

Exécuter une charge de travail d'IA distribuée synchrone
 Suggérer des modifications
Suggérer des modifications
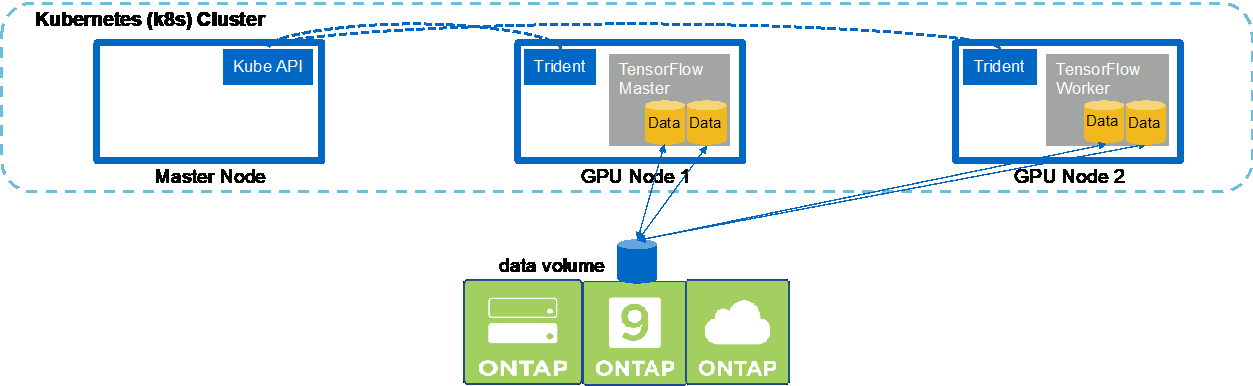
Pour exécuter une tâche IA et ML multinœud synchrone dans votre cluster Kubernetes, effectuez les tâches suivantes sur l'hôte de saut de déploiement. Ce processus vous permet de tirer parti des données stockées sur un volume NetApp et d’utiliser plus de GPU qu’un seul nœud de travail ne peut en fournir. Consultez la figure suivante pour une représentation d’un travail d’IA distribué synchrone.

|
Les tâches distribuées synchrones peuvent aider à augmenter les performances et la précision de la formation par rapport aux tâches distribuées asynchrones. Une discussion sur les avantages et les inconvénients des tâches synchrones par rapport aux tâches asynchrones n’entre pas dans le cadre de ce document. |
-
Les exemples de commandes suivants montrent la création d'un worker qui participe à l'exécution distribuée synchrone du même travail de référence TensorFlow qui a été exécuté sur un seul nœud dans l'exemple de la section"Exécuter une charge de travail d'IA à nœud unique" . Dans cet exemple spécifique, un seul travailleur est déployé car le travail est exécuté sur deux nœuds de travail.
Cet exemple de déploiement de travailleur nécessite huit GPU et peut donc s'exécuter sur un seul nœud de travail GPU doté de huit GPU ou plus. Si vos nœuds de travail GPU comportent plus de huit GPU, pour optimiser les performances, vous souhaiterez peut-être augmenter ce nombre pour qu'il soit égal au nombre de GPU dont disposent vos nœuds de travail. Pour plus d'informations sur les déploiements Kubernetes, consultez le "documentation officielle de Kubernetes" .
Un déploiement Kubernetes est créé dans cet exemple car ce travailleur conteneurisé spécifique ne se terminerait jamais tout seul. Par conséquent, il n’est pas logique de le déployer en utilisant la construction de tâche Kubernetes. Si votre worker est conçu ou écrit pour s'exécuter de manière autonome, il peut être judicieux d'utiliser la construction de tâche pour déployer votre worker.
Le pod spécifié dans cet exemple de spécification de déploiement reçoit un
hostNetworkvaleur detrue. Cette valeur signifie que le pod utilise la pile réseau du nœud de travail hôte au lieu de la pile réseau virtuelle que Kubernetes crée habituellement pour chaque pod. Cette annotation est utilisée dans ce cas car la charge de travail spécifique s'appuie sur Open MPI, NCCL et Horovod pour exécuter la charge de travail de manière distribuée synchrone. Par conséquent, il nécessite un accès à la pile réseau de l'hôte. Une discussion sur Open MPI, NCCL et Horovod sort du cadre de ce document. Que cela soit ou nonhostNetwork: trueL'annotation est nécessaire en fonction des exigences de la charge de travail spécifique que vous exécutez. Pour plus d'informations sur lehostNetworkchamp, voir le "documentation officielle de Kubernetes" .$ cat << EOF > ./netapp-tensorflow-multi-imagenet-worker.yaml apiVersion: apps/v1 kind: Deployment metadata: name: netapp-tensorflow-multi-imagenet-worker spec: replicas: 1 selector: matchLabels: app: netapp-tensorflow-multi-imagenet-worker template: metadata: labels: app: netapp-tensorflow-multi-imagenet-worker spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["bash", "/netapp/scripts/start-slave-multi.sh", "22122"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-worker.yaml deployment.apps/netapp-tensorflow-multi-imagenet-worker created $ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 4s -
Confirmez que le déploiement de travail que vous avez créé à l’étape 1 a été lancé avec succès. Les exemples de commandes suivants confirment qu'un seul pod de travail a été créé pour le déploiement, comme indiqué dans la définition de déploiement, et que ce pod est actuellement en cours d'exécution sur l'un des nœuds de travail GPU.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 60s 10.61.218.154 10.61.218.154 <none> $ kubectl logs netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 22122
-
Créez une tâche Kubernetes pour un maître qui démarre, participe et suit l’exécution de la tâche multinœud synchrone. Les exemples de commandes suivants créent un maître qui lance, participe et suit l'exécution distribuée synchrone du même travail de référence TensorFlow qui a été exécuté sur un seul nœud dans l'exemple de la section"Exécuter une charge de travail d'IA à nœud unique" .
Cet exemple de tâche principale demande huit GPU et peut donc s'exécuter sur un seul nœud de travail GPU doté de huit GPU ou plus. Si vos nœuds de travail GPU comportent plus de huit GPU, pour optimiser les performances, vous souhaiterez peut-être augmenter ce nombre pour qu'il soit égal au nombre de GPU dont disposent vos nœuds de travail.
Le pod maître spécifié dans cet exemple de définition de tâche reçoit un
hostNetworkvaleur detrue, tout comme le groupe de travailleurs a reçu unhostNetworkvaleur detrueà l'étape 1. Consultez l’étape 1 pour plus de détails sur la raison pour laquelle cette valeur est nécessaire.$ cat << EOF > ./netapp-tensorflow-multi-imagenet-master.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-tensorflow-multi-imagenet-master spec: backoffLimit: 5 template: spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["python", "/netapp/scripts/run.py", "--dataset_dir=/mnt/mount_0/dataset/imagenet", "--port=22122", "--num_devices=16", "--dgx_version=dgx1", "--nodes=10.61.218.152,10.61.218.154"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true restartPolicy: Never EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-master.yaml job.batch/netapp-tensorflow-multi-imagenet-master created $ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 0/1 25s 25s -
Confirmez que le travail principal que vous avez créé à l’étape 3 s’exécute correctement. L'exemple de commande suivant confirme qu'un seul pod maître a été créé pour le travail, comme indiqué dans la définition du travail, et que ce pod est actuellement en cours d'exécution sur l'un des nœuds de travail GPU. Vous devriez également voir que le pod de travail que vous avez vu à l’origine à l’étape 1 est toujours en cours d’exécution et que les pods maître et de travail s’exécutent sur des nœuds différents.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-master-ppwwj 1/1 Running 0 45s 10.61.218.152 10.61.218.152 <none> netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 26m 10.61.218.154 10.61.218.154 <none>
-
Confirmez que le travail principal que vous avez créé à l’étape 3 se termine avec succès. Les exemples de commandes suivants confirment que le travail s'est terminé avec succès.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 9m18s $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 9m38s netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 35m $ kubectl logs netapp-tensorflow-multi-imagenet-master-ppwwj [10.61.218.152:00008] WARNING: local probe returned unhandled shell:unknown assuming bash rm: cannot remove '/lib': Is a directory [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 Total images/sec = 12881.33875 ================ Clean Cache !!! ================== mpirun -allow-run-as-root -np 2 -H 10.61.218.152:1,10.61.218.154:1 -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" bash -c 'sync; echo 1 > /proc/sys/vm/drop_caches' ========================================= mpirun -allow-run-as-root -np 16 -H 10.61.218.152:8,10.61.218.154:8 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -x NCCL_IB_HCA=mlx5 -x NCCL_NET_GDR_READ=1 -x NCCL_IB_SL=3 -x NCCL_IB_GID_INDEX=3 -x NCCL_SOCKET_IFNAME=enp5s0.3091,enp12s0.3092,enp132s0.3093,enp139s0.3094 -x NCCL_IB_CUDA_SUPPORT=1 -mca orte_base_help_aggregate 0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" python /netapp/tensorflow/benchmarks_190205/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=256 --device=gpu --force_gpu_compatible=True --num_intra_threads=1 --num_inter_threads=48 --variable_update=horovod --batch_group_size=20 --num_batches=500 --nodistortions --num_gpus=1 --data_format=NCHW --use_fp16=True --use_tf_layers=False --data_name=imagenet --use_datasets=True --data_dir=/mnt/mount_0/dataset/imagenet --datasets_parallel_interleave_cycle_length=10 --datasets_sloppy_parallel_interleave=False --num_mounts=2 --mount_prefix=/mnt/mount_%d --datasets_prefetch_buffer_size=2000 -- datasets_use_prefetch=True --datasets_num_private_threads=4 --horovod_device=gpu > /tmp/20190814_161609_tensorflow_horovod_rdma_resnet50_gpu_16_256_b500_imagenet_nodistort_fp16_r10_m2_nockpt.txt 2>&1
-
Supprimez le déploiement du travailleur lorsque vous n’en avez plus besoin. Les exemples de commandes suivants montrent la suppression de l’objet de déploiement Worker créé à l’étape 1.
Lorsque vous supprimez l’objet de déploiement de travail, Kubernetes supprime automatiquement tous les pods de travail associés.
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 43m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 17m netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 43m $ kubectl delete deployment netapp-tensorflow-multi-imagenet-worker deployment.extensions "netapp-tensorflow-multi-imagenet-worker" deleted $ kubectl get deployments No resources found. $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 18m
-
Facultatif : Nettoyez les artefacts du travail principal. Les exemples de commandes suivants montrent la suppression de l’objet de travail principal créé à l’étape 3.
Lorsque vous supprimez l’objet de tâche principal, Kubernetes supprime automatiquement tous les pods principaux associés.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 19m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 19m $ kubectl delete job netapp-tensorflow-multi-imagenet-master job.batch "netapp-tensorflow-multi-imagenet-master" deleted $ kubectl get jobs No resources found. $ kubectl get pods No resources found.