Aperçu des performances et validation dans AWS
 Suggérer des modifications
Suggérer des modifications
Un cluster Kafka avec la couche de stockage montée sur NetApp NFS a été évalué pour les performances dans le cloud AWS. Les exemples d’analyse comparative sont décrits dans les sections suivantes.
Kafka dans le cloud AWS avec NetApp Cloud Volumes ONTAP (paire haute disponibilité et nœud unique)
Un cluster Kafka avec NetApp Cloud Volumes ONTAP (paire HA) a été évalué pour ses performances dans le cloud AWS. Cette analyse comparative est décrite dans les sections suivantes.
Configuration architecturale
Le tableau suivant montre la configuration environnementale d’un cluster Kafka utilisant NAS.
| Composant de la plateforme | Configuration de l'environnement |
|---|---|
Kafka 3.2.3 |
|
Système d'exploitation sur tous les nœuds |
RHEL8.6 |
Instance NetApp Cloud Volumes ONTAP |
Instance de paire HA – m5dn.12xLarge x 2node Instance de nœud unique - m5dn.12xLarge x 1 nœud |
Configuration du volume de cluster NetApp ONTAP
-
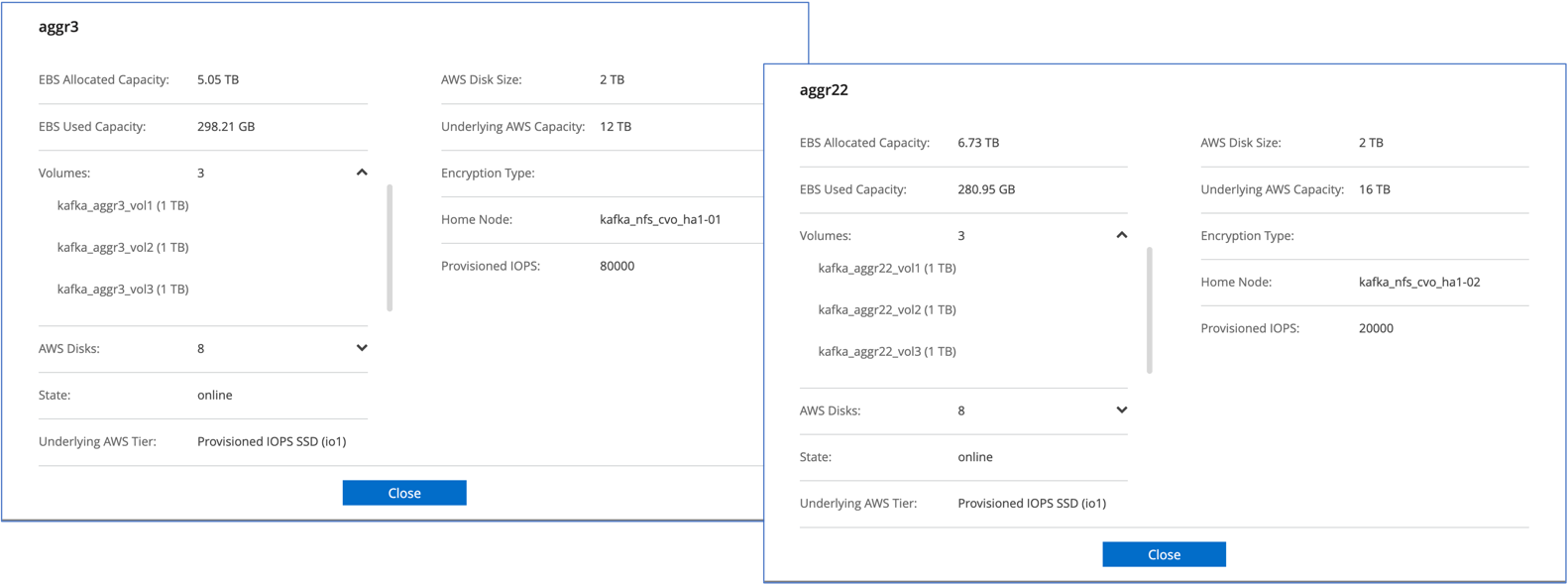
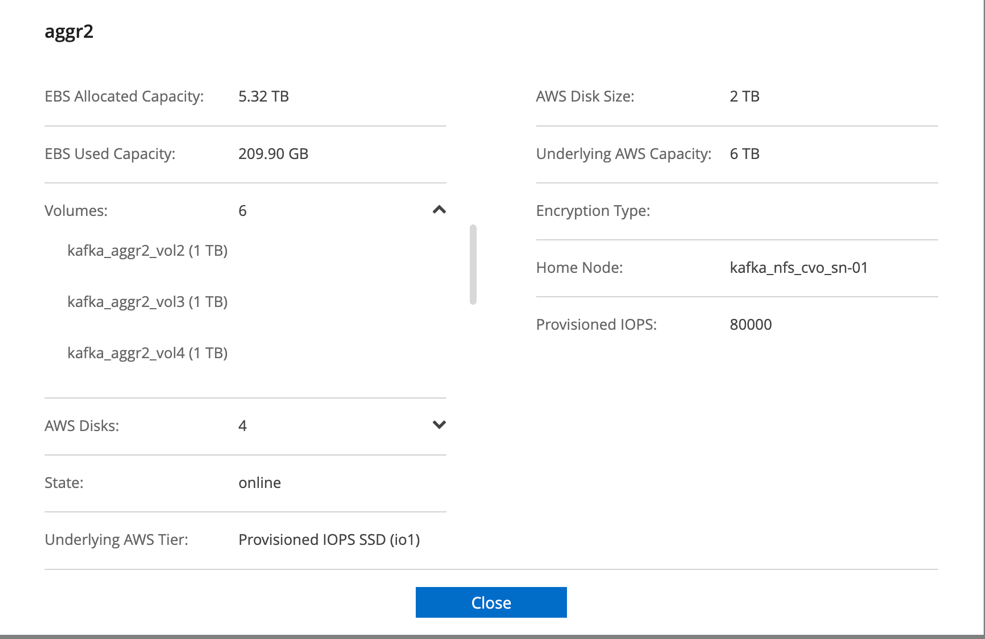
Pour la paire Cloud Volumes ONTAP HA, nous avons créé deux agrégats avec trois volumes sur chaque agrégat sur chaque contrôleur de stockage. Pour le nœud unique Cloud Volumes ONTAP , nous créons six volumes dans un agrégat.
-
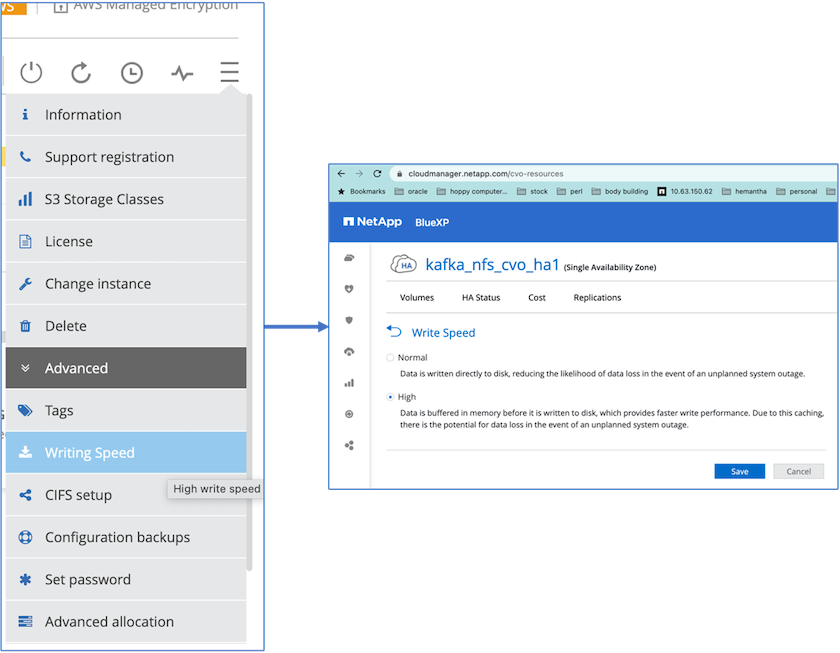
Pour obtenir de meilleures performances réseau, nous avons activé la mise en réseau à haut débit pour la paire HA et le nœud unique.
-
Nous avons remarqué que la NVRAM ONTAP avait plus d'IOPS, nous avons donc modifié les IOPS à 2350 pour le volume racine Cloud Volumes ONTAP . Le disque du volume racine dans Cloud Volumes ONTAP avait une taille de 47 Go. La commande ONTAP suivante concerne la paire HA et la même étape s’applique au nœud unique.
statistics start -object vnvram -instance vnvram -counter backing_store_iops -sample-id sample_555 kafka_nfs_cvo_ha1::*> statistics show -sample-id sample_555 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-01 Counter Value -------------------------------- -------------------------------- backing_store_iops 1479 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-02 Counter Value -------------------------------- -------------------------------- backing_store_iops 1210 2 entries were displayed. kafka_nfs_cvo_ha1::*>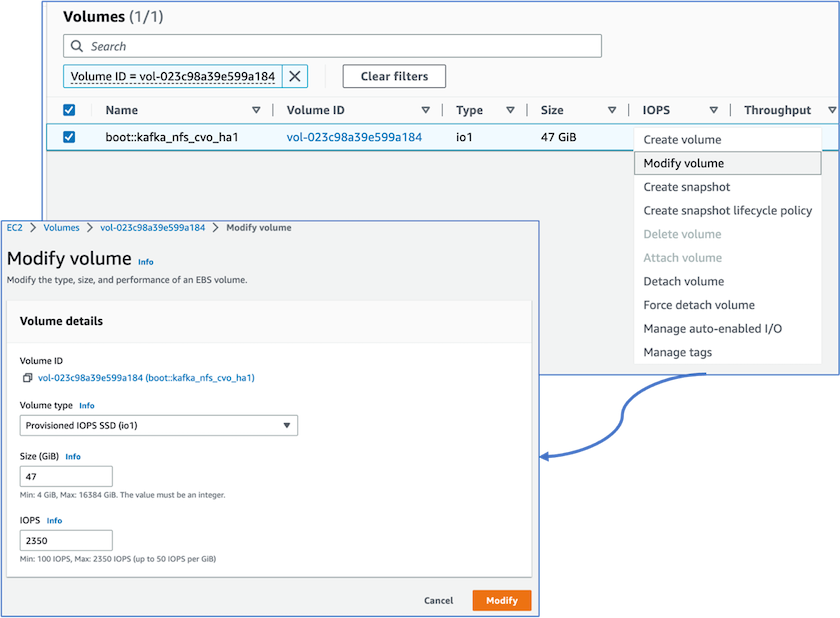
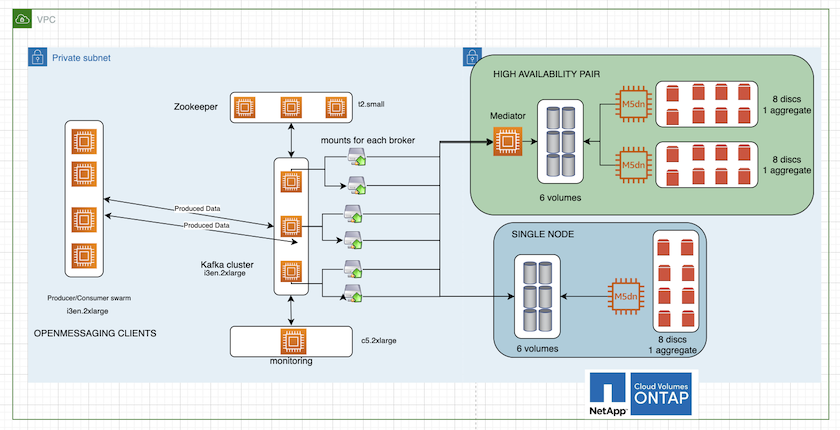
La figure suivante illustre l’architecture d’un cluster Kafka basé sur NAS.
-
Calculer. Nous avons utilisé un cluster Kafka à trois nœuds avec un ensemble zookeeper à trois nœuds exécuté sur des serveurs dédiés. Chaque courtier disposait de deux points de montage NFS sur un seul volume sur l'instance Cloud Volumes ONTAP via un LIF dédié.
-
Surveillance. Nous avons utilisé deux nœuds pour une combinaison Prometheus-Grafana. Pour générer des charges de travail, nous avons utilisé un cluster à trois nœuds distinct qui pouvait produire et consommer sur ce cluster Kafka.
-
Stockage. Nous avons utilisé une instance ONTAP de volumes Cloud à paire HA avec un volume AWS-EBS GP3 de 6 To monté sur l'instance. Le volume a ensuite été exporté vers le courtier Kafka avec un montage NFS.
Configurations d'analyse comparative d'OpenMessage
-
Pour de meilleures performances NFS, nous avons besoin de plus de connexions réseau entre le serveur NFS et le client NFS, qui peuvent être créées à l'aide de nconnect. Montez les volumes NFS sur les nœuds du courtier avec l'option nconnect en exécutant la commande suivante :
[root@ip-172-30-0-121 ~]# cat /etc/fstab UUID=eaa1f38e-de0f-4ed5-a5b5-2fa9db43bb38/xfsdefaults00 /dev/nvme1n1 /mnt/data-1 xfs defaults,noatime,nodiscard 0 0 /dev/nvme2n1 /mnt/data-2 xfs defaults,noatime,nodiscard 0 0 172.30.0.233:/kafka_aggr3_vol1 /kafka_aggr3_vol1 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol2 /kafka_aggr3_vol2 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol3 /kafka_aggr3_vol3 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol1 /kafka_aggr22_vol1 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol2 /kafka_aggr22_vol2 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol3 /kafka_aggr22_vol3 nfs defaults,nconnect=16 0 0 [root@ip-172-30-0-121 ~]# mount -a [root@ip-172-30-0-121 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 31G 0 31G 0% /dev tmpfs 31G 249M 31G 1% /run tmpfs 31G 0 31G 0% /sys/fs/cgroup /dev/nvme0n1p2 10G 2.8G 7.2G 28% / /dev/nvme1n1 2.3T 248G 2.1T 11% /mnt/data-1 /dev/nvme2n1 2.3T 245G 2.1T 11% /mnt/data-2 172.30.0.233:/kafka_aggr3_vol1 1.0T 12G 1013G 2% /kafka_aggr3_vol1 172.30.0.233:/kafka_aggr3_vol2 1.0T 5.5G 1019G 1% /kafka_aggr3_vol2 172.30.0.233:/kafka_aggr3_vol3 1.0T 8.9G 1016G 1% /kafka_aggr3_vol3 172.30.0.242:/kafka_aggr22_vol1 1.0T 7.3G 1017G 1% /kafka_aggr22_vol1 172.30.0.242:/kafka_aggr22_vol2 1.0T 6.9G 1018G 1% /kafka_aggr22_vol2 172.30.0.242:/kafka_aggr22_vol3 1.0T 5.9G 1019G 1% /kafka_aggr22_vol3 tmpfs 6.2G 0 6.2G 0% /run/user/1000 [root@ip-172-30-0-121 ~]#
-
Vérifiez les connexions réseau dans Cloud Volumes ONTAP. La commande ONTAP suivante est utilisée à partir du nœud Cloud Volumes ONTAP unique. La même étape s’applique à la paire Cloud Volumes ONTAP HA.
Last login time: 1/20/2023 00:16:29 kafka_nfs_cvo_sn::> network connections active show -service nfs* -fields remote-host node cid vserver remote-host ------------------- ---------- -------------------- ------------ kafka_nfs_cvo_sn-01 2315762628 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762629 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762630 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762631 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762632 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762633 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762634 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762635 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762636 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762637 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762639 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762640 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762641 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762642 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762643 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762644 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762645 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762646 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762647 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762648 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762649 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762650 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762651 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762652 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762653 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762656 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762657 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762658 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762659 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762660 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762661 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762662 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762663 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762664 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762665 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762666 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762667 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762668 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762669 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762670 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762671 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762672 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762673 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762674 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762676 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762677 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762678 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762679 svm_kafka_nfs_cvo_sn 172.30.0.223 48 entries were displayed. kafka_nfs_cvo_sn::>
-
Nous utilisons le Kafka suivant
server.propertiesdans tous les courtiers Kafka pour la paire Cloud Volumes ONTAP HA. Lelog.dirsla propriété est différente pour chaque courtier, et les propriétés restantes sont communes aux courtiers. Pour broker1, lelog.dirsla valeur est la suivante :[root@ip-172-30-0-121 ~]# cat /opt/kafka/config/server.properties broker.id=0 advertised.listeners=PLAINTEXT://172.30.0.121:9092 #log.dirs=/mnt/data-1/d1,/mnt/data-1/d2,/mnt/data-1/d3,/mnt/data-2/d1,/mnt/data-2/d2,/mnt/data-2/d3 log.dirs=/kafka_aggr3_vol1/broker1,/kafka_aggr3_vol2/broker1,/kafka_aggr3_vol3/broker1,/kafka_aggr22_vol1/broker1,/kafka_aggr22_vol2/broker1,/kafka_aggr22_vol3/broker1 zookeeper.connect=172.30.0.12:2181,172.30.0.30:2181,172.30.0.178:2181 num.network.threads=64 num.io.threads=64 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 replica.fetch.max.bytes=524288000 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 [root@ip-172-30-0-121 ~]#
-
Pour broker2, le
log.dirsla valeur de la propriété est la suivante :log.dirs=/kafka_aggr3_vol1/broker2,/kafka_aggr3_vol2/broker2,/kafka_aggr3_vol3/broker2,/kafka_aggr22_vol1/broker2,/kafka_aggr22_vol2/broker2,/kafka_aggr22_vol3/broker2
-
Pour broker3, le
log.dirsla valeur de la propriété est la suivante :log.dirs=/kafka_aggr3_vol1/broker3,/kafka_aggr3_vol2/broker3,/kafka_aggr3_vol3/broker3,/kafka_aggr22_vol1/broker3,/kafka_aggr22_vol2/broker3,/kafka_aggr22_vol3/broker3
-
-
Pour le nœud unique Cloud Volumes ONTAP , Kafka
servers.propertiesest le même que pour la paire Cloud Volumes ONTAP HA, à l'exception dulog.dirspropriété.-
Pour broker1, le
log.dirsla valeur est la suivante :log.dirs=/kafka_aggr2_vol1/broker1,/kafka_aggr2_vol2/broker1,/kafka_aggr2_vol3/broker1,/kafka_aggr2_vol4/broker1,/kafka_aggr2_vol5/broker1,/kafka_aggr2_vol6/broker1
-
Pour broker2, le
log.dirsla valeur est la suivante :log.dirs=/kafka_aggr2_vol1/broker2,/kafka_aggr2_vol2/broker2,/kafka_aggr2_vol3/broker2,/kafka_aggr2_vol4/broker2,/kafka_aggr2_vol5/broker2,/kafka_aggr2_vol6/broker2
-
Pour broker3, le
log.dirsla valeur de la propriété est la suivante :log.dirs=/kafka_aggr2_vol1/broker3,/kafka_aggr2_vol2/broker3,/kafka_aggr2_vol3/broker3,/kafka_aggr2_vol4/broker3,/kafka_aggr2_vol5/broker3,/kafka_aggr2_vol6/broker3
-
-
La charge de travail dans l'OMB est configurée avec les propriétés suivantes :
(/opt/benchmark/workloads/1-topic-100-partitions-1kb.yaml).topics: 4 partitionsPerTopic: 100 messageSize: 32768 useRandomizedPayloads: true randomBytesRatio: 0.5 randomizedPayloadPoolSize: 100 subscriptionsPerTopic: 1 consumerPerSubscription: 80 producersPerTopic: 40 producerRate: 1000000 consumerBacklogSizeGB: 0 testDurationMinutes: 5
Le
messageSizepeut varier pour chaque cas d'utilisation. Dans notre test de performance, nous avons utilisé 3K.Nous avons utilisé deux pilotes différents, Sync ou Throughput, d'OMB pour générer la charge de travail sur le cluster Kafka.
-
Le fichier yaml utilisé pour les propriétés du pilote de synchronisation est le suivant
(/opt/benchmark/driver- kafka/kafka-sync.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 flush.messages=1 flush.ms=0 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
Le fichier yaml utilisé pour les propriétés du pilote de débit est le suivant
(/opt/benchmark/driver- kafka/kafka-throughput.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 default.api.timeout.ms=1200000 request.timeout.ms=1200000 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
Méthodologie des tests
-
Un cluster Kafka a été provisionné conformément à la spécification décrite ci-dessus à l'aide de Terraform et Ansible. Terraform est utilisé pour créer l'infrastructure à l'aide d'instances AWS pour le cluster Kafka et Ansible construit le cluster Kafka sur celles-ci.
-
Une charge de travail OMB a été déclenchée avec la configuration de charge de travail décrite ci-dessus et le pilote Sync.
Sudo bin/benchmark –drivers driver-kafka/kafka- sync.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Une autre charge de travail a été déclenchée avec le pilote de débit avec la même configuration de charge de travail.
sudo bin/benchmark –drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
Observation
Deux types de pilotes différents ont été utilisés pour générer des charges de travail afin d'évaluer les performances d'une instance Kafka exécutée sur NFS. La différence entre les pilotes est la propriété de vidage du journal.
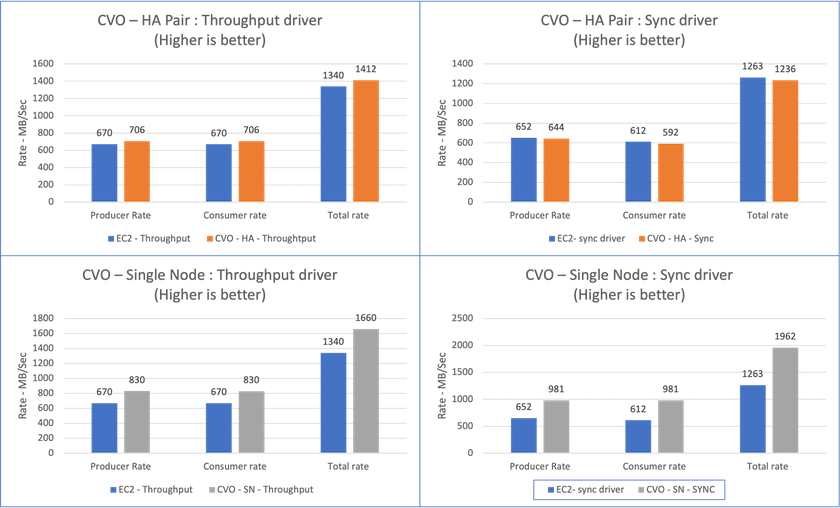
Pour une paire Cloud Volumes ONTAP HA :
-
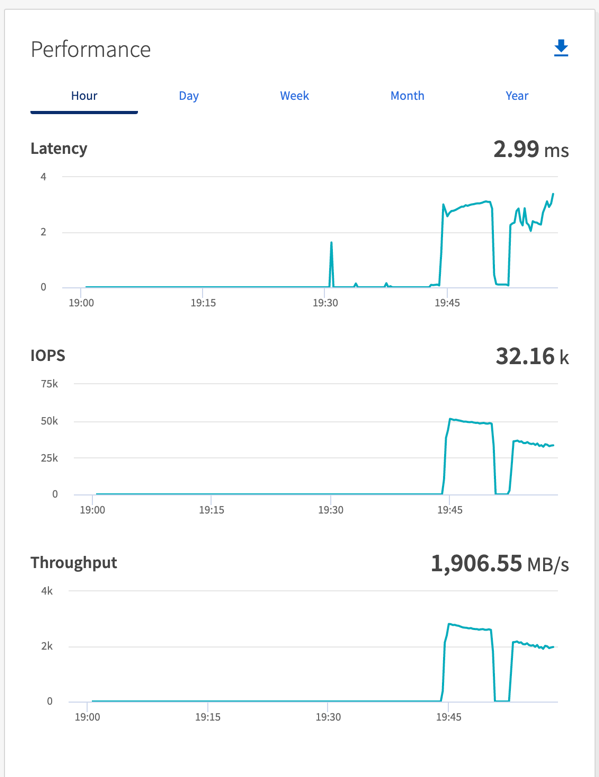
Débit total généré de manière cohérente par le pilote Sync : environ 1 236 Mo/s.
-
Débit total généré pour le pilote de débit : pic ~ 1 412 Mo/s.
Pour un seul nœud Cloud Volumes ONTAP :
-
Débit total généré de manière cohérente par le pilote Sync : ~ 1 962 Mo/s.
-
Débit total généré par le pilote de débit : pic ~ 1 660 Mo/s
Le pilote de synchronisation peut générer un débit constant lorsque les journaux sont vidés instantanément sur le disque, tandis que le pilote de débit génère des rafales de débit lorsque les journaux sont validés sur le disque en masse.
Ces numéros de débit sont générés pour la configuration AWS donnée. Pour des exigences de performances plus élevées, les types d'instances peuvent être mis à l'échelle et optimisés davantage pour de meilleurs chiffres de débit. Le débit total ou le taux total est la combinaison du taux du producteur et du taux du consommateur.
Assurez-vous de vérifier le débit de stockage lorsque vous effectuez une analyse comparative du débit ou du pilote de synchronisation.