

Aperçu de la technologie
 Suggérer des modifications
Suggérer des modifications
Cette section décrit la technologie utilisée dans cette solution.
NetApp StorageGRID
NetApp StorageGRID est une plate-forme de stockage d'objets hautes performances et rentable. En utilisant le stockage hiérarchisé, la plupart des données sur Confluent Kafka, qui sont stockées dans le stockage local ou le stockage SAN du courtier, sont déchargées vers le magasin d'objets distant. Cette configuration entraîne des améliorations opérationnelles significatives en réduisant le temps et le coût nécessaires pour rééquilibrer, étendre ou réduire les clusters ou remplacer un courtier défaillant. Le stockage d'objets joue un rôle important dans la gestion des données qui résident sur le niveau du magasin d'objets, c'est pourquoi il est important de choisir le bon stockage d'objets.
StorageGRID offre une gestion intelligente des données mondiales basée sur des politiques à l'aide d'une architecture de grille distribuée basée sur des nœuds. Il simplifie la gestion de pétaoctets de données non structurées et de milliards d'objets grâce à son espace de noms d'objets global omniprésent combiné à des fonctionnalités de gestion de données sophistiquées. L'accès aux objets par appel unique s'étend sur plusieurs sites et simplifie les architectures à haute disponibilité tout en garantissant un accès continu aux objets, quelles que soient les pannes du site ou de l'infrastructure.
La multilocation permet à plusieurs applications de données cloud et d'entreprise non structurées d'être gérées en toute sécurité au sein de la même grille, augmentant ainsi le retour sur investissement et les cas d'utilisation de NetApp StorageGRID. Vous pouvez créer plusieurs niveaux de service avec des politiques de cycle de vie d'objet basées sur les métadonnées, optimisant la durabilité, la protection, les performances et la localité dans plusieurs zones géographiques. Les utilisateurs peuvent ajuster les politiques de gestion des données et surveiller et appliquer des limites de trafic pour se réaligner sur le paysage des données de manière non perturbatrice à mesure que leurs besoins évoluent dans des environnements informatiques en constante évolution.
Gestion simple avec Grid Manager
StorageGRID Grid Manager est une interface graphique basée sur un navigateur qui vous permet de configurer, de gérer et de surveiller votre système StorageGRID sur des emplacements distribués à l'échelle mondiale dans une seule fenêtre.
Vous pouvez effectuer les tâches suivantes avec l'interface StorageGRID Grid Manager :
-
Gérez des référentiels d'objets distribués à l'échelle mondiale et à l'échelle du pétaoctet, tels que des images, des vidéos et des enregistrements.
-
Surveillez les nœuds et les services de la grille pour garantir la disponibilité des objets.
-
Gérez le placement des données d'objet au fil du temps à l'aide de règles de gestion du cycle de vie des informations (ILM). Ces règles régissent ce qui arrive aux données d'un objet après son ingestion, comment elles sont protégées contre la perte, où les données de l'objet sont stockées et pendant combien de temps.
-
Surveiller les transactions, les performances et les opérations au sein du système.
Politiques de gestion du cycle de vie de l'information
StorageGRID dispose de politiques de gestion des données flexibles qui incluent la conservation de copies de réplique de vos objets et l'utilisation de schémas EC (codage d'effacement) tels que 2+1 et 4+2 (entre autres) pour stocker vos objets, en fonction des exigences spécifiques en matière de performances et de protection des données. À mesure que les charges de travail et les exigences évoluent au fil du temps, il est courant que les politiques ILM doivent également évoluer au fil du temps. La modification des politiques ILM est une fonctionnalité essentielle, permettant aux clients de StorageGRID de s'adapter rapidement et facilement à leur environnement en constante évolution.
Performances
StorageGRID augmente les performances en ajoutant davantage de nœuds de stockage, qui peuvent être des machines virtuelles, du matériel nu ou des appareils spécialement conçus comme le"SG5712, SG5760, SG6060 ou SGF6024" . Lors de nos tests, nous avons dépassé les exigences de performances clés d'Apache Kafka avec une grille à trois nœuds de taille minimale utilisant l'appliance SGF6024. À mesure que les clients font évoluer leur cluster Kafka avec des courtiers supplémentaires, ils peuvent ajouter davantage de nœuds de stockage pour augmenter les performances et la capacité.
Configuration de l'équilibreur de charge et du point de terminaison
Les nœuds d'administration de StorageGRID fournissent l'interface utilisateur de Grid Manager et le point de terminaison de l'API REST pour afficher, configurer et gérer votre système StorageGRID , ainsi que des journaux d'audit pour suivre l'activité du système. Pour fournir un point de terminaison S3 hautement disponible pour le stockage hiérarchisé Confluent Kafka, nous avons implémenté l'équilibreur de charge StorageGRID , qui s'exécute en tant que service sur les nœuds d'administration et les nœuds de passerelle. De plus, l'équilibreur de charge gère également le trafic local et communique avec le GSLB (Global Server Load Balancing) pour faciliter la reprise après sinistre.
Pour améliorer davantage la configuration des points de terminaison, StorageGRID fournit des stratégies de classification du trafic intégrées au nœud d'administration, vous permet de surveiller le trafic de votre charge de travail et applique diverses limites de qualité de service (QoS) à vos charges de travail. Les stratégies de classification du trafic sont appliquées aux points de terminaison sur le service StorageGRID Load Balancer pour les nœuds de passerelle et les nœuds d'administration. Ces politiques peuvent aider à réguler et à surveiller le trafic.
Classification du trafic dans StorageGRID
StorageGRID dispose d'une fonctionnalité QoS intégrée. Les politiques de classification du trafic peuvent aider à surveiller différents types de trafic S3 provenant d’une application cliente. Vous pouvez ensuite créer et appliquer des politiques pour limiter ce trafic en fonction de la bande passante entrante/sortante, du nombre de requêtes simultanées en lecture/écriture ou du taux de requêtes en lecture/écriture.
Apache Kafka
Apache Kafka est une implémentation framework d'un bus logiciel utilisant le traitement de flux écrit en Java et Scala. Son objectif est de fournir une plate-forme unifiée, à haut débit et à faible latence pour gérer les flux de données en temps réel. Kafka peut se connecter à un système externe pour l'exportation et l'importation de données via Kafka Connect et fournit des flux Kafka, une bibliothèque de traitement de flux Java. Kafka utilise un protocole binaire basé sur TCP, optimisé pour l'efficacité et s'appuyant sur une abstraction « d'ensemble de messages » qui regroupe naturellement les messages pour réduire la surcharge de l'aller-retour réseau. Cela permet des opérations de disque séquentielles plus importantes, des paquets réseau plus volumineux et des blocs de mémoire contigus, permettant ainsi à Kafka de transformer un flux rafaleux d'écritures de messages aléatoires en écritures linéaires. La figure suivante illustre le flux de données de base d’Apache Kafka.
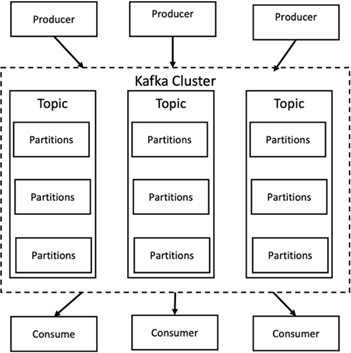
Kafka stocke les messages clé-valeur provenant d'un nombre arbitraire de processus appelés producteurs. Les données peuvent être partitionnées en différentes partitions au sein de différents sujets. Au sein d'une partition, les messages sont strictement ordonnés par leurs décalages (la position d'un message au sein d'une partition) et indexés et stockés avec un horodatage. D’autres processus appelés consommateurs peuvent lire les messages des partitions. Pour le traitement des flux, Kafka propose l'API Streams qui permet d'écrire des applications Java qui consomment des données de Kafka et réécrivent les résultats dans Kafka. Apache Kafka fonctionne également avec des systèmes de traitement de flux externes tels qu'Apache Apex, Apache Flink, Apache Spark, Apache Storm et Apache NiFi.
Kafka s'exécute sur un cluster d'un ou plusieurs serveurs (appelés courtiers), et les partitions de tous les sujets sont réparties sur les nœuds du cluster. De plus, les partitions sont répliquées sur plusieurs courtiers. Cette architecture permet à Kafka de diffuser des flux massifs de messages de manière tolérante aux pannes et lui a permis de remplacer certains des systèmes de messagerie conventionnels tels que Java Message Service (JMS), Advanced Message Queuing Protocol (AMQP), etc. Depuis la version 0.11.0.0, Kafka propose des écritures transactionnelles, qui fournissent un traitement de flux une seule fois à l'aide de l'API Streams.
Kafka prend en charge deux types de sujets : réguliers et compactés. Les sujets réguliers peuvent être configurés avec un temps de rétention ou une limite d'espace. S'il existe des enregistrements plus anciens que la durée de conservation spécifiée ou si l'espace limité est dépassé pour une partition, Kafka est autorisé à supprimer les anciennes données pour libérer de l'espace de stockage. Par défaut, les sujets sont configurés avec une durée de conservation de 7 jours, mais il est également possible de stocker des données indéfiniment. Pour les sujets compactés, les enregistrements n'expirent pas en fonction des limites de temps ou d'espace. Au lieu de cela, Kafka traite les messages ultérieurs comme des mises à jour d'un message plus ancien avec la même clé et garantit de ne jamais supprimer le dernier message par clé. Les utilisateurs peuvent supprimer entièrement les messages en écrivant un message dit « tombstone » avec la valeur nulle pour une clé spécifique.
Il existe cinq API principales dans Kafka :
-
API du producteur. Permet à une application de publier des flux d'enregistrements.
-
API consommateur. Permet à une application de s'abonner à des sujets et de traiter des flux d'enregistrements.
-
API du connecteur. Exécute les API de production et de consommation réutilisables qui peuvent lier les sujets aux applications existantes.
-
API de flux. Cette API convertit les flux d'entrée en sortie et produit le résultat.
-
API d'administration. Utilisé pour gérer les sujets Kafka, les courtiers et autres objets Kafka.
Les API consommateur et producteur s'appuient sur le protocole de messagerie Kafka et offrent une implémentation de référence pour les clients consommateurs et producteurs Kafka en Java. Le protocole de messagerie sous-jacent est un protocole binaire que les développeurs peuvent utiliser pour écrire leurs propres clients consommateurs ou producteurs dans n'importe quel langage de programmation. Cela déverrouille Kafka de l'écosystème Java Virtual Machine (JVM). Une liste des clients non Java disponibles est conservée dans le wiki Apache Kafka.
Cas d'utilisation d'Apache Kafka
Apache Kafka est le plus populaire pour la messagerie, le suivi de l'activité du site Web, les métriques, l'agrégation de journaux, le traitement de flux, l'approvisionnement d'événements et la journalisation des validations.
-
Kafka a amélioré le débit, le partitionnement intégré, la réplication et la tolérance aux pannes, ce qui en fait une bonne solution pour les applications de traitement de messages à grande échelle.
-
Kafka peut reconstruire les activités d'un utilisateur (pages vues, recherches) dans un pipeline de suivi sous la forme d'un ensemble de flux de publication-abonnement en temps réel.
-
Kafka est souvent utilisé pour les données de surveillance opérationnelle. Il s’agit d’agréger des statistiques provenant d’applications distribuées pour produire des flux centralisés de données opérationnelles.
-
De nombreuses personnes utilisent Kafka comme solution de remplacement pour une solution d’agrégation de journaux. L'agrégation de journaux collecte généralement les fichiers journaux physiques des serveurs et les place dans un emplacement central (par exemple, un serveur de fichiers ou HDFS) pour traitement. Kafka résume les détails des fichiers et fournit une abstraction plus propre des données de journal ou d'événement sous forme de flux de messages. Cela permet un traitement à faible latence et une prise en charge plus facile de plusieurs sources de données et d'une consommation de données distribuée.
-
De nombreux utilisateurs de Kafka traitent les données dans des pipelines de traitement composés de plusieurs étapes, dans lesquels les données d'entrée brutes sont consommées à partir des rubriques Kafka, puis agrégées, enrichies ou transformées d'une autre manière en de nouvelles rubriques pour une consommation ultérieure ou un traitement de suivi. Par exemple, un pipeline de traitement pour recommander des articles d'actualité peut explorer le contenu des articles à partir de flux RSS et le publier dans une rubrique « articles ». Un traitement ultérieur pourrait normaliser ou dédupliquer ce contenu et publier le contenu de l'article nettoyé dans une nouvelle rubrique, et une étape de traitement finale pourrait tenter de recommander ce contenu aux utilisateurs. Ces pipelines de traitement créent des graphiques de flux de données en temps réel en fonction des sujets individuels.
-
L'approvisionnement d'événements est un style de conception d'application pour lequel les changements d'état sont enregistrés sous la forme d'une séquence d'enregistrements ordonnée dans le temps. La prise en charge par Kafka de données de journaux stockées très volumineuses en fait un excellent backend pour une application construite dans ce style.
-
Kafka peut servir de sorte de journal de validation externe pour un système distribué. Le journal permet de répliquer les données entre les nœuds et agit comme un mécanisme de resynchronisation pour les nœuds défaillants afin de restaurer leurs données. La fonctionnalité de compactage des journaux dans Kafka permet de prendre en charge ce cas d'utilisation.
Confluent
Confluent Platform est une plateforme prête pour l'entreprise qui complète Kafka avec des fonctionnalités avancées conçues pour aider à accélérer le développement et la connectivité des applications, permettre les transformations grâce au traitement des flux, simplifier les opérations d'entreprise à grande échelle et répondre aux exigences architecturales strictes. Conçu par les créateurs originaux d'Apache Kafka, Confluent étend les avantages de Kafka avec des fonctionnalités de niveau entreprise tout en supprimant le fardeau de la gestion ou de la surveillance de Kafka. Aujourd’hui, plus de 80 % des entreprises du Fortune 100 utilisent la technologie de streaming de données, et la plupart d’entre elles utilisent Confluent.
Pourquoi Confluent ?
En intégrant des données historiques et en temps réel dans une source unique et centrale de vérité, Confluent facilite la création d'une toute nouvelle catégorie d'applications modernes axées sur les événements, l'obtention d'un pipeline de données universel et le déblocage de nouveaux cas d'utilisation puissants avec une évolutivité, des performances et une fiabilité complètes.
À quoi sert Confluent ?
Confluent Platform vous permet de vous concentrer sur la manière de tirer profit de vos données plutôt que de vous soucier des mécanismes sous-jacents, tels que la manière dont les données sont transportées ou intégrées entre des systèmes disparates. Plus précisément, Confluent Platform simplifie la connexion des sources de données à Kafka, la création d'applications de streaming, ainsi que la sécurisation, la surveillance et la gestion de votre infrastructure Kafka. Aujourd'hui, Confluent Platform est utilisé pour un large éventail de cas d'utilisation dans de nombreux secteurs, des services financiers, de la vente au détail omnicanal et des voitures autonomes, à la détection de fraude, aux microservices et à l'IoT.
La figure suivante montre les composants de la plateforme Confluent Kafka.
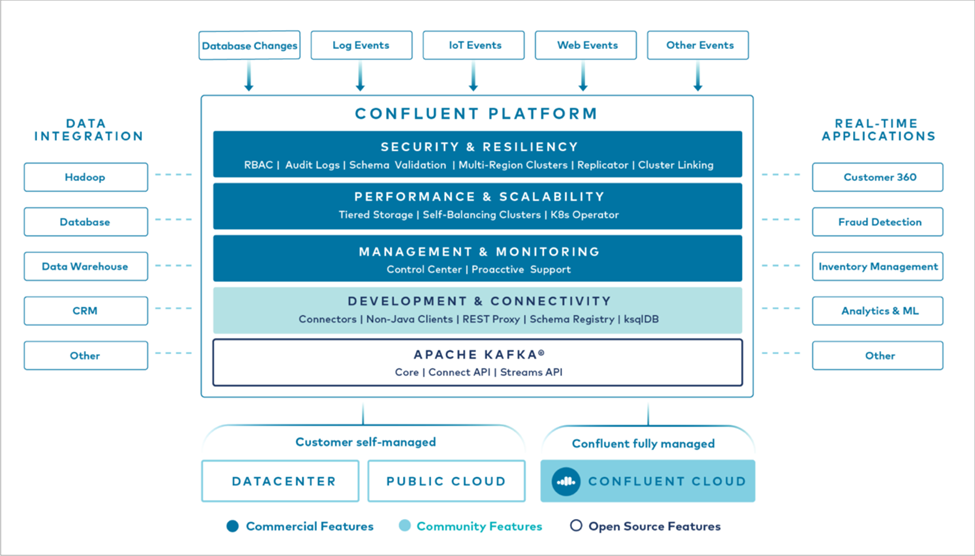
Présentation de la technologie de streaming d'événements de Confluent
Au cœur de la plateforme Confluent se trouve "Apache Kafka" , la plateforme de streaming distribuée open source la plus populaire. Les principales fonctionnalités de Kafka sont les suivantes :
-
Publiez et abonnez-vous à des flux d'enregistrements.
-
Stockez des flux d’enregistrements de manière tolérante aux pannes.
-
Traiter les flux d'enregistrements.
Prêt à l'emploi, Confluent Platform inclut également Schema Registry, REST Proxy, un total de plus de 100 connecteurs Kafka prédéfinis et ksqlDB.
Aperçu des fonctionnalités d'entreprise de la plateforme Confluent
-
Centre de contrôle Confluent. Un système basé sur une interface graphique pour la gestion et la surveillance de Kafka. Il vous permet de gérer facilement Kafka Connect et de créer, modifier et gérer des connexions à d'autres systèmes.
-
Confluent pour Kubernetes. Confluent pour Kubernetes est un opérateur Kubernetes. Les opérateurs Kubernetes étendent les capacités d’orchestration de Kubernetes en fournissant les fonctionnalités et les exigences uniques pour une application de plate-forme spécifique. Pour Confluent Platform, cela inclut la simplification considérable du processus de déploiement de Kafka sur Kubernetes et l'automatisation des tâches typiques du cycle de vie de l'infrastructure.
-
Connecteurs confluents vers Kafka. Les connecteurs utilisent l'API Kafka Connect pour connecter Kafka à d'autres systèmes tels que des bases de données, des magasins de valeurs clés, des index de recherche et des systèmes de fichiers. Confluent Hub propose des connecteurs téléchargeables pour les sources et récepteurs de données les plus populaires, y compris des versions entièrement testées et prises en charge de ces connecteurs avec Confluent Platform. Plus de détails peuvent être trouvés "ici" .
-
Clusters auto-équilibrés. Fournit un équilibrage de charge automatisé, une détection des pannes et une auto-réparation. Il fournit un support pour l'ajout ou la désactivation de courtiers selon les besoins, sans réglage manuel.
-
Liaison de cluster confluent. Connecte directement les clusters entre eux et reflète les sujets d'un cluster à un autre via un pont de liaison. La liaison de cluster simplifie la configuration des déploiements multi-centres de données, multi-clusters et cloud hybride.
-
Équilibreur automatique de données Confluent. Surveille votre cluster pour le nombre de courtiers, la taille des partitions, le nombre de partitions et le nombre de leaders au sein du cluster. Il vous permet de déplacer les données pour créer une charge de travail uniforme sur votre cluster, tout en limitant le trafic de rééquilibrage pour minimiser l'effet sur les charges de travail de production lors du rééquilibrage.
-
Réplicateur confluent. Il est plus facile que jamais de maintenir plusieurs clusters Kafka dans plusieurs centres de données.
-
Stockage à plusieurs niveaux. Fournit des options pour stocker de grands volumes de données Kafka à l'aide de votre fournisseur de cloud préféré, réduisant ainsi la charge et les coûts opérationnels. Avec le stockage hiérarchisé, vous pouvez conserver les données sur un stockage d'objets rentable et faire évoluer les courtiers uniquement lorsque vous avez besoin de davantage de ressources de calcul.
-
Client JMS confluent. Confluent Platform inclut un client compatible JMS pour Kafka. Ce client Kafka implémente l'API standard JMS 1.1, en utilisant les courtiers Kafka comme backend. Ceci est utile si vous avez des applications héritées utilisant JMS et que vous souhaitez remplacer le courtier de messages JMS existant par Kafka.
-
Proxy MQTT confluent. Fournit un moyen de publier des données directement sur Kafka à partir d'appareils et de passerelles MQTT sans avoir besoin d'un courtier MQTT au milieu.
-
Plugins de sécurité Confluent. Les plugins de sécurité Confluent sont utilisés pour ajouter des fonctionnalités de sécurité à divers outils et produits de la plateforme Confluent. Actuellement, il existe un plugin disponible pour le proxy REST Confluent qui permet d'authentifier les requêtes entrantes et de propager le principal authentifié aux requêtes vers Kafka. Cela permet aux clients proxy Confluent REST d'utiliser les fonctionnalités de sécurité multilocataire du courtier Kafka.