Cas d'utilisation 3 : Activation de DevTest sur des données Hadoop existantes
 Suggérer des modifications
Suggérer des modifications
Dans ce cas d'utilisation, l'exigence du client est de créer rapidement et efficacement de nouveaux clusters Hadoop/Spark basés sur un cluster Hadoop existant contenant une grande quantité de données d'analyse à des fins de DevTest et de reporting dans le même centre de données ainsi que dans des emplacements distants.
Scénario
Dans ce scénario, plusieurs clusters Spark/Hadoop sont construits à partir d'une grande implémentation de lac de données Hadoop sur site ainsi que sur des sites de reprise après sinistre.
Exigences et défis
Les principales exigences et défis pour ce cas d'utilisation incluent :
-
Créez plusieurs clusters Hadoop pour DevTest, QA ou tout autre objectif nécessitant l'accès aux mêmes données de production. Le défi ici est de cloner un très grand cluster Hadoop plusieurs fois instantanément et de manière très efficace en termes d’espace.
-
Synchronisez les données Hadoop avec les équipes DevTest et de reporting pour une efficacité opérationnelle.
-
Distribuez les données Hadoop en utilisant les mêmes informations d’identification entre la production et les nouveaux clusters.
-
Utilisez des stratégies planifiées pour créer efficacement des clusters QA sans affecter le cluster de production.
Solution
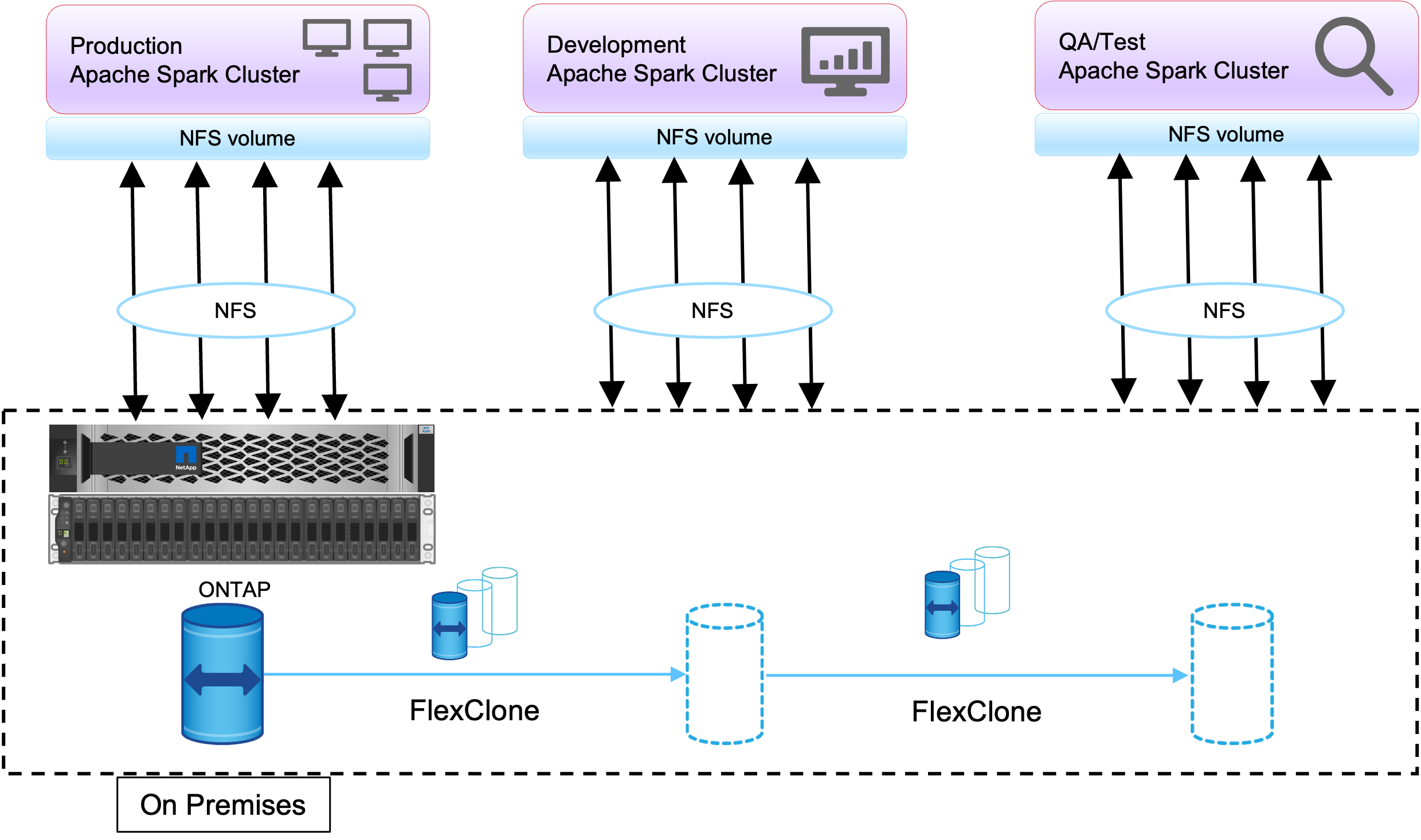
La technologie FlexClone est utilisée pour répondre aux exigences qui viennent d'être décrites. La technologie FlexClone est la copie en lecture/écriture d'une copie Snapshot. Il lit les données à partir des données de copie Snapshot parent et consomme uniquement de l'espace supplémentaire pour les blocs nouveaux/modifiés. C'est rapide et peu encombrant.
Tout d’abord, une copie instantanée du cluster existant a été créée à l’aide d’un groupe de cohérence NetApp .
Copies instantanées dans NetApp System Manager ou dans l'invite d'administration du stockage. Les copies Snapshot du groupe de cohérence sont des copies Snapshot du groupe cohérentes avec l'application, et le volume FlexClone est créé sur la base des copies Snapshot du groupe de cohérence. Il convient de mentionner qu'un volume FlexClone hérite de la politique d'exportation NFS du volume parent. Une fois la copie Snapshot créée, un nouveau cluster Hadoop doit être installé à des fins de DevTest et de création de rapports, comme illustré dans la figure ci-dessous. Le volume NFS cloné du nouveau cluster Hadoop accède aux données NFS.
Cette image montre le cluster Hadoop pour DevTest.