

Architecture Splunk
 Suggérer des modifications
Suggérer des modifications
Cette section décrit l'architecture Splunk, y compris les définitions clés, les déploiements distribués Splunk, Splunk SmartStore, le flux de données, les exigences matérielles et logicielles, les exigences mono et multisites, etc.
Définitions clés
Les deux tableaux suivants répertorient les composants Splunk et NetApp utilisés dans le déploiement Splunk distribué.
Ce tableau répertorie les composants matériels Splunk pour la configuration distribuée de Splunk Enterprise.
| Composant Splunk | Tâche |
|---|---|
Indexeur |
Référentiel pour les données Splunk Enterprise |
Transitaire universel |
Responsable de l'ingestion des données et de leur transmission aux indexeurs |
Tête de recherche |
L'interface utilisateur utilisée pour rechercher des données dans les indexeurs |
Maître de cluster |
Gère l'installation Splunk des indexeurs et des têtes de recherche |
Console de surveillance |
Outil de surveillance centralisé utilisé sur l'ensemble du déploiement |
Licence master |
Le maître des licences gère les licences Splunk Enterprise |
Serveur de déploiement |
Met à jour les configurations et distribue les applications au composant de traitement |
Composant de stockage |
Tâche |
NetApp AFF |
Stockage entièrement flash utilisé pour gérer les données de niveau chaud. Également connu sous le nom de stockage local. |
NetApp StorageGRID |
Stockage d'objets S3 utilisé pour gérer les données de niveau chaud. Utilisé par SmartStore pour déplacer des données entre les niveaux chaud et tiède. Également connu sous le nom de stockage à distance. |
Ce tableau répertorie les composants de l’architecture de stockage Splunk.
| Composant Splunk | Tâche | Composant responsable |
|---|---|---|
Magasin intelligent |
Fournit aux indexeurs la possibilité de hiérarchiser les données du stockage local vers le stockage d'objets. |
Splunk |
Chaud |
Le point d'atterrissage où les transitaires universels placent les données nouvellement écrites. Le stockage est accessible en écriture et les données sont consultables. Ce niveau de données est généralement composé de SSD ou de disques durs rapides. |
ONTAP |
Gestionnaire de cache |
Gère le cache local des données indexées, récupère les données chaudes du stockage distant lorsqu'une recherche se produit et supprime les données les moins fréquemment utilisées du cache. |
Magasin intelligent |
Chaud |
Les données sont transférées logiquement vers le bucket, renommées d'abord vers le niveau chaud à partir du niveau chaud. Les données de ce niveau sont protégées et, comme le niveau chaud, peuvent être composées de SSD ou de disques durs de plus grande capacité. Les sauvegardes incrémentielles et complètes sont prises en charge à l'aide de solutions de protection des données courantes. |
StorageGRID |
Déploiements distribués Splunk
Pour prendre en charge des environnements plus vastes dans lesquels les données proviennent de nombreuses machines, vous devez traiter de grands volumes de données. Si de nombreux utilisateurs doivent rechercher les données, vous pouvez faire évoluer le déploiement en distribuant les instances Splunk Enterprise sur plusieurs machines. C'est ce qu'on appelle un déploiement distribué.
Dans un déploiement distribué typique, chaque instance Splunk Enterprise exécute une tâche spécialisée et réside sur l’un des trois niveaux de traitement correspondant aux principales fonctions de traitement.
Le tableau suivant répertorie les niveaux de traitement de Splunk Enterprise.
| Étage | Composant | Description |
|---|---|---|
Saisie de données |
Transitaire |
Un transitaire consomme des données, puis les transmet à un groupe d’indexeurs. |
Indexage |
Indexeur |
Un indexeur indexe les données entrantes qu'il reçoit généralement d'un groupe de transitaires. L'indexeur transforme les données en événements et stocke les événements dans un index. L'indexeur recherche également les données indexées en réponse aux demandes de recherche d'une tête de recherche. |
Gestion de la recherche |
Tête de recherche |
Une tête de recherche sert de ressource centrale pour la recherche. Les têtes de recherche d'un cluster sont interchangeables et ont accès aux mêmes recherches, tableaux de bord, objets de connaissances, etc., à partir de n'importe quel membre du cluster de têtes de recherche. |
Le tableau suivant répertorie les composants importants utilisés dans un environnement Splunk Enterprise distribué.
| Composant | Description | Responsabilité |
|---|---|---|
Maître du cluster d'index |
Coordonne les activités et les mises à jour d'un cluster d'indexeurs |
Gestion des indices |
cluster d'index |
Groupe d'indexeurs Splunk Enterprise configurés pour répliquer des données entre eux |
Indexage |
Déploiement de la tête de recherche |
Gère le déploiement et les mises à jour du cluster maître |
Gestion de la tête de recherche |
Cluster de têtes de recherche |
Groupe de têtes de recherche qui sert de ressource centrale pour la recherche |
Gestion de la recherche |
Équilibreurs de charge |
Utilisé par les composants en cluster pour gérer la demande croissante des têtes de recherche, des indexeurs et de la cible S3 afin de répartir la charge sur les composants en cluster. |
Gestion de la charge pour les composants en cluster |
Découvrez les avantages suivants des déploiements distribués Splunk Enterprise :
-
Accéder à des sources de données diverses ou dispersées
-
Fournir des fonctionnalités pour gérer les besoins en données des entreprises de toute taille et de toute complexité
-
Obtenez une haute disponibilité et assurez la reprise après sinistre grâce à la réplication des données et au déploiement multisite
Splunk SmartStore
SmartStore est une fonctionnalité d'indexation qui permet aux magasins d'objets distants tels qu'Amazon S3 de stocker des données indexées. À mesure que le volume de données d’un déploiement augmente, la demande de stockage dépasse généralement la demande de ressources de calcul. SmartStore vous permet de gérer de manière rentable le stockage de votre indexeur et vos ressources de calcul en mettant à l'échelle ces ressources séparément.
SmartStore introduit un niveau de stockage à distance et un gestionnaire de cache. Ces fonctionnalités permettent aux données de résider soit localement sur des indexeurs, soit sur le niveau de stockage distant. Le gestionnaire de cache gère le déplacement des données entre l'indexeur et le niveau de stockage distant, qui est configuré sur l'indexeur.
Avec SmartStore, vous pouvez réduire au minimum l'empreinte de stockage de l'indexeur et choisir des ressources de calcul optimisées pour les E/S. La plupart des données résident sur le stockage distant. L'indexeur conserve un cache local contenant une quantité minimale de données : buckets chauds, copies de buckets chauds participant à des recherches actives ou récentes et métadonnées de bucket.
Flux de données Splunk SmartStore
Lorsque les données provenant de diverses sources atteignent les indexeurs, les données sont indexées et enregistrées localement dans un bucket chaud. L'indexeur réplique également les données du compartiment chaud vers les indexeurs cibles. Jusqu’à présent, le flux de données est identique au flux de données des index non SmartStore.
Lorsque le seau chaud devient chaud, le flux de données diverge. L'indexeur source copie le bucket chaud dans le magasin d'objets distant (niveau de stockage distant) tout en laissant la copie existante dans son cache, car les recherches ont tendance à s'exécuter sur des données récemment indexées. Cependant, les indexeurs cibles suppriment leurs copies car le magasin distant offre une haute disponibilité sans conserver plusieurs copies locales. La copie principale du bucket réside désormais dans le magasin distant.
L'image suivante montre le flux de données Splunk SmartStore.
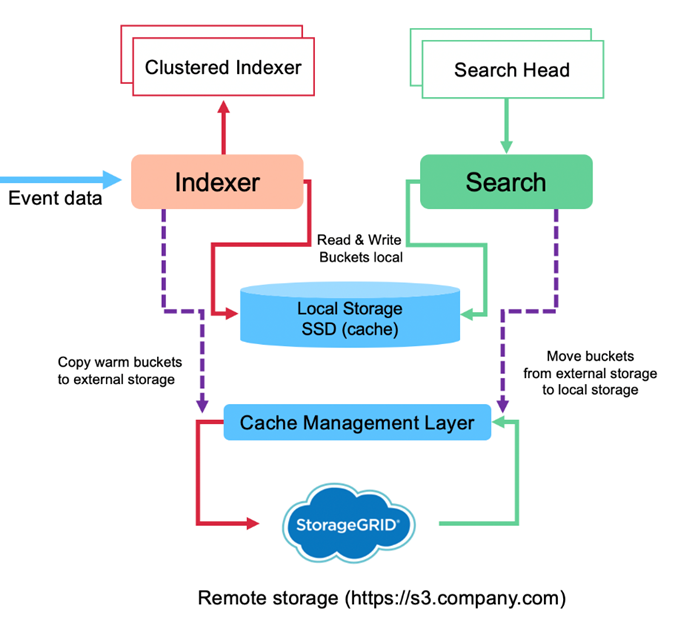
Le gestionnaire de cache sur l'indexeur est au cœur du flux de données SmartStore. Il récupère des copies des buckets du magasin distant si nécessaire pour gérer les demandes de recherche. Il supprime également les copies plus anciennes ou moins recherchées des buckets du cache, car la probabilité qu'ils participent aux recherches diminue avec le temps.
Le travail du gestionnaire de cache est d'optimiser l'utilisation du cache disponible tout en garantissant que les recherches ont un accès immédiat aux compartiments dont elles ont besoin.
Configuration logicielle requise
Le tableau ci-dessous répertorie les composants logiciels nécessaires à la mise en œuvre de la solution. Les composants logiciels utilisés dans toute implémentation de la solution peuvent varier en fonction des exigences du client.
| Famille de produits | Nom du produit | Version du produit | Système opérateur |
|---|---|---|---|
NetApp StorageGRID |
Stockage d'objets StorageGRID |
11,6 |
n / A |
CentOS |
CentOS |
8,1 |
CentOS 7.x |
Splunk Entreprise |
Splunk Enterprise avec SmartStore |
8.0.3 |
CentOS 7.x |
Exigences mono et multisites
Dans un environnement Splunk Enterprise (déploiements moyens et grands) où les données proviennent de nombreuses machines et où de nombreux utilisateurs doivent rechercher les données, vous pouvez faire évoluer votre déploiement en distribuant des instances Splunk Enterprise sur un ou plusieurs sites.
Découvrez les avantages suivants des déploiements distribués Splunk Enterprise :
-
Accéder à des sources de données diverses ou dispersées
-
Fournir des fonctionnalités pour gérer les besoins en données des entreprises de toute taille et de toute complexité
-
Obtenez une haute disponibilité et assurez la reprise après sinistre grâce à la réplication des données et au déploiement multisite
Le tableau suivant répertorie les composants utilisés dans un environnement Splunk Enterprise distribué.
| Composant | Description | Responsabilité |
|---|---|---|
Maître du cluster d'index |
Coordonne les activités et les mises à jour d'un cluster d'indexeurs |
Gestion des indices |
cluster d'index |
Groupe d'indexeurs Splunk Enterprise configurés pour répliquer les données des autres |
Indexage |
Déploiement de la tête de recherche |
Gère le déploiement et les mises à jour du cluster maître |
Gestion de la tête de recherche |
Cluster de têtes de recherche |
Groupe de têtes de recherche qui sert de ressource centrale pour la recherche |
Gestion de la recherche |
Équilibreurs de charge |
Utilisé par les composants en cluster pour gérer la demande croissante des têtes de recherche, des indexeurs et de la cible S3 afin de répartir la charge sur les composants en cluster. |
Gestion de la charge pour les composants en cluster |
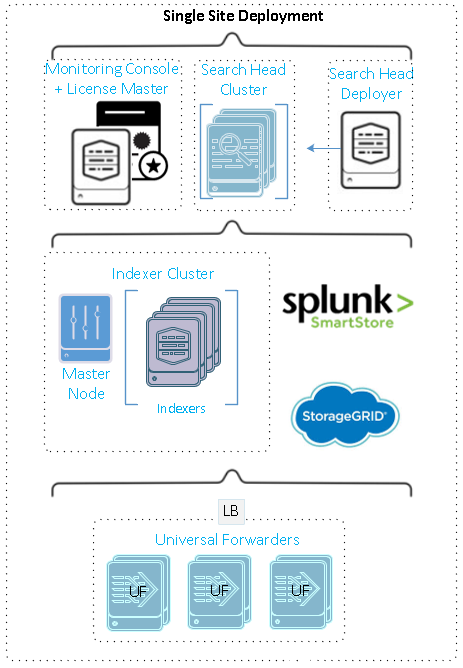
Cette figure illustre un exemple de déploiement distribué sur un seul site.
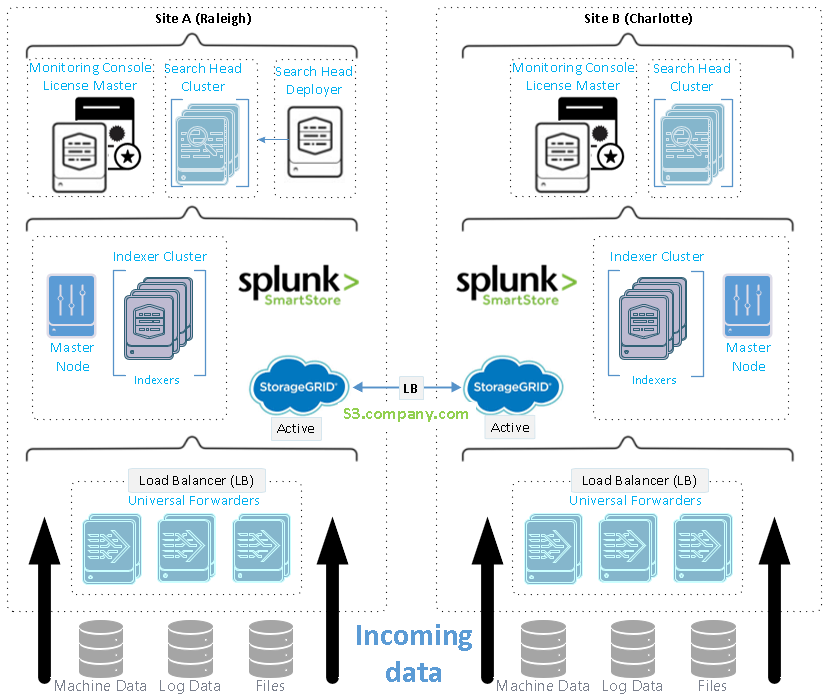
Cette figure illustre un exemple de déploiement distribué multisite.
Configuration matérielle requise
Les tableaux suivants répertorient le nombre minimum de composants matériels requis pour implémenter la solution. Les composants matériels utilisés dans les implémentations spécifiques de la solution peuvent varier en fonction des exigences du client.

|
Que vous ayez déployé Splunk SmartStore et StorageGRID sur un seul site ou sur plusieurs sites, tous les systèmes sont gérés à partir de StorageGRID GRID Manager dans une seule fenêtre. Consultez la section « Gestion simple avec Grid Manager » pour plus de détails. |
Ce tableau répertorie le matériel utilisé pour un seul site.
| Matériel | Quantité | Disque | Capacité utilisable | Remarque |
|---|---|---|---|---|
StorageGRID SG1000 |
1 |
n / A |
n / A |
Nœud d'administration et équilibreur de charge |
StorageGRID SG6060 |
4 |
x48, 8 To (disque dur NL-SAS) |
1PB |
Stockage à distance |
Ce tableau répertorie le matériel utilisé pour une configuration multisite (par site).
| Matériel | Quantité | Disque | Capacité utilisable | Remarque |
|---|---|---|---|---|
StorageGRID SG1000 |
2 |
n / A |
n / A |
Nœud d'administration et équilibreur de charge |
StorageGRID SG6060 |
4 |
x48, 8 To (disque dur NL-SAS) |
1PB |
Stockage à distance |
Équilibreur de charge NetApp StorageGRID : SG1000
Le stockage d’objets nécessite l’utilisation d’un équilibreur de charge pour présenter l’espace de noms de stockage cloud. StorageGRID prend en charge les équilibreurs de charge tiers des principaux fournisseurs tels que F5 et Citrix, mais de nombreux clients choisissent l'équilibreur StorageGRID de niveau entreprise pour sa simplicité, sa résilience et ses hautes performances. L'équilibreur de charge StorageGRID est disponible sous forme de machine virtuelle, de conteneur ou d'appliance spécialement conçue.
Le StorageGRID SG1000 facilite l'utilisation de groupes de haute disponibilité (HA) et l'équilibrage de charge intelligent pour les connexions de chemin de données S3. Aucun autre système de stockage d’objets sur site ne fournit un équilibreur de charge personnalisé.
L'appareil SG1000 offre les fonctionnalités suivantes :
-
Un équilibreur de charge et, éventuellement, des fonctions de nœud d'administration pour un système StorageGRID
-
Le programme d'installation de l'appliance StorageGRID pour simplifier le déploiement et la configuration des nœuds
-
Configuration simplifiée des points de terminaison S3 et SSL
-
Bande passante dédiée (par rapport au partage d'un équilibreur de charge tiers avec d'autres applications)
-
Jusqu'à 4 x 100 Gbit/s de bande passante Ethernet agrégée
L'image suivante montre l'appareil SG1000 Gateway Services.

SG6060
L'appliance StorageGRID SG6060 comprend un contrôleur de calcul (SG6060) et une étagère de contrôleur de stockage (E-Series E2860) contenant deux contrôleurs de stockage et 60 disques. Cet appareil offre les fonctionnalités suivantes :
-
Évoluez jusqu'à 400 Po dans un seul espace de noms.
-
Jusqu'à 4x 25 Gbit/s de bande passante Ethernet agrégée.
-
Inclut le programme d'installation de l'appliance StorageGRID pour simplifier le déploiement et la configuration des nœuds.
-
Chaque appareil SG6060 peut disposer d'une ou deux étagères d'extension supplémentaires pour un total de 180 disques.
-
Deux contrôleurs E-Series E2800 (configuration duplex) pour fournir une prise en charge du basculement du contrôleur de stockage.
-
Étagère à cinq tiroirs pouvant contenir soixante disques de 3,5 pouces (deux disques SSD et 58 disques NL-SAS).
L'image suivante montre l'appareil SG6060.

Conception de Splunk
Le tableau suivant répertorie la configuration Splunk pour un seul site.
| Composant Splunk | Tâche | Quantité | Noyaux | Mémoire | Système d'exploitation |
|---|---|---|---|---|---|
Transitaire universel |
Responsable de l'ingestion des données et de leur transmission aux indexeurs |
4 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Indexeur |
Gère les données des utilisateurs |
10 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Tête de recherche |
L'interface utilisateur recherche des données dans les indexeurs |
3 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Déploiement de la tête de recherche |
Gère les mises à jour des clusters de têtes de recherche |
1 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Maître de cluster |
Gère l'installation et les indexeurs de Splunk |
1 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Console de surveillance et maître de licence |
Effectue une surveillance centralisée de l'ensemble du déploiement Splunk et gère les licences Splunk |
1 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Les tableaux suivants décrivent la configuration Splunk pour les configurations multisites.
Ce tableau répertorie la configuration Splunk pour une configuration multisite (site A).
| Composant Splunk | Tâche | Quantité | Noyaux | Mémoire | Système d'exploitation |
|---|---|---|---|---|---|
Transitaire universel |
Responsable de l'ingestion des données et de leur transmission aux indexeurs. |
4 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Indexeur |
Gère les données des utilisateurs |
10 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Tête de recherche |
L'interface utilisateur recherche des données dans les indexeurs |
3 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Déploiement de la tête de recherche |
Gère les mises à jour des clusters de têtes de recherche |
1 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Maître de cluster |
Gère l'installation et les indexeurs de Splunk |
1 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Console de surveillance et maître de licence |
Effectue une surveillance centralisée de l'ensemble du déploiement Splunk et gère les licences Splunk. |
1 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Ce tableau répertorie la configuration Splunk pour une configuration multisite (site B).
| Composant Splunk | Tâche | Quantité | Noyaux | Mémoire | Système d'exploitation |
|---|---|---|---|---|---|
Transitaire universel |
Responsable de l'ingestion des données et de leur transmission aux indexeurs |
4 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Indexeur |
Gère les données des utilisateurs |
10 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Tête de recherche |
L'interface utilisateur recherche des données dans les indexeurs |
3 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Maître de cluster |
Gère l'installation et les indexeurs de Splunk |
1 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |
Console de surveillance et maître de licence |
Effectue une surveillance centralisée de l'ensemble du déploiement Splunk et gère les licences Splunk |
1 |
16 cœurs |
32 Go de RAM |
CentOS 8.1 |