

Procédure de test
 Suggérer des modifications
Suggérer des modifications
Cette section décrit les tâches nécessaires pour terminer la validation.
Prérequis
Pour exécuter les tâches décrites dans cette section, vous devez avoir accès à un hôte Linux ou macOS avec les outils suivants installés et configurés :
Scénario 1 – Inférence à la demande dans JupyterLab
-
Créez un espace de noms Kubernetes pour les charges de travail d’inférence AI/ML.
$ kubectl create namespace inference namespace/inference created
-
Utilisez la boîte à outils NetApp DataOps pour provisionner un volume persistant pour stocker les données sur lesquelles vous effectuerez l’inférence.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Utilisez la boîte à outils NetApp DataOps pour créer un nouvel espace de travail JupyterLab. Montez le volume persistant qui a été créé à l'étape précédente en utilisant le
--mount- pvcoption. Allouez les GPU NVIDIA à l'espace de travail si nécessaire en utilisant le-- nvidia-gpuoption.Dans l'exemple suivant, le volume persistant
inference-dataest monté sur le conteneur d'espace de travail JupyterLab à/home/jovyan/data. Lors de l'utilisation d'images de conteneur officielles du projet Jupyter,/home/jovyanest présenté comme le répertoire de niveau supérieur dans l'interface Web JupyterLab.$ netapp_dataops_k8s_cli.py create jupyterlab --namespace=inference --workspace-name=live-inference --size=50Gi --nvidia-gpu=2 --mount-pvc=inference-data:/home/jovyan/data Set workspace password (this password will be required in order to access the workspace): Re-enter password: Creating persistent volume for workspace... Creating PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Creating Service 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Service successfully created. Attaching Additional PVC: 'inference-data' at mount_path: '/home/jovyan/data'. Creating Deployment 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Deployment 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Deployment 'ntap-dsutil-jupyterlab-live-inference' to reach Ready state. Deployment successfully created. Workspace successfully created. To access workspace, navigate to http://192.168.0.152:32721
-
Accédez à l'espace de travail JupyterLab en utilisant l'URL spécifiée dans la sortie du
create jupyterlabcommande. Le répertoire de données représente le volume persistant qui a été monté sur l’espace de travail.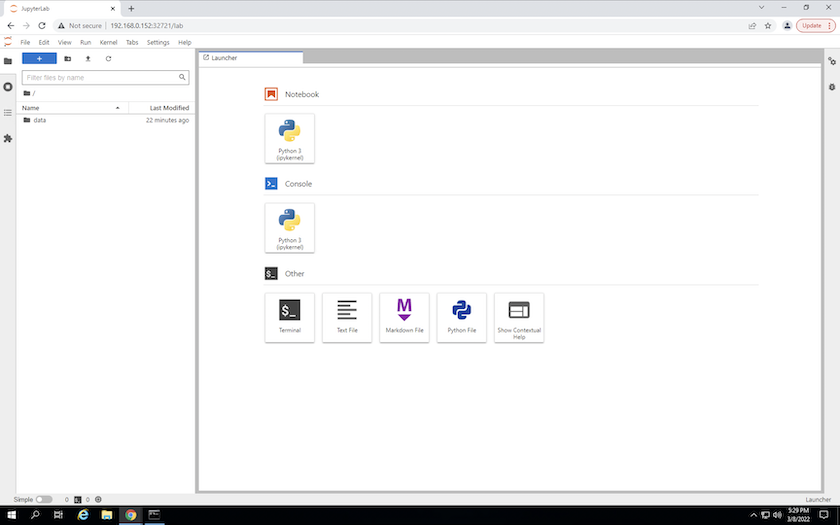
-
Ouvrez le
datarépertoire et téléchargez les fichiers sur lesquels l'inférence doit être effectuée. Lorsque des fichiers sont téléchargés dans le répertoire de données, ils sont automatiquement stockés sur le volume persistant qui a été monté sur l'espace de travail. Pour télécharger des fichiers, cliquez sur l’icône Télécharger des fichiers, comme indiqué dans l’image suivante.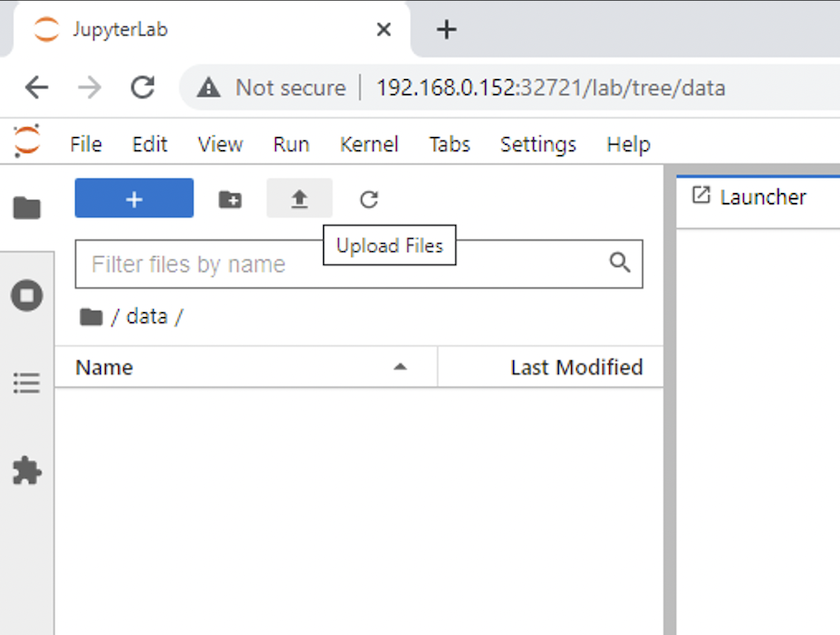
-
Revenez au répertoire de niveau supérieur et créez un nouveau bloc-notes.
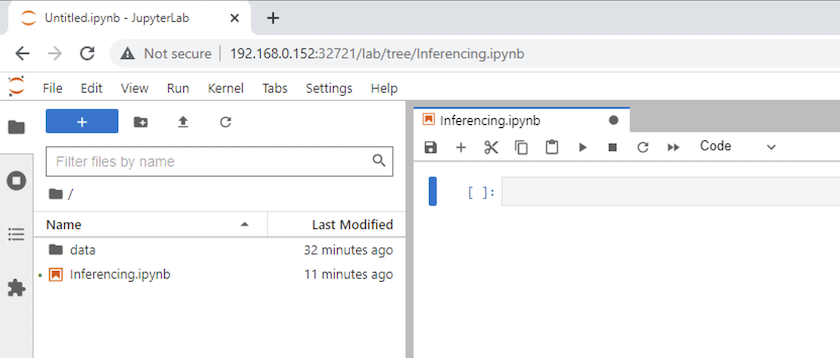
-
Ajoutez du code d’inférence au bloc-notes. L'exemple suivant montre le code d'inférence pour un cas d'utilisation de détection d'image.
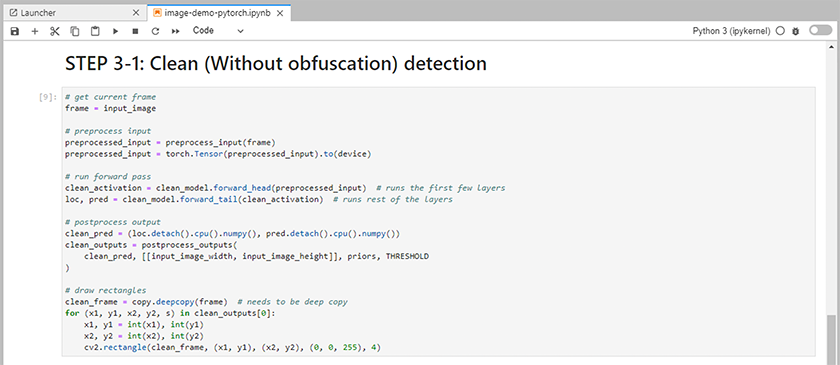
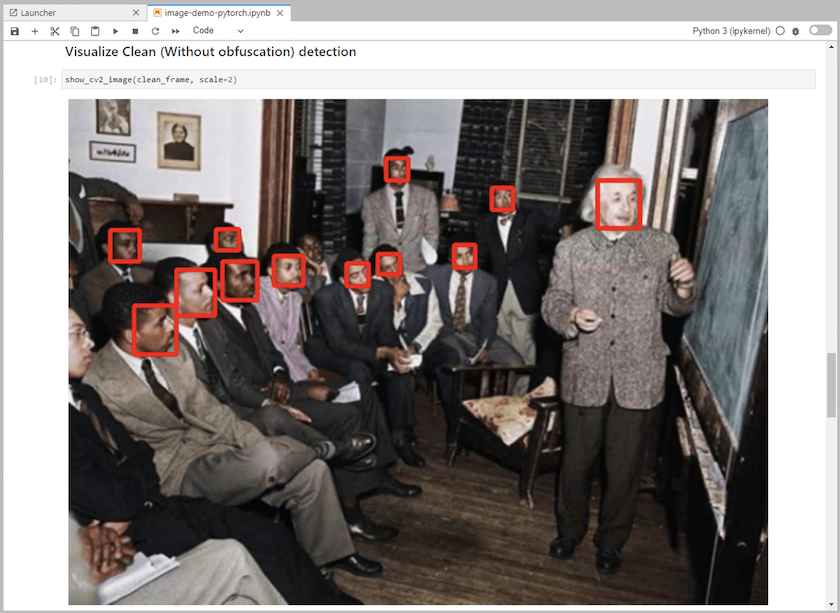
-
Ajoutez l’obfuscation Protopia à votre code d’inférence. Protopia travaille directement avec les clients pour fournir une documentation spécifique au cas d'utilisation et n'entre pas dans le cadre de ce rapport technique. L'exemple suivant montre le code d'inférence pour un cas d'utilisation de détection d'image avec l'obfuscation Protopia ajoutée.
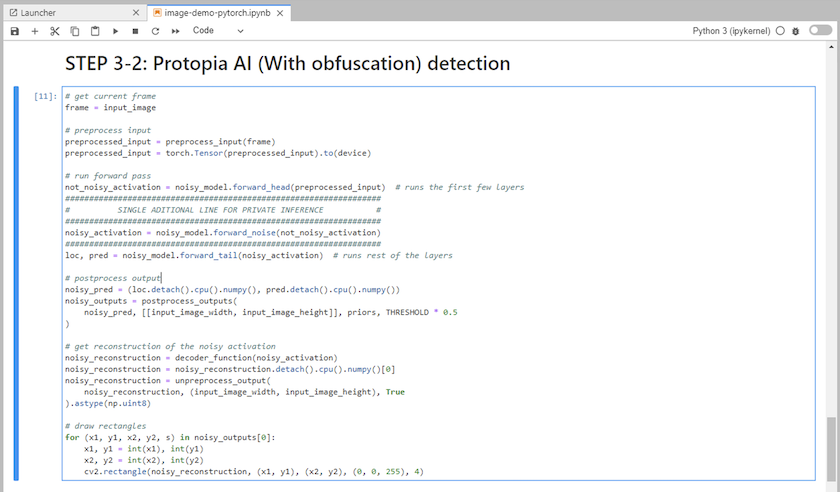
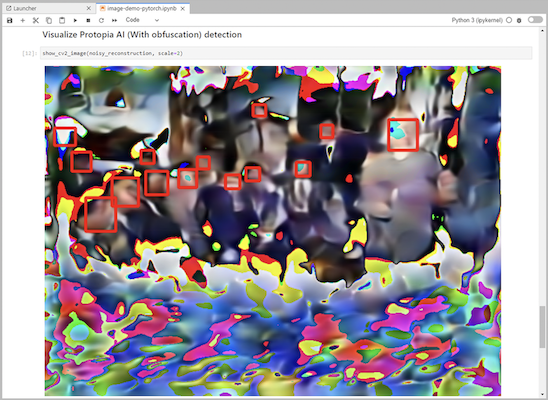
Scénario 2 – Inférence par lots sur Kubernetes
-
Créez un espace de noms Kubernetes pour les charges de travail d’inférence AI/ML.
$ kubectl create namespace inference namespace/inference created
-
Utilisez la boîte à outils NetApp DataOps pour provisionner un volume persistant pour stocker les données sur lesquelles vous effectuerez l’inférence.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Remplissez le nouveau volume persistant avec les données sur lesquelles vous effectuerez l’inférence.
Il existe plusieurs méthodes pour charger des données sur un PVC. Si vos données sont actuellement stockées sur une plateforme de stockage d'objets compatible S3, telle que NetApp StorageGRID ou Amazon S3, vous pouvez utiliser "Fonctionnalités de NetApp DataOps Toolkit S3 Data Mover" . Une autre méthode simple consiste à créer un espace de travail JupyterLab, puis à télécharger des fichiers via l'interface Web JupyterLab, comme indiqué dans les étapes 3 à 5 de la section «Scénario 1 – Inférence à la demande dans JupyterLab ."
-
Créez une tâche Kubernetes pour votre tâche d’inférence par lots. L'exemple suivant montre un travail d'inférence par lots pour un cas d'utilisation de détection d'images. Ce travail effectue des inférences sur chaque image d'un ensemble d'images et écrit les mesures de précision des inférences sur stdout.
$ vi inference-job-raw.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-raw namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-raw.yaml job.batch/netapp-inference-raw created -
Confirmez que le travail d’inférence s’est terminé avec succès.
$ kubectl -n inference logs netapp-inference-raw-255sp 100%|██████████| 89/89 [00:52<00:00, 1.68it/s] Reading Predictions : 100%|██████████| 10/10 [00:01<00:00, 6.23it/s] Predicting ... : 100%|██████████| 10/10 [00:16<00:00, 1.64s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.9491256561145955 FDDB-fold-2 Val AP: 0.9205024466101926 FDDB-fold-3 Val AP: 0.9253013871078468 FDDB-fold-4 Val AP: 0.9399781485863011 FDDB-fold-5 Val AP: 0.9504280149478732 FDDB-fold-6 Val AP: 0.9416473519339292 FDDB-fold-7 Val AP: 0.9241631566241117 FDDB-fold-8 Val AP: 0.9072663297546659 FDDB-fold-9 Val AP: 0.9339648715035469 FDDB-fold-10 Val AP: 0.9447707905560152 FDDB Dataset Average AP: 0.9337148153739079 ================================================= mAP: 0.9337148153739079
-
Ajoutez l’obfuscation Protopia à votre travail d’inférence. Vous pouvez trouver des instructions spécifiques au cas d'utilisation pour ajouter l'obfuscation Protopia directement à partir de Protopia, ce qui n'entre pas dans le cadre de ce rapport technique. L'exemple suivant montre un travail d'inférence par lots pour un cas d'utilisation de détection de visage avec l'obfuscation Protopia ajoutée à l'aide d'une valeur ALPHA de 0,8. Ce travail applique l'obfuscation Protopia avant d'effectuer l'inférence pour chaque image d'un ensemble d'images, puis écrit les mesures de précision de l'inférence sur stdout.
Nous avons répété cette étape pour les valeurs ALPHA 0,05, 0,1, 0,2, 0,4, 0,6, 0,8, 0,9 et 0,95. Vous pouvez voir les résultats dans"Comparaison de la précision des inférences."
$ vi inference-job-protopia-0.8.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-protopia-0.8 namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent env: - name: ALPHA value: "0.8" command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB", "--alpha", "$(ALPHA)", "--noisy"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-protopia-0.8.yaml job.batch/netapp-inference-protopia-0.8 created -
Confirmez que le travail d’inférence s’est terminé avec succès.
$ kubectl -n inference logs netapp-inference-protopia-0.8-b4dkz 100%|██████████| 89/89 [01:05<00:00, 1.37it/s] Reading Predictions : 100%|██████████| 10/10 [00:02<00:00, 3.67it/s] Predicting ... : 100%|██████████| 10/10 [00:22<00:00, 2.24s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.8953066115834589 FDDB-fold-2 Val AP: 0.8819580264029936 FDDB-fold-3 Val AP: 0.8781107458462862 FDDB-fold-4 Val AP: 0.9085731346308461 FDDB-fold-5 Val AP: 0.9166445508275378 FDDB-fold-6 Val AP: 0.9101178994188819 FDDB-fold-7 Val AP: 0.8383443678423771 FDDB-fold-8 Val AP: 0.8476311547659464 FDDB-fold-9 Val AP: 0.8739624502111121 FDDB-fold-10 Val AP: 0.8905468076424851 FDDB Dataset Average AP: 0.8841195749171925 ================================================= mAP: 0.8841195749171925
Scénario 3 – Serveur d'inférence NVIDIA Triton
-
Créez un espace de noms Kubernetes pour les charges de travail d’inférence AI/ML.
$ kubectl create namespace inference namespace/inference created
-
Utilisez NetApp DataOps Toolkit pour provisionner un volume persistant à utiliser comme référentiel modèle pour le serveur d’inférence NVIDIA Triton.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=triton-model-repo --size=100Gi Creating PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'. PersistentVolumeClaim (PVC) 'triton-model-repo' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'.
-
Stockez votre modèle sur le nouveau volume persistant dans un "format" qui est reconnu par le serveur d'inférence NVIDIA Triton.
Il existe plusieurs méthodes pour charger des données sur un PVC. Une méthode simple consiste à créer un espace de travail JupyterLab, puis à télécharger des fichiers via l'interface Web JupyterLab, comme indiqué dans les étapes 3 à 5 de «Scénario 1 – Inférence à la demande dans JupyterLab . "
-
Utilisez NetApp DataOps Toolkit pour déployer une nouvelle instance de NVIDIA Triton Inference Server.
$ netapp_dataops_k8s_cli.py create triton-server --namespace=inference --server-name=netapp-inference --model-repo-pvc-name=triton-model-repo Creating Service 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Service successfully created. Creating Deployment 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Deployment 'ntap-dsutil-triton-netapp-inference' created. Waiting for Deployment 'ntap-dsutil-triton-netapp-inference' to reach Ready state. Deployment successfully created. Server successfully created. Server endpoints: http: 192.168.0.152: 31208 grpc: 192.168.0.152: 32736 metrics: 192.168.0.152: 30009/metrics
-
Utilisez un SDK client Triton pour effectuer une tâche d’inférence. L'extrait de code Python suivant utilise le SDK client Python Triton pour effectuer une tâche d'inférence pour un cas d'utilisation de détection de visage. Cet exemple appelle l’API Triton et transmet une image pour l’inférence. Le serveur d'inférence Triton reçoit ensuite la demande, appelle le modèle et renvoie la sortie d'inférence dans le cadre des résultats de l'API.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass clean_activation = clean_model_head(preprocessed_input) # runs the first few layers ###################################################################################### # pass clean image to Triton Inference Server API for inferencing # ###################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_base" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(clean_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ###################################################################################### # postprocess output clean_pred = (loc_numpy, pred_numpy) clean_outputs = postprocess_outputs( clean_pred, [[input_image_width, input_image_height]], priors, THRESHOLD ) # draw rectangles clean_frame = copy.deepcopy(frame) # needs to be deep copy for (x1, y1, x2, y2, s) in clean_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(clean_frame, (x1, y1), (x2, y2), (0, 0, 255), 4) -
Ajoutez l’obfuscation Protopia à votre code d’inférence. Vous pouvez trouver des instructions spécifiques au cas d'utilisation pour ajouter l'obfuscation Protopia directement à partir de Protopia ; cependant, ce processus n'entre pas dans le cadre de ce rapport technique. L'exemple suivant montre le même code Python que celui présenté à l'étape 5 précédente, mais avec l'obfuscation Protopia ajoutée.
Notez que l'obfuscation Protopia est appliquée à l'image avant qu'elle ne soit transmise à l'API Triton. Ainsi, l’image non obscurcie ne quitte jamais la machine locale. Seule l’image obscurcie est transmise sur le réseau. Ce flux de travail s'applique aux cas d'utilisation dans lesquels les données sont collectées dans une zone de confiance, mais doivent ensuite être transmises en dehors de cette zone de confiance pour l'inférence. Sans l'obfuscation Protopia, il n'est pas possible de mettre en œuvre ce type de flux de travail sans que des données sensibles ne quittent la zone de confiance.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass not_noisy_activation = noisy_model_head(preprocessed_input) # runs the first few layers ################################################################## # obfuscate image locally prior to inferencing # # SINGLE ADITIONAL LINE FOR PRIVATE INFERENCE # ################################################################## noisy_activation = noisy_model_noise(not_noisy_activation) ################################################################## ########################################################################################### # pass obfuscated image to Triton Inference Server API for inferencing # ########################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_noisy" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(noisy_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ########################################################################################### # postprocess output noisy_pred = (loc_numpy, pred_numpy) noisy_outputs = postprocess_outputs( noisy_pred, [[input_image_width, input_image_height]], priors, THRESHOLD * 0.5 ) # get reconstruction of the noisy activation noisy_reconstruction = decoder_function(noisy_activation) noisy_reconstruction = noisy_reconstruction.detach().cpu().numpy()[0] noisy_reconstruction = unpreprocess_output( noisy_reconstruction, (input_image_width, input_image_height), True ).astype(np.uint8) # draw rectangles for (x1, y1, x2, y2, s) in noisy_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(noisy_reconstruction, (x1, y1), (x2, y2), (0, 0, 255), 4)