

Créer un plan de réplication dans NetApp Disaster Recovery
 Suggérer des modifications
Suggérer des modifications
Après avoir ajouté des ressources et des sites, créez un plan de réplication pour gérer la protection des données. La création du plan de réplication consiste à désigner les sites source et de destination, à sélectionner les groupes de ressources et à choisir la manière dont les applications doivent être restaurées et mises sous tension. Par exemple, vous pouvez regrouper des machines virtuelles (VM) associées à une application ou regrouper des applications qui présentent des niveaux similaires.
Lorsque vous créez un plan de réplication, vous pouvez également modifier les calendriers de conformité et de test, en effectuant des basculements de test sans impacter vos données de production.
Rôle requis de la console NetApp Le rôle de super administrateur, d'administrateur de reprise après sinistre, d'administrateur de basculement de reprise après sinistre ou d'administrateur d'application de reprise après sinistre est requis pour effectuer cette tâche. "En savoir plus sur les rôles et les autorisations des utilisateurs dans NetApp Disaster Recovery". "En savoir plus sur les rôles d'accès à la NetApp Console pour tous les services".
À propos des plans de réplication
Vous pouvez protéger plusieurs machines virtuelles sur plusieurs banques de données. NetApp Disaster Recovery crée des groupes de cohérence ONTAP pour tous les volumes ONTAP hébergeant des banques de données de machines virtuelles protégées.
Vous ne pouvez activer la protection que si le plan de réplication se trouve dans l'un des états suivants :
-
Prêt
-
Failback validé
-
Test de basculement validé
Instantanés du plan de réplication
La récupération après sinistre conserve le même nombre de snapshots sur les clusters source et de destination. Par défaut, le service exécute un processus de réconciliation de snapshots toutes les 24 heures pour garantir que le nombre de snapshots sur les clusters source et de destination est le même.
Les situations suivantes peuvent entraîner une différence dans le nombre de snapshots entre les clusters source et de destination :
-
Certaines situations peuvent amener les opérations ONTAP en dehors de la reprise après sinistre à ajouter ou supprimer des snapshots du volume :
-
S'il manque des instantanés sur le site source, les instantanés correspondants sur le site de destination peuvent être supprimés, en fonction de la stratégie SnapMirror par défaut pour la relation.
-
S'il manque des instantanés sur le site de destination, le service peut supprimer les instantanés correspondants sur le site source lors du prochain processus de rapprochement d'instantanés planifié, en fonction de la stratégie SnapMirror par défaut pour la relation.
-
-
Une réduction du nombre de rétentions d'instantanés du plan de réplication peut amener le service à supprimer les instantanés les plus anciens sur les sites source et de destination pour respecter le nombre de rétention nouvellement réduit.
Dans ces cas, Disaster Recovery supprime les anciens snapshots des clusters source et de destination lors de la prochaine vérification de cohérence. Ou, l'administrateur peut effectuer un nettoyage instantané immédiat en sélectionnant Actions*![]() icône sur le plan de réplication et en sélectionnant *Nettoyer les snapshots.
icône sur le plan de réplication et en sélectionnant *Nettoyer les snapshots.
La reprise après sinistre effectue des vérifications de symétrie des instantanés toutes les 24 heures.
Avant de commencer
-
Avant de créer une relation SnapMirror , configurez le cluster et le peering SVM en dehors de Disaster Recovery.
-
Si vous configurez des mappages réseau au niveau de vCenter, la reprise après sinistre reconnaît ces mappages lors de la création du plan de réplication. Si vous modifiez ou ajoutez le mappage réseau au niveau de vCenter après la création du plan de réplication, la reprise après sinistre reconnaît ces mappages lorsque vous modifiez manuellement le plan de réplication.
-
Avec Google Cloud, vous ne pouvez ajouter qu'un seul volume ou datastore à un plan de réplication.

|
Organisez vos machines virtuelles ou clusters Kubernetes avant de déployer NetApp Disaster Recovery afin de minimiser la prolifération. Placez les ressources nécessitant une protection sur un sous-ensemble de banques de données et placez les ressources qui ne seront pas protégées sur un autre sous-ensemble de banques de données. Pour organiser les groupes de ressources avant de créer le plan de réplication, consultez "Créer un groupe de ressources". |
Créer le plan de réplication
Un assistant vous guide à travers ces étapes :
-
Sélectionnez les serveurs vCenter.
-
Sélectionnez les ressources (VMs, datastore, espaces de noms) que vous souhaitez répliquer et attribuez des groupes de ressources.
-
Cartographiez la manière dont les ressources de l'environnement source sont mappées vers la destination.
-
Définissez la fréquence d’exécution du plan, exécutez un script hébergé par l’invité, définissez l’ordre de démarrage et sélectionnez l’objectif du point de récupération.
-
Revoyez le plan.
Lorsque vous créez le plan, suivez ces directives :
-
Utilisez les mêmes paramètres d'authentification pour toutes les machines virtuelles ou tous les clusters Kubernetes du plan.
-
Utilisez le même script pour toutes les machines virtuelles ou tous les clusters Kubernetes du plan.
-
Utilisez le même sous-réseau, le même DNS et la même passerelle pour toutes les machines virtuelles ou tous les clusters Kubernetes du plan.
Sélectionner les serveurs vCenter
Tout d’abord, vous sélectionnez le vCenter source, puis sélectionnez le vCenter de destination.
-
Dans la navigation de gauche de la NetApp Console , sélectionnez Protection > Reprise après sinistre.
-
Dans le menu NetApp Disaster Recovery , sélectionnez Plans de réplication.
-
Dans le menu déroulant, choisissez le type de ressource pour lequel vous souhaitez créer un plan de réplication : Kubernetes ou vCenter.
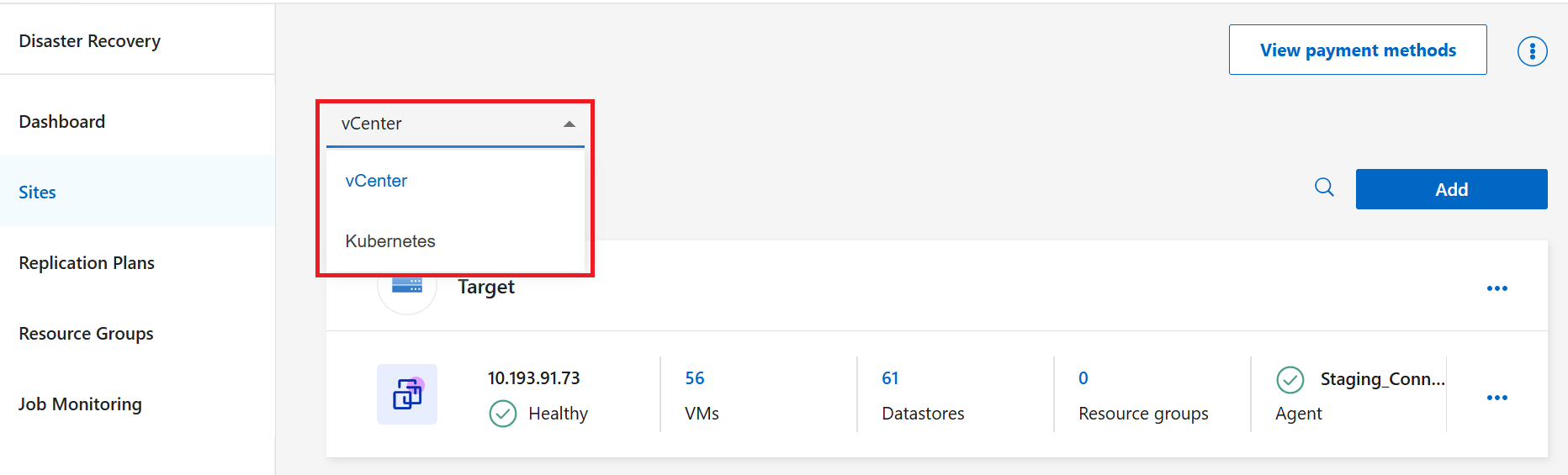
-
Sélectionnez Ajouter.
-
Saisissez un nom pour le plan de réplication.
-
Pour Source, sélectionnez le vCenter ou le cluster Kubernetes à désigner comme source.
-
Sous Source vCenter, sélectionnez le vCenter où se trouvent les données dans le menu déroulant. Sous Cible, sélectionnez le vCenter ou le cluster Kubernetes à utiliser comme cluster de destination pour la reprise après sinistre.
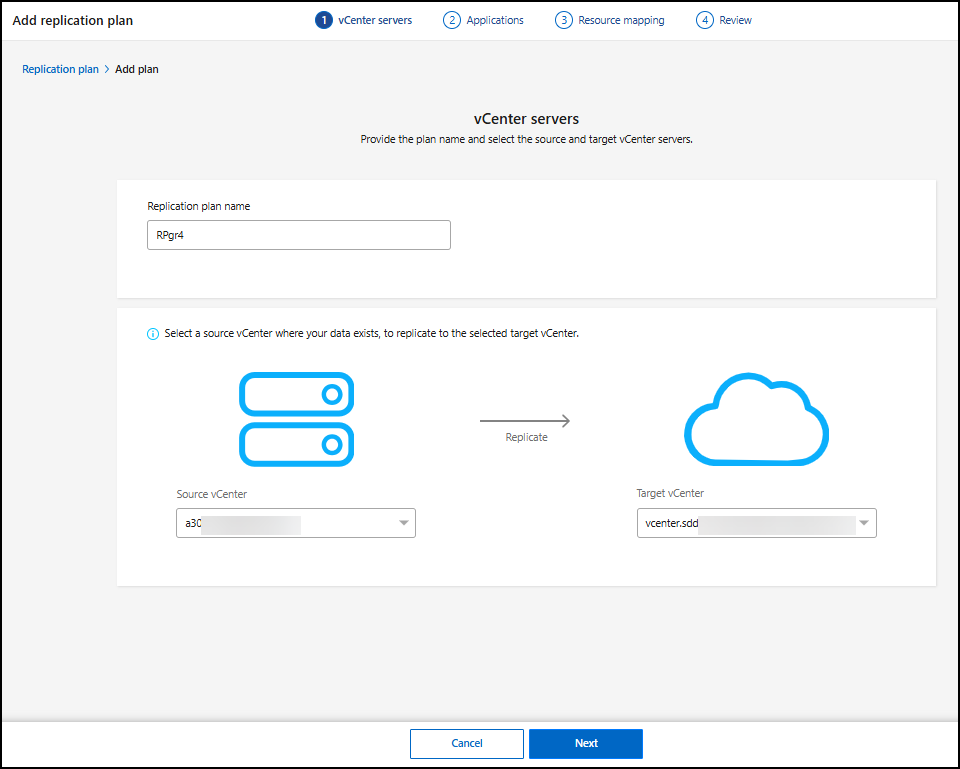
-
Sélectionnez Suivant.
Sélectionnez les applications à répliquer et attribuez des groupes de ressources
L'étape suivante consiste à regrouper les machines virtuelles, les banques de données ou les clusters Kubernetes nécessaires en groupes de ressources fonctionnels. Les groupes de ressources permettent de protéger un ensemble de ressources, comme un cluster Kubernetes ou une machine virtuelle, à l'aide d'un instantané commun.
Lorsque vous créez des groupes de ressources, tenez compte des points suivants :
-
Avant d'ajouter des ressources à des groupes de ressources, effectuez d'abord une découverte manuelle ou planifiée. Cela garantit que les ressources sont découvertes et répertoriées dans le groupe de ressources.
-
Assurez-vous qu'au moins une machine virtuelle est présente dans la banque de données. Si aucune machine virtuelle n'est présente dans la banque de données, la banque de données ne sera pas détectée.
-
Un seul magasin de données ne doit pas héberger de machines virtuelles protégées par plusieurs plans de réplication.
-
N’hébergez pas de ressources protégées et non protégées sur le même datastore. Si des ressources protégées et non protégées sont hébergées sur le même datastore, vous risquez de rencontrer les problèmes suivants :
-
La capacité utilisée de ce volume peut être prise en compte dans le calcul de la licence, car NetApp Disaster Recovery utilise SnapMirror, ce qui signifie que le système réplique des volumes ONTAP entiers. Dans ce cas, l’espace de volume consommé par les ressources protégées et non protégées serait inclus dans ce calcul.
-
Si le groupe de ressources et ses ressources associées doivent être basculés vers le site de reprise après sinistre, les ressources non protégées n'existeront plus sur le site source à la suite du processus de basculement, ce qui entraînera l'échec des ressources non protégées sur le site source. De plus, NetApp Disaster Recovery ne démarrera pas ces ressources non protégées sur le site de basculement.
-
|
|
Créez un ensemble de mappages dédié et distinct pour vos tests de basculement afin d'empêcher que les ressources soient connectées aux réseaux de production en utilisant les mêmes adresses IP. |
-
Si vous avez des groupes de ressources existants, sélectionnez Resource groups, choisissez le groupe de ressources puis Next.
Si vous n'avez pas de groupes de ressources existants ou si vous devez ajouter des ressources à un groupe, sélectionnez Machines virtuelles ou Banques de données.
-
Sélectionnez les machines virtuelles ou les banques de données que vous souhaitez ajouter au plan de réplication dans la liste générée automatiquement. Pour les machines virtuelles, vous pouvez filtrer par banque de données. Lorsque vous sélectionnez une banque de données ou une machine virtuelle, elle est automatiquement ajoutée à un groupe de ressources.
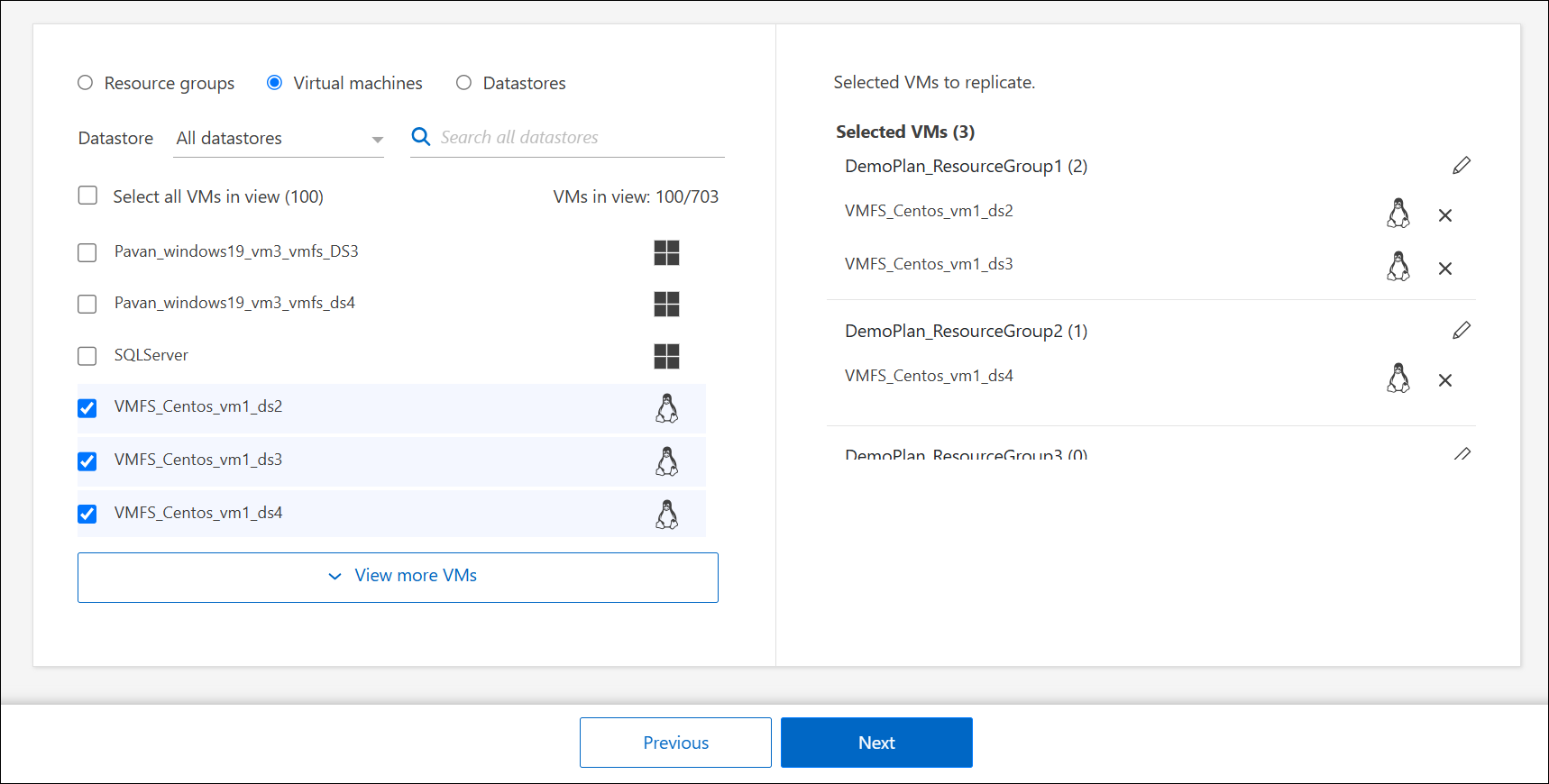
-
Sur la moitié droite de la page, examinez les machines virtuelles ou les datastores sélectionnés.
-
Pour supprimer une VM ou une banque de données, survolez le nom de la source de données, puis sélectionnez X.
-
Pour organiser les ressources en plusieurs groupes de ressources, sélectionnez Cliquez pour ajouter un autre groupe de ressources. Après avoir ajouté le groupe de ressources, vous pouvez glisser-déposer des ressources entre les groupes. Sélectionnez l'icône en forme de crayon* pour modifier le nom du groupe de ressources.
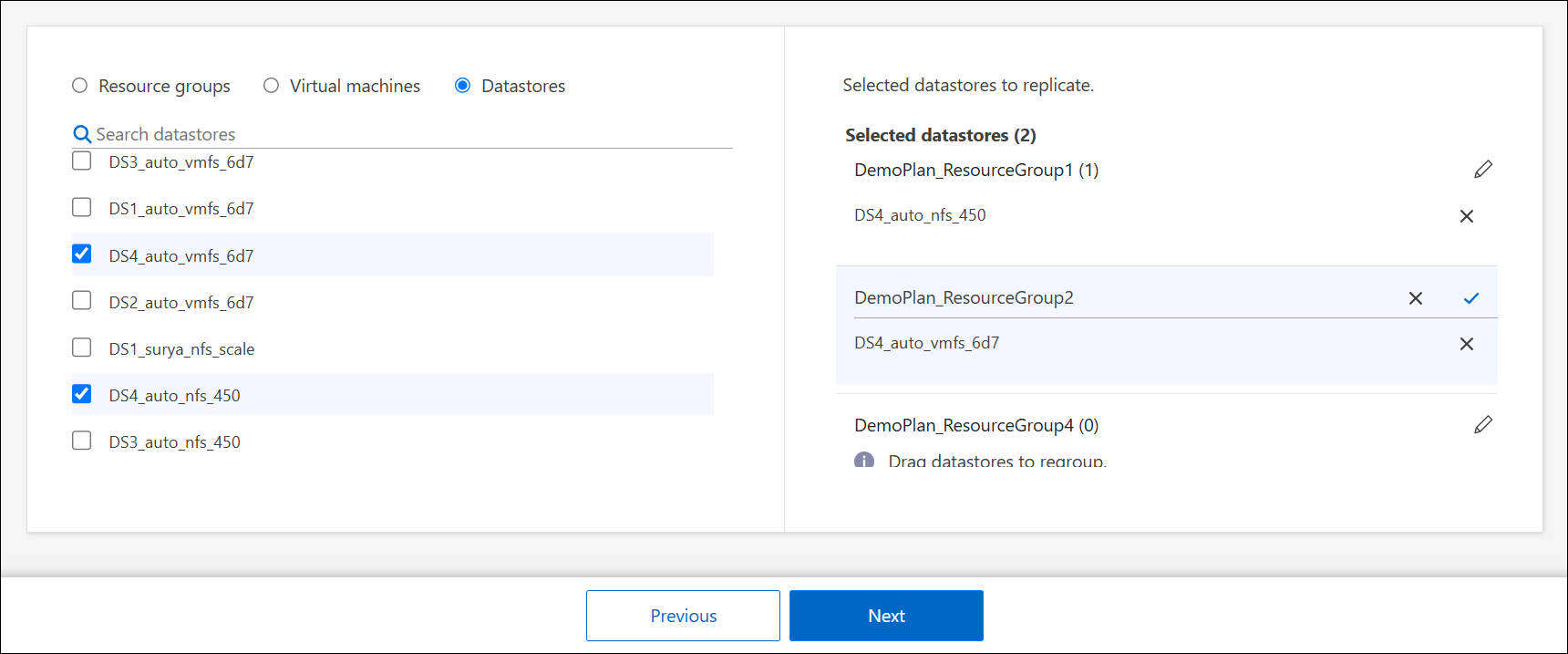
-
-
Sélectionnez Suivant.
Lors de la création d'un plan de réplication pour les clusters Kubernetes, les espaces de noms Kubernetes d'un groupe de ressources doivent appartenir au même cluster ONTAP.
-
Si vous avez déjà des groupes de ressources, sélectionnez-les dans la liste.
Si vous n'avez pas de groupes de ressources existants ou si vous devez ajouter des ressources à un groupe, sélectionnez + Créer un nouveau groupe de ressources. Suivez les instructions pour "ajouter des espaces de noms à un groupe de ressources".
Lors de la dénomination d'un groupe de ressources, seuls les caractères minuscules et les chiffres sont autorisés.
-
Dans la colonne alternative, examinez les groupes de ressources sélectionnés.
-
Sélectionnez Suivant.
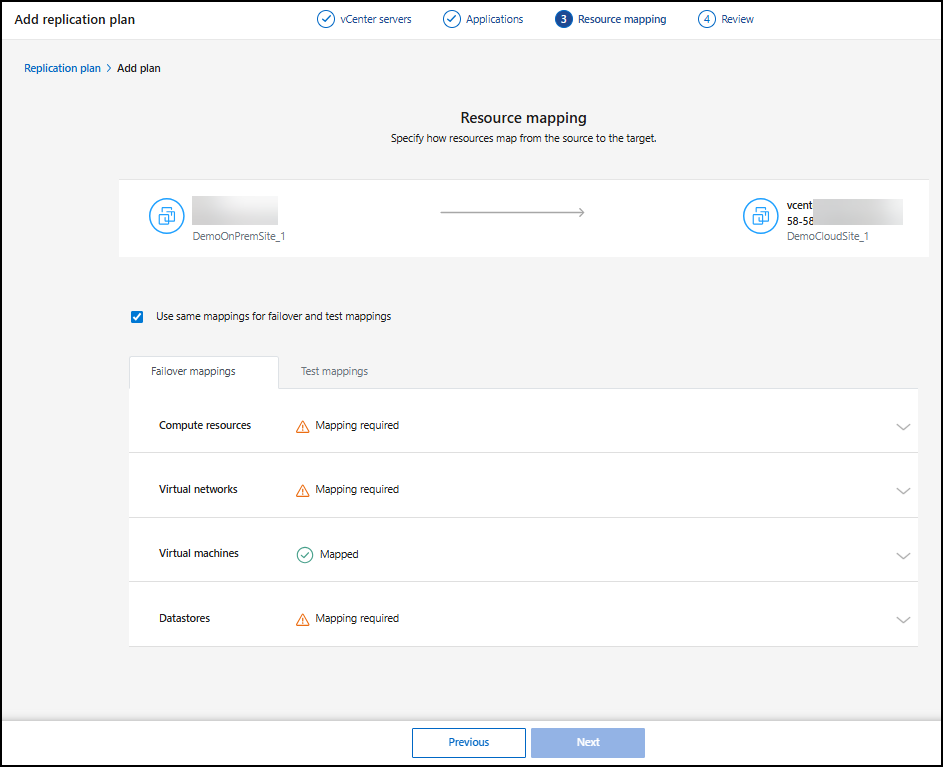
Mapper les ressources sources vers la cible
À l’étape Mappage des ressources, spécifiez comment les ressources de l’environnement source doivent être mappées à la cible. Lorsque vous créez un plan de réplication, vous pouvez définir un délai et un ordre de démarrage pour chaque machine virtuelle du plan. Cela vous permet de définir une séquence de démarrage des machines virtuelles.
Si vous prévoyez d'effectuer des tests de basculement dans le cadre de votre plan de reprise après sinistre, vous devez fournir un ensemble de mappages de basculement de test pour garantir que les machines virtuelles démarrées pendant le test de basculement n'interfèrent pas avec les machines virtuelles de production. Vous pouvez y parvenir soit en fournissant des machines virtuelles de test avec des adresses IP différentes, soit en mappant les cartes réseau virtuelles des machines virtuelles de test à un réseau différent, isolé de la production mais doté de la même configuration IP (appelé bulle ou réseau de test).
Si vous souhaitez créer une relation SnapMirror dans ce service, le cluster et son peering SVM doivent déjà avoir été configurés en dehors de NetApp Disaster Recovery.
-
Sur la page de mappage des ressources, cochez la case pour utiliser les mêmes mappages pour les opérations de basculement et de test.
-
Dans l'onglet Mappages de basculement, sélectionnez la flèche vers le bas à droite de chaque ressource et mappez les ressources dans chaque section :
-
Ressources de calcul
-
Réseaux virtuels
-
Machines virtuelles
-
Magasins de données
-
-
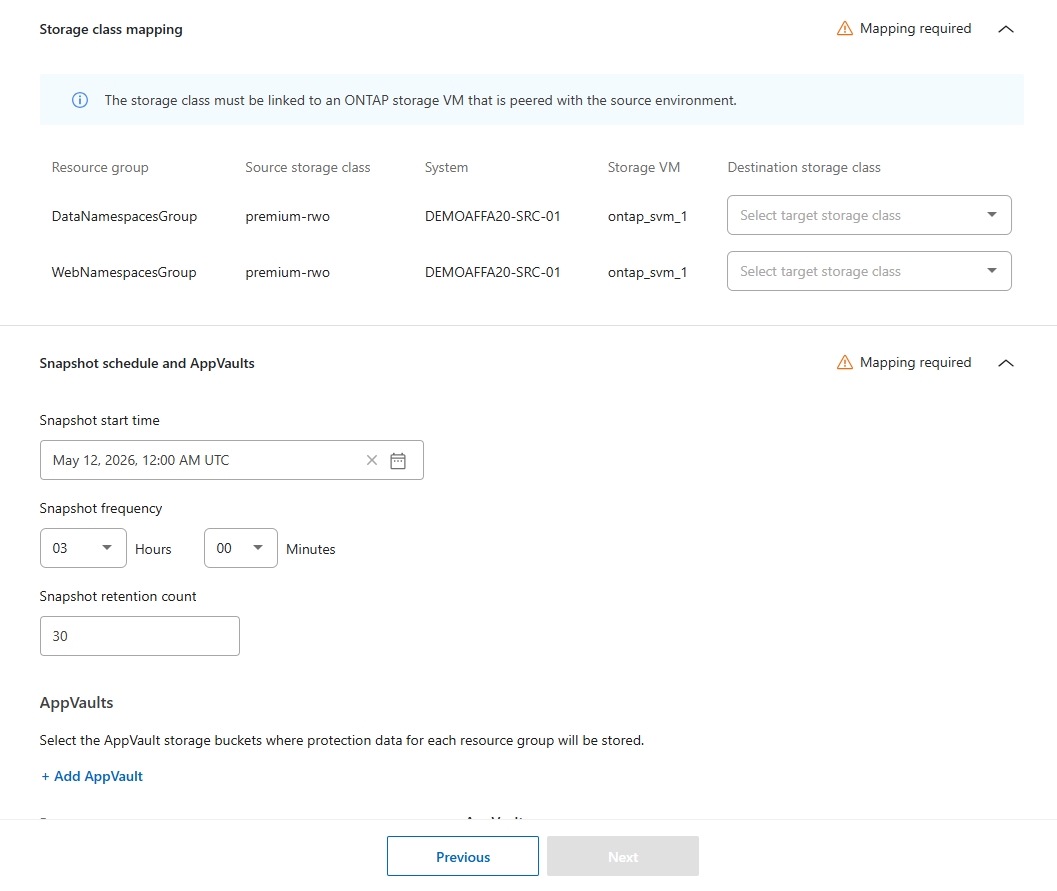
Choisissez les correspondances d'espaces de noms pour chaque espace de noms dans chaque groupe de ressources. Par défaut, NetApp Disaster Recovery sélectionne la cible identique à la source. Vous pouvez choisir un espace de noms différent dans le cluster de destination.
-
Définissez le mappage de classe de stockage pour chaque groupe de ressources. La classe de stockage doit être liée à une machine virtuelle de stockage ONTAP appairée avec l'environnement source. La classe de stockage par défaut du cluster est utilisée si vous n'en désignez pas.
Exécutez la commande CLI kubectl get pvc -n <namespace>sur l'espace de noms pour afficher la classe de stockage. -
Définissez la planification des instantanés :
Choisissez la date et l'heure de début des instantanés et de leur conservation (date et heure du calendrier), la fréquence des instantanés et de leur conservation (à quelle fréquence les instantanés sont déclenchés) et le nombre d'instantanés conservés (nombre d'instantanés enregistrés).
Lors de la configuration de la fréquence des instantanés, la valeur minimale autorisée est de cinq minutes.
-
Sélectionnez Ajouter AppVault pour créer le AppVault où les données de protection seront enregistrées.
-
Saisissez un Nom et sélectionnez l'Agent de console auquel AppVault doit être connecté.
-
Sélectionnez le fournisseur de cloud pour héberger le AppVault.
-
En fonction du fournisseur sélectionné, NetApp Disaster Recovery renseigne les abonnements cloud déjà configurés. Choisissez l’abonnement, le groupe de ressources et le compte de stockage pour le fournisseur de cloud.
-
Sélectionnez Ajouter.
-
-
Sélectionnez Suivant.
-
Examinez les mappages de basculement, puis sélectionnez Ajouter pour créer le plan de réplication.
Après avoir sélectionné Ajouter, vous pouvez surveiller les différents travaux dans Job monitoring.

|
Pour Kubernetes, il s'agit de la dernière étape de la création d'une réplication. Pour vCenters, continuez à Section des ressources de calcul. |
Section des ressources de calcul
La section Ressources de calcul définit où les machines virtuelles seront restaurées après un basculement. Mappez le centre de données et le cluster vCenter source vers un centre de données et un cluster cibles.
En option, les machines virtuelles peuvent être redémarrées sur un hôte vCenter ESXi spécifique. Si VMWare DRS est activé, vous pouvez déplacer automatiquement la machine virtuelle vers un autre hôte si nécessaire pour respecter la politique DR configurée.
En option, vous pouvez placer toutes les machines virtuelles de ce plan de réplication dans un dossier unique avec vCenter. Cela fournit un moyen simple d’organiser rapidement les machines virtuelles basculées dans vCenter.
Sélectionnez la flèche vers le bas à côté de Ressources de calcul.
-
Centres de données source et cible
-
Groupe cible
-
Hôte cible (facultatif) : après avoir sélectionné le cluster, vous pouvez définir ces informations.
-
Dossier (facultatif)
|
|
Si un vCenter dispose d'un planificateur de ressources distribuées (DRS) configuré pour gérer plusieurs hôtes dans un cluster, vous n'avez pas besoin de sélectionner un hôte. Si vous sélectionnez un hôte, NetApp Disaster Recovery placera toutes les machines virtuelles sur l'hôte sélectionné. * Dossier de machine virtuelle cible (facultatif) : créez un nouveau dossier racine pour stocker les machines virtuelles sélectionnées. |
Réseaux virtuels
Les machines virtuelles utilisent des cartes réseau virtuelles connectées à des réseaux virtuels. Dans le processus de basculement, le service connecte ces cartes réseau virtuelles à des réseaux virtuels définis dans l'environnement VMware de destination. Pour chaque réseau virtuel source utilisé par les machines virtuelles du groupe de ressources, le service requiert une attribution de réseau virtuel de destination.
|
|
Cette section est uniquement requise pour vCenters. Vous n'avez pas besoin de la remplir pour Kubernetes. |
|
|
Vous pouvez affecter plusieurs réseaux virtuels sources au même réseau virtuel cible. Cela pourrait cependant créer des conflits de configuration du réseau IP. Vous pouvez mapper plusieurs réseaux sources à un seul réseau cible pour garantir que tous les réseaux sources ont la même configuration. |
Dans l’onglet Mappages de basculement, sélectionnez la flèche vers le bas à côté de Réseaux virtuels. Sélectionnez le LAN virtuel source et le LAN virtuel cible.
Sélectionnez le mappage réseau vers le LAN virtuel approprié. Les réseaux locaux virtuels doivent déjà être provisionnés, sélectionnez donc le réseau local virtuel approprié pour mapper la machine virtuelle.
Machines virtuelles
Vous pouvez configurer chaque machine virtuelle du groupe de ressources protégé par le plan de réplication en fonction de l'environnement virtuel vCenter de destination en définissant l'une des options suivantes :
-
Le nombre de CPU virtuels
-
La quantité de DRAM virtuelle
-
La configuration de l'adresse IP
-
La possibilité d'exécuter des scripts shell du système d'exploitation invité dans le cadre du processus de basculement
-
La possibilité de modifier les noms des machines virtuelles ayant échoué en utilisant un préfixe et un suffixe uniques
-
La possibilité de définir l'ordre de redémarrage lors du basculement de la machine virtuelle
Dans l’onglet Mappages de basculement, sélectionnez la flèche vers le bas à côté de Machines virtuelles.
La valeur par défaut pour les machines virtuelles est mappée. Le mappage par défaut utilise les mêmes paramètres que ceux utilisés par les machines virtuelles dans l'environnement de production (même adresse IP, même masque de sous-réseau et même passerelle).
Si vous apportez des modifications aux paramètres par défaut, vous devez modifier le champ IP cible sur « Différent de la source ».
|
|
Si vous modifiez les paramètres sur « Différent de la source », vous devez fournir les informations d’identification du système d’exploitation invité de la machine virtuelle. |
Cette section peut afficher des champs différents en fonction de votre sélection.
Vous pouvez augmenter ou diminuer le nombre de processeurs virtuels attribués à chaque machine virtuelle basculée. Cependant, chaque machine virtuelle nécessite au moins un processeur virtuel. Vous pouvez modifier le nombre de processeurs virtuels et de DRAM virtuelle attribués à chaque machine virtuelle. La raison la plus courante pour laquelle vous souhaiterez peut-être modifier les paramètres par défaut du processeur virtuel et de la DRAM virtuelle est si les nœuds du cluster vCenter cible ne disposent pas d'autant de ressources disponibles que le cluster vCenter source.
|
|
Activez les paramètres avancés pour ajouter les paramètres Scripts et cohérent au niveau des applications. |
Paramètres réseau NetApp Disaster Recovery prend en charge un large éventail d'options de configuration pour les réseaux de machines virtuelles. Il peut être nécessaire de les modifier si le site cible possède des réseaux virtuels utilisant des paramètres TCP/IP différents de ceux des réseaux virtuels de production du site source.
Au niveau le plus basique (et par défaut), les paramètres utilisent simplement les mêmes paramètres réseau TCP/IP pour chaque machine virtuelle sur le site de destination que ceux utilisés sur le site source. Cela nécessite que vous configuriez les mêmes paramètres TCP/IP sur les réseaux virtuels source et de destination.
Le service prend en charge les paramètres réseau de configuration IP statique ou Dynamic Host Configuration Protocol (DHCP) pour les machines virtuelles. DHCP fournit une méthode basée sur des normes permettant de configurer dynamiquement les paramètres TCP/IP d'un port réseau hôte. DHCP doit fournir, au minimum, une adresse TCP/IP et peut également fournir une adresse de passerelle par défaut (pour le routage vers une connexion Internet externe), un masque de sous-réseau et une adresse de serveur DNS. DHCP est couramment utilisé pour les périphériques informatiques des utilisateurs finaux tels que les ordinateurs de bureau, les ordinateurs portables et les connexions de téléphones portables des employés, mais il peut également être utilisé pour tout périphérique informatique réseau tel que les serveurs.
-
Option Utiliser les mêmes paramètres de masque de sous-réseau, DNS et de passerelle : Étant donné que ces paramètres sont généralement les mêmes pour toutes les machines virtuelles connectées aux mêmes réseaux virtuels, il peut être plus simple de les configurer une seule fois et de laisser Disaster Recovery utiliser les paramètres pour toutes les machines virtuelles du groupe de ressources protégé par le plan de réplication. Si certaines machines virtuelles utilisent des paramètres différents, vous devez décocher cette case et fournir ces paramètres pour chaque machine virtuelle.
-
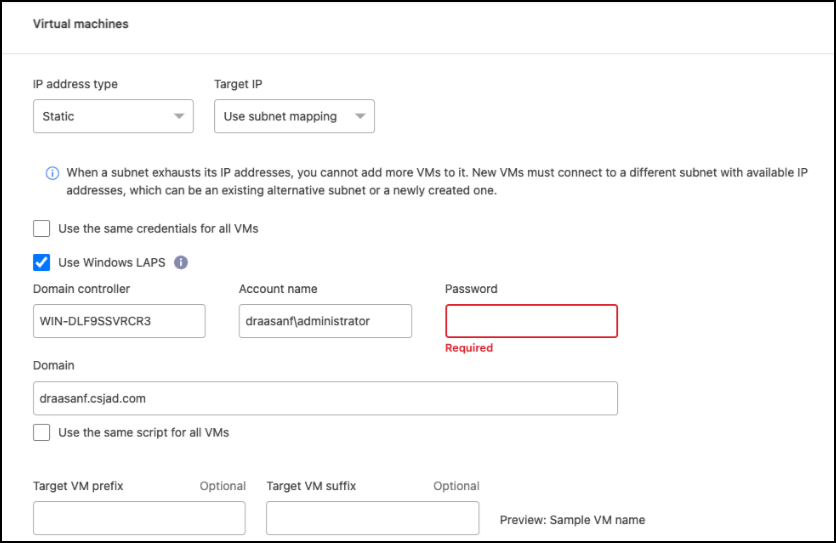
Type d'adresse IP : reconfigurez la configuration des machines virtuelles pour qu'elle corresponde aux exigences du réseau virtuel cible. NetApp Disaster Recovery propose deux options : DHCP ou IP statique. Pour les adresses IP statiques, configurez le masque de sous-réseau, la passerelle et les serveurs DNS. Saisissez également les informations d’identification des machines virtuelles.
-
DHCP : sélectionnez ce paramètre si vous souhaitez que vos machines virtuelles obtiennent des informations de configuration réseau à partir d'un serveur DHCP. Si vous choisissez cette option, vous fournissez uniquement les informations d’identification de la machine virtuelle.
-
IP statique : sélectionnez ce paramètre si vous souhaitez spécifier manuellement les informations de configuration IP. Vous pouvez sélectionner l'une des options suivantes : identique à la source, différent de la source ou mappage de sous-réseau. Si vous choisissez la même chose que la source, vous n'avez pas besoin de saisir d'informations d'identification. D'autre part, si vous choisissez d'utiliser des informations différentes de la source, vous pouvez fournir les informations d'identification, l'adresse IP de la machine virtuelle, le masque de sous-réseau, le DNS et les informations de passerelle. Les informations d’identification du système d’exploitation invité de la machine virtuelle doivent être fournies soit au niveau global, soit au niveau de chaque machine virtuelle.
Cela peut être très utile lors de la récupération de grands environnements vers des clusters cibles plus petits ou pour effectuer des tests de reprise après sinistre sans avoir à provisionner une infrastructure VMware physique individuelle.
-
-
Scripts : Vous pouvez inclure des scripts personnalisés hébergés par le système d’exploitation invité au format .sh, .bat ou .ps1 en tant que post-processus. Grâce aux scripts personnalisés, la reprise après sinistre peut exécuter votre script après un basculement, un retour en arrière et une migration de processus. Par exemple, vous pouvez utiliser un script personnalisé pour reprendre toutes les transactions de la base de données une fois le basculement terminé. Ce service peut exécuter des scripts au sein de machines virtuelles fonctionnant sous Microsoft Windows ou toute variante Linux prise en charge avec des paramètres de ligne de commande. Vous pouvez attribuer un script à des machines virtuelles individuelles ou à toutes les machines virtuelles du plan de réplication.
Pour permettre l'exécution de scripts avec le système d'exploitation invité de la machine virtuelle, les conditions suivantes doivent être remplies :
-
VMware Tools doit être installé sur la machine virtuelle.
-
Des informations d'identification utilisateur appropriées doivent être fournies avec des privilèges de système d'exploitation invité adéquats pour exécuter le script.
-
Vous pouvez éventuellement inclure une valeur de délai d'expiration en secondes pour le script.
VM exécutant Microsoft Windows : peuvent exécuter des scripts Windows batch (.bat) ou PowerShell (ps1). Les scripts Windows peuvent utiliser des arguments de ligne de commande. Formatez chaque argument dans le
arg_name$valueformat, oùarg_nameest le nom de l'argument et$valueest la valeur de l'argument et un point-virgule sépare chaqueargument$valuepaire.
VM exécutant Linux : peuvent exécuter n'importe quel script shell (.sh) pris en charge par la version de Linux utilisée par la VM. Les scripts Linux peuvent utiliser des arguments de ligne de commande. Fournissez des arguments dans une liste de valeurs séparées par des points-virgules. Les arguments nommés ne sont pas pris en charge. Ajoutez chaque argument à la
Arg[x]liste d'arguments et référencez chaque valeur à l'aide d'un pointeur dans leArg[x]tableau, par exemple,value1;value2;value3. -
-
Rétrograder la version matérielle de la VM et l'enregistrer : Sélectionnez cette option si la version de l'hôte ESX de destination est antérieure à celle de la source afin qu'elles correspondent lors de l'enregistrement.
-
Conserver la hiérarchie des dossiers d'origine : Par défaut, la reprise après sinistre conserve la hiérarchie de l'inventaire des machines virtuelles (structure des dossiers) en cas de basculement. Si le répertoire cible de récupération ne possède pas l'arborescence de dossiers d'origine, la fonction de récupération après sinistre la crée.
Décochez cette case pour ignorer l'arborescence des dossiers d'origine.
-
Préfixe et suffixe de la machine virtuelle cible : sous les détails des machines virtuelles, vous pouvez éventuellement ajouter un préfixe et un suffixe à chaque nom de machine virtuelle basculée. Cela peut être utile pour différencier les machines virtuelles basculées des machines virtuelles de production exécutées sur le même cluster vCenter. Par exemple, vous pouvez ajouter un préfixe « DR- » et un suffixe « -failover » au nom de la machine virtuelle. Certaines personnes ajoutent un deuxième vCenter de production pour héberger temporairement des machines virtuelles sur un site différent en cas de sinistre. L'ajout d'un préfixe ou d'un suffixe peut vous aider à identifier rapidement les machines virtuelles ayant échoué. Vous pouvez également utiliser le préfixe ou le suffixe dans les scripts personnalisés.
Vous pouvez utiliser la méthode alternative de définition du dossier de la machine virtuelle cible dans la section Ressources de calcul.
-
Processeur et Mémoire (Go) : Dans les détails de la machine virtuelle, vous pouvez éventuellement redimensionner le processeur et la mémoire de la VM.
Vous pouvez configurer la DRAM en gigaoctets (Gio) ou en mégaoctets (Mio). Bien que chaque machine virtuelle nécessite au moins un Mio de RAM, la quantité réelle doit garantir que le système d'exploitation invité de la machine virtuelle et toutes les applications en cours d'exécution peuvent fonctionner efficacement. -
Ordre de démarrage : vous pouvez modifier l’ordre de démarrage après un basculement pour toutes les machines virtuelles sélectionnées dans les groupes de ressources. Par défaut, toutes les machines virtuelles démarrent ensemble en parallèle ; toutefois, vous pouvez apporter des modifications à ce stade. Cela est utile pour garantir que toutes vos machines virtuelles de priorité 1 sont en cours d'exécution avant le démarrage des machines virtuelles de priorité suivantes.
La reprise après sinistre démarre en parallèle toutes les machines virtuelles ayant le même numéro d'ordre de démarrage.
-
Démarrage séquentiel : attribuez à chaque machine virtuelle un numéro unique pour démarrer dans l'ordre attribué, par exemple, 1, 2, 3, 4, 5.
-
Démarrage simultané : attribuez le même numéro à toutes les machines virtuelles pour les démarrer en même temps, par exemple, 1,1,1,1,2,2,3,4,4.
-
-
Délai de démarrage : ajustez le délai en minutes de l'action de démarrage, indiquant la durée pendant laquelle la machine virtuelle attendra avant de démarrer le processus de mise sous tension. Entrez une valeur comprise entre 0 et 10 minutes.
-
Cohérent au niveau des applications : Indiquez s'il faut créer des copies d'instantané cohérentes au niveau des applications. Le service mettra l'application en veille, puis prendra un instantané pour obtenir un état cohérent de l'application. Cette fonctionnalité est prise en charge avec Oracle exécuté sous Windows et Linux et SQL Server exécuté sous Windows. Voir plus de détails ci-dessous.
Vous devez activer le bouton Paramètres avancés pour cette option. Si vous activez la cohérence au niveau des applications, vous devez fournir des identifiants sous la forme d'un nom d'utilisateur et d'un mot de passe.
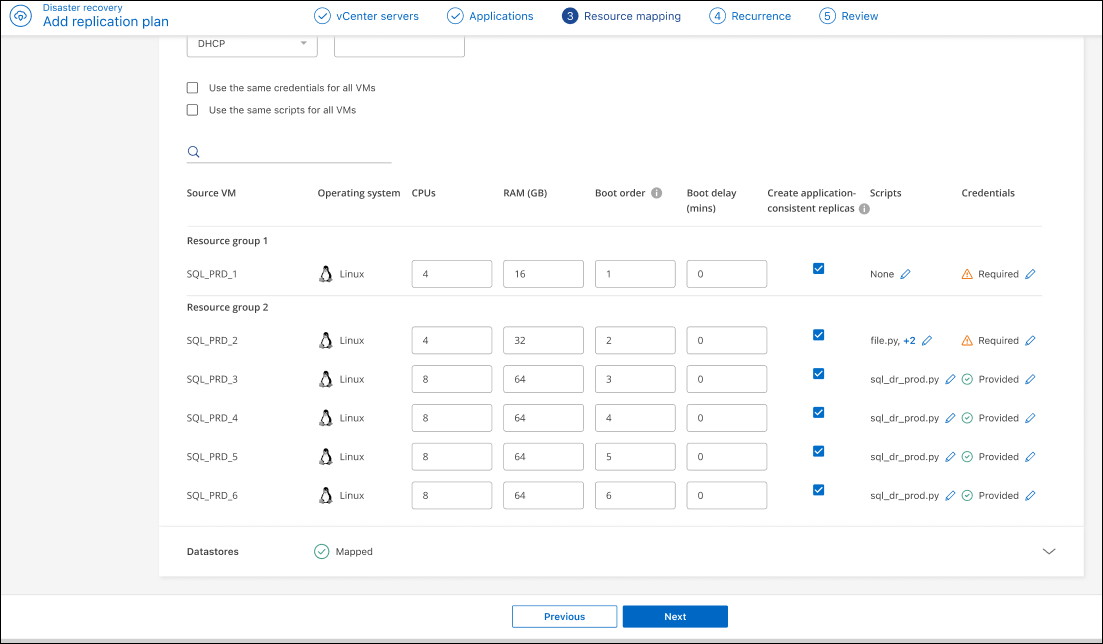
Créer des répliques cohérentes avec les applications
De nombreuses machines virtuelles hébergent des serveurs de bases de données tels qu'Oracle ou Microsoft SQL Server. Ces serveurs de base de données nécessitent des instantanés cohérents avec les applications pour garantir que la base de données est dans un état cohérent lorsque l'instantané est pris.
Les instantanés cohérents avec les applications garantissent que la base de données est dans un état cohérent lorsque l'instantané est pris. Ceci est important car cela garantit que la base de données peut être restaurée à un état cohérent après une opération de basculement ou de restauration.
Les données gérées par le serveur de base de données peuvent être hébergées sur le même magasin de données que la machine virtuelle hébergeant le serveur de base de données, ou elles peuvent être hébergées sur un magasin de données différent. Le tableau suivant présente les configurations prises en charge pour les snapshots cohérents avec les applications dans la reprise après sinistre :
| Emplacement des données | Soutenu | Remarques |
|---|---|---|
Dans le même datastore vCenter que la machine virtuelle |
Oui |
Étant donné que le serveur de base de données et la base de données résident tous deux sur le même magasin de données, le serveur et les données seront synchronisés lors du basculement. |
Dans une banque de données vCenter différente de la machine virtuelle |
Non |
La récupération après sinistre ne peut pas identifier quand les données d’un serveur de base de données se trouvent sur une autre banque de données vCenter. Le service ne peut pas répliquer les données, mais peut répliquer la machine virtuelle du serveur de base de données. Bien que les données de la base de données ne puissent pas être répliquées, le service garantit que le serveur de base de données exécute toutes les étapes nécessaires pour garantir que la base de données est mise au repos au moment de la sauvegarde de la machine virtuelle. |
Au sein d'une source de données externe |
Non |
Si les données résident sur un LUN monté sur invité ou sur un partage NFS, Disaster Recovery ne peut pas répliquer les données, mais peut répliquer la machine virtuelle du serveur de base de données. Bien que les données de la base de données ne puissent pas être répliquées, le service garantit que le serveur de base de données exécute toutes les étapes nécessaires pour garantir que la base de données est mise au repos au moment de la sauvegarde de la machine virtuelle. |
Lors d'une sauvegarde planifiée, Disaster Recovery met en veille le serveur de base de données, puis prend un instantané de la machine virtuelle hébergeant le serveur de base de données. Cela garantit que la base de données est dans un état cohérent lorsque l'instantané est pris.
-
Pour les machines virtuelles Windows, le service utilise le service Microsoft Volume Shadow Copy Service (VSS) pour se coordonner avec l’un ou l’autre serveur de base de données.
-
Pour les machines virtuelles Linux, le service utilise un ensemble de scripts pour placer le serveur Oracle en mode de sauvegarde.
Pour activer les répliques cohérentes avec les applications des machines virtuelles et de leurs banques de données d'hébergement, cochez la case en regard de Créer des répliques cohérentes avec les applications pour chaque machine virtuelle et fournissez les informations d'identification de connexion invité avec les privilèges appropriés.
Section Datastores
Les banques de données VMware sont hébergées sur des volumes ONTAP FlexVol ou des LUN ONTAP iSCSI ou FC à l'aide de VMware VMFS. Utilisez la section Banques de données pour définir le cluster ONTAP cible, la machine virtuelle de stockage (SVM) et le volume ou LUN pour répliquer les données sur disque vers la destination.
Sélectionnez la flèche vers le bas à côté de Datastores. En fonction de la sélection des machines virtuelles, les mappages de banques de données sont automatiquement sélectionnés.
Cette section peut être activée ou désactivée en fonction de votre sélection.
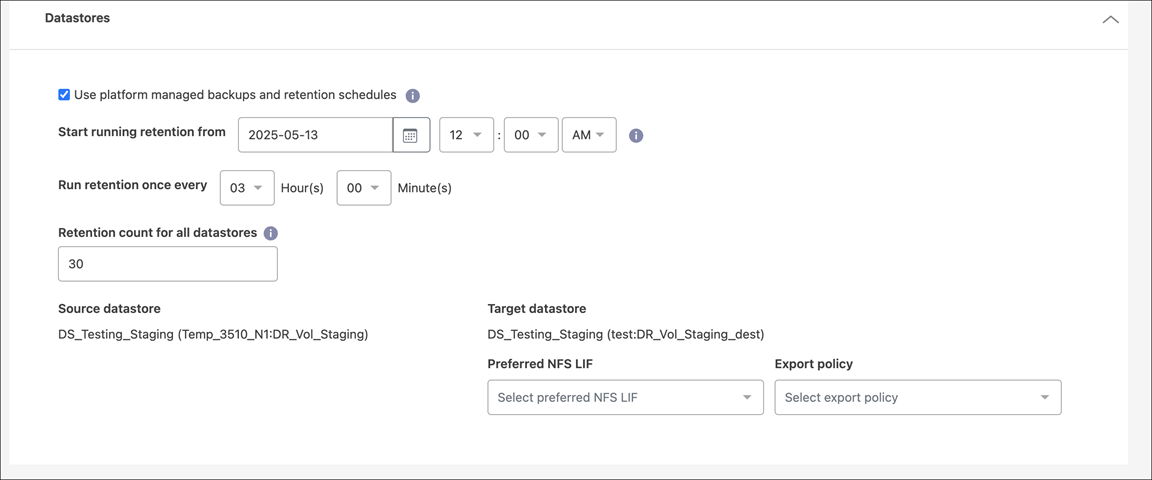
-
Utiliser les sauvegardes gérées par la plateforme et les planifications de conservation : si vous utilisez une solution de gestion des snapshots externe, cochez cette case. NetApp Disaster Recovery prend en charge l’utilisation de solutions de gestion de snapshots externes telles que le planificateur de politiques ONTAP SnapMirror natif ou des intégrations tierces. Si chaque banque de données (volume) du plan de réplication dispose déjà d'une relation SnapMirror gérée ailleurs, vous pouvez utiliser ces snapshots comme points de récupération dans NetApp Disaster Recovery.
Lorsque cette option est sélectionnée, NetApp Disaster Recovery ne configure pas de planification de sauvegarde. Cependant, vous devez toujours configurer un calendrier de conservation, car des instantanés peuvent toujours être pris pour des opérations de test, de basculement et de restauration automatique.
Une fois cette configuration effectuée, le service ne prend aucun instantané planifié régulièrement, mais s'appuie plutôt sur l'entité externe pour prendre et mettre à jour ces instantanés.
-
Heure de début des sauvegardes et de la conservation : Saisissez la date et l’heure auxquelles vous souhaitez que les sauvegardes et la conservation commencent à s’exécuter.
-
Fréquence des sauvegardes et de leur conservation : Indiquez l’intervalle de temps en heures et minutes. Par exemple, si vous indiquez 1 heure, le service prendra un snapshot chaque heure.
-
Retention count for all datastores : Saisissez le nombre de snapshots que vous souhaitez conserver.
Le nombre d'instantanés conservés ainsi que le taux de modification des données entre chaque instantané déterminent la quantité d'espace de stockage consommée sur la source et la destination. Plus vous conservez d'instantanés, plus l'espace de stockage consommé est important. -
Magasins de données source et cible : si plusieurs relations SnapMirror (en éventail) existent, vous pouvez sélectionner la destination à utiliser. Si un volume possède déjà une relation SnapMirror établie, les banques de données source et cible correspondantes s'affichent. Si un volume ne possède pas de relation SnapMirror , vous pouvez en créer une maintenant en sélectionnant un cluster cible, en sélectionnant une SVM cible et en fournissant un nom de volume. Le service créera le volume et la relation SnapMirror .
Si vous souhaitez créer une relation SnapMirror dans ce service, le cluster et son peering SVM doivent déjà avoir été configurés en dehors de NetApp Disaster Recovery. -
Si les machines virtuelles proviennent du même volume et du même SVM, le service effectue un instantané ONTAP standard et met à jour les destinations secondaires.
-
Si les machines virtuelles proviennent de volumes différents et du même SVM, le service crée un instantané du groupe de cohérence en incluant tous les volumes et met à jour les destinations secondaires.
-
Si les machines virtuelles proviennent de volumes différents et de SVM différents, le service effectue une phase de démarrage du groupe de cohérence et un instantané de la phase de validation en incluant tous les volumes dans le même cluster ou dans un cluster différent et met à jour les destinations secondaires.
-
Pendant le basculement, vous pouvez sélectionner n’importe quel instantané. Si vous sélectionnez le dernier instantané, le service crée une sauvegarde à la demande, met à jour la destination et utilise cet instantané pour le basculement.
-
Ajouter des mappages de basculement de test
-
Pour définir des mappages différents pour l'environnement de test, décochez la case et sélectionnez l'onglet Mappages de test.
-
Parcourez chaque onglet comme précédemment, mais cette fois pour l’environnement de test.
Dans l’onglet Mappages de test, les mappages de machines virtuelles et de magasins de données sont désactivés.
Vous pourrez ensuite tester l'ensemble du plan. Vous configurez actuellement les mappages pour l’environnement de test.
Revoir le plan de réplication
Enfin, prenez quelques instants pour examiner le plan de réplication.
|
|
Vous pouvez ultérieurement désactiver ou supprimer le plan de réplication. |
-
Consultez les informations dans chaque onglet : Détails du plan, Mappage de basculement et Machines virtuelles.
-
Sélectionnez Ajouter un plan.
Le plan est ajouté à la liste des plans.
Modifier un plan de réplication
Vous pouvez modifier la planification d'un plan de réplication pour tester la conformité et vous assurer que les tests de basculement se terminent avec succès.
-
Impact sur le temps de conformité : Lorsqu'un plan de réplication est créé, le service crée un calendrier de conformité par défaut. Le temps de conformité par défaut est de 30 minutes. Pour modifier cette heure, vous pouvez utiliser la fonction Modifier la planification dans le plan de réplication.
-
Test d'impact du basculement : Vous pouvez tester un processus de basculement à la demande ou selon une planification. Cela vous permet de tester le basculement des machines virtuelles vers une destination spécifiée dans un plan de réplication.
Un basculement de test crée un volume FlexClone , monte la banque de données et déplace la charge de travail sur cette banque de données. Une opération de basculement de test n'a pas d'impact sur les charges de travail de production, la relation SnapMirror utilisée sur le site de test et les charges de travail protégées qui doivent continuer à fonctionner normalement.
En fonction du calendrier, le test de basculement s'exécute et garantit que les charges de travail se déplacent vers la destination spécifiée par le plan de réplication.
-
Dans le menu NetApp Disaster Recovery , sélectionnez Plans de réplication.
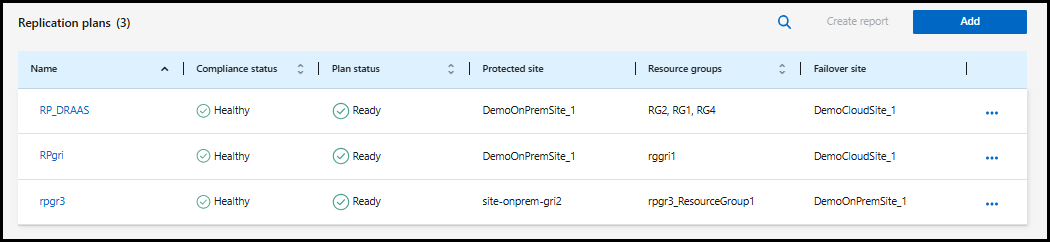
-
Sélectionnez les Actions*
 icône et sélectionnez *Modifier les horaires.
icône et sélectionnez *Modifier les horaires. -
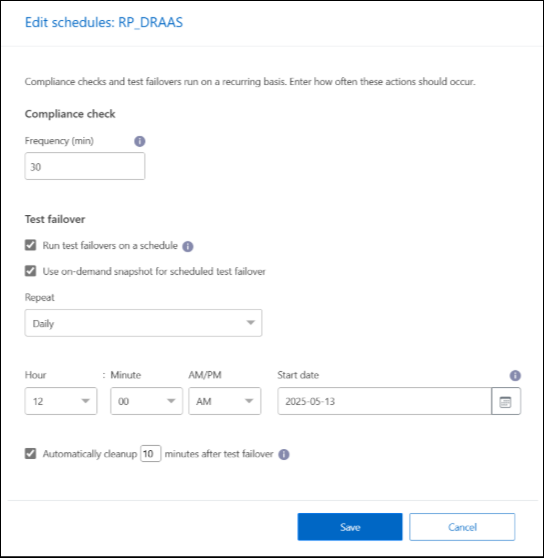
Saisissez la fréquence en minutes à laquelle vous souhaitez que NetApp Disaster Recovery vérifie la conformité des tests.
-
Pour vérifier que vos tests de basculement sont sains, cochez Exécuter les basculements selon un calendrier mensuel.
-
Sélectionnez le jour du mois et l’heure à laquelle vous souhaitez que ces tests soient exécutés.
-
Saisissez la date au format aaaa-mm-jj à laquelle vous souhaitez que le test commence.
-
-
Utiliser un instantané à la demande pour le basculement de test planifié : pour prendre un nouvel instantané avant de lancer le basculement de test automatisé, cochez cette case.
-
Pour nettoyer l'environnement de test une fois le test de basculement terminé, cochez Nettoyer automatiquement après le basculement du test et entrez le nombre de minutes que vous souhaitez attendre avant le début du nettoyage.
Ce processus annule l'enregistrement des machines virtuelles temporaires de l'emplacement de test, supprime le volume FlexClone qui a été créé et démonte les banques de données temporaires. -
Sélectionnez Enregistrer.