Validation fonctionnelle - Correction d'un changement de nom idiot
 Suggérer des modifications
Suggérer des modifications
Pour la validation fonctionnelle, nous avons montré qu'un cluster Kafka avec un montage NFSv3 pour le stockage ne parvient pas à effectuer des opérations Kafka comme la redistribution de partition, alors qu'un autre cluster monté sur NFSv4 avec le correctif peut effectuer les mêmes opérations sans aucune interruption.
Configuration de validation
L'installation est exécutée sur AWS. Le tableau suivant présente les différents composants de la plateforme et la configuration environnementale utilisés pour la validation.
| Composant de la plateforme | Configuration de l'environnement |
|---|---|
Plateforme Confluent version 7.2.1 |
|
Système d'exploitation sur tous les nœuds |
RHEL 8.7 ou version ultérieure |
Instance NetApp Cloud Volumes ONTAP |
Instance à nœud unique – M5.2xLarge |
La figure suivante montre la configuration architecturale de cette solution.
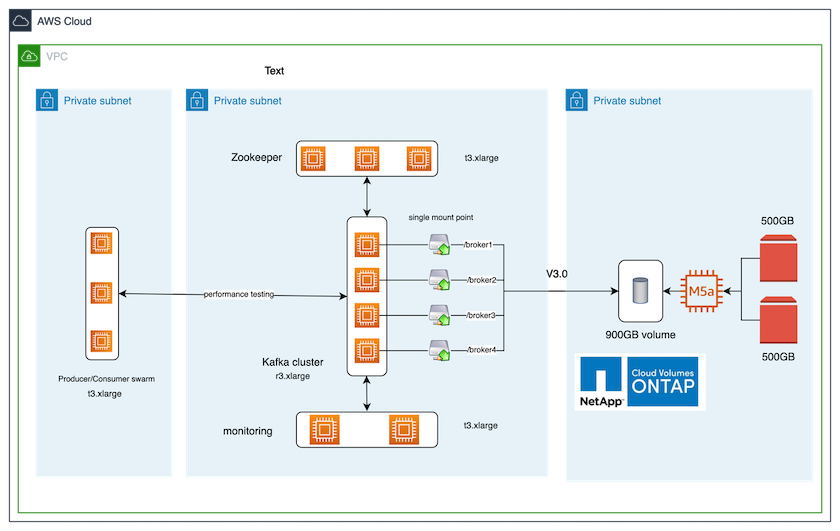
Flux architectural
-
Calculer. Nous avons utilisé un cluster Kafka à quatre nœuds avec un ensemble zookeeper à trois nœuds exécuté sur des serveurs dédiés.
-
Surveillance. Nous avons utilisé deux nœuds pour une combinaison Prometheus-Grafana.
-
Charge de travail. Pour générer des charges de travail, nous avons utilisé un cluster à trois nœuds distinct qui peut produire et consommer à partir de ce cluster Kafka.
-
Stockage. Nous avons utilisé une instance ONTAP de volumes NetApp Cloud à nœud unique avec deux volumes AWS-EBS GP2 de 500 Go attachés à l'instance. Ces volumes ont ensuite été exposés au cluster Kafka en tant que volume NFSv4.1 unique via un LIF.
Les propriétés par défaut de Kafka ont été choisies pour tous les serveurs. La même chose a été faite pour l’essaim de gardiens de zoo.
Méthodologie des tests
-
Mise à jour
-is-preserve-unlink-enabled trueau volume Kafka, comme suit :aws-shantanclastrecall-aws::*> volume create -vserver kafka_svm -volume kafka_fg_vol01 -aggregate kafka_aggr -size 3500GB -state online -policy kafka_policy -security-style unix -unix-permissions 0777 -junction-path /kafka_fg_vol01 -type RW -is-preserve-unlink-enabled true [Job 32] Job succeeded: Successful
-
Deux clusters Kafka similaires ont été créés avec la différence suivante :
-
Groupe 1. Le serveur backend NFS v4.1 exécutant la version ONTAP 9.12.1 prête pour la production était hébergé par une instance NetApp CVO. RHEL 8.7/RHEL 9.1 ont été installés sur les courtiers.
-
Groupe 2. Le serveur NFS principal était un serveur Linux NFSv3 générique créé manuellement.
-
-
Un sujet de démonstration a été créé sur les deux clusters Kafka.
Groupe 1 :

Groupe 2 :

-
Les données ont été chargées dans ces rubriques nouvellement créées pour les deux clusters. Cela a été fait en utilisant la boîte à outils producer-perf-test fournie dans le package Kafka par défaut :
./kafka-producer-perf-test.sh --topic __a_demo_topic --throughput -1 --num-records 3000000 --record-size 1024 --producer-props acks=all bootstrap.servers=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092
-
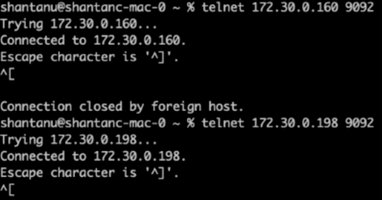
Un contrôle de santé a été effectué pour broker-1 pour chacun des clusters à l'aide de telnet :
-
telnet
172.30.0.160 9092 -
telnet
172.30.0.198 9092Un contrôle de santé réussi pour les courtiers sur les deux clusters est présenté dans la capture d'écran suivante :
-
-
Pour déclencher la condition d’échec qui provoque le blocage des clusters Kafka utilisant des volumes de stockage NFSv3, nous avons lancé le processus de réaffectation de partition sur les deux clusters. La réaffectation des partitions a été effectuée à l'aide de
kafka-reassign-partitions.sh. Le processus détaillé est le suivant :-
Pour réaffecter les partitions d'un sujet dans un cluster Kafka, nous avons généré la configuration de réaffectation proposée JSON (cela a été effectué pour les deux clusters).
kafka-reassign-partitions --bootstrap-server=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092 --broker-list "1,2,3,4" --topics-to-move-json-file /tmp/topics.json --generate
-
Le JSON de réaffectation généré a ensuite été enregistré dans
/tmp/reassignment- file.json. -
Le processus de réaffectation de partition réel a été déclenché par la commande suivante :
kafka-reassign-partitions --bootstrap-server=172.30.0.198:9092,172.30.0.163:9092,172.30.0.221:9092,172.30.0.204:9092 --reassignment-json-file /tmp/reassignment-file.json –execute
-
-
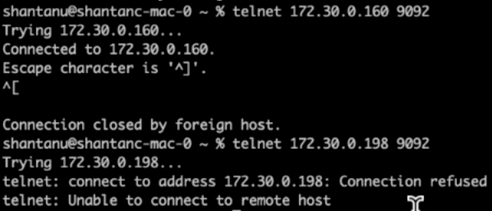
Quelques minutes après la fin de la réaffectation, un autre contrôle de santé sur les courtiers a montré que le cluster utilisant des volumes de stockage NFSv3 avait rencontré un problème de renommage stupide et s'était écrasé, tandis que le cluster 1 utilisant des volumes de stockage NetApp ONTAP NFSv4.1 avec le correctif a continué ses opérations sans aucune interruption.
-
Cluster1-Broker-1 est actif.
-
Cluster2-broker-1 est mort.
-
-
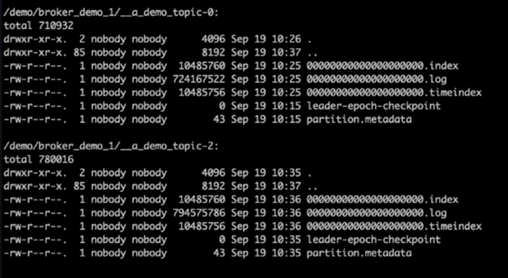
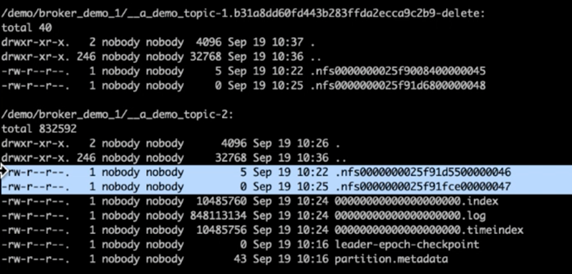
Après avoir vérifié les répertoires de journaux Kafka, il était clair que le cluster 1 utilisant les volumes de stockage NetApp ONTAP NFSv4.1 avec le correctif avait une attribution de partition propre, tandis que le cluster 2 utilisant le stockage NFSv3 générique ne l'avait pas en raison de problèmes de renommage stupides, ce qui a conduit au crash. L'image suivante montre le rééquilibrage des partitions du cluster 2, qui a entraîné un problème de renommage stupide sur le stockage NFSv3.
L'image suivante montre un rééquilibrage de partition propre du cluster 1 à l'aide du stockage NetApp NFSv4.1.