

Présentation de la vérification des solutions
 Suggérer des modifications
Suggérer des modifications
Dans cette section, nous avons exécuté des requêtes de test SQL à partir de plusieurs sources pour vérifier la fonctionnalité, tester et vérifier le débordement vers le stockage NetApp .
Requête SQL sur le stockage d'objets
-
Définissez la mémoire à 250 Go par serveur dans dremio.env
root@hadoopmaster:~# for i in hadoopmaster hadoopnode1 hadoopnode2 hadoopnode3 hadoopnode4; do ssh $i "hostname; grep -i DREMIO_MAX_MEMORY_SIZE_MB /opt/dremio/conf/dremio-env; cat /proc/meminfo | grep -i memtotal"; done hadoopmaster #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515760 kB hadoopnode1 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515860 kB hadoopnode2 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515864 kB hadoopnode3 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 264004556 kB node4 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515484 kB root@hadoopmaster:~#
-
Vérifiez l'emplacement de débordement (${DREMIO_HOME}"/dremiocache) dans le fichier dremio.conf et les détails de stockage.
paths: { # the local path for dremio to store data. local: ${DREMIO_HOME}"/dremiocache" # the distributed path Dremio data including job results, downloads, uploads, etc #dist: "hdfs://hadoopmaster:9000/dremiocache" dist: "dremioS3:///dremioconf" } services: { coordinator.enabled: true, coordinator.master.enabled: true, executor.enabled: false, flight.use_session_service: false } zookeeper: "10.63.150.130:2181,10.63.150.153:2181,10.63.150.151:2181" services.coordinator.master.embedded-zookeeper.enabled: false -
Dirigez l'emplacement de débordement de Dremio vers le stockage NetApp NFS
root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# ls -ltrh /opt/dremio/dremiocache/ total 8.0K drwxr-xr-x 3 dremio dremio 4.0K Aug 22 18:19 spill_old drwxr-xr-x 4 dremio dremio 4.0K Aug 22 18:19 cm lrwxrwxrwx 1 root root 12 Aug 22 19:03 spill -> /dremiocache root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# df -h /dremiocache Filesystem Size Used Avail Use% Mounted on 10.63.150.159:/dremiocache_hadoopnode1 2.1T 209M 2.0T 1% /dremiocache root@hadoopnode1:~#
-
Sélectionnez le contexte. Dans notre test, nous avons exécuté le test sur les fichiers parquet générés par TPCDS résidant dans ONTAP S3. Tableau de bord Dremio → Exécuteur SQL → Contexte → NetAppONTAPS3 → Parquet1TB
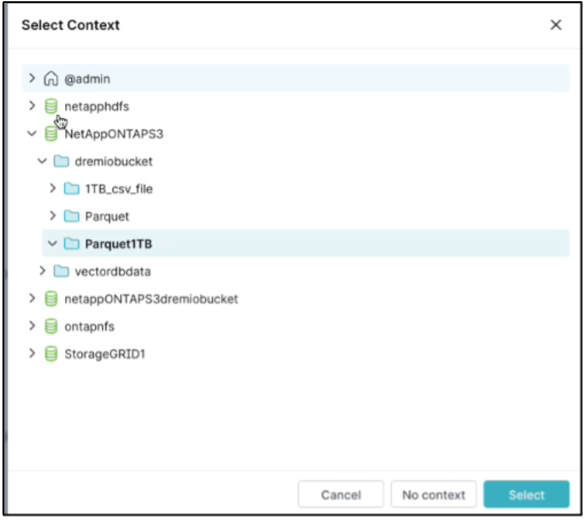
-
Exécutez la requête TPC-DS67 à partir du tableau de bord Dremio
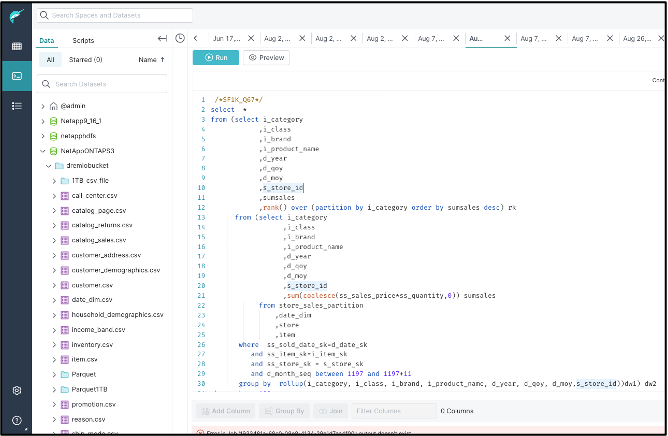
-
Vérifiez que le travail est en cours d’exécution sur tous les exécuteurs. Tableau de bord Dremio → tâches → <jobid> → profil brut → sélectionnez EXTERNAL_SORT → Nom d'hôte
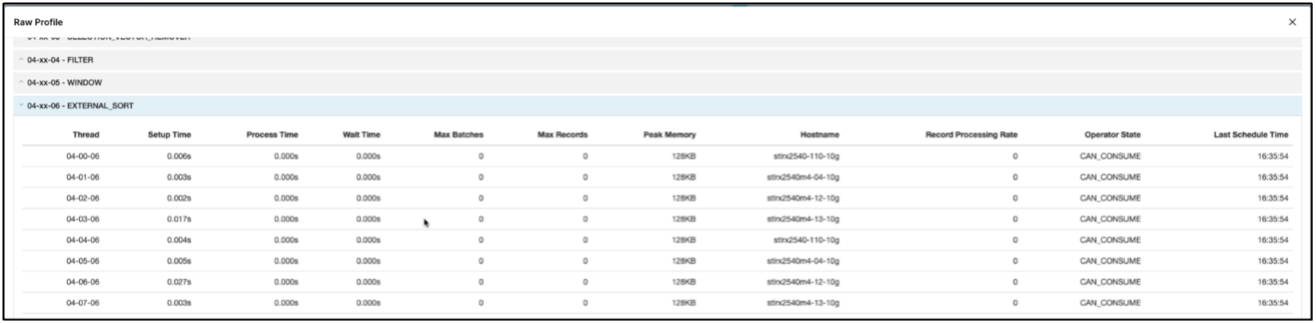
-
Lorsque la requête SQL est en cours d'exécution, vous pouvez vérifier le dossier divisé pour la mise en cache des données dans le contrôleur de stockage NetApp .
root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# ls -ltrh /dremiocache/spilling_stlrx2540m4-12-10g_45678/ total 4.0K drwxr-xr-x 2 root daemon 4.0K Sep 13 16:23 1726243167416
-
La requête SQL complétée avec débordement

-
Résumé de l'achèvement du travail.
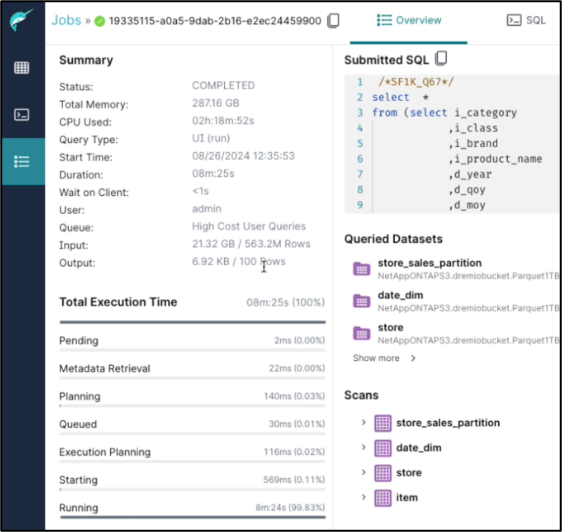
-
Vérifiez la taille des données renversées
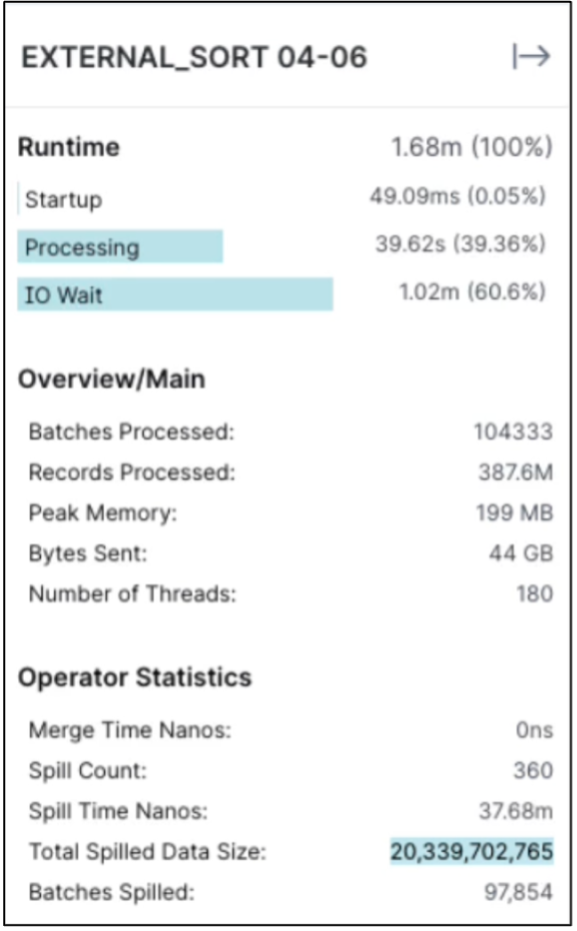
La même procédure s'applique au stockage d'objets NAS et StorageGRID .