

Lignes directrices sur les meilleures pratiques
 Suggérer des modifications
Suggérer des modifications
Cette section présente les enseignements tirés de cette certification.
-
Sur la base de notre validation, le stockage d’objets S3 est le meilleur moyen pour Confluent de conserver les données.
-
Nous pouvons utiliser un SAN à haut débit (en particulier FC) pour conserver les données chaudes du courtier ou le disque local, car, dans la configuration de stockage hiérarchisé Confluent, la taille des données conservées dans le répertoire de données des courtiers est basée sur la taille du segment et le temps de rétention lorsque les données sont déplacées vers le stockage d'objets.
-
Les magasins d'objets offrent de meilleures performances lorsque segment.bytes est plus élevé ; nous avons testé 512 Mo.
-
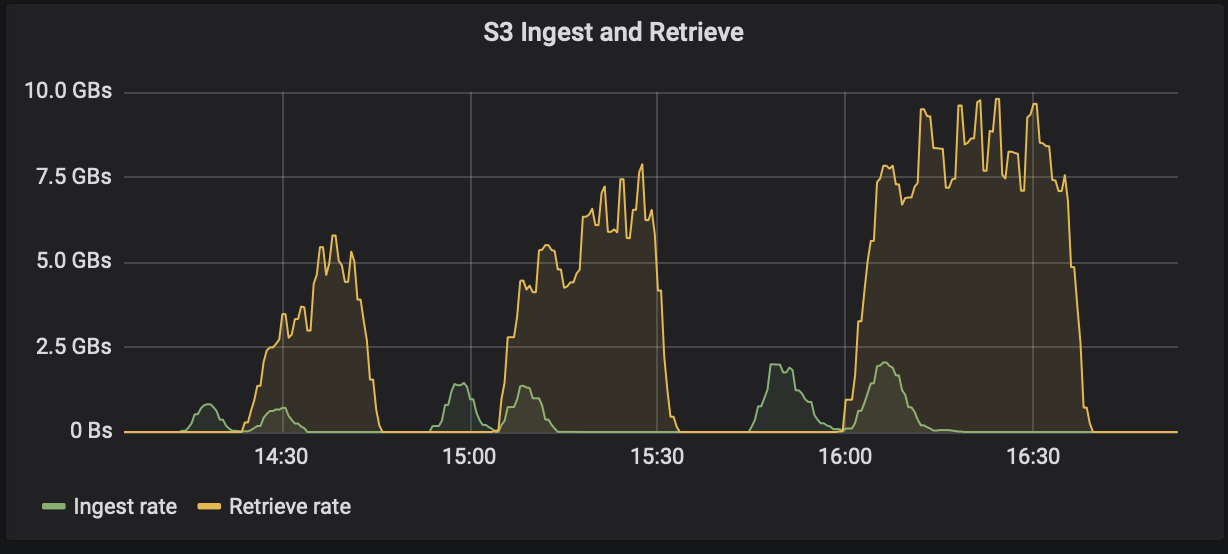
Dans Kafka, la longueur de la clé ou de la valeur (en octets) pour chaque enregistrement produit dans le sujet est contrôlée par le
length.key.valueparamètre. Pour StorageGRID, les performances d'ingestion et de récupération d'objets S3 ont été augmentées à des valeurs plus élevées. Par exemple, 512 octets ont fourni une récupération de 5,8 Gbit/s, 1 024 octets ont fourni une récupération S3 de 7,5 Gbit/s et 2 048 octets ont fourni près de 10 Gbit/s.
La figure suivante présente l'objet S3 ingéré et récupéré en fonction de length.key.value .
-
Réglage Kafka. Pour améliorer les performances du stockage hiérarchisé, vous pouvez augmenter TierFetcherNumThreads et TierArchiverNumThreads. En règle générale, vous souhaitez augmenter TierFetcherNumThreads pour qu'il corresponde au nombre de cœurs de processeur physiques et augmenter TierArchiverNumThreads à la moitié du nombre de cœurs de processeur. Par exemple, dans les propriétés du serveur, si vous disposez d’une machine avec huit cœurs physiques, définissez confluent.tier.fetcher.num.threads = 8 et confluent.tier.archiver.num.threads = 4.
-
Intervalle de temps pour les suppressions de sujets. Lorsqu'une rubrique est supprimée, la suppression des fichiers de segment de journal dans le stockage d'objets ne commence pas immédiatement. Il existe plutôt un intervalle de temps avec une valeur par défaut de 3 heures avant que la suppression de ces fichiers n'ait lieu. Vous pouvez modifier la configuration, confluent.tier.topic.delete.check.interval.ms, pour modifier la valeur de cet intervalle. Si vous supprimez une rubrique ou un cluster, vous pouvez également supprimer manuellement les objets dans le compartiment correspondant.
-
ACL sur les sujets internes du stockage hiérarchisé. Une bonne pratique recommandée pour les déploiements sur site consiste à activer un autorisateur ACL sur les rubriques internes utilisées pour le stockage hiérarchisé. Définissez des règles ACL pour limiter l’accès à ces données à l’utilisateur du courtier uniquement. Cela sécurise les sujets internes et empêche l'accès non autorisé aux données et métadonnées de stockage hiérarchisées.
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \ --add --allow-principal User:<kafka> --operation All --topic "_confluent-tier-state"

|
Remplacer l'utilisateur <kafka> avec le courtier principal réel dans votre déploiement.
|
Par exemple, la commande confluent-tier-state définit les ACL sur le sujet interne pour le stockage hiérarchisé. Actuellement, il n’existe qu’un seul sujet interne lié au stockage hiérarchisé. L'exemple crée une ACL qui fournit l'autorisation principale Kafka pour toutes les opérations sur la rubrique interne.