

TR-4928 : IA responsable et inférence confidentielle – NetApp AI avec Protopia Image and Data Transformation
 Suggérer des modifications
Suggérer des modifications
Sathish Thyagarajan, Michael Oglesby, NetApp Byung Hoon Ahn, Jennifer Cwagenberg, Protopia
Les interprétations visuelles sont devenues partie intégrante de la communication avec l’émergence de la capture et du traitement d’images. L’intelligence artificielle (IA) dans le traitement d’images numériques offre de nouvelles opportunités commerciales, comme dans le domaine médical pour l’identification du cancer et d’autres maladies, dans l’analyse visuelle géospatiale pour l’étude des risques environnementaux, dans la reconnaissance de formes, dans le traitement vidéo pour la lutte contre la criminalité, etc. Mais cette opportunité s’accompagne également de responsabilités extraordinaires.
Plus les organisations confient de décisions à l’IA, plus elles acceptent les risques liés à la confidentialité et à la sécurité des données, ainsi qu’aux questions juridiques, éthiques et réglementaires. L’IA responsable permet une pratique qui permet aux entreprises et aux organisations gouvernementales de renforcer la confiance et la gouvernance, ce qui est crucial pour l’IA à grande échelle dans les grandes entreprises. Ce document décrit une solution d'inférence d'IA validée par NetApp dans trois scénarios différents en utilisant les technologies de gestion de données NetApp avec le logiciel d'obscurcissement des données Protopia pour privatiser les données sensibles et réduire les risques et les préoccupations éthiques.
Des millions d’images sont générées chaque jour à l’aide de divers appareils numériques, tant par les consommateurs que par les entreprises. L’explosion massive des données et de la charge de travail informatique qui en résulte incite les entreprises à se tourner vers les plateformes de cloud computing pour gagner en évolutivité et en efficacité. Parallèlement, des préoccupations en matière de confidentialité des informations sensibles contenues dans les données d’image surviennent lors du transfert vers un cloud public. Le manque de garanties de sécurité et de confidentialité devient le principal obstacle au déploiement des systèmes d’IA de traitement d’images.
De plus, il y a le "droit à l'effacement" par le RGPD, le droit d'un individu de demander à une organisation d'effacer toutes ses données personnelles. Il y a aussi le "Loi sur la protection des renseignements personnels" , qui établit un code de pratiques équitables en matière d’information. Les images numériques telles que les photographies peuvent constituer des données personnelles au sens du RGPD, qui régit la manière dont les données doivent être collectées, traitées et effacées. Le non-respect de ces règles constitue un manquement au RGPD, ce qui peut entraîner de lourdes amendes pour violation des règles de conformité, ce qui peut être gravement préjudiciable aux organisations. Les principes de confidentialité sont l’un des piliers de la mise en œuvre d’une IA responsable qui garantit l’équité dans les prédictions des modèles d’apprentissage automatique (ML) et d’apprentissage profond (DL) et réduit les risques associés à la violation de la confidentialité ou de la conformité réglementaire.
Ce document décrit une solution de conception validée dans trois scénarios différents avec et sans obscurcissement d'image, pertinents pour préserver la confidentialité et déployer une solution d'IA responsable :
-
Scénario 1. Inférence à la demande dans le notebook Jupyter.
-
Scénario 2. Inférence par lots sur Kubernetes.
-
Scénario 3. Serveur d'inférence NVIDIA Triton.
Pour cette solution, nous utilisons le Face Detection Data Set and Benchmark (FDDB), un ensemble de données de régions de visage conçu pour étudier le problème de la détection de visage sans contrainte, combiné au framework d'apprentissage automatique PyTorch pour la mise en œuvre de FaceBoxes. Cet ensemble de données contient les annotations de 5171 visages dans un ensemble de 2845 images de différentes résolutions. En outre, ce rapport technique présente certains des domaines de solution et des cas d’utilisation pertinents recueillis auprès des clients NetApp et des ingénieurs de terrain dans les situations où cette solution est applicable.
Public cible
Ce rapport technique est destiné aux publics suivants :
-
Dirigeants d'entreprise et architectes d'entreprise qui souhaitent concevoir et déployer une IA responsable et répondre aux problèmes de protection des données et de confidentialité concernant le traitement des images faciales dans les espaces publics.
-
Scientifiques des données, ingénieurs des données, chercheurs en IA/apprentissage automatique (ML) et développeurs de systèmes d'IA/ML qui visent à protéger et à préserver la confidentialité.
-
Architectes d'entreprise qui conçoivent des solutions d'obscurcissement des données pour les modèles et applications d'IA/ML conformes aux normes réglementaires telles que le RGPD, le CCPA ou la loi sur la confidentialité du ministère de la Défense (DoD) et des organisations gouvernementales.
-
Les scientifiques des données et les ingénieurs en IA recherchent des moyens efficaces de déployer des modèles d'apprentissage profond (DL) et d'inférence IA/ML/DL qui protègent les informations sensibles.
-
Gestionnaires de périphériques Edge et administrateurs de serveurs Edge responsables du déploiement et de la gestion des modèles d'inférence Edge.
Architecture de la solution
Cette solution est conçue pour gérer les charges de travail d'IA d'inférence en temps réel et par lots sur de grands ensembles de données en utilisant la puissance de traitement des GPU aux côtés des CPU traditionnels. Cette validation démontre l’inférence préservant la confidentialité pour le ML et la gestion optimale des données requises pour les organisations recherchant des déploiements d’IA responsables. Cette solution fournit une architecture adaptée à une plate-forme Kubernetes à nœud unique ou multi-nœuds pour le edge computing et le cloud computing interconnectés avec NetApp ONTAP AI au cœur sur site, NetApp DataOps Toolkit et le logiciel d'obfuscation Protopia utilisant Jupyter Lab et les interfaces CLI. La figure suivante montre l’aperçu de l’architecture logique de Data Fabric optimisé par NetApp avec DataOps Toolkit et Protopia.
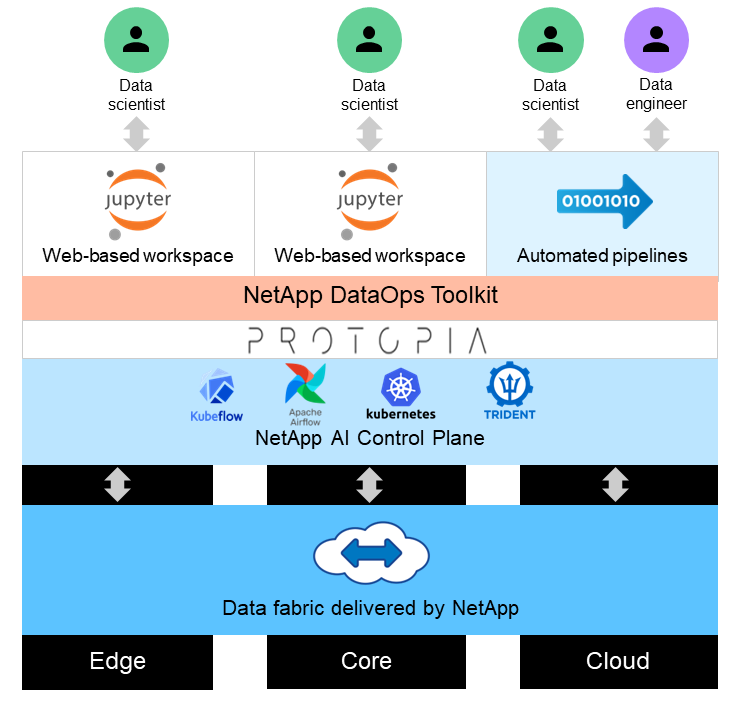
Le logiciel d'obfuscation Protopia s'exécute de manière transparente sur la boîte à outils NetApp DataOps et transforme les données avant de quitter le serveur de stockage.