

Aperçu des performances et validation avec AFF A900 sur site
 Suggérer des modifications
Suggérer des modifications
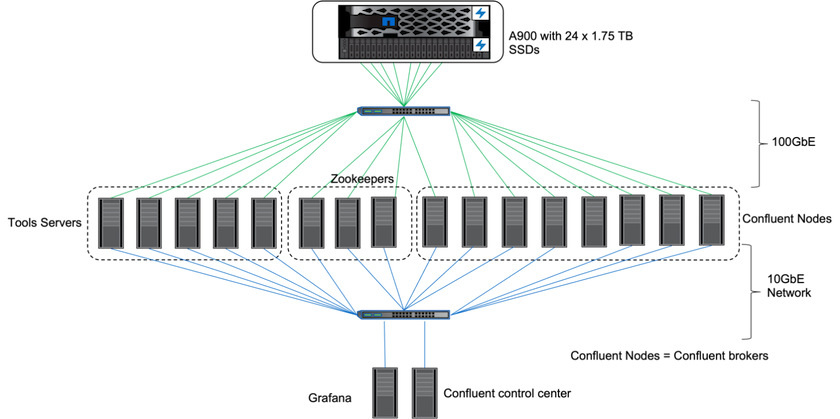
Sur site, nous avons utilisé le contrôleur de stockage NetApp AFF A900 avec ONTAP 9.12.1RC1 pour valider les performances et la mise à l'échelle d'un cluster Kafka. Nous avons utilisé le même banc d’essai que dans nos précédentes meilleures pratiques de stockage hiérarchisé avec ONTAP et AFF.
Nous avons utilisé Confluent Kafka 6.2.0 pour évaluer l' AFF A900. Le cluster comprend huit nœuds de courtier et trois nœuds de gardien de zoo. Pour les tests de performances, nous avons utilisé cinq nœuds de travail OMB.
Configuration de stockage
Nous avons utilisé des instances NetApp FlexGroups pour fournir un espace de noms unique pour les répertoires de journaux, simplifiant ainsi la récupération et la configuration. Nous avons utilisé NFSv4.1 et pNFS pour fournir un accès direct aux données des segments de journaux.
Réglage du client
Chaque client a monté l’instance FlexGroup avec la commande suivante.
mount -t nfs -o vers=4.1,nconnect=16 172.30.0.121:/kafka_vol01 /data/kafka_vol01
De plus, nous avons augmenté le max_session_slots` à partir de la valeur par défaut 64 à 180 . Cela correspond à la limite d'emplacement de session par défaut dans ONTAP.
Réglage du courtier Kafka
Afin de maximiser le débit du système testé, nous avons considérablement augmenté les paramètres par défaut pour certains pools de threads clés. Nous vous recommandons de suivre les meilleures pratiques de Confluent Kafka pour la plupart des configurations. Ce réglage a été utilisé pour maximiser la concurrence des E/S en attente vers le stockage. Ces paramètres peuvent être ajustés pour correspondre aux ressources de calcul et aux attributs de stockage de votre courtier.
num.io.threads=96 num.network.threads=96 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 queued.max.requests=2000
Méthodologie de test du générateur de charge de travail
Nous avons utilisé les mêmes configurations OMB que pour les tests cloud pour le pilote de débit et la configuration de rubrique.
-
Une instance FlexGroup a été provisionnée à l’aide d’Ansible sur un cluster AFF .
--- - name: Set up kafka broker processes hosts: localhost vars: ntap_hostname: 'hostname' ntap_username: 'user' ntap_password: 'password' size: 10 size_unit: tb vserver: vs1 state: present https: true export_policy: default volumes: - name: kafka_fg_vol01 aggr: ["aggr1_a", "aggr2_a", "aggr1_b", "aggr2_b"] path: /kafka_fg_vol01 tasks: - name: Edit volumes netapp.ontap.na_ontap_volume: state: "{{ state }}" name: "{{ item.name }}" aggr_list: "{{ item.aggr }}" aggr_list_multiplier: 8 size: "{{ size }}" size_unit: "{{ size_unit }}" vserver: "{{ vserver }}" snapshot_policy: none export_policy: default junction_path: "{{ item.path }}" qos_policy_group: none wait_for_completion: True hostname: "{{ ntap_hostname }}" username: "{{ ntap_username }}" password: "{{ ntap_password }}" https: "{{ https }}" validate_certs: false connection: local with_items: "{{ volumes }}" -
pNFS a été activé sur le SVM ONTAP .
vserver modify -vserver vs1 -v4.1-pnfs enabled -tcp-max-xfer-size 262144
-
La charge de travail a été déclenchée avec le pilote de débit utilisant la même configuration de charge de travail que pour Cloud Volumes ONTAP. Voir la section "Performances à l'état stable " ci-dessous. La charge de travail utilisait un facteur de réplication de 3, ce qui signifie que trois copies de segments de journaux étaient conservées dans NFS.
sudo bin/benchmark --drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Enfin, nous avons réalisé des mesures à l’aide d’un backlog pour évaluer la capacité des consommateurs à rattraper les derniers messages. L'OMB construit un backlog en mettant les consommateurs en pause au début d'une mesure. Cela produit trois phases distinctes : la création du backlog (trafic réservé aux producteurs), l'épuisement du backlog (une phase très axée sur les consommateurs dans laquelle les consommateurs rattrapent les événements manqués dans un sujet) et l'état stable. Voir la section "Performances extrêmes et exploration des limites de stockage " pour plus d'informations.
Performances à l'état stable
Nous avons évalué l' AFF A900 à l'aide de l'OpenMessaging Benchmark pour fournir une comparaison similaire à celle de Cloud Volumes ONTAP dans AWS et DAS dans AWS. Toutes les valeurs de performance représentent le débit du cluster Kafka au niveau du producteur et du consommateur.
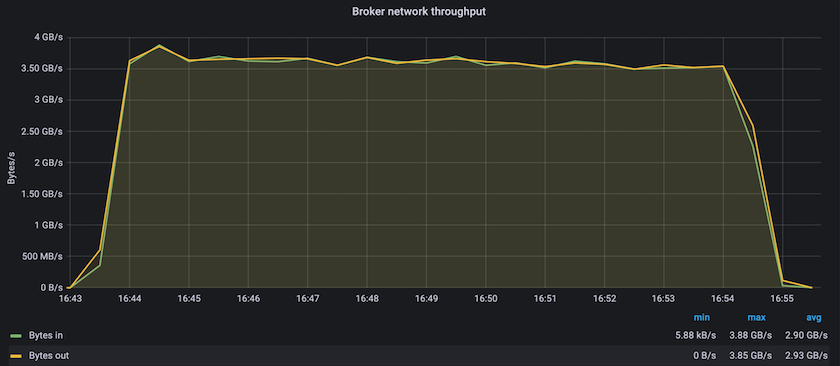
Les performances en régime permanent avec Confluent Kafka et l' AFF A900 ont atteint un débit moyen de plus de 3,4 Gbit/s pour les producteurs et les consommateurs. Cela représente plus de 3,4 millions de messages sur l’ensemble du cluster Kafka. En visualisant le débit soutenu en octets par seconde pour BrokerTopicMetrics, nous constatons les excellentes performances en régime permanent et le trafic pris en charge par l' AFF A900.
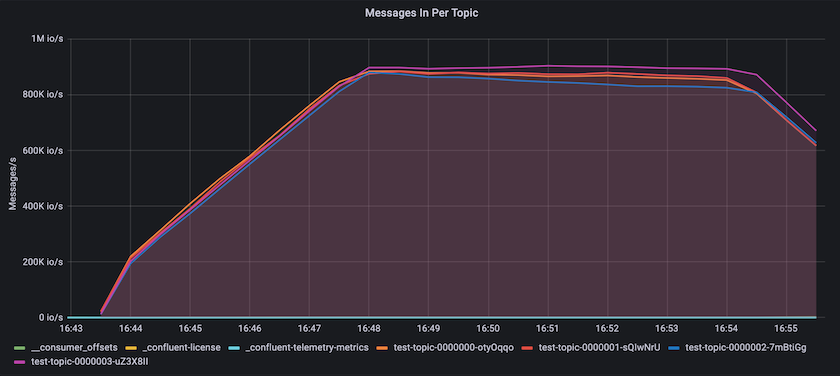
Cela correspond bien à la vue des messages délivrés par sujet. Le graphique suivant fournit une répartition par sujet. Dans la configuration testée, nous avons vu près de 900 000 messages par sujet sur quatre sujets.
Performances extrêmes et exploration des limites de stockage
Pour AFF, nous avons également testé avec OMB en utilisant la fonctionnalité backlog. La fonctionnalité de backlog suspend les abonnements des consommateurs pendant qu'un backlog d'événements est constitué dans le cluster Kafka. Au cours de cette phase, seul le trafic du producteur se produit, ce qui génère des événements qui sont validés dans les journaux. Cela émule le plus étroitement les flux de travail de traitement par lots ou d'analyse hors ligne ; dans ces flux de travail, les abonnements des consommateurs sont démarrés et doivent lire les données historiques qui ont déjà été expulsées du cache du courtier.
Pour comprendre les limites de stockage sur le débit du consommateur dans cette configuration, nous avons mesuré la phase réservée au producteur pour comprendre la quantité de trafic d'écriture que l'A900 pouvait absorber. Voir la section suivante "Guide de dimensionnement " pour comprendre comment exploiter ces données.
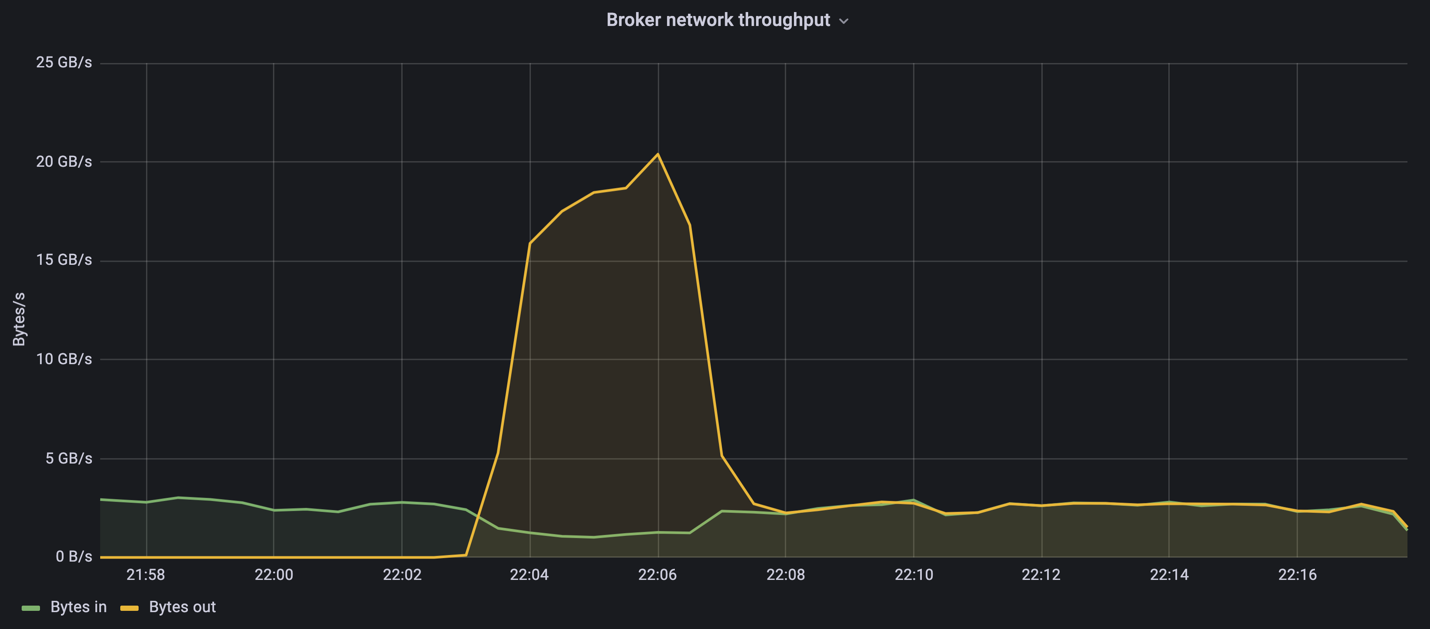
Au cours de la partie réservée aux producteurs de cette mesure, nous avons constaté un débit de pointe élevé qui a repoussé les limites des performances de l'A900 (lorsque les autres ressources du courtier n'étaient pas saturées et ne desservaient pas le trafic des producteurs et des consommateurs).

|
Nous avons augmenté la taille du message à 16 Ko pour cette mesure afin de limiter les frais généraux par message et de maximiser le débit de stockage vers les points de montage NFS. |
messageSize: 16384 consumerBacklogSizeGB: 4096
Le cluster Confluent Kafka a atteint un débit de production maximal de 4,03 Gbit/s.
18:12:23.833 [main] INFO WorkloadGenerator - Pub rate 257759.2 msg/s / 4027.5 MB/s | Pub err 0.0 err/s …
Une fois que l'OMB a terminé de remplir le backlog des événements, le trafic consommateur a été redémarré. Lors des mesures avec drainage du backlog, nous avons observé un débit consommateur maximal de plus de 20 Gbit/s sur tous les sujets. Le débit combiné du volume NFS stockant les données du journal OMB approchait environ 30 Gbit/s.
Guide de dimensionnement
Amazon Web Services propose une "guide des tailles" pour le dimensionnement et la mise à l'échelle des clusters Kafka.
Ce dimensionnement fournit une formule utile pour déterminer les besoins en débit de stockage de votre cluster Kafka :
Pour un débit agrégé produit dans le cluster de tcluster avec un facteur de réplication de r, le débit reçu par le stockage du courtier est le suivant :
t[storage] = t[cluster]/#brokers + t[cluster]/#brokers * (r-1)
= t[cluster]/#brokers * r
Cela peut être encore simplifié :
max(t[cluster]) <= max(t[storage]) * #brokers/r
L’utilisation de cette formule vous permet de sélectionner la plate-forme ONTAP appropriée à vos besoins en matière de niveau chaud Kafka.
Le tableau suivant explique le débit de production prévu pour l'A900 avec différents facteurs de réplication :
| Facteur de réplication | Débit du producteur (GPps) |
|---|---|
3 (mesuré) |
3,4 |
2 |
5,1 |
1 |
10,2 |