Pourquoi NetApp NFS pour les charges de travail Kafka ?
 Suggérer des modifications
Suggérer des modifications
Maintenant qu’il existe une solution au problème de renommage stupide dans le stockage NFS avec Kafka, vous pouvez créer des déploiements robustes qui exploitent le stockage NetApp ONTAP pour votre charge de travail Kafka. Non seulement cela réduit considérablement les frais opérationnels, mais cela apporte également les avantages suivants à vos clusters Kafka :
-
Utilisation réduite du processeur sur les courtiers Kafka. L'utilisation d'un stockage NetApp ONTAP désagrégé sépare les opérations d'E/S de disque du courtier et réduit ainsi son empreinte CPU.
-
Temps de récupération du courtier plus rapide. Étant donné que le stockage NetApp ONTAP désagrégé est partagé entre les nœuds de courtier Kafka, une nouvelle instance de calcul peut remplacer un courtier défectueux à tout moment en une fraction du temps par rapport aux déploiements Kafka conventionnels sans reconstruire les données.
-
Efficacité de stockage. Étant donné que la couche de stockage de l'application est désormais provisionnée via NetApp ONTAP, les clients peuvent bénéficier de tous les avantages de l'efficacité du stockage offerts par ONTAP, tels que la compression des données en ligne, la déduplication et le compactage.
Ces avantages ont été testés et validés dans des cas de test que nous discutons en détail dans cette section.
Utilisation réduite du processeur sur le courtier Kafka
Nous avons découvert que l'utilisation globale du processeur est inférieure à celle de son homologue DAS lorsque nous avons exécuté des charges de travail similaires sur deux clusters Kafka distincts qui étaient identiques dans leurs spécifications techniques mais différaient dans leurs technologies de stockage. Non seulement l’utilisation globale du processeur est plus faible lorsque le cluster Kafka utilise le stockage ONTAP , mais l’augmentation de l’utilisation du processeur a démontré un gradient plus doux que dans un cluster Kafka basé sur DAS.
Configuration architecturale
Le tableau suivant montre la configuration environnementale utilisée pour démontrer l’utilisation réduite du processeur.
| Composant de la plateforme | Configuration de l'environnement |
|---|---|
Outil d'analyse comparative Kafka 3.2.3 : OpenMessaging |
|
Système d'exploitation sur tous les nœuds |
RHEL 8.7 ou version ultérieure |
Instance NetApp Cloud Volumes ONTAP |
Instance à nœud unique – M5.2xLarge |
Outil d'analyse comparative
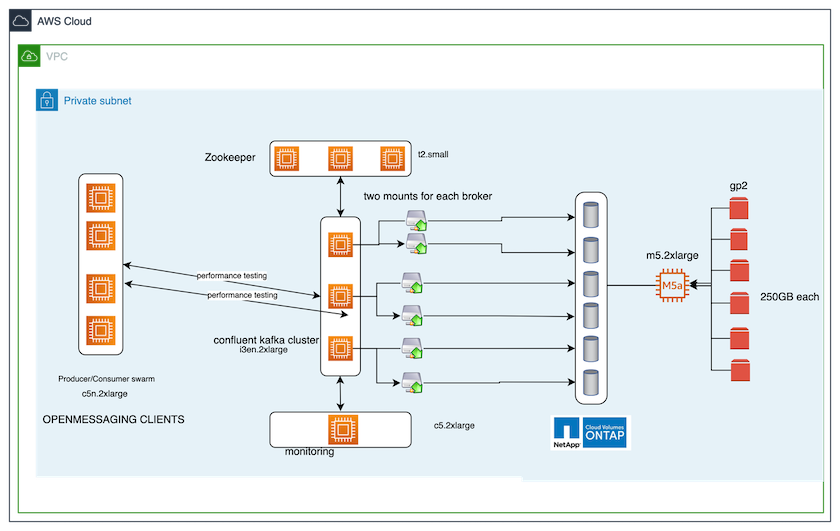
L'outil d'analyse comparative utilisé dans ce cas de test est le "OpenMessaging" cadre. OpenMessaging est indépendant des fournisseurs et de la langue ; il fournit des directives sectorielles pour la finance, le commerce électronique, l'IoT et le big data ; et il aide à développer des applications de messagerie et de streaming sur des systèmes et des plates-formes hétérogènes. La figure suivante illustre l’interaction des clients OpenMessaging avec un cluster Kafka.
-
Calculer. Nous avons utilisé un cluster Kafka à trois nœuds avec un ensemble zookeeper à trois nœuds exécuté sur des serveurs dédiés. Chaque courtier disposait de deux points de montage NFSv4.1 sur un seul volume sur l'instance NetApp CVO via un LIF dédié.
-
Surveillance. Nous avons utilisé deux nœuds pour une combinaison Prometheus-Grafana. Pour générer des charges de travail, nous disposons d'un cluster distinct à trois nœuds qui peut produire et consommer à partir de ce cluster Kafka.
-
Stockage. Nous avons utilisé une instance ONTAP de volumes NetApp Cloud à nœud unique avec six volumes AWS-EBS GP2 de 250 Go montés sur l'instance. Ces volumes ont ensuite été exposés au cluster Kafka sous forme de six volumes NFSv4.1 via des LIF dédiés.
-
Configuration. Les deux éléments configurables dans ce cas de test étaient les courtiers Kafka et les charges de travail OpenMessaging.
-
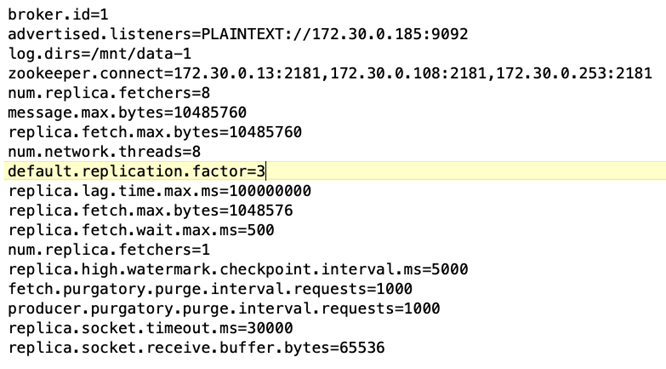
Configuration du courtier. Les spécifications suivantes ont été sélectionnées pour les courtiers Kafka. Nous avons utilisé un facteur de réplication de 3 pour toutes les mesures, comme indiqué ci-dessous.
-
-
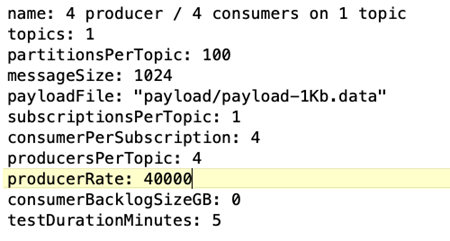
Configuration de la charge de travail du benchmark OpenMessaging (OMB). Les spécifications suivantes ont été fournies. Nous avons spécifié un taux de producteur cible, mis en évidence ci-dessous.
Méthodologie des tests
-
Deux clusters similaires ont été créés, chacun disposant de son propre ensemble d'essaims de clusters d'analyse comparative.
-
Groupe 1. Cluster Kafka basé sur NFS.
-
Groupe 2. Cluster Kafka basé sur DAS.
-
-
À l’aide d’une commande OpenMessaging, des charges de travail similaires ont été déclenchées sur chaque cluster.
sudo bin/benchmark --drivers driver-kafka/kafka-group-all.yaml workloads/1-topic-100-partitions-1kb.yaml
-
La configuration du taux de production a été augmentée en quatre itérations et l'utilisation du processeur a été enregistrée avec Grafana. Le taux de production a été fixé aux niveaux suivants :
-
10 000
-
40 000
-
80 000
-
100 000
-
Observation
L’utilisation du stockage NetApp NFS avec Kafka présente deux avantages principaux :
-
Vous pouvez réduire l’utilisation du processeur de près d’un tiers. L'utilisation globale du processeur sous des charges de travail similaires était inférieure pour NFS par rapport aux SSD DAS ; les économies varient de 5 % pour des taux de production inférieurs à 32 % pour des taux de production plus élevés.
-
Une réduction de trois fois de la dérive d'utilisation du processeur à des taux de production plus élevés. Comme prévu, il y a eu une tendance à la hausse de l’utilisation du processeur à mesure que les taux de production ont augmenté. Cependant, l'utilisation du processeur sur les courtiers Kafka utilisant DAS est passée de 31 % pour le taux de production inférieur à 70 % pour le taux de production supérieur, soit une augmentation de 39 %. Cependant, avec un backend de stockage NFS, l'utilisation du processeur est passée de 26 % à 38 %, soit une augmentation de 12 %.
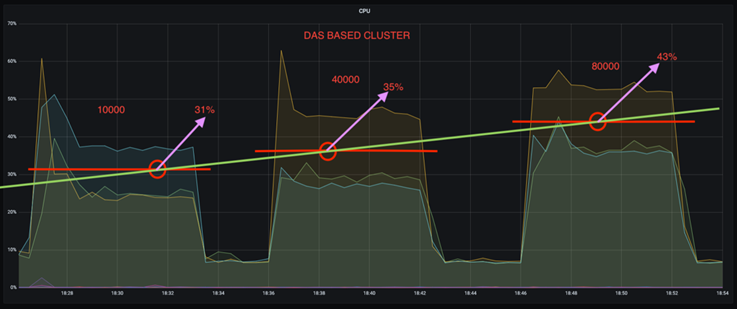
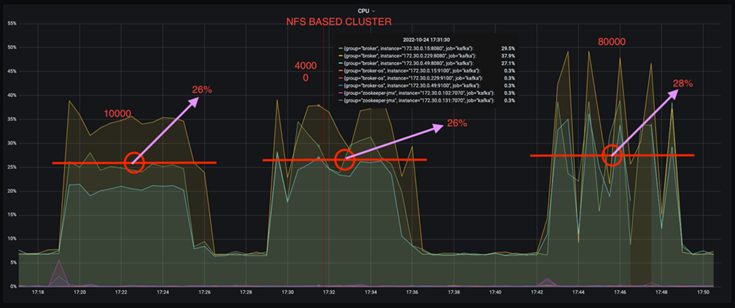
De plus, à 100 000 messages, DAS affiche une utilisation du processeur supérieure à celle d'un cluster NFS.
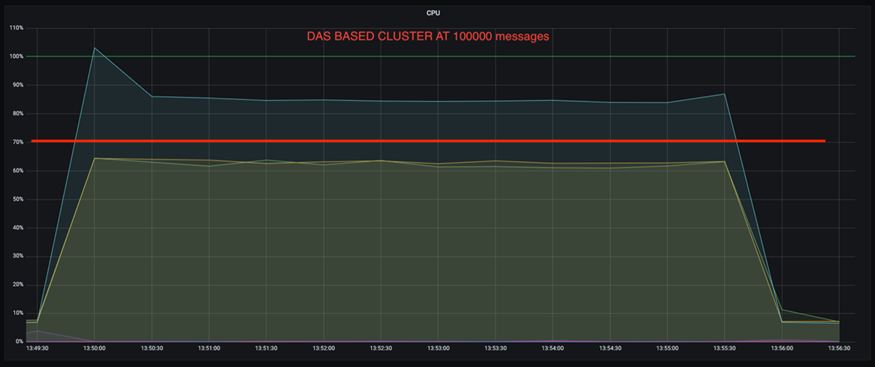
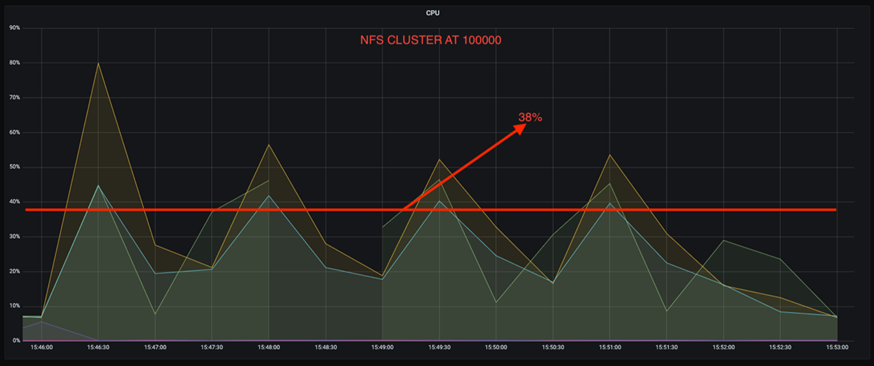
Récupération plus rapide des courtiers
Nous avons découvert que les courtiers Kafka récupèrent plus rapidement lorsqu’ils utilisent un stockage NetApp NFS partagé. Lorsqu'un courtier tombe en panne dans un cluster Kafka, ce courtier peut être remplacé par un courtier sain avec le même ID de courtier. Après avoir effectué ce cas de test, nous avons constaté que, dans le cas d'un cluster Kafka basé sur DAS, le cluster reconstruit les données sur un courtier sain nouvellement ajouté, ce qui prend du temps. Dans le cas d'un cluster Kafka basé sur NetApp NFS, le courtier de remplacement continue de lire les données du répertoire de journaux précédent et récupère beaucoup plus rapidement.
Configuration architecturale
Le tableau suivant montre la configuration environnementale d’un cluster Kafka utilisant NAS.
| Composant de la plateforme | Configuration de l'environnement |
|---|---|
Kafka 3.2.3 |
|
Système d'exploitation sur tous les nœuds |
RHEL8.7 ou version ultérieure |
Instance NetApp Cloud Volumes ONTAP |
Instance à nœud unique – M5.2xLarge |
La figure suivante illustre l’architecture d’un cluster Kafka basé sur NAS.
-
Calculer. Un cluster Kafka à trois nœuds avec un ensemble zookeeper à trois nœuds exécuté sur des serveurs dédiés. Chaque courtier dispose de deux points de montage NFS sur un seul volume sur l'instance NetApp CVO via un LIF dédié.
-
Surveillance. Deux nœuds pour une combinaison Prometheus-Grafana. Pour générer des charges de travail, nous utilisons un cluster à trois nœuds distinct qui peut produire et consommer sur ce cluster Kafka.
-
Stockage. Une instance ONTAP de volumes NetApp Cloud à nœud unique avec six volumes AWS-EBS GP2 de 250 Go montés sur l'instance. Ces volumes sont ensuite exposés au cluster Kafka sous forme de six volumes NFS via des LIF dédiés.
-
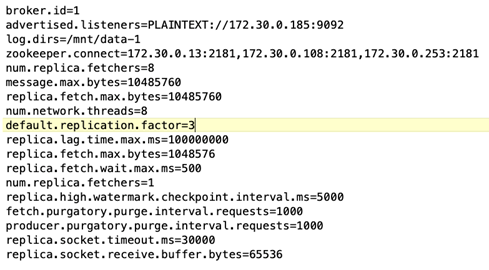
Configuration du courtier. Le seul élément configurable dans ce cas de test sont les courtiers Kafka. Les spécifications suivantes ont été sélectionnées pour les courtiers Kafka. Le
replica.lag.time.mx.msest défini sur une valeur élevée car cela détermine la vitesse à laquelle un nœud particulier est retiré de la liste ISR. Lorsque vous basculez entre des nœuds défectueux et sains, vous ne souhaitez pas que cet ID de courtier soit exclu de la liste ISR.
Méthodologie des tests
-
Deux clusters similaires ont été créés :
-
Un cluster confluent basé sur EC2.
-
Un cluster confluent basé sur NetApp NFS.
-
-
Un nœud Kafka de secours a été créé avec une configuration identique aux nœuds du cluster Kafka d'origine.
-
Sur chacun des clusters, un exemple de sujet a été créé et environ 110 Go de données ont été renseignés sur chacun des courtiers.
-
Cluster basé sur EC2. Un répertoire de données de courtier Kafka est mappé sur
/mnt/data-2(Dans la figure suivante, Broker-1 du cluster1 [terminal gauche]). -
* Cluster basé sur NetApp NFS.* Un répertoire de données de courtier Kafka est monté sur un point NFS
/mnt/data(Dans la figure suivante, Broker-1 du cluster2 [terminal de droite]).
-
-
Dans chacun des clusters, Broker-1 a été arrêté pour déclencher un processus de récupération de courtier ayant échoué.
-
Une fois le courtier terminé, l'adresse IP du courtier a été attribuée comme adresse IP secondaire au courtier de secours. Cela était nécessaire car un courtier dans un cluster Kafka est identifié par les éléments suivants :
-
Adresse IP. Attribué en réaffectant l'IP du courtier défaillant au courtier de secours.
-
Identifiant du courtier. Ceci a été configuré dans le courtier de secours
server.properties.
-
-
Lors de l'attribution de l'IP, le service Kafka a été démarré sur le courtier de secours.
-
Après un certain temps, les journaux du serveur ont été extraits pour vérifier le temps nécessaire à la création des données sur le nœud de remplacement du cluster.
Observation
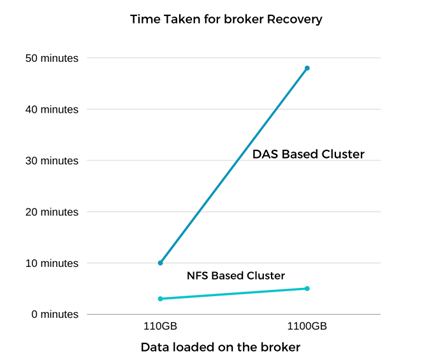
La récupération du courtier Kafka a été presque neuf fois plus rapide. Le temps nécessaire pour récupérer un nœud de courtier défaillant s'est avéré nettement plus rapide lors de l'utilisation du stockage partagé NetApp NFS par rapport à l'utilisation de SSD DAS dans un cluster Kafka. Pour 1 To de données de sujet, le temps de récupération pour un cluster basé sur DAS était de 48 minutes, contre moins de 5 minutes pour un cluster Kafka basé sur NetApp-NFS.
Nous avons observé que le cluster basé sur EC2 a mis 10 minutes pour reconstruire les 110 Go de données sur le nouveau nœud de courtier, tandis que le cluster basé sur NFS a terminé la récupération en 3 minutes. Nous avons également observé dans les journaux que les décalages des consommateurs pour les partitions pour EC2 étaient de 0, tandis que, sur le cluster NFS, les décalages des consommateurs étaient récupérés à partir du courtier précédent.
[2022-10-31 09:39:17,747] INFO [LogLoader partition=test-topic-51R3EWs-0000-55, dir=/mnt/kafka-data/broker2] Reloading from producer snapshot and rebuilding producer state from offset 583999 (kafka.log.UnifiedLog$) [2022-10-31 08:55:55,170] INFO [LogLoader partition=test-topic-qbVsEZg-0000-8, dir=/mnt/data-1] Loading producer state till offset 0 with message format version 2 (kafka.log.UnifiedLog$)
Cluster basé sur DAS
-
Le nœud de sauvegarde a démarré à 08:55:53,730.

-
Le processus de reconstruction des données s'est terminé à 09:05:24,860. Le traitement de 110 Go de données a nécessité environ 10 minutes.

Cluster basé sur NFS
-
Le nœud de sauvegarde a été démarré à 09:39:17,213. L'entrée du journal de départ est mise en évidence ci-dessous.

-
Le processus de reconstruction des données s'est terminé à 09:42:29,115. Le traitement de 110 Go de données a nécessité environ 3 minutes.

Le test a été répété pour les courtiers contenant environ 1 To de données, ce qui a pris environ 48 minutes pour le DAS et 3 minutes pour le NFS. Les résultats sont représentés dans le graphique suivant.
Efficacité du stockage
Étant donné que la couche de stockage du cluster Kafka a été provisionnée via NetApp ONTAP, nous avons obtenu toutes les capacités d’efficacité de stockage d’ ONTAP. Cela a été testé en générant une quantité importante de données sur un cluster Kafka avec un stockage NFS provisionné sur Cloud Volumes ONTAP. Nous avons pu constater une réduction significative de l’espace grâce aux capacités ONTAP .
Configuration architecturale
Le tableau suivant montre la configuration environnementale d’un cluster Kafka utilisant NAS.
| Composant de la plateforme | Configuration de l'environnement |
|---|---|
Kafka 3.2.3 |
|
Système d'exploitation sur tous les nœuds |
RHEL8.7 ou version ultérieure |
Instance NetApp Cloud Volumes ONTAP |
Instance à nœud unique – M5.2xLarge |
La figure suivante illustre l’architecture d’un cluster Kafka basé sur NAS.
-
Calculer. Nous avons utilisé un cluster Kafka à trois nœuds avec un ensemble zookeeper à trois nœuds exécuté sur des serveurs dédiés. Chaque courtier disposait de deux points de montage NFS sur un seul volume sur l'instance NetApp CVO via un LIF dédié.
-
Surveillance. Nous avons utilisé deux nœuds pour une combinaison Prometheus-Grafana. Pour générer des charges de travail, nous avons utilisé un cluster à trois nœuds distinct qui pouvait produire et consommer sur ce cluster Kafka.
-
Stockage. Nous avons utilisé une instance NetApp Cloud Volumes ONTAP à nœud unique avec six volumes AWS-EBS GP2 de 250 Go montés sur l'instance. Ces volumes ont ensuite été exposés au cluster Kafka sous forme de six volumes NFS via des LIF dédiés.
-
Configuration. Les éléments configurables dans ce cas de test étaient les courtiers Kafka.
La compression a été désactivée du côté du producteur, permettant ainsi aux producteurs de générer un débit élevé. L'efficacité du stockage était plutôt gérée par la couche de calcul.
Méthodologie des tests
-
Un cluster Kafka a été provisionné avec les spécifications mentionnées ci-dessus.
-
Sur le cluster, environ 350 Go de données ont été produites à l’aide de l’outil OpenMessaging Benchmarking.
-
Une fois la charge de travail terminée, les statistiques d'efficacité du stockage ont été collectées à l'aide ONTAP System Manager et de l'interface de ligne de commande.
Observation
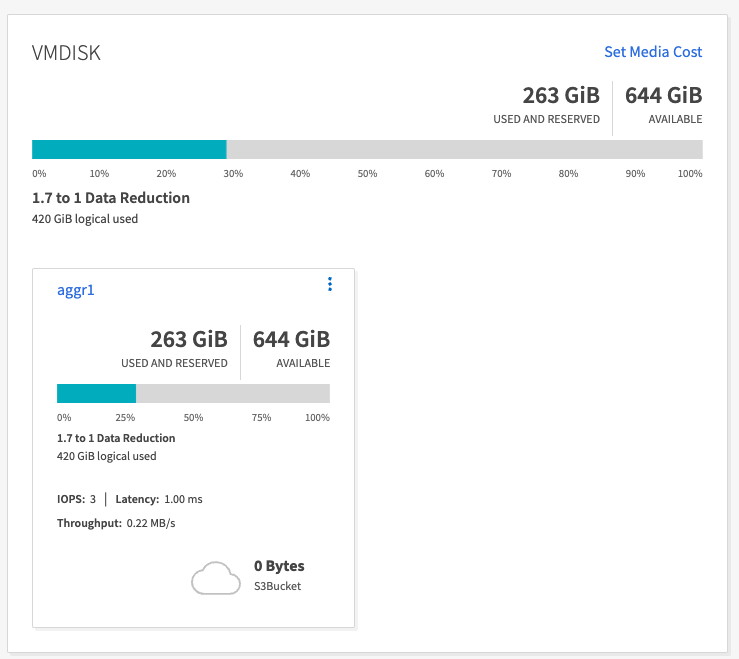
Pour les données générées à l’aide de l’outil OMB, nous avons constaté des économies d’espace d’environ 33 % avec un ratio d’efficacité de stockage de 1,70:1. Comme le montrent les figures suivantes, l’espace logique utilisé par les données produites était de 420,3 Go et l’espace physique utilisé pour contenir les données était de 281,7 Go.