
-
Red Hat Enterprise Linux version 8.8, 8.10, 9.0, 9.1, 9.2, 9.3, 9.4, 9.5, 9.6 et 9.7.
-
-
Les extensions vectorielles avancées (AVX2) doivent être activées sur le système hôte.
-
-
Red Hat Subscription Management : L'hôte doit être enregistré auprès de Red Hat Subscription Management. S'il n'est pas enregistré, le système ne peut pas accéder aux référentiels pour mettre à jour les logiciels tiers requis lors de l'installation.
-
Logiciel supplémentaire : Vous devez installer le logiciel suivant sur l'hôte avant d'installer Data Classification :
-
Selon le système d'exploitation que vous utilisez, vous devez installer l'un des moteurs de conteneurs :
-
Docker Engine version 19.3.1 ou supérieure. "Voir les instructions d'installation" .
-
Podman version 4 ou supérieure. Pour installer Podman, entrez(
sudo yum install podman netavark -y).
-
-
-
Version Python 3.6 ou supérieure. "Voir les instructions d'installation" .
-
Considérations NTP : NetApp recommande de configurer le système de classification des données pour utiliser un service NTP (Network Time Protocol). L'heure doit être synchronisée entre le système de classification des données et le système d'agent de la console.
-
-
Considérations relatives au pare-feu : Si vous envisagez d'utiliser
firewalld, nous vous recommandons de l'activer avant d'installer Data Classification. Exécutez les commandes suivantes pour configurerfirewalldafin qu'il soit compatible avec la classification des données :firewall-cmd --permanent --add-service=http firewall-cmd --permanent --add-service=https firewall-cmd --permanent --add-port=80/tcp firewall-cmd --permanent --add-port=8080/tcp firewall-cmd --permanent --add-port=443/tcp firewall-cmd --reload
Si vous prévoyez d'utiliser des hôtes de classification de données supplémentaires comme nœuds de scanner, ajoutez ces règles à votre système principal à ce stade :
firewall-cmd --permanent --add-port=2377/tcp firewall-cmd --permanent --add-port=7946/udp firewall-cmd --permanent --add-port=7946/tcp firewall-cmd --permanent --add-port=4789/udp
Notez que vous devez redémarrer Docker ou Podman chaque fois que vous activez ou mettez à jour
firewalldparamètres.

|
L'adresse IP du système hôte de classification des données ne peut pas être modifiée après l'installation. |
Activer l'accès Internet sortant à partir de la classification des données
La classification des données nécessite un accès Internet sortant. Si votre réseau virtuel ou physique utilise un serveur proxy pour l'accès à Internet, assurez-vous que l'instance de classification des données dispose d'un accès Internet sortant pour contacter les points de terminaison suivants.
| Points de terminaison | But |
|---|---|
Communication avec la console, qui inclut les comptes NetApp . |
|
\ https://netapp-cloud-account.auth0.com \ https://auth0.com |
Communication avec le site Web de la console pour l'authentification centralisée des utilisateurs. |
\ https://support.compliance.api.bluexp.netapp.com/ \ https://hub.docker.com \ https://auth.docker.io \ https://registry-1.docker.io \ https://index.docker.io/ \ https://dseasb33srnrn.cloudfront.net/ \ https://production.cloudflare.docker.com/ |
Fournit un accès aux images logicielles, aux manifestes, aux modèles et permet d'envoyer des journaux et des métriques. |
Permet à NetApp de diffuser des données à partir des enregistrements d'audit. |
|
Fournit des packages prérequis pour l'installation de Docker. |
|
Fournit des packages prérequis pour l'installation d'Ubuntu. |
Vérifiez que tous les ports requis sont activés
Vous devez vous assurer que tous les ports requis sont ouverts pour la communication entre l'agent de console, la classification des données, Active Directory et vos sources de données.
| Type de connexion | Ports | Description |
|---|---|---|
Agent de console <> Classification des données |
8080 (TCP), 443 (TCP) et 80. 9000 |
Les règles de pare-feu ou de routage de l'agent de console doivent autoriser le trafic entrant et sortant sur le port 443 vers et depuis l'instance de classification des données. Assurez-vous que le port 8080 est ouvert afin de pouvoir voir la progression de l'installation dans la console. Si un pare-feu est utilisé sur l'hôte Linux, le port 9000 est requis pour les processus internes au sein d'un serveur Ubuntu. |
Agent de console <> cluster ONTAP (NAS) |
443 (TCP) |
La console découvre les clusters ONTAP à l'aide de HTTPS. Si vous utilisez des stratégies de pare-feu personnalisées, elles doivent répondre aux exigences suivantes :
|
Classification des données <> cluster ONTAP |
|
La classification des données nécessite une connexion réseau à chaque sous-réseau Cloud Volumes ONTAP ou à un système ONTAP sur site. Les pare-feu ou les règles de routage pour Cloud Volumes ONTAP doivent autoriser les connexions entrantes à partir de l'instance de classification des données. Assurez-vous que ces ports sont ouverts à l’instance de classification des données :
Les stratégies d’exportation de volume NFS doivent autoriser l’accès à partir de l’instance de classification des données. |
Classification des données <> Active Directory |
389 (TCP et UDP), 636 (TCP), 3268 (TCP) et 3269 (TCP) |
Vous devez déjà avoir un Active Directory configuré pour les utilisateurs de votre entreprise. De plus, la classification des données nécessite des informations d’identification Active Directory pour analyser les volumes CIFS. Vous devez disposer des informations pour Active Directory :
|
Installer la classification des données sur l'hôte Linux
Pour les configurations typiques, vous installerez le logiciel sur un seul système hôte. Voir ces étapes ici .
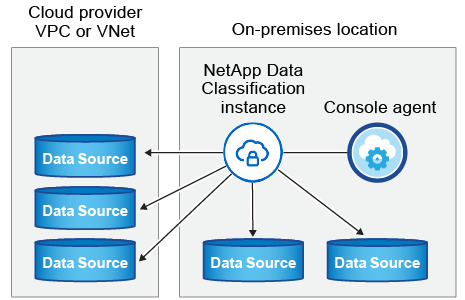
VoirPréparation du système hôte Linux etRévision des prérequis pour obtenir la liste complète des exigences avant de déployer la classification des données.
Les mises à niveau du logiciel de classification des données sont automatisées tant que l'instance dispose d'une connexion Internet.
|
|
La classification des données ne peut actuellement pas analyser les compartiments S3, Azure NetApp Files ou FSx pour ONTAP lorsque le logiciel est installé sur site. Dans ces cas, vous devrez déployer un agent de console distinct et une instance de classification des données dans le cloud et "basculer entre les connecteurs" pour vos différentes sources de données. |
Installation sur un seul hôte pour les configurations typiques
Passez en revue les exigences et suivez ces étapes lors de l’installation du logiciel de classification des données sur un seul hôte local.
"Regardez cette vidéo"pour voir comment installer Data Classification.
Notez que toutes les activités d'installation sont enregistrées lors de l'installation de Data Classification. Si vous rencontrez des problèmes lors de l’installation, vous pouvez afficher le contenu du journal d’audit d’installation. Il est écrit à /opt/netapp/install_logs/ .
-
Vérifiez que votre système Linux répond auxexigences de l'hôte .
-
Vérifiez que le système dispose des deux packages logiciels prérequis installés (Docker Engine ou Podman et Python 3).
-
Assurez-vous que vous disposez des privilèges root sur le système Linux.
-
Si vous utilisez un proxy pour accéder à Internet :
-
Vous aurez besoin des informations du serveur proxy (adresse IP ou nom d'hôte, port de connexion, schéma de connexion : https ou http, nom d'utilisateur et mot de passe).
-
Si le proxy effectue une interception TLS, vous devez connaître le chemin sur le système Linux de classification des données où les certificats CA TLS sont stockés.
-
Le proxy doit être non transparent. La classification des données ne prend actuellement pas en charge les proxys transparents.
-
L'utilisateur doit être un utilisateur local. Les utilisateurs de domaine ne sont pas pris en charge.
-
-
Vérifiez que votre environnement hors ligne répond aux exigences requisesautorisations et connectivité .
-
Téléchargez le logiciel Data Classification depuis le "Site de support NetApp". Sélectionnez le fichier nommé DATASENSE-INSTALLER-<version>.tar.gz.
-
Copiez le fichier d'installation sur l'hôte Linux que vous prévoyez d'utiliser (en utilisant
scpou une autre méthode). -
Décompressez le fichier d’installation sur la machine hôte, par exemple :
tar -xzf DATASENSE-INSTALLER-V1.25.0.tar.gz -
Dans la console, sélectionnez Gouvernance > Classification.
-
Sélectionnez Déployer la classification sur site ou dans le cloud.
-
Selon que vous installez Data Classification sur une instance que vous avez préparée dans le cloud ou sur une instance que vous avez préparée dans vos locaux, sélectionnez l'option Déployer appropriée pour démarrer l'installation de Data Classification.
-
La boîte de dialogue Déployer la classification des données sur site s'affiche. Copiez la commande fournie (par exemple :
sudo ./install.sh -a 12345 -c 27AG75 -t 2198qq) et collez-le dans un fichier texte pour pouvoir l'utiliser plus tard. Sélectionnez ensuite Fermer pour fermer la boîte de dialogue. -
Sur la machine hôte, entrez la commande que vous avez copiée, puis suivez une série d’invites, ou vous pouvez fournir la commande complète, y compris tous les paramètres requis, comme arguments de ligne de commande.
Notez que le programme d'installation effectue une pré-vérification pour s'assurer que votre système et vos exigences réseau sont en place pour une installation réussie. "Regardez cette vidéo" pour comprendre les messages et les implications du pré-contrôle.
Entrez les paramètres comme demandé : Entrez la commande complète : -
Collez la commande que vous avez copiée à l’étape 7 :
sudo ./install.sh -a <account_id> -c <client_id> -t <user_token>Si vous effectuez l'installation sur une instance cloud (pas dans vos locaux), ajoutez
--manual-cloud-install <cloud_provider>. -
Saisissez l'adresse IP ou le nom d'hôte de la machine hôte de classification des données afin que le système d'agent de la console puisse y accéder.
-
Saisissez l'adresse IP ou le nom d'hôte de la machine hôte de l'agent de console afin que le système de classification des données puisse y accéder.
-
Saisissez les détails du proxy lorsque vous y êtes invité. Si votre agent de console utilise déjà un proxy, il n'est pas nécessaire de saisir à nouveau ces informations ici, car la classification des données utilisera automatiquement le proxy utilisé par l'agent de console.
Alternativement, vous pouvez créer la commande entière à l'avance, en fournissant les paramètres d'hôte et de proxy nécessaires :
sudo ./install.sh -a <account_id> -c <client_id> -t <user_token> --host <ds_host> --manager-host <cm_host> --manual-cloud-install <cloud_provider> --proxy-host <proxy_host> --proxy-port <proxy_port> --proxy-scheme <proxy_scheme> --proxy-user <proxy_user> --proxy-password <proxy_password> --cacert-folder-path <ca_cert_dir>Valeurs des variables :
-
account_id = ID de compte NetApp
-
client_id = ID client de l'agent de console (ajoutez le suffixe « clients » à l'ID client s'il n'est pas déjà présent)
-
user_token = jeton d'accès utilisateur JWT
-
ds_host = Adresse IP ou nom d'hôte du système Linux de classification des données.
-
cm_host = Adresse IP ou nom d'hôte du système agent de la console.
-
cloud_provider = Lors de l'installation sur une instance cloud, saisissez « AWS », « Azure » ou « Gcp » selon le fournisseur de cloud.
-
proxy_host = IP ou nom d'hôte du serveur proxy si l'hôte est derrière un serveur proxy.
-
proxy_port = Port de connexion au serveur proxy (par défaut 80).
-
proxy_scheme = Schéma de connexion : https ou http (par défaut http).
-
proxy_user = Utilisateur authentifié pour se connecter au serveur proxy, si une authentification de base est requise. L'utilisateur doit être un utilisateur local - les utilisateurs de domaine ne sont pas pris en charge.
-
proxy_password = Mot de passe pour le nom d'utilisateur que vous avez spécifié.
-
ca_cert_dir = Chemin sur le système Linux de classification des données contenant des ensembles de certificats CA TLS supplémentaires. Requis uniquement si le proxy effectue une interception TLS.
-
Le programme d’installation de la classification des données installe les packages, enregistre l’installation et installe la classification des données. L'installation peut prendre 10 à 20 minutes.
S'il existe une connectivité via le port 8080 entre la machine hôte et l'instance de l'agent de la console, vous verrez la progression de l'installation dans l'onglet Classification des données de la console.