Cas d'utilisation 2 : Sauvegarde et reprise après sinistre du cloud vers les locaux
 Suggérer des modifications
Suggérer des modifications
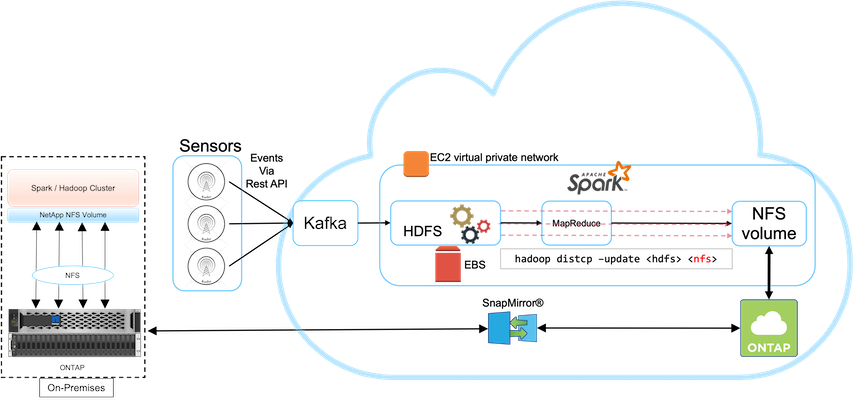
Ce cas d’utilisation est basé sur un client de diffusion qui a besoin de sauvegarder des données d’analyse basées sur le cloud dans son centre de données sur site, comme illustré dans la figure ci-dessous.
Scénario
Dans ce scénario, les données du capteur IoT sont ingérées dans le cloud et analysées à l’aide d’un cluster Apache Spark open source au sein d’AWS. L’exigence est de sauvegarder les données traitées du cloud vers les locaux.
Exigences et défis
Les principales exigences et défis pour ce cas d'utilisation incluent :
-
L'activation de la protection des données ne devrait pas avoir d'effet sur les performances du cluster Spark/Hadoop de production dans le cloud.
-
Les données des capteurs cloud doivent être déplacées et protégées sur site de manière efficace et sécurisée.
-
Flexibilité pour transférer des données du cloud vers les locaux dans différentes conditions, telles que la demande, l'instantané et pendant les périodes de faible charge du cluster.
Solution
Le client utilise AWS Elastic Block Store (EBS) pour son stockage HDFS de cluster Spark afin de recevoir et d'ingérer des données provenant de capteurs distants via Kafka. Par conséquent, le stockage HDFS agit comme source pour les données de sauvegarde.
Pour répondre à ces exigences, NetApp ONTAP Cloud est déployé dans AWS et un partage NFS est créé pour servir de cible de sauvegarde pour le cluster Spark/Hadoop.
Une fois le partage NFS créé, copiez les données du stockage EBS HDFS dans le partage NFS ONTAP . Une fois les données stockées dans NFS dans ONTAP Cloud, la technologie SnapMirror peut être utilisée pour mettre en miroir les données du cloud vers le stockage sur site, selon les besoins, de manière sécurisée et efficace.
Cette image montre la solution de sauvegarde et de reprise après sinistre du cloud vers la solution sur site.