Résultats des tests
 Suggérer des modifications
Suggérer des modifications
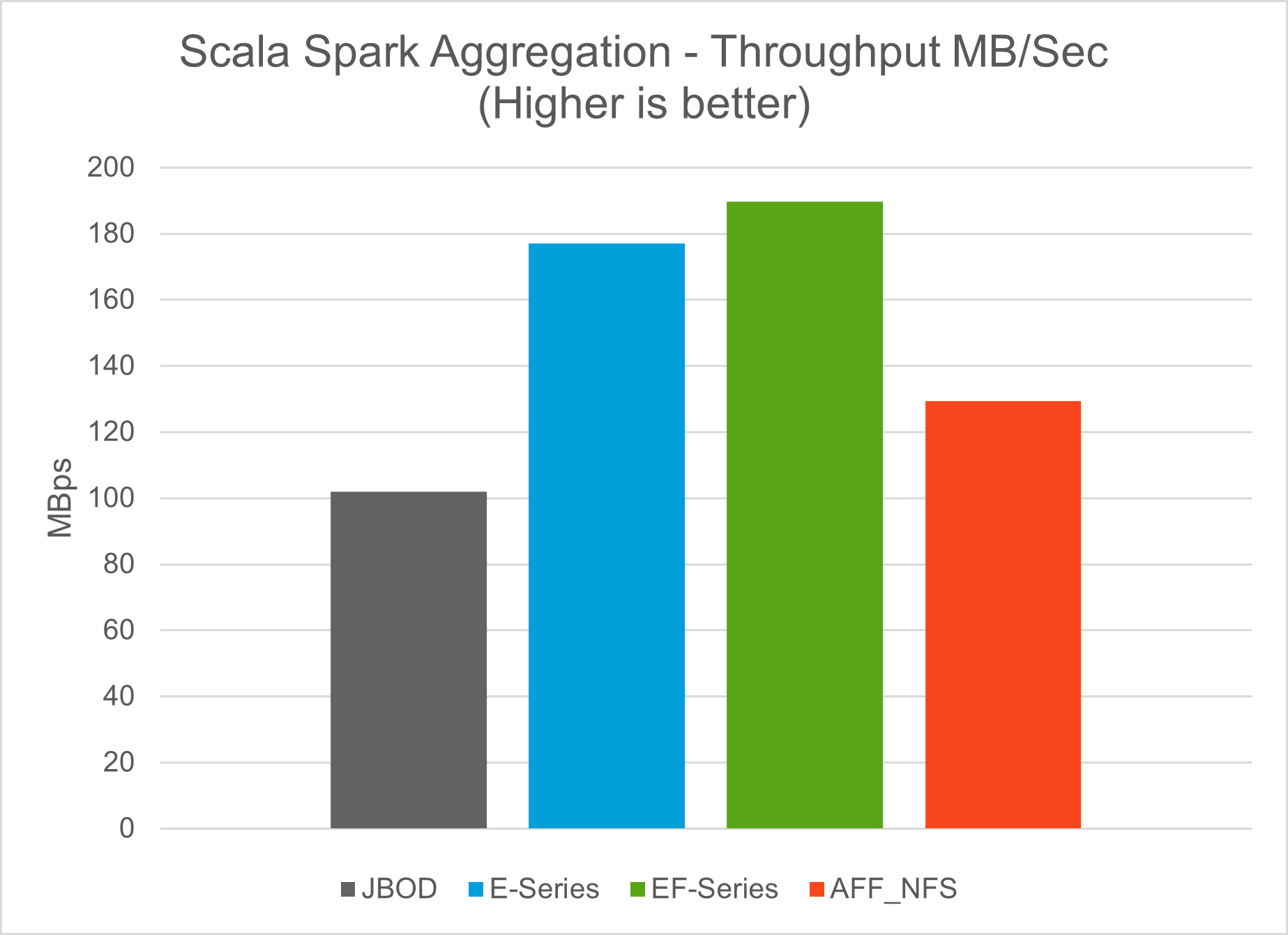
Nous avons utilisé les scripts TeraSort et TeraValidate dans l'outil d'analyse comparative TeraGen pour mesurer la validation des performances de Spark avec les configurations E5760, E5724 et AFF-A800. De plus, trois cas d'utilisation majeurs ont été testés : les pipelines Spark NLP et la formation distribuée TensorFlow, la formation distribuée Horovod et l'apprentissage profond multi-travailleurs utilisant Keras pour la prédiction CTR avec DeepFM.
Pour la validation des séries E et StorageGRID , nous avons utilisé le facteur de réplication Hadoop 2. Pour la validation AFF , nous n’avons utilisé qu’une seule source de données.
Le tableau suivant répertorie la configuration matérielle pour la validation des performances de Spark.
| Type | Nœuds de travail Hadoop | Type de lecteur | Lecteurs par nœud | Contrôleur de stockage |
|---|---|---|---|---|
SG6060 |
4 |
SAS |
12 |
Paire unique à haute disponibilité (HA) |
E5760 |
4 |
SAS |
60 |
Paire HA unique |
E5724 |
4 |
SAS |
24 |
Paire HA unique |
AFF800 |
4 |
SSD |
6 |
Paire HA unique |
Le tableau suivant répertorie les exigences logicielles.
| Logiciels | Version |
|---|---|
RHEL |
7,9 |
Environnement d'exécution OpenJDK |
1.8.0 |
Machine virtuelle serveur OpenJDK 64 bits |
25,302 |
Git |
2.24.1 |
GCC/G++ |
11.2.1 |
Étincelle |
3.2.1 |
PySpark |
3.1.2 |
SparkNLP |
3.4.2 |
TensorFlow |
2.9.0 |
Keras |
2.9.0 |
Horovod |
0.24.3 |
Analyse du sentiment financier
Nous avons publié"TR-4910 : Analyse des sentiments à partir des communications clients avec NetApp AI" , dans lequel un pipeline d'IA conversationnelle de bout en bout a été construit en utilisant le "Boîte à outils NetApp DataOps" , Stockage AFF et système NVIDIA DGX. Le pipeline effectue le traitement du signal audio par lots, la reconnaissance automatique de la parole (ASR), l'apprentissage par transfert et l'analyse des sentiments en exploitant la boîte à outils DataOps, "Kit de développement logiciel NVIDIA Riva" , et le "Cadre Tao" . En étendant le cas d'utilisation de l'analyse des sentiments au secteur des services financiers, nous avons créé un flux de travail SparkNLP, chargé trois modèles BERT pour diverses tâches NLP, telles que la reconnaissance d'entités nommées, et obtenu un sentiment au niveau des phrases pour les appels de résultats trimestriels des 10 premières entreprises du NASDAQ.
Le script suivant sentiment_analysis_spark. py utilise le modèle FinBERT pour traiter les transcriptions dans HDFS et produire des décomptes de sentiments positifs, neutres et négatifs, comme indiqué dans le tableau suivant :
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py hdfs:///data1/Transcripts/ > ./sentiment_analysis_hdfs.log 2>&1 real13m14.300s user557m11.319s sys4m47.676s
Le tableau suivant répertorie l'analyse des sentiments au niveau des phrases et des appels aux résultats pour les 10 premières sociétés du NASDAQ de 2016 à 2020.
| Nombre et pourcentage de sentiments | Les 10 entreprises | AAPL | DMLA | AMZN | CSCO | GOOGL | INTC | MSFT | NVDA |
|---|---|---|---|---|---|---|---|---|---|
Comptes positifs |
7447 |
1567 |
743 |
290 |
682 |
826 |
824 |
904 |
417 |
Comptes neutres |
64067 |
6856 |
7596 |
5086 |
6650 |
5914 |
6099 |
5715 |
6189 |
Comptes négatifs |
1787 |
253 |
213 |
84 |
189 |
97 |
282 |
202 |
89 |
Comptes non classés |
196 |
0 |
0 |
76 |
0 |
0 |
0 |
1 |
0 |
(nombre total de comptes) |
73497 |
8676 |
8552 |
5536 |
7521 |
6837 |
7205 |
6822 |
6695 |
En termes de pourcentages, la plupart des phrases prononcées par les PDG et les directeurs financiers sont factuelles et véhiculent donc un sentiment neutre. Lors d’une conférence téléphonique sur les résultats, les analystes posent des questions qui peuvent transmettre un sentiment positif ou négatif. Il vaut la peine d’étudier plus en détail quantitativement la manière dont le sentiment négatif ou positif affecte les cours des actions le jour même ou le jour suivant la négociation.
Le tableau suivant répertorie l'analyse des sentiments au niveau des phrases pour les 10 premières sociétés du NASDAQ, exprimée en pourcentage.
| Pourcentage de sentiment | Les 10 entreprises | AAPL | DMLA | AMZN | CSCO | GOOGL | INTC | MSFT | NVDA |
|---|---|---|---|---|---|---|---|---|---|
Positif |
10,13% |
18,06% |
8,69% |
5,24% |
9,07% |
12,08% |
11,44% |
13,25% |
6,23% |
Neutre |
87,17% |
79,02% |
88,82% |
91,87% |
88,42% |
86,50% |
84,65% |
83,77% |
92,44% |
Négatif |
2,43% |
2,92% |
2,49% |
1,52% |
2,51% |
1,42% |
3,91% |
2,96% |
1,33% |
Non classé |
0,27% |
0% |
0% |
1,37% |
0% |
0% |
0% |
0,01% |
0% |
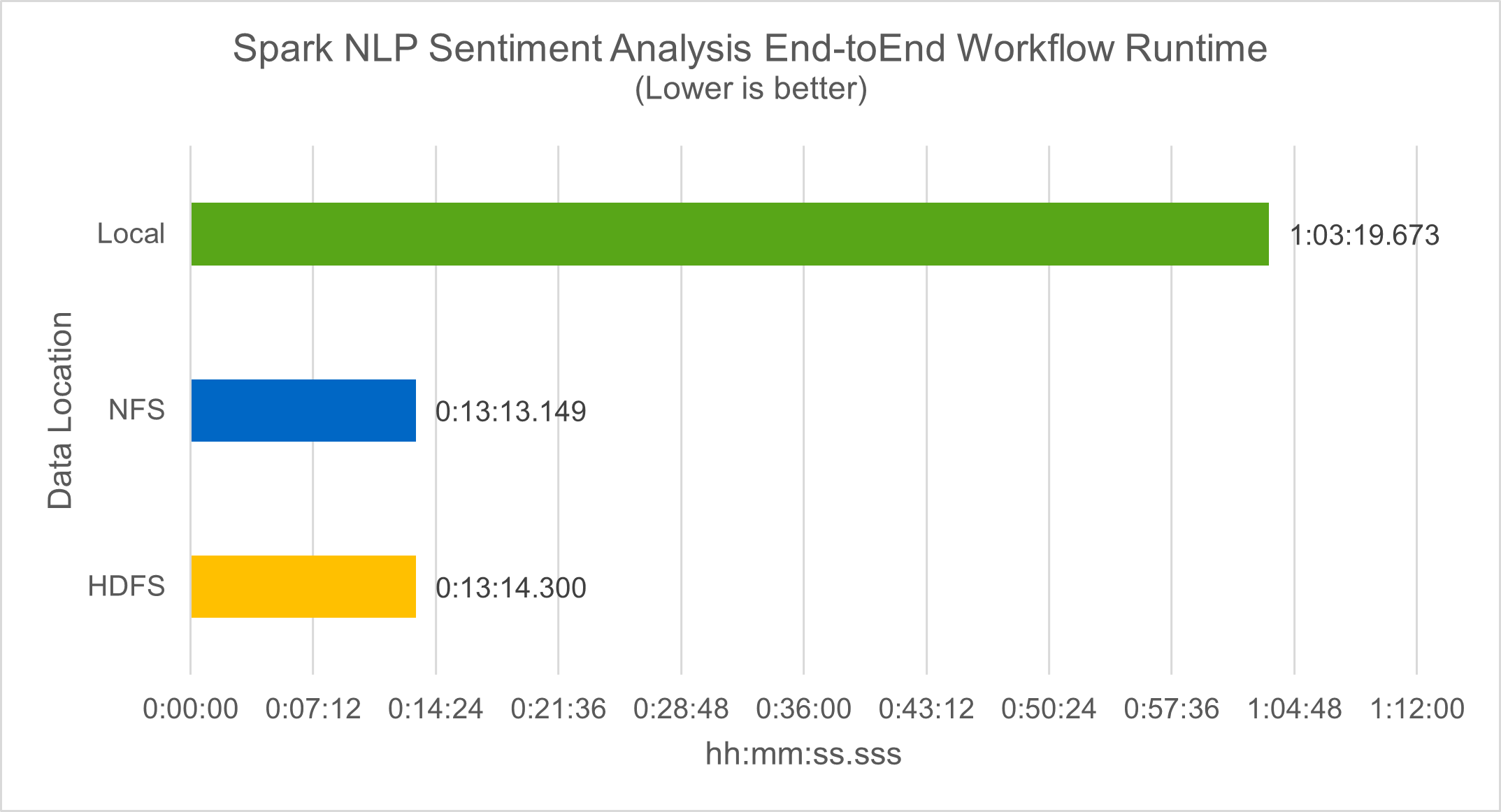
En termes de temps d'exécution du flux de travail, nous avons constaté une amélioration significative de 4,78x par rapport à local mode vers un environnement distribué dans HDFS, et une amélioration supplémentaire de 0,14 % en exploitant NFS.
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py file:///sparkdemo/sparknlp/Transcripts/ > ./sentiment_analysis_nfs.log 2>&1 real13m13.149s user537m50.148s sys4m46.173s
Comme le montre la figure suivante, le parallélisme des données et du modèle a amélioré le traitement des données et la vitesse d’inférence du modèle TensorFlow distribué. L'emplacement des données dans NFS a donné un temps d'exécution légèrement meilleur, car le goulot d'étranglement du flux de travail est le téléchargement de modèles pré-entraînés. Si nous augmentons la taille de l’ensemble de données de transcription, l’avantage de NFS est plus évident.
Formation distribuée avec performance Horovod
La commande suivante a produit des informations d'exécution et un fichier journal dans notre cluster Spark à l'aide d'un seul master nœud avec 160 exécuteurs chacun avec un cœur. La mémoire de l'exécuteur a été limitée à 5 Go pour éviter une erreur de mémoire insuffisante. Voir la section"Scripts Python pour chaque cas d'utilisation majeur" pour plus de détails concernant le traitement des données, la formation du modèle et le calcul de la précision du modèle dans keras_spark_horovod_rossmann_estimator.py .
(base) [root@n138 horovod]# time spark-submit --master local --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkusecase/horovod --local-submission-csv /tmp/submission_0.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_local. log 2>&1
Le temps d'exécution résultant avec dix époques d'entraînement était le suivant :
real43m34.608s user12m22.057s sys2m30.127s
Il a fallu plus de 43 minutes pour traiter les données d'entrée, former un modèle DNN, calculer la précision et produire des points de contrôle TensorFlow et un fichier CSV pour les résultats de prédiction. Nous avons limité le nombre d'époques d'entraînement à 10, qui dans la pratique est souvent fixé à 100 pour garantir une précision satisfaisante du modèle. Le temps de formation évolue généralement de manière linéaire avec le nombre d’époques.
Nous avons ensuite utilisé les quatre nœuds de travail disponibles dans le cluster et exécuté le même script dans yarn mode avec données dans HDFS :
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir hdfs:///user/hdfs/tr-4570/experiments/horovod --local-submission-csv /tmp/submission_1.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_yarn.log 2>&1
Le temps d'exécution résultant a été amélioré comme suit :
real8m13.728s user7m48.421s sys1m26.063s
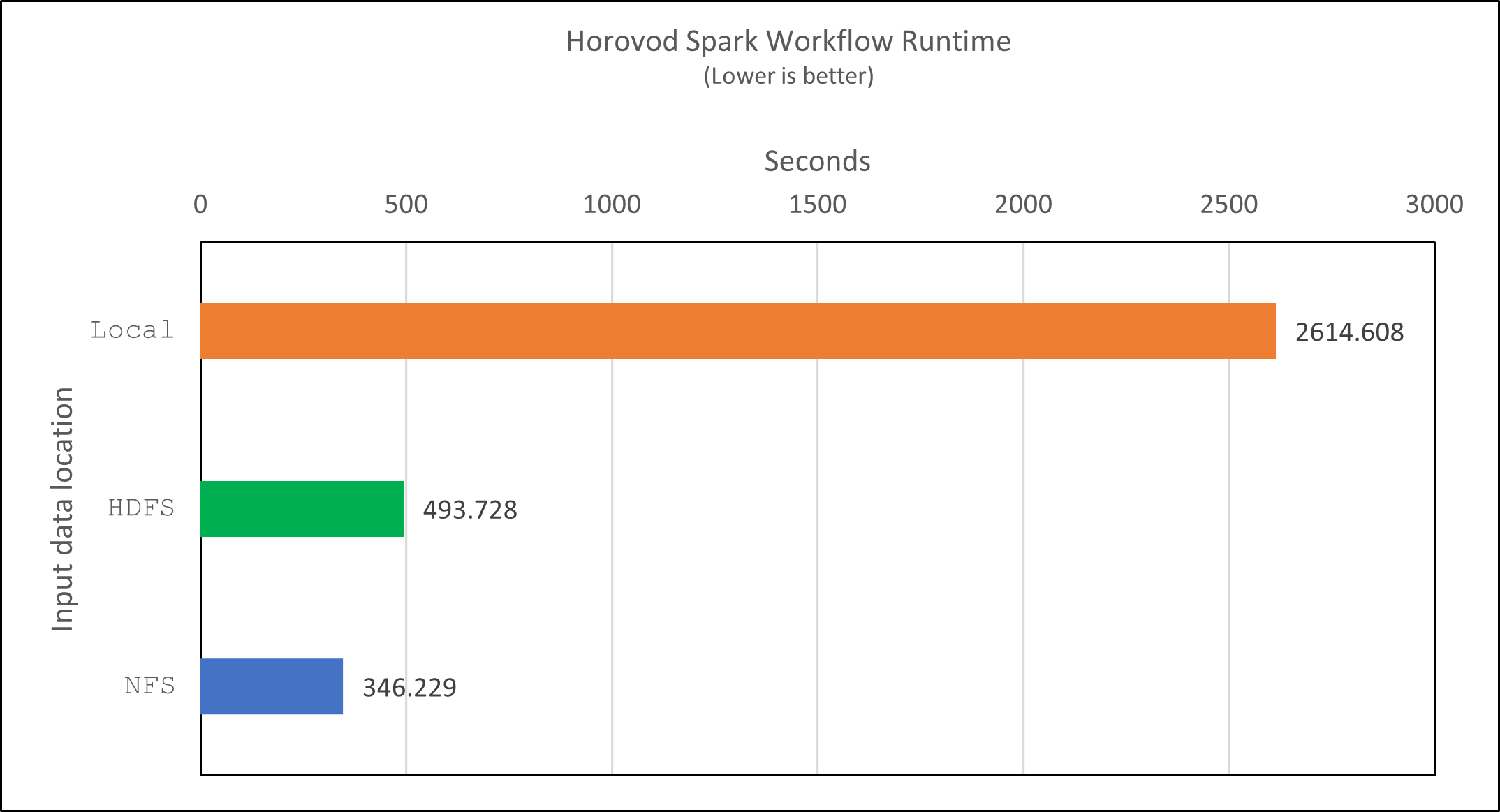
Avec le modèle d'Horovod et le parallélisme des données dans Spark, nous avons constaté une accélération d'exécution de 5,29x yarn contre local mode avec dix époques d'entraînement. Ceci est illustré dans la figure suivante avec les légendes HDFS et Local . La formation du modèle DNN TensorFlow sous-jacent peut être encore accélérée avec des GPU s'ils sont disponibles. Nous prévoyons de réaliser ces tests et de publier les résultats dans un futur rapport technique.
Notre prochain test a comparé les temps d’exécution avec des données d’entrée résidant dans NFS par rapport à HDFS. Le volume NFS sur l' AFF A800 a été monté sur /sparkdemo/horovod sur les cinq nœuds (un maître, quatre travailleurs) de notre cluster Spark. Nous avons exécuté une commande similaire à celle des tests précédents, avec le --data- dir paramètre pointant désormais vers le montage NFS :
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkdemo/horovod --local-submission-csv /tmp/submission_2.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_nfs.log 2>&1
Le temps d'exécution résultant avec NFS était le suivant :
real 5m46.229s user 5m35.693s sys 1m5.615s
Il y a eu une accélération supplémentaire de 1,43x, comme le montre la figure suivante. Par conséquent, avec un stockage entièrement flash NetApp connecté à leur cluster, les clients bénéficient des avantages d'un transfert et d'une distribution rapides des données pour les flux de travail Horovod Spark, atteignant une accélération de 7,55 fois par rapport à l'exécution sur un seul nœud.
Modèles d'apprentissage profond pour les performances de prédiction du CTR
Pour les systèmes de recommandation conçus pour maximiser le CTR, vous devez apprendre les interactions sophistiquées des fonctionnalités derrière les comportements des utilisateurs qui peuvent être calculées mathématiquement d'un ordre faible à un ordre élevé. Les interactions entre les caractéristiques d’ordre faible et d’ordre élevé doivent être tout aussi importantes pour un bon modèle d’apprentissage en profondeur, sans biaiser vers l’une ou l’autre. Deep Factorization Machine (DeepFM), un réseau neuronal basé sur une machine de factorisation, combine des machines de factorisation pour la recommandation et l'apprentissage en profondeur pour l'apprentissage des fonctionnalités dans une nouvelle architecture de réseau neuronal.
Bien que les machines de factorisation conventionnelles modélisent les interactions de caractéristiques par paires comme un produit interne de vecteurs latents entre les caractéristiques et puissent théoriquement capturer des informations d'ordre élevé, dans la pratique, les praticiens de l'apprentissage automatique n'utilisent généralement que des interactions de caractéristiques de second ordre en raison de la complexité élevée du calcul et du stockage. Variantes de réseaux neuronaux profonds comme celui de Google "Modèles larges et profonds" d'autre part, apprend les interactions de fonctionnalités sophistiquées dans une structure de réseau hybride en combinant un modèle linéaire large et un modèle profond.
Ce modèle large et profond comporte deux entrées, l'une pour le modèle large sous-jacent et l'autre pour le modèle profond, cette dernière partie nécessitant encore une ingénierie des fonctionnalités experte et rendant ainsi la technique moins généralisable à d'autres domaines. Contrairement au modèle large et profond, DeepFM peut être efficacement formé avec des fonctionnalités brutes sans aucune ingénierie de fonctionnalités, car sa partie large et sa partie profonde partagent la même entrée et le même vecteur d'intégration.
Nous avons d'abord traité le Criteo train.txt (11 Go) dans un fichier CSV nommé ctr_train.csv stocké dans un montage NFS /sparkdemo/tr-4570-data en utilisant run_classification_criteo_spark.py de la section"Scripts Python pour chaque cas d'utilisation majeur." Dans ce script, la fonction process_input_file exécute plusieurs méthodes de chaîne pour supprimer les tabulations et insérer ',' comme délimiteur et '\n' comme nouvelle ligne. Notez que vous n'avez besoin de traiter que l'original train.txt une fois, afin que le bloc de code soit affiché sous forme de commentaires.
Pour les tests suivants de différents modèles DL, nous avons utilisé ctr_train.csv comme fichier d'entrée. Lors des tests ultérieurs, le fichier CSV d'entrée a été lu dans un Spark DataFrame avec un schéma contenant un champ de 'label' , caractéristiques denses en nombres entiers ['I1', 'I2', 'I3', …, 'I13'] , et des fonctionnalités éparses ['C1', 'C2', 'C3', …, 'C26'] . Ce qui suit spark-submit la commande prend un fichier CSV d'entrée, entraîne les modèles DeepFM avec une répartition de 20 % pour la validation croisée et sélectionne le meilleur modèle après dix époques d'entraînement pour calculer la précision de prédiction sur l'ensemble de test :
(base) [root@n138 ~]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > /tmp/run_classification_criteo_spark_local.log 2>&1
Notez que puisque le fichier de données ctr_train.csv est supérieur à 11 Go, vous devez définir une valeur suffisante spark.driver.maxResultSize supérieur à la taille de l'ensemble de données pour éviter les erreurs.
spark = SparkSession.builder \
.master("yarn") \
.appName("deep_ctr_classification") \
.config("spark.jars.packages", "io.github.ravwojdyla:spark-schema-utils_2.12:0.1.0") \
.config("spark.executor.cores", "1") \
.config('spark.executor.memory', '5gb') \
.config('spark.executor.memoryOverhead', '1500') \
.config('spark.driver.memoryOverhead', '1500') \
.config("spark.sql.shuffle.partitions", "480") \
.config("spark.sql.execution.arrow.enabled", "true") \
.config("spark.driver.maxResultSize", "50gb") \
.getOrCreate()
Dans ce qui précède SparkSession.builder configuration que nous avons également activée "Apache Arrow" , qui convertit un Spark DataFrame en Pandas DataFrame avec le df.toPandas() méthode.
22/06/17 15:56:21 INFO scheduler.DAGScheduler: Job 2 finished: toPandas at /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py:96, took 627.126487 s Obtained Spark DF and transformed to Pandas DF using Arrow.
Après une division aléatoire, il y a plus de 36 millions de lignes dans l'ensemble de données d'entraînement et 9 millions d'échantillons dans l'ensemble de test :
Training dataset size = 36672493 Testing dataset size = 9168124
Étant donné que ce rapport technique se concentre sur les tests de processeur sans utiliser de GPU, il est impératif de créer TensorFlow avec les indicateurs de compilateur appropriés. Cette étape évite d’appeler des bibliothèques accélérées par GPU et tire pleinement parti des instructions AVX (Advanced Vector Extensions) et AVX2 de TensorFlow. Ces fonctionnalités sont conçues pour les calculs algébriques linéaires tels que l'addition vectorisée, les multiplications matricielles dans un entraînement DNN à propagation directe ou à rétropropagation. L'instruction Fused Multiply Add (FMA) disponible avec AVX2 utilisant des registres à virgule flottante (FP) 256 bits est idéale pour le code entier et les types de données, ce qui permet une accélération jusqu'à 2x. Pour le code FP et les types de données, AVX2 atteint une accélération de 8 % par rapport à AVX.
2022-06-18 07:19:20.101478: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Pour créer TensorFlow à partir de la source, NetApp recommande d'utiliser "Bazel" . Pour notre environnement, nous avons exécuté les commandes suivantes dans l'invite du shell pour installer dnf , dnf-plugins , et Bazel.
yum install dnf dnf install 'dnf-command(copr)' dnf copr enable vbatts/bazel dnf install bazel5
Vous devez activer GCC 5 ou une version plus récente pour utiliser les fonctionnalités C++17 pendant le processus de génération, qui est fourni par RHEL avec Software Collections Library (SCL). Les commandes suivantes installent devtoolset et GCC 11.2.1 sur notre cluster RHEL 7.9 :
subscription-manager repos --enable rhel-server-rhscl-7-rpms yum install devtoolset-11-toolchain yum install devtoolset-11-gcc-c++ yum update scl enable devtoolset-11 bash . /opt/rh/devtoolset-11/enable
Notez que les deux dernières commandes permettent devtoolset-11 , qui utilise /opt/rh/devtoolset-11/root/usr/bin/gcc (CCG 11.2.1). Assurez-vous également que votre git la version est supérieure à 1.8.3 (celle-ci est fournie avec RHEL 7.9). Se référer à ceci "article" pour la mise à jour git à 2.24.1.
Nous supposons que vous avez déjà cloné le dernier référentiel maître TensorFlow. Créez ensuite un workspace répertoire avec un WORKSPACE fichier pour créer TensorFlow à partir de la source avec AVX, AVX2 et FMA. Exécutez le configure fichier et spécifiez l'emplacement binaire Python correct. "CUDA" est désactivé pour nos tests car nous n'avons pas utilisé de GPU. UN .bazelrc le fichier est généré en fonction de vos paramètres. De plus, nous avons édité le fichier et défini build --define=no_hdfs_support=false pour activer la prise en charge HDFS. Se référer à .bazelrc dans la section"Scripts Python pour chaque cas d'utilisation majeur," pour une liste complète des paramètres et des indicateurs.
./configure bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both -k //tensorflow/tools/pip_package:build_pip_package
Après avoir créé TensorFlow avec les indicateurs appropriés, exécutez le script suivant pour traiter l'ensemble de données Criteo Display Ads, entraîner un modèle DeepFM et calculer l'aire sous la courbe caractéristique de fonctionnement du récepteur (ROC AUC) à partir des scores de prédiction.
(base) [root@n138 examples]# ~/anaconda3/bin/spark-submit --master yarn --executor-memory 15g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > . /run_classification_criteo_spark_nfs.log 2>&1
Après dix périodes d'entraînement, nous avons obtenu le score AUC sur l'ensemble de données de test :
Epoch 1/10 125/125 - 7s - loss: 0.4976 - binary_crossentropy: 0.4974 - val_loss: 0.4629 - val_binary_crossentropy: 0.4624 Epoch 2/10 125/125 - 1s - loss: 0.3281 - binary_crossentropy: 0.3271 - val_loss: 0.5146 - val_binary_crossentropy: 0.5130 Epoch 3/10 125/125 - 1s - loss: 0.1948 - binary_crossentropy: 0.1928 - val_loss: 0.6166 - val_binary_crossentropy: 0.6144 Epoch 4/10 125/125 - 1s - loss: 0.1408 - binary_crossentropy: 0.1383 - val_loss: 0.7261 - val_binary_crossentropy: 0.7235 Epoch 5/10 125/125 - 1s - loss: 0.1129 - binary_crossentropy: 0.1102 - val_loss: 0.7961 - val_binary_crossentropy: 0.7934 Epoch 6/10 125/125 - 1s - loss: 0.0949 - binary_crossentropy: 0.0921 - val_loss: 0.9502 - val_binary_crossentropy: 0.9474 Epoch 7/10 125/125 - 1s - loss: 0.0778 - binary_crossentropy: 0.0750 - val_loss: 1.1329 - val_binary_crossentropy: 1.1301 Epoch 8/10 125/125 - 1s - loss: 0.0651 - binary_crossentropy: 0.0622 - val_loss: 1.3794 - val_binary_crossentropy: 1.3766 Epoch 9/10 125/125 - 1s - loss: 0.0555 - binary_crossentropy: 0.0527 - val_loss: 1.6115 - val_binary_crossentropy: 1.6087 Epoch 10/10 125/125 - 1s - loss: 0.0470 - binary_crossentropy: 0.0442 - val_loss: 1.6768 - val_binary_crossentropy: 1.6740 test AUC 0.6337
D’une manière similaire aux cas d’utilisation précédents, nous avons comparé l’exécution du workflow Spark avec des données résidant dans différents emplacements. La figure suivante montre une comparaison de la prédiction CTR d’apprentissage profond pour un environnement d’exécution de workflows Spark.