

Technologie des solutions
 Suggérer des modifications
Suggérer des modifications
Apache Spark est un framework de programmation populaire pour l'écriture d'applications Hadoop qui fonctionne directement avec le système de fichiers distribué Hadoop (HDFS). Spark est prêt pour la production, prend en charge le traitement des données en streaming et est plus rapide que MapReduce. Spark dispose d'une mise en cache de données en mémoire configurable pour une itération efficace, et le shell Spark est interactif pour l'apprentissage et l'exploration des données. Avec Spark, vous pouvez créer des applications en Python, Scala ou Java. Les applications Spark se composent d’un ou plusieurs travaux comportant une ou plusieurs tâches.
Chaque application Spark dispose d'un pilote Spark. En mode YARN-Client, le pilote s'exécute localement sur le client. En mode YARN-Cluster, le pilote s'exécute dans le cluster sur le maître d'application. En mode cluster, l'application continue de s'exécuter même si le client se déconnecte.
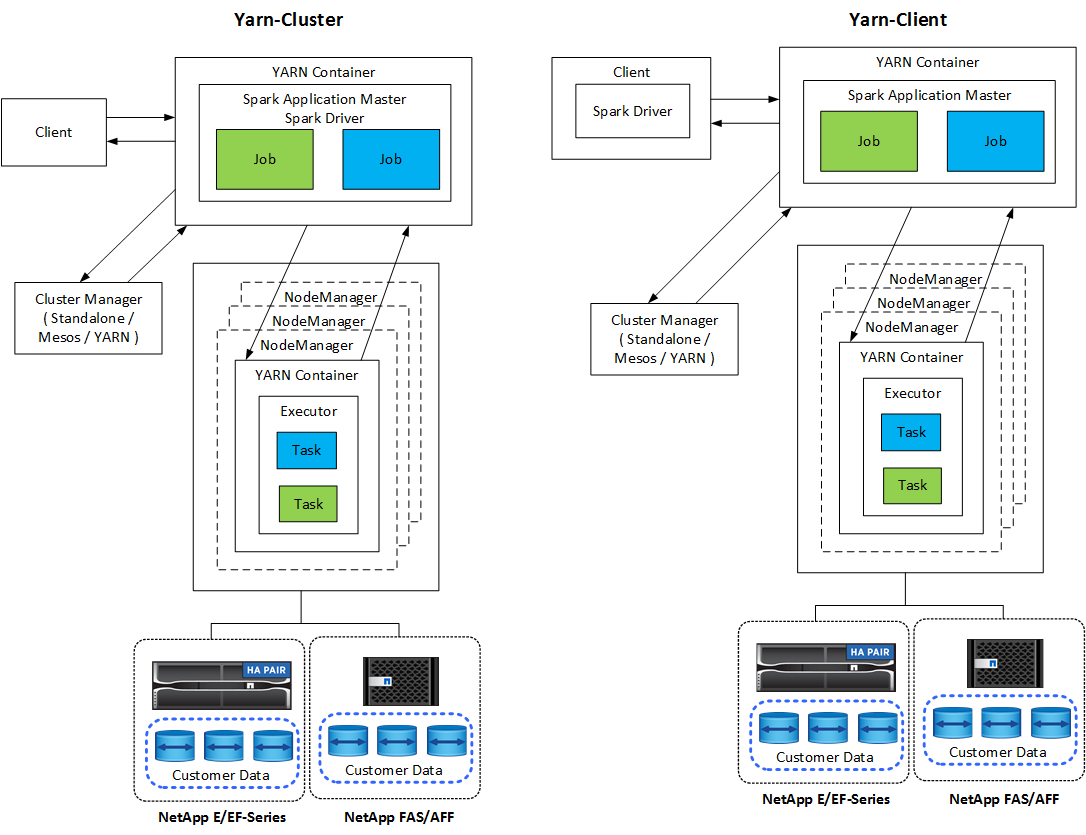
Il existe trois gestionnaires de clusters :
-
Autonome. Ce gestionnaire fait partie de Spark, ce qui facilite la configuration d'un cluster.
-
Apache Mesos. Il s’agit d’un gestionnaire de cluster général qui exécute également MapReduce et d’autres applications.
-
FIL Hadoop. Il s’agit d’un gestionnaire de ressources dans Hadoop 3.
L'ensemble de données distribué résilient (RDD) est le composant principal de Spark. RDD recrée les données perdues et manquantes à partir des données stockées en mémoire dans le cluster et stocke les données initiales provenant d'un fichier ou créées par programmation. Les RDD sont créés à partir de fichiers, de données en mémoire ou d'un autre RDD. La programmation Spark effectue deux opérations : la transformation et les actions. La transformation crée un nouveau RDD basé sur un RDD existant. Les actions renvoient une valeur à partir d’un RDD.
Les transformations et les actions s’appliquent également aux ensembles de données et aux DataFrames Spark. Un ensemble de données est une collection distribuée de données qui offre les avantages des RDD (typage fort, utilisation de fonctions lambda) avec les avantages du moteur d'exécution optimisé de Spark SQL. Un ensemble de données peut être construit à partir d'objets JVM, puis manipulé à l'aide de transformations fonctionnelles (map, flatMap, filter, etc.). Un DataFrame est un ensemble de données organisé en colonnes nommées. Il est conceptuellement équivalent à une table dans une base de données relationnelle ou à un cadre de données dans R/Python. Les DataFrames peuvent être construits à partir d'un large éventail de sources telles que des fichiers de données structurés, des tables dans Hive/HBase, des bases de données externes sur site ou dans le cloud, ou des RDD existants.
Les applications Spark incluent une ou plusieurs tâches Spark. Les tâches exécutent des tâches dans des exécuteurs, et les exécuteurs s'exécutent dans des conteneurs YARN. Chaque exécuteur s'exécute dans un seul conteneur et les exécuteurs existent tout au long de la vie d'une application. Un exécuteur est corrigé après le démarrage de l'application et YARN ne redimensionne pas le conteneur déjà alloué. Un exécuteur peut exécuter des tâches simultanément sur des données en mémoire.