

Présentation des solutions NetApp Spark
 Suggérer des modifications
Suggérer des modifications
NetApp dispose de trois portefeuilles de stockage : FAS/ AFF, E-Series et Cloud Volumes ONTAP. Nous avons validé AFF et la série E avec le système de stockage ONTAP pour les solutions Hadoop avec Apache Spark.
La structure de données optimisée par NetApp intègre des services et des applications de gestion des données (blocs de construction) pour l'accès, le contrôle, la protection et la sécurité des données, comme illustré dans la figure ci-dessous.
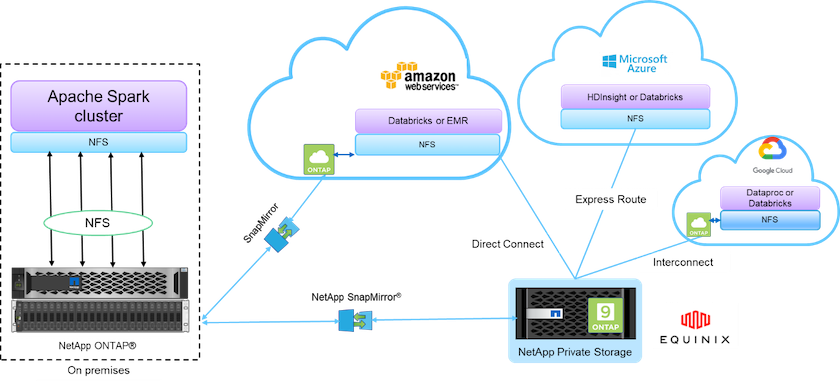
Les éléments constitutifs de la figure ci-dessus comprennent :
-
* Accès direct NetApp NFS.* Fournit aux derniers clusters Hadoop et Spark un accès direct aux volumes NetApp NFS sans exigences de logiciel ou de pilote supplémentaires.
-
* NetApp Cloud Volumes ONTAP et Google Cloud NetApp Volumes.* Stockage connecté défini par logiciel basé sur ONTAP exécuté dans Amazon Web Services (AWS) ou Azure NetApp Files (ANF) dans les services cloud Microsoft Azure.
-
* Technologie NetApp SnapMirror .* Fournit des capacités de protection des données entre les instances locales et ONTAP Cloud ou NPS.
-
Fournisseurs de services cloud. Ces fournisseurs incluent AWS, Microsoft Azure, Google Cloud et IBM Cloud.
-
PaaS. Services d'analyse basés sur le cloud tels qu'Amazon Elastic MapReduce (EMR) et Databricks dans AWS ainsi que Microsoft Azure HDInsight et Azure Databricks.
La figure suivante illustre la solution Spark avec le stockage NetApp .
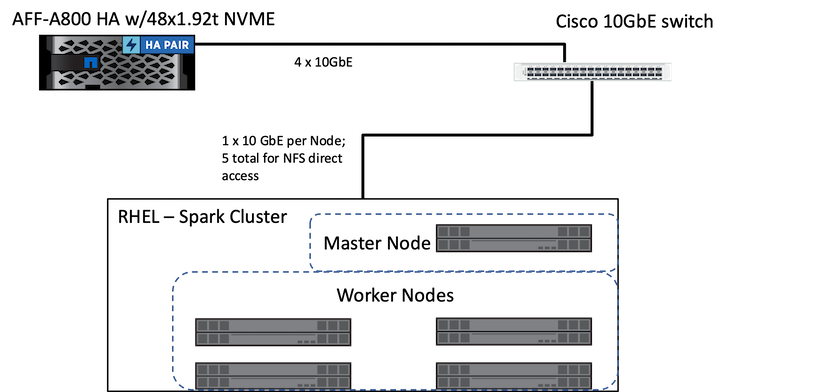
La solution ONTAP Spark utilise le protocole d'accès direct NetApp NFS pour les analyses sur place et les flux de travail IA, ML et DL utilisant l'accès aux données de production existantes. Les données de production disponibles pour les nœuds Hadoop sont exportées pour effectuer des tâches d'analyse et d'IA, de ML et de DL sur place. Vous pouvez accéder aux données à traiter dans les nœuds Hadoop avec ou sans accès direct NetApp NFS. Dans Spark avec le standalone ou yarn gestionnaire de cluster, vous pouvez configurer un volume NFS en utilisant file://<target_volume> . Nous avons validé trois cas d’utilisation avec différents ensembles de données. Les détails de ces validations sont présentés dans la section « Résultats des tests ». (xref)
La figure suivante illustre le positionnement du stockage NetApp Apache Spark/Hadoop.
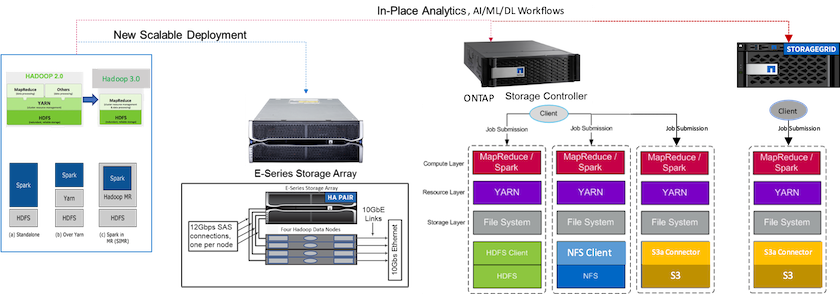
Nous avons identifié les caractéristiques uniques de la solution E-Series Spark, de la solution AFF/ FAS ONTAP Spark et de la solution StorageGRID Spark, et avons effectué une validation et des tests détaillés. Sur la base de nos observations, NetApp recommande la solution E-Series pour les installations greenfield et les nouveaux déploiements évolutifs, ainsi que la solution AFF/ FAS pour les charges de travail d'analyse sur place, d'IA, de ML et de DL utilisant les données NFS existantes, et StorageGRID pour l'IA, le ML et le DL et les analyses de données modernes lorsque le stockage d'objets est requis.
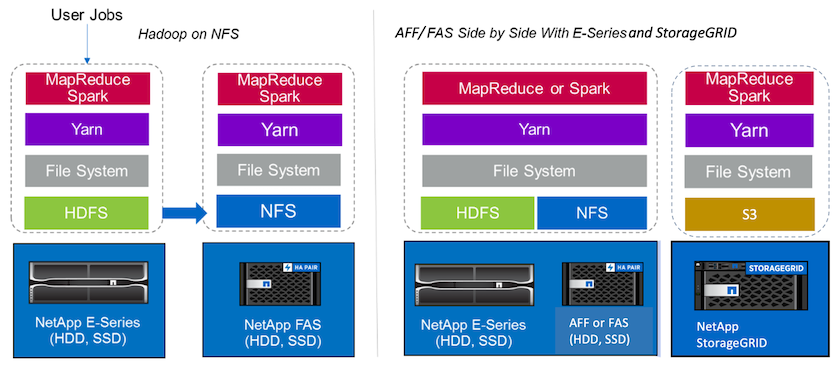
Un lac de données est un référentiel de stockage pour de grands ensembles de données sous forme native qui peuvent être utilisés pour les tâches d'analyse, d'IA, de ML et de DL. Nous avons créé un référentiel de lac de données pour les solutions E-Series, AFF/ FAS et StorageGRID SG6060 Spark. Le système E-Series fournit un accès HDFS au cluster Hadoop Spark, tandis que les données de production existantes sont accessibles via le protocole d'accès direct NFS au cluster Hadoop. Pour les ensembles de données résidant dans le stockage d'objets, NetApp StorageGRID fournit un accès sécurisé S3 et S3a.