

Partie 2 - Exploiter AWS Amazon FSx for NetApp ONTAP (FSx ONTAP) comme source de données pour la formation de modèles dans SageMaker
 Suggérer des modifications
Suggérer des modifications
Cet article est un didacticiel sur l’utilisation Amazon FSx for NetApp ONTAP (FSx ONTAP) pour la formation de modèles PyTorch dans SageMaker, en particulier pour un projet de classification de la qualité des pneus.
Introduction
Ce didacticiel propose un exemple pratique d'un projet de classification de vision par ordinateur, offrant une expérience pratique dans la création de modèles ML qui utilisent FSx ONTAP comme source de données dans l'environnement SageMaker. Le projet se concentre sur l’utilisation de PyTorch, un framework d’apprentissage en profondeur, pour classer la qualité des pneus en fonction des images de pneus. Il met l’accent sur le développement de modèles d’apprentissage automatique utilisant FSx ONTAP comme source de données dans Amazon SageMaker.
Qu'est-ce que FSx ONTAP
Amazon FSx ONTAP est en effet une solution de stockage entièrement gérée proposée par AWS. Il exploite le système de fichiers ONTAP de NetApp pour fournir un stockage fiable et hautes performances. Avec la prise en charge de protocoles tels que NFS, SMB et iSCSI, il permet un accès transparent à partir de différentes instances de calcul et conteneurs. Le service est conçu pour offrir des performances exceptionnelles, garantissant des opérations de données rapides et efficaces. Il offre également une haute disponibilité et une durabilité élevée, garantissant que vos données restent accessibles et protégées. De plus, la capacité de stockage d' Amazon FSx ONTAP est évolutive, ce qui vous permet de l'ajuster facilement en fonction de vos besoins.
Condition préalable
Environnement réseau
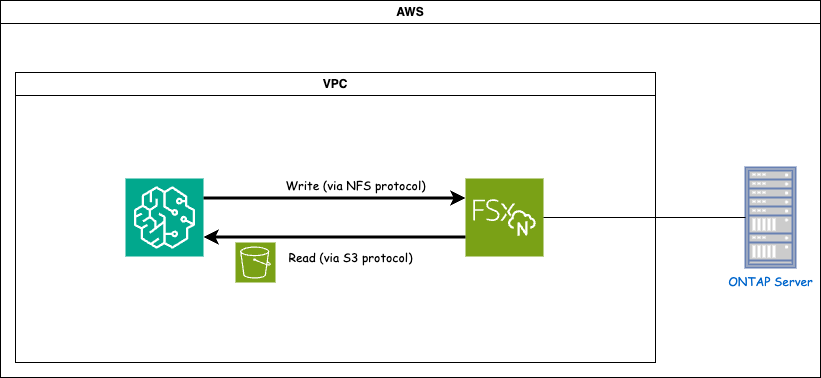
FSx ONTAP (Amazon FSx ONTAP) est un service de stockage AWS. Il comprend un système de fichiers exécuté sur le système NetApp ONTAP et une machine virtuelle système gérée par AWS (SVM) qui s'y connecte. Dans le diagramme fourni, le serveur NetApp ONTAP géré par AWS est situé en dehors du VPC. Le SVM sert d'intermédiaire entre SageMaker et le système NetApp ONTAP , recevant les demandes d'opération de SageMaker et les transmettant au stockage sous-jacent. Pour accéder à FSx ONTAP, SageMaker doit être placé dans le même VPC que le déploiement FSx ONTAP . Cette configuration assure la communication et l'accès aux données entre SageMaker et FSx ONTAP.
Accès aux données
Dans les scénarios réels, les scientifiques des données utilisent généralement les données existantes stockées dans FSx ONTAP pour créer leurs modèles d’apprentissage automatique. Cependant, à des fins de démonstration, étant donné que le système de fichiers FSx ONTAP est initialement vide après sa création, il est nécessaire de télécharger manuellement les données de formation. Cela peut être réalisé en montant FSx ONTAP en tant que volume sur SageMaker. Une fois le système de fichiers monté avec succès, vous pouvez télécharger votre ensemble de données vers l'emplacement monté, le rendant ainsi accessible pour la formation de vos modèles dans l'environnement SageMaker. Cette approche vous permet d’exploiter la capacité de stockage et les capacités de FSx ONTAP tout en travaillant avec SageMaker pour le développement et la formation de modèles.
Le processus de lecture des données implique la configuration de FSx ONTAP en tant que bucket S3 privé. Pour connaître les instructions de configuration détaillées, veuillez vous référer à"Partie 1 - Intégration Amazon FSx for NetApp ONTAP (FSx ONTAP) en tant que compartiment S3 privé dans AWS SageMaker"
Présentation de l'intégration
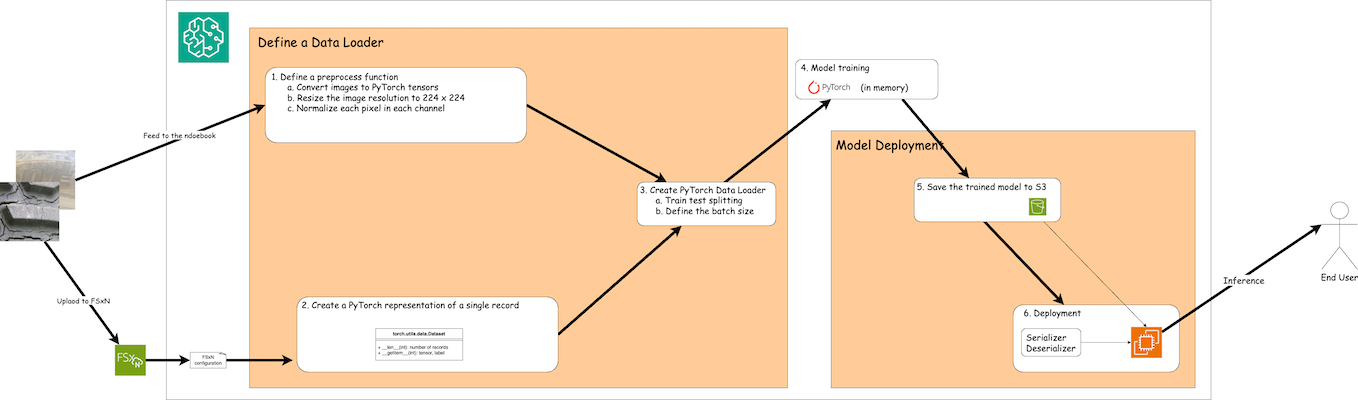
Le flux de travail d'utilisation des données de formation dans FSx ONTAP pour créer un modèle d'apprentissage en profondeur dans SageMaker peut être résumé en trois étapes principales : définition du chargeur de données, formation du modèle et déploiement. À un niveau élevé, ces étapes constituent la base d’un pipeline MLOps. Cependant, chaque étape implique plusieurs sous-étapes détaillées pour une mise en œuvre complète. Ces sous-étapes englobent diverses tâches telles que le prétraitement des données, le fractionnement des ensembles de données, la configuration du modèle, le réglage des hyperparamètres, l’évaluation du modèle et le déploiement du modèle. Ces étapes garantissent un processus complet et efficace pour la création et le déploiement de modèles d’apprentissage en profondeur à l’aide de données de formation de FSx ONTAP dans l’environnement SageMaker.
Intégration étape par étape
Loader de données
Afin de former un réseau d'apprentissage profond PyTorch avec des données, un chargeur de données est créé pour faciliter l'alimentation des données. Le chargeur de données définit non seulement la taille du lot, mais détermine également la procédure de lecture et de prétraitement de chaque enregistrement au sein du lot. En configurant le chargeur de données, nous pouvons gérer le traitement des données par lots, permettant ainsi la formation du réseau d'apprentissage en profondeur.
Le chargeur de données se compose de 3 parties.
Fonction de prétraitement
from torchvision import transforms
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])L'extrait de code ci-dessus illustre la définition des transformations de prétraitement d'image à l'aide du module torchvision.transforms. Dans ce tutoriel, l'objet de prétraitement est créé pour appliquer une série de transformations. Tout d’abord, la transformation ToTensor() convertit l’image en une représentation tensorielle. Par la suite, la transformation Resize224,224 redimensionne l'image à une taille fixe de 224x224 pixels. Enfin, la transformation Normalize() normalise les valeurs du tenseur en soustrayant la moyenne et en divisant par l'écart type le long de chaque canal. Les valeurs moyennes et d’écart type utilisées pour la normalisation sont couramment utilisées dans les modèles de réseaux neuronaux pré-entraînés. Dans l’ensemble, ce code prépare les données d’image pour un traitement ultérieur ou une entrée dans un modèle pré-entraîné en les convertissant en tenseur, en les redimensionnant et en normalisant les valeurs des pixels.
La classe de jeu de données PyTorch
import torch
from io import BytesIO
from PIL import Image
class FSxNImageDataset(torch.utils.data.Dataset):
def __init__(self, bucket, prefix='', preprocess=None):
self.image_keys = [
s3_obj.key
for s3_obj in list(bucket.objects.filter(Prefix=prefix).all())
]
self.preprocess = preprocess
def __len__(self):
return len(self.image_keys)
def __getitem__(self, index):
key = self.image_keys[index]
response = bucket.Object(key)
label = 1 if key[13:].startswith('defective') else 0
image_bytes = response.get()['Body'].read()
image = Image.open(BytesIO(image_bytes))
if image.mode == 'L':
image = image.convert('RGB')
if self.preprocess is not None:
image = self.preprocess(image)
return image, labelCette classe fournit des fonctionnalités permettant d'obtenir le nombre total d'enregistrements dans l'ensemble de données et définit la méthode de lecture des données pour chaque enregistrement. Dans la fonction getitem, le code utilise l'objet bucket S3 boto3 pour récupérer les données binaires de FSx ONTAP. Le style de code permettant d'accéder aux données de FSx ONTAP est similaire à la lecture des données d'Amazon S3. L'explication suivante approfondit le processus de création de l'objet S3 privé bucket.
FSx ONTAP comme référentiel S3 privé
seed = 77 # Random seed
bucket_name = '<Your ONTAP bucket name>' # The bucket name in ONTAP
aws_access_key_id = '<Your ONTAP bucket key id>' # Please get this credential from ONTAP
aws_secret_access_key = '<Your ONTAP bucket access key>' # Please get this credential from ONTAP
fsx_endpoint_ip = '<Your FSx ONTAP IP address>' # Please get this IP address from FSXNimport boto3
# Get session info
region_name = boto3.session.Session().region_name
# Initialize Fsxn S3 bucket object
# --- Start integrating SageMaker with FSXN ---
# This is the only code change we need to incorporate SageMaker with FSXN
s3_client: boto3.client = boto3.resource(
's3',
region_name=region_name,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
use_ssl=False,
endpoint_url=f'http://{fsx_endpoint_ip}',
config=boto3.session.Config(
signature_version='s3v4',
s3={'addressing_style': 'path'}
)
)
# s3_client = boto3.resource('s3')
bucket = s3_client.Bucket(bucket_name)
# --- End integrating SageMaker with FSXN ---Pour lire les données de FSx ONTAP dans SageMaker, un gestionnaire est créé qui pointe vers le stockage FSx ONTAP à l'aide du protocole S3. Cela permet à FSx ONTAP d'être traité comme un bucket S3 privé. La configuration du gestionnaire inclut la spécification de l'adresse IP du SVM FSx ONTAP , du nom du bucket et des informations d'identification nécessaires. Pour une explication complète sur l'obtention de ces éléments de configuration, veuillez vous référer au document à l'adresse"Partie 1 - Intégration Amazon FSx for NetApp ONTAP (FSx ONTAP) en tant que compartiment S3 privé dans AWS SageMaker" .
Dans l'exemple mentionné ci-dessus, l'objet bucket est utilisé pour instancier l'objet de jeu de données PyTorch. L'objet de jeu de données sera expliqué plus en détail dans la section suivante.
Le Loader de données PyTorch
from torch.utils.data import DataLoader
torch.manual_seed(seed)
# 1. Hyperparameters
batch_size = 64
# 2. Preparing for the dataset
dataset = FSxNImageDataset(bucket, 'dataset/tyre', preprocess=preprocess)
train, test = torch.utils.data.random_split(dataset, [1500, 356])
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)Dans l'exemple fourni, une taille de lot de 64 est spécifiée, indiquant que chaque lot contiendra 64 enregistrements. En combinant la classe PyTorch Dataset, la fonction de prétraitement et la taille du lot d'entraînement, nous obtenons le chargeur de données pour l'entraînement. Ce chargeur de données facilite le processus d’itération de l’ensemble de données par lots pendant la phase de formation.
Formation de modèle
from torch import nn
class TyreQualityClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,64,(3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(224-6)*(224-6),2)
)
def forward(self, x):
return self.model(x)import datetime
num_epochs = 2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TyreQualityClassifier()
fn_loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
model.to(device)
for epoch in range(num_epochs):
for idx, (X, y) in enumerate(data_loader):
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = fn_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Current Time: {current_time} - Epoch [{epoch+1}/{num_epochs}]- Batch [{idx + 1}] - Loss: {loss}", end='\r')Ce code implémente un processus de formation PyTorch standard. Il définit un modèle de réseau neuronal appelé TyreQualityClassifier utilisant des couches convolutives et une couche linéaire pour classer la qualité des pneus. La boucle de formation parcourt les lots de données, calcule la perte et met à jour les paramètres du modèle à l'aide de la rétropropagation et de l'optimisation. De plus, il imprime l'heure actuelle, l'époque, le lot et la perte à des fins de surveillance.
Déploiement du modèle
Déploiement
import io
import os
import tarfile
import sagemaker
# 1. Save the PyTorch model to memory
buffer_model = io.BytesIO()
traced_model = torch.jit.script(model)
torch.jit.save(traced_model, buffer_model)
# 2. Upload to AWS S3
sagemaker_session = sagemaker.Session()
bucket_name_default = sagemaker_session.default_bucket()
model_name = f'tyre_quality_classifier.pth'
# 2.1. Zip PyTorch model into tar.gz file
buffer_zip = io.BytesIO()
with tarfile.open(fileobj=buffer_zip, mode="w:gz") as tar:
# Add PyTorch pt file
file_name = os.path.basename(model_name)
file_name_with_extension = os.path.split(file_name)[-1]
tarinfo = tarfile.TarInfo(file_name_with_extension)
tarinfo.size = len(buffer_model.getbuffer())
buffer_model.seek(0)
tar.addfile(tarinfo, buffer_model)
# 2.2. Upload the tar.gz file to S3 bucket
buffer_zip.seek(0)
boto3.resource('s3') \
.Bucket(bucket_name_default) \
.Object(f'pytorch/{model_name}.tar.gz') \
.put(Body=buffer_zip.getvalue())Le code enregistre le modèle PyTorch sur Amazon S3 car SageMaker exige que le modèle soit stocké dans S3 pour le déploiement. En téléchargeant le modèle sur Amazon S3, il devient accessible à SageMaker, permettant le déploiement et l'inférence sur le modèle déployé.
import time
from sagemaker.pytorch import PyTorchModel
from sagemaker.predictor import Predictor
from sagemaker.serializers import IdentitySerializer
from sagemaker.deserializers import JSONDeserializer
class TyreQualitySerializer(IdentitySerializer):
CONTENT_TYPE = 'application/x-torch'
def serialize(self, data):
transformed_image = preprocess(data)
tensor_image = torch.Tensor(transformed_image)
serialized_data = io.BytesIO()
torch.save(tensor_image, serialized_data)
serialized_data.seek(0)
serialized_data = serialized_data.read()
return serialized_data
class TyreQualityPredictor(Predictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(
endpoint_name,
sagemaker_session=sagemaker_session,
serializer=TyreQualitySerializer(),
deserializer=JSONDeserializer(),
)
sagemaker_model = PyTorchModel(
model_data=f's3://{bucket_name_default}/pytorch/{model_name}.tar.gz',
role=sagemaker.get_execution_role(),
framework_version='2.0.1',
py_version='py310',
predictor_cls=TyreQualityPredictor,
entry_point='inference.py',
source_dir='code',
)
timestamp = int(time.time())
pytorch_endpoint_name = '{}-{}-{}'.format('tyre-quality-classifier', 'pt', timestamp)
sagemaker_predictor = sagemaker_model.deploy(
initial_instance_count=1,
instance_type='ml.p3.2xlarge',
endpoint_name=pytorch_endpoint_name
)Ce code facilite le déploiement d'un modèle PyTorch sur SageMaker. Il définit un sérialiseur personnalisé, TyreQualitySerializer, qui prétraite et sérialise les données d'entrée sous forme de tenseur PyTorch. La classe TyreQualityPredictor est un prédicteur personnalisé qui utilise le sérialiseur défini et un JSONDeserializer. Le code crée également un objet PyTorchModel pour spécifier l'emplacement S3 du modèle, le rôle IAM, la version du framework et le point d'entrée pour l'inférence. Le code génère un horodatage et construit un nom de point de terminaison basé sur le modèle et l'horodatage. Enfin, le modèle est déployé à l’aide de la méthode deploy, en spécifiant le nombre d’instances, le type d’instance et le nom du point de terminaison généré. Cela permet au modèle PyTorch d'être déployé et accessible pour l'inférence sur SageMaker.
Inférence
image_object = list(bucket.objects.filter('dataset/tyre'))[0].get()
image_bytes = image_object['Body'].read()
with Image.open(with Image.open(BytesIO(image_bytes)) as image:
predicted_classes = sagemaker_predictor.predict(image)
print(predicted_classes)Voici l’exemple d’utilisation du point de terminaison déployé pour effectuer l’inférence.