

Validation des performances de Confluent
 Suggérer des modifications
Suggérer des modifications
Nous avons effectué la vérification avec Confluent Platform pour le stockage hiérarchisé sur NetApp ONTAP. Les équipes NetApp et Confluent ont travaillé ensemble sur cette vérification et ont exécuté les cas de test nécessaires à cet effet.
Configuration confluente
Pour la configuration, nous avons utilisé trois gardiens de zoo, cinq courtiers et cinq serveurs de test avec 256 Go de RAM et 16 processeurs. Pour le stockage NetApp , nous avons utilisé ONTAP avec une paire AFF A900 HA. Le stockage et les courtiers étaient connectés via des connexions 100 GbE.
La figure suivante montre la topologie du réseau de configuration utilisée pour la vérification du stockage à plusieurs niveaux.
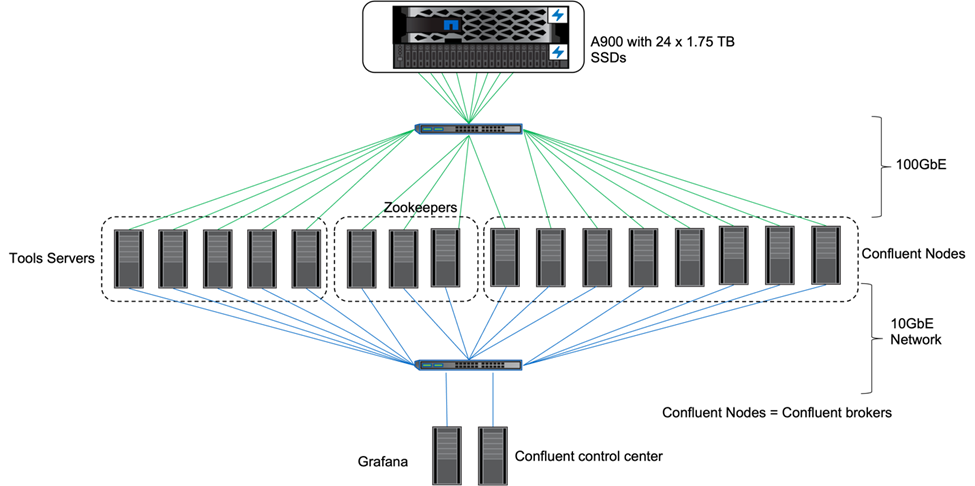
Les serveurs d’outils agissent comme des clients d’application qui envoient ou reçoivent des événements vers ou depuis des nœuds Confluent.
Configuration de stockage hiérarchisé Confluent
Nous avons utilisé les paramètres de test suivants :
confluent.tier.fetcher.num.threads=80 confluent.tier.archiver.num.threads=80 confluent.tier.enable=true confluent.tier.feature=true confluent.tier.backend=S3 confluent.tier.s3.bucket=kafkabucket1-1 confluent.tier.s3.region=us-east-1 confluent.tier.s3.cred.file.path=/data/kafka/.ssh/credentials confluent.tier.s3.aws.endpoint.override=http://wle-mendocino-07-08/ confluent.tier.s3.force.path.style.access=true bootstrap.server=192.168.150.172:9092,192.168.150.120:9092,192.168.150.164:9092,192.168.150.198:9092,192.168.150.109:9092,192.168.150.165:9092,192.168.150.119:9092,192.168.150.133:9092 debug=true jmx.port=7203 num.partitions=80 num.records=200000000 #object PUT size - 512MB and fetch 100MB – netapp segment.bytes=536870912 max.partition.fetch.bytes=1048576000 #GET size is max.partition.fetch.bytes/num.partitions length.key.value=2048 trogdor.agent.nodes=node0,node1,node2,node3,node4 trogdor.coordinator.hostname.port=192.168.150.155:8889 num.producers=20 num.head.consumers=20 num.tail.consumers=1 test.binary.task.max.heap.size=32G test.binary.task.timeout.sec=3600 producer.timeout.sec=3600 consumer.timeout.sec=3600
Pour la vérification, nous avons utilisé ONTAP avec le protocole HTTP, mais HTTPS a également fonctionné. La clé d'accès et la clé secrète sont stockées dans le nom de fichier fourni dans le confluent.tier.s3.cred.file.path paramètre.
Contrôleur de stockage NetApp – ONTAP
Nous avons configuré une seule configuration de paire HA dans ONTAP pour vérification.
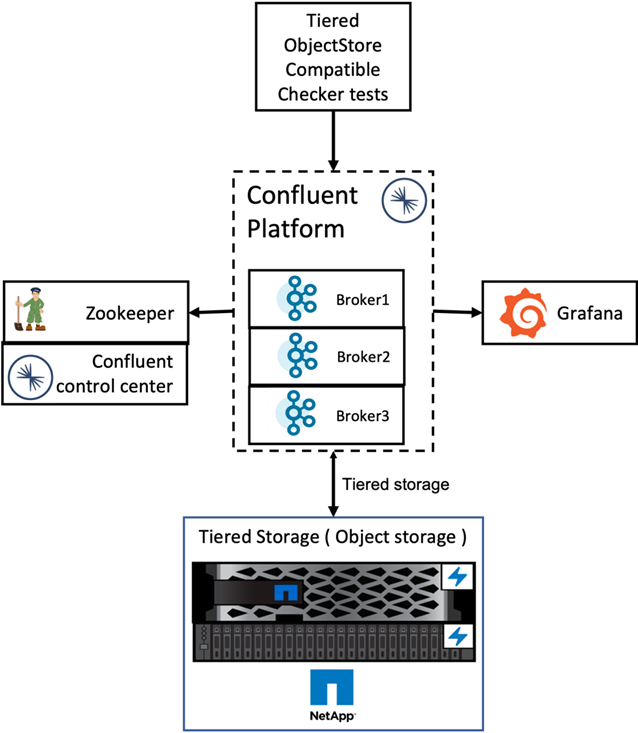
Résultats de la vérification
Nous avons réalisé les cinq cas de test suivants pour la vérification. Les deux premiers étaient des tests de fonctionnalité et les trois autres étaient des tests de performance.
Test d'exactitude du magasin d'objets
Ce test effectue des opérations de base telles que get, put et delete sur le magasin d'objets utilisé pour le stockage hiérarchisé à l'aide d'appels API.
Test d'exactitude des fonctionnalités de hiérarchisation
Ce test vérifie la fonctionnalité de bout en bout du stockage d'objets. Il crée une rubrique, produit un flux d'événements vers la rubrique nouvellement créée, attend que les courtiers archivent les segments dans le stockage d'objets, consomme le flux d'événements et valide les correspondances du flux consommé avec le flux produit. Nous avons effectué ce test avec et sans injection de fautes dans le magasin d’objets. Nous avons simulé une défaillance de nœud en arrêtant le service du gestionnaire de services dans l’un des nœuds d’ ONTAP et en validant que la fonctionnalité de bout en bout fonctionne avec le stockage d’objets.
Benchmark de récupération de niveaux
Ce test a validé les performances de lecture du stockage d'objets hiérarchisé et a vérifié la plage de requêtes de lecture d'extraction sous une charge importante à partir des segments générés par le benchmark. Dans cette référence, Confluent a développé des clients personnalisés pour répondre aux demandes de récupération de niveau.
Générateur de charge de travail de production-consommation
Ce test génère indirectement une charge de travail d'écriture sur le magasin d'objets via l'archivage des segments. La charge de travail de lecture (segments lus) a été générée à partir du stockage d'objets lorsque les groupes de consommateurs ont récupéré les segments. Cette charge de travail a été générée par un script TOCC. Ce test a vérifié les performances de lecture et d'écriture sur le stockage d'objets dans des threads parallèles. Nous avons testé avec et sans injection de pannes de magasin d'objets comme nous l'avons fait pour le test d'exactitude de la fonctionnalité de hiérarchisation.
Générateur de charge de travail de rétention
Ce test a vérifié les performances de suppression d'un stockage d'objets sous une charge de travail de rétention de sujets importante. La charge de travail de rétention a été générée à l'aide d'un script TOCC qui produit de nombreux messages en parallèle avec une rubrique de test. Le sujet de test consistait à configurer un paramètre de rétention agressif basé sur la taille et le temps, ce qui entraînait la purge continue du flux d'événements du magasin d'objets. Les segments ont ensuite été archivés. Cela a conduit à de nombreuses suppressions dans le stockage d'objets par le courtier et à la collecte des performances des opérations de suppression du magasin d'objets.
Pour plus de détails sur la vérification, consultez le "Confluent" site web.