

Solution de transfert de données
 Suggérer des modifications
Suggérer des modifications
Dans un cluster Big Data, les données sont stockées dans HDFS ou HCFS, comme MapR-FS, Windows Azure Storage Blob, S3 ou le système de fichiers Google. Nous avons effectué des tests avec HDFS, MapR-FS et S3 comme source pour copier les données vers l'exportation NetApp ONTAP NFS à l'aide de NIPAM en utilisant le hadoop distcp commande de la source.
Le diagramme suivant illustre le déplacement de données typique d'un cluster Spark exécuté avec un stockage HDFS vers un volume NetApp ONTAP NFS afin que NVIDIA puisse traiter les opérations d'IA.
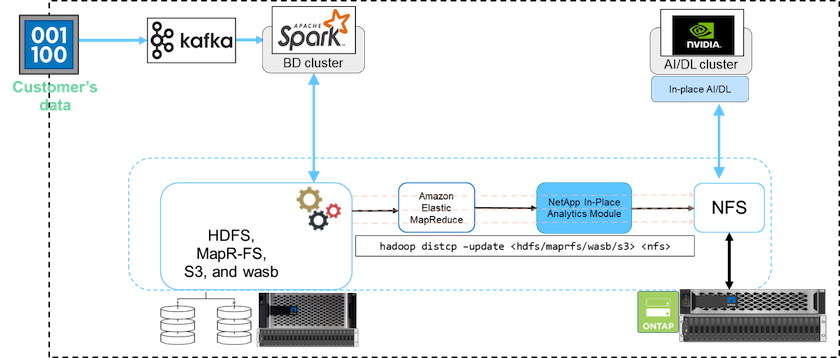
Le hadoop distcp La commande utilise le programme MapReduce pour copier les données. NIPAM fonctionne avec MapReduce pour agir comme pilote pour le cluster Hadoop lors de la copie des données. NIPAM peut distribuer une charge sur plusieurs interfaces réseau pour une seule exportation. Ce processus maximise le débit du réseau en distribuant les données sur plusieurs interfaces réseau lorsque vous copiez les données de HDFS ou HCFS vers NFS.

|
NIPAM n'est pas pris en charge ou certifié avec MapR. |