

TR-4570 : Solutions de stockage NetApp pour Apache Spark : architecture, cas d'utilisation et résultats de performance
 Suggérer des modifications
Suggérer des modifications
Rick Huang, Karthikeyan Nagalingam, NetApp
Ce document se concentre sur l’architecture Apache Spark, les cas d’utilisation des clients et le portefeuille de stockage NetApp liés à l’analyse du Big Data et à l’intelligence artificielle (IA). Il présente également divers résultats de tests utilisant des outils d'IA, d'apprentissage automatique (ML) et d'apprentissage profond (DL) standard de l'industrie par rapport à un système Hadoop typique afin que vous puissiez choisir la solution Spark appropriée. Pour commencer, vous avez besoin d’une architecture Spark, de composants appropriés et de deux modes de déploiement (cluster et client).
Ce document fournit également des cas d’utilisation client pour résoudre les problèmes de configuration et présente un aperçu du portefeuille de stockage NetApp pertinent pour l’analyse du Big Data et l’IA, le ML et le DL avec Spark. Nous terminons ensuite avec les résultats des tests dérivés des cas d’utilisation spécifiques à Spark et du portefeuille de solutions NetApp Spark.
Les défis des clients
Cette section se concentre sur les défis des clients en matière d'analyse de Big Data et d'IA/ML/DL dans les secteurs de croissance des données tels que la vente au détail, le marketing numérique, la banque, la fabrication discrète, la fabrication de processus, le gouvernement et les services professionnels.
Des performances imprévisibles
Les déploiements Hadoop traditionnels utilisent généralement du matériel standard. Pour améliorer les performances, vous devez ajuster le réseau, le système d’exploitation, le cluster Hadoop, les composants de l’écosystème tels que Spark et le matériel. Même si vous ajustez chaque couche, il peut être difficile d'atteindre les niveaux de performances souhaités, car Hadoop s'exécute sur du matériel standard qui n'a pas été conçu pour des performances élevées dans votre environnement.
Pannes de médias et de nœuds
Même dans des conditions normales, le matériel informatique de base est sujet à des pannes. Si un disque sur un nœud de données tombe en panne, le maître Hadoop considère par défaut que ce nœud est défectueux. Il copie ensuite des données spécifiques de ce nœud sur le réseau à partir de répliques vers un nœud sain. Ce processus ralentit les paquets réseau pour tous les travaux Hadoop. Le cluster doit ensuite recopier les données et supprimer les données sur-répliquées lorsque le nœud défectueux revient à un état sain.
Verrouillage du fournisseur Hadoop
Les distributeurs Hadoop ont leur propre distribution Hadoop avec leur propre versionnage, ce qui verrouille le client sur ces distributions. Cependant, de nombreux clients ont besoin d’une prise en charge des analyses en mémoire qui ne lie pas le client à des distributions Hadoop spécifiques. Ils ont besoin de la liberté de modifier les distributions tout en conservant leurs analyses avec eux.
Manque de support pour plus d'une langue
Les clients ont souvent besoin de la prise en charge de plusieurs langues en plus des programmes Java MapReduce pour exécuter leurs tâches. Des options telles que SQL et les scripts offrent plus de flexibilité pour obtenir des réponses, plus d'options pour organiser et récupérer des données, et des moyens plus rapides de déplacer des données dans un cadre d'analyse.
Difficulté d'utilisation
Depuis un certain temps, les gens se plaignent de la difficulté d’utilisation d’Hadoop. Même si Hadoop est devenu plus simple et plus puissant à chaque nouvelle version, cette critique a persisté. Hadoop exige que vous compreniez les modèles de programmation Java et MapReduce, un défi pour les administrateurs de bases de données et les personnes possédant des compétences de script traditionnelles.
Cadres et outils complexes
Les équipes d’IA des entreprises sont confrontées à de multiples défis. Même avec des connaissances spécialisées en science des données, les outils et les cadres pour différents écosystèmes de déploiement et applications peuvent ne pas être facilement transposables de l’un à l’autre. Une plateforme de science des données doit s'intégrer de manière transparente aux plateformes Big Data correspondantes construites sur Spark avec une facilité de déplacement des données, des modèles réutilisables, du code prêt à l'emploi et des outils qui prennent en charge les meilleures pratiques de prototypage, de validation, de versionnage, de partage, de réutilisation et de déploiement rapide des modèles en production.
Pourquoi choisir NetApp?
NetApp peut améliorer votre expérience Spark des manières suivantes :
-
L'accès direct NetApp NFS (illustré dans la figure ci-dessous) permet aux clients d'exécuter des tâches d'analyse de Big Data sur leurs données NFSv3 ou NFSv4 existantes ou nouvelles sans déplacer ni copier les données. Il empêche les copies multiples de données et élimine le besoin de synchroniser les données avec une source.
-
Stockage plus efficace et moins de réplication de serveur. Par exemple, la solution Hadoop NetApp E-Series nécessite deux répliques de données au lieu de trois, et la solution Hadoop FAS nécessite une source de données mais aucune réplication ni copie de données. Les solutions de stockage NetApp génèrent également moins de trafic de serveur à serveur.
-
Meilleur comportement des tâches et des clusters Hadoop en cas de panne de lecteur et de nœud.
-
Meilleures performances d’ingestion de données.
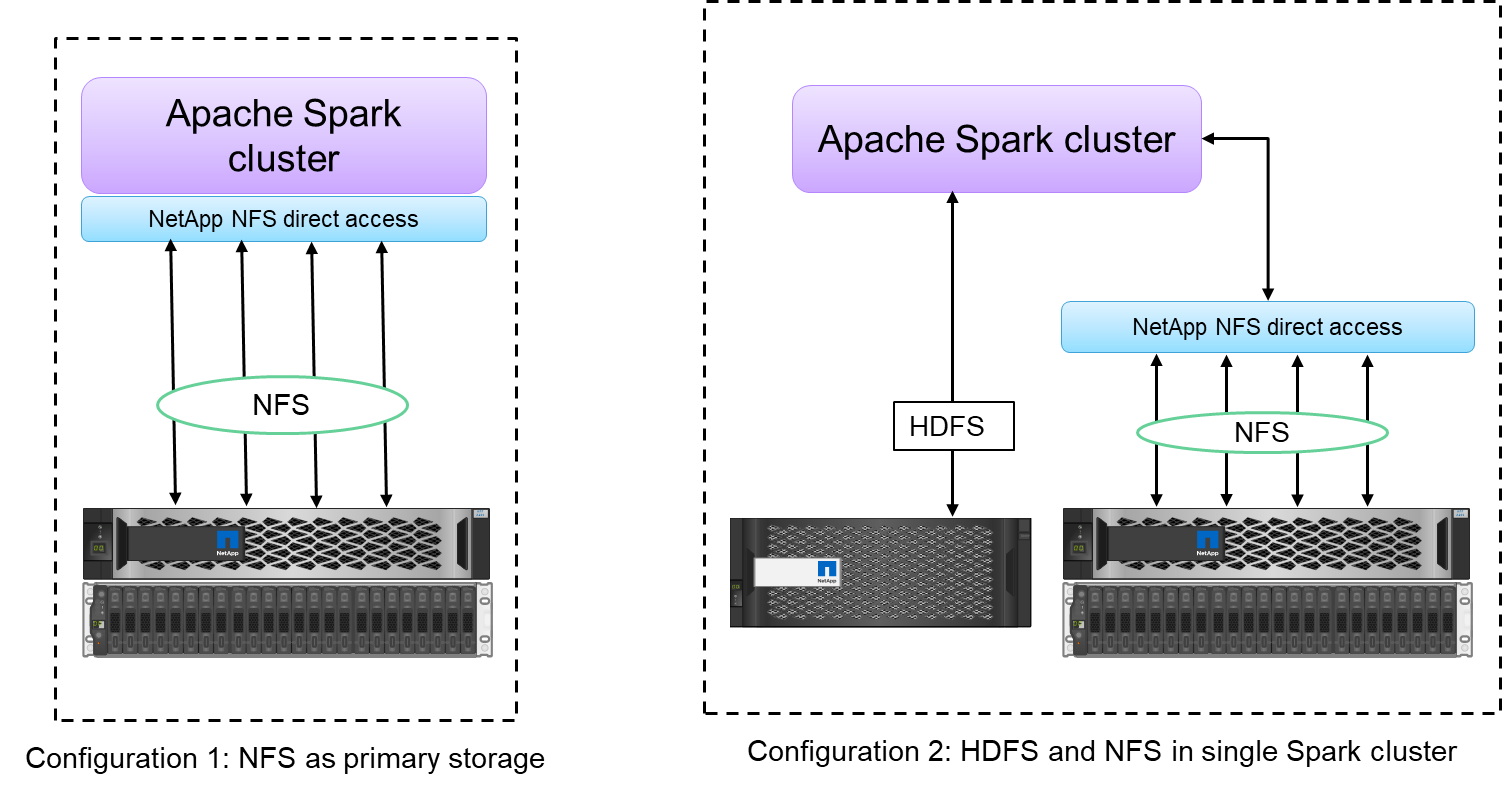
Par exemple, dans le secteur financier et de la santé, le déplacement de données d’un endroit à un autre doit répondre à des obligations légales, ce qui n’est pas une tâche facile. Dans ce scénario, l’accès direct NetApp NFS analyse les données financières et de santé à partir de leur emplacement d’origine. Un autre avantage clé est que l’utilisation de l’accès direct NetApp NFS simplifie la protection des données Hadoop en utilisant des commandes Hadoop natives et en activant les flux de travail de protection des données avec le riche portefeuille de gestion des données de NetApp.
L'accès direct NetApp NFS offre deux types d'options de déploiement pour les clusters Hadoop/Spark :
-
Par défaut, les clusters Hadoop ou Spark utilisent le système de fichiers distribué Hadoop (HDFS) pour le stockage des données et le système de fichiers par défaut. L'accès direct NetApp NFS peut remplacer le HDFS par défaut par le stockage NFS comme système de fichiers par défaut, permettant ainsi des analyses directes sur les données NFS.
-
Dans une autre option de déploiement, l’accès direct NetApp NFS prend en charge la configuration de NFS comme stockage supplémentaire avec HDFS dans un seul cluster Hadoop ou Spark. Dans ce cas, le client peut partager des données via des exportations NFS et y accéder à partir du même cluster avec les données HDFS.
Les principaux avantages de l’utilisation de l’accès direct NetApp NFS sont les suivants :
-
Analyse des données à partir de leur emplacement actuel, ce qui évite la tâche fastidieuse et coûteuse en performances consistant à déplacer les données d'analyse vers une infrastructure Hadoop telle que HDFS.
-
Réduction du nombre de répliques de trois à une.
-
Permettre aux utilisateurs de découpler le calcul et le stockage pour les faire évoluer indépendamment.
-
Assurer la protection des données d'entreprise en exploitant les riches capacités de gestion des données d' ONTAP.
-
Certification avec la plateforme de données Hortonworks.
-
Permettre des déploiements d’analyse de données hybrides.
-
Réduction du temps de sauvegarde en exploitant la capacité multithread dynamique.
Voir"TR-4657 : Solutions de données cloud hybrides NetApp - Spark et Hadoop basées sur des cas d'utilisation client" pour la sauvegarde des données Hadoop, la sauvegarde et la reprise après sinistre du cloud vers les locaux, permettant DevTest sur les données Hadoop existantes, la protection des données et la connectivité multicloud, et l'accélération des charges de travail d'analyse.
Les sections suivantes décrivent les capacités de stockage importantes pour les clients Spark.
hiérarchisation du stockage
Avec la hiérarchisation du stockage Hadoop, vous pouvez stocker des fichiers avec différents types de stockage conformément à une politique de stockage. Les types de stockage incluent hot , cold , warm , all_ssd , one_ssd , et lazy_persist .
Nous avons effectué la validation de la hiérarchisation du stockage Hadoop sur un contrôleur de stockage NetApp AFF et un contrôleur de stockage E-Series avec des disques SSD et SAS avec différentes politiques de stockage. Le cluster Spark avec AFF-A800 dispose de quatre nœuds de calcul, tandis que le cluster avec la série E en a huit. Il s’agit principalement de comparer les performances des disques SSD (Solid State Drives) par rapport aux disques durs (HDD).
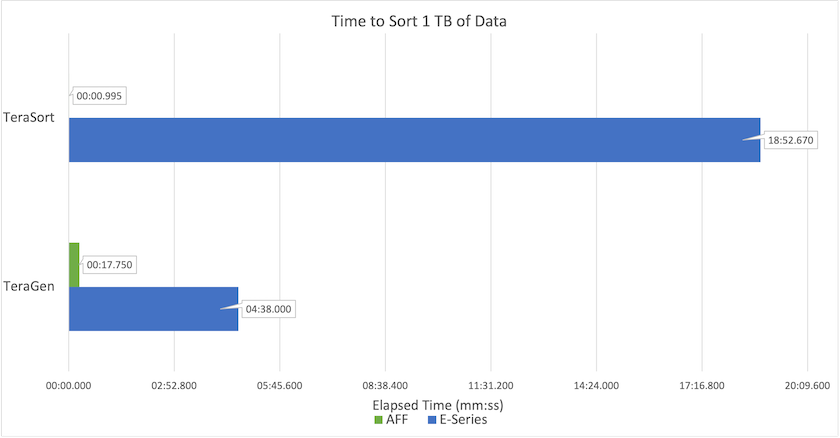
La figure suivante montre les performances des solutions NetApp pour un SSD Hadoop.
-
La configuration NL-SAS de base utilisait huit nœuds de calcul et 96 lecteurs NL-SAS. Cette configuration a généré 1 To de données en 4 minutes et 38 secondes. Voir "TR-3969 Solution NetApp E-Series pour Hadoop" pour plus de détails sur la configuration du cluster et du stockage.
-
Grâce à TeraGen, la configuration SSD a généré 1 To de données 15,66 fois plus rapidement que la configuration NL-SAS. De plus, la configuration SSD utilisait la moitié du nombre de nœuds de calcul et la moitié du nombre de lecteurs de disque (24 lecteurs SSD au total). En fonction du temps d’exécution du travail, il était presque deux fois plus rapide que la configuration NL-SAS.
-
Grâce à TeraSort, la configuration SSD a trié 1 To de données 1 138,36 fois plus rapidement que la configuration NL-SAS. De plus, la configuration SSD utilisait la moitié du nombre de nœuds de calcul et la moitié du nombre de lecteurs de disque (24 lecteurs SSD au total). Par conséquent, par lecteur, il était environ trois fois plus rapide que la configuration NL-SAS.
-
Le point à retenir est que la transition des disques rotatifs vers le tout flash améliore les performances. Le nombre de nœuds de calcul n’était pas le goulot d’étranglement. Avec le stockage entièrement flash de NetApp, les performances d'exécution évoluent bien.
-
Avec NFS, les données étaient fonctionnellement équivalentes à un regroupement complet, ce qui peut réduire le nombre de nœuds de calcul en fonction de votre charge de travail. Les utilisateurs du cluster Apache Spark n’ont pas besoin de rééquilibrer manuellement les données lors du changement du nombre de nœuds de calcul.
Mise à l'échelle des performances - Évolution horizontale
Lorsque vous avez besoin de plus de puissance de calcul à partir d’un cluster Hadoop dans une solution AFF , vous pouvez ajouter des nœuds de données avec un nombre approprié de contrôleurs de stockage. NetApp recommande de commencer avec quatre nœuds de données par baie de contrôleurs de stockage et d'augmenter le nombre à huit nœuds de données par contrôleur de stockage, en fonction des caractéristiques de la charge de travail.
AFF et FAS sont parfaits pour les analyses sur place. En fonction des exigences de calcul, vous pouvez ajouter des gestionnaires de nœuds et des opérations non perturbatrices vous permettent d'ajouter un contrôleur de stockage à la demande sans temps d'arrêt. Nous proposons des fonctionnalités riches avec AFF et FAS, telles que la prise en charge des médias NVME, l'efficacité garantie, la réduction des données, la qualité de service, l'analyse prédictive, la hiérarchisation du cloud, la réplication, le déploiement du cloud et la sécurité. Pour aider les clients à répondre à leurs besoins, NetApp propose des fonctionnalités telles que l'analyse du système de fichiers, les quotas et l'équilibrage de charge sur site sans frais de licence supplémentaires. NetApp offre de meilleures performances en termes de nombre de tâches simultanées, de latence plus faible, d'opérations plus simples et de débit en gigaoctets par seconde plus élevé que nos concurrents. De plus, NetApp Cloud Volumes ONTAP fonctionne sur les trois principaux fournisseurs de cloud.
Mise à l'échelle des performances - Mise à l'échelle
Les fonctionnalités de mise à l'échelle vous permettent d'ajouter des lecteurs de disque aux systèmes AFF, FAS et E-Series lorsque vous avez besoin d'une capacité de stockage supplémentaire. Avec Cloud Volumes ONTAP, la mise à l'échelle du stockage au niveau Po est une combinaison de deux facteurs : la hiérarchisation des données rarement utilisées vers le stockage d'objets à partir du stockage en blocs et l'empilement de licences Cloud Volumes ONTAP sans calcul supplémentaire.
Protocoles multiples
Les systèmes NetApp prennent en charge la plupart des protocoles pour les déploiements Hadoop, notamment SAS, iSCSI, FCP, InfiniBand et NFS.
Solutions opérationnelles et supportées
Les solutions Hadoop décrites dans ce document sont prises en charge par NetApp. Ces solutions sont également certifiées auprès des principaux distributeurs Hadoop. Pour plus d'informations, consultez le "Hortonworks" site et Cloudera "certification" et "partenaire" sites.