

Exemple de workflow : Entraîner un modèle de reconnaissance d'images à l'aide de Kubeflow et de la boîte à outils NetApp DataOps
 Suggérer des modifications
Suggérer des modifications
Cette section décrit les étapes impliquées dans la formation et le déploiement d'un réseau neuronal pour la reconnaissance d'images à l'aide de Kubeflow et de NetApp DataOps Toolkit. Ceci est destiné à servir d'exemple pour montrer un travail de formation qui intègre le stockage NetApp .
Prérequis
Créez un Dockerfile avec les configurations requises à utiliser pour les étapes de train et de test dans le pipeline Kubeflow. Voici un exemple de Dockerfile -
FROM pytorch/pytorch:latest
RUN pip install torchvision numpy scikit-learn matplotlib tensorboard
WORKDIR /app
COPY . /app
COPY train_mnist.py /app/train_mnist.py
CMD ["python", "train_mnist.py"]En fonction de vos besoins, installez toutes les bibliothèques et packages requis pour exécuter le programme. Avant de former le modèle d’apprentissage automatique, il est supposé que vous disposez déjà d’un déploiement Kubeflow fonctionnel.
Entraîner un petit NN sur des données MNIST à l'aide de pipelines PyTorch et Kubeflow
Nous utilisons l’exemple d’un petit réseau neuronal formé sur des données MNIST. L'ensemble de données MNIST se compose d'images manuscrites de chiffres de 0 à 9. Les images ont une taille de 28x28 pixels. L'ensemble de données est divisé en 60 000 images de train et 10 000 images de validation. Le réseau neuronal utilisé pour cette expérience est un réseau à propagation directe à 2 couches. La formation est exécutée à l’aide de Kubeflow Pipelines. Se référer à la documentation "ici" pour plus d'informations. Notre pipeline Kubeflow intègre l'image Docker de la section Prérequis.
Visualiser les résultats à l'aide de Tensorboard
Une fois le modèle formé, nous pouvons visualiser les résultats à l’aide de Tensorboard. "Panneau Tensorboard" est disponible en tant que fonctionnalité sur le tableau de bord Kubeflow. Vous pouvez créer un tensorboard personnalisé pour votre travail. Un exemple ci-dessous montre le graphique de la précision de l'entraînement par rapport au nombre d'époques et de la perte d'entraînement par rapport au nombre d'époques.

Expérimenter avec des hyperparamètres à l'aide de Katib
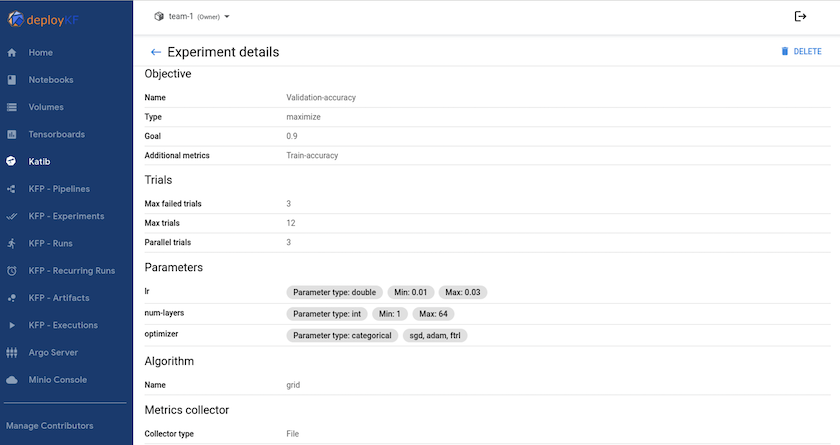
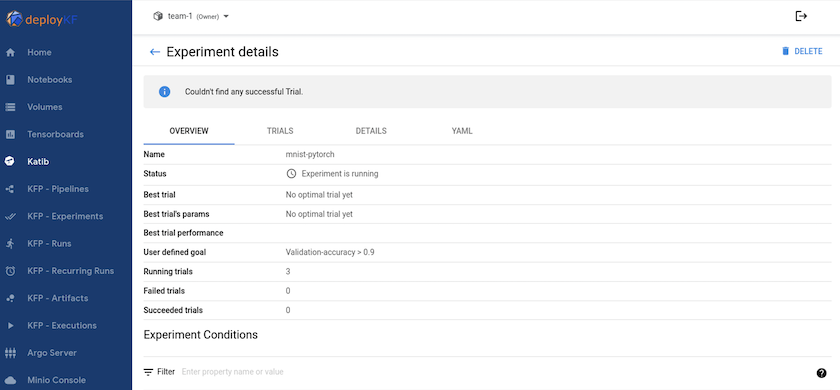
"Katib"est un outil au sein de Kubeflow qui peut être utilisé pour expérimenter les hyperparamètres du modèle. Pour créer une expérience, définissez d’abord une métrique/un objectif souhaité. Il s’agit généralement de la précision du test. Une fois la métrique définie, choisissez les hyperparamètres avec lesquels vous souhaitez jouer (optimiseur/taux d'apprentissage/nombre de couches). Katib effectue un balayage d'hyperparamètres avec les valeurs définies par l'utilisateur pour trouver la meilleure combinaison de paramètres qui satisfont la métrique souhaitée. Vous pouvez définir ces paramètres dans chaque section de l'interface utilisateur. Alternativement, vous pouvez définir un fichier YAML avec les spécifications nécessaires. Ci-dessous, une illustration d'une expérience Katib -
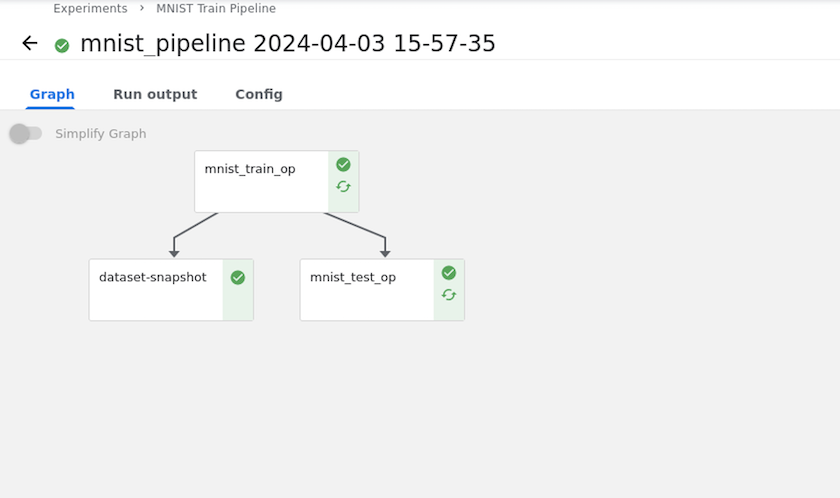
Utilisez les instantanés NetApp pour enregistrer les données à des fins de traçabilité
Pendant la formation du modèle, nous souhaiterons peut-être enregistrer un instantané de l'ensemble de données de formation à des fins de traçabilité. Pour ce faire, nous pouvons ajouter une étape d’instantané au pipeline comme indiqué ci-dessous. Pour créer l'instantané, nous pouvons utiliser le "Boîte à outils NetApp DataOps pour Kubernetes" .

Se référer à la "Exemple de boîte à outils NetApp DataOps pour Kubeflow" pour plus d'informations.