

Base de données vectorielles
 Suggérer des modifications
Suggérer des modifications
Cette section couvre la définition et l’utilisation d’une base de données vectorielle dans les solutions NetApp AI.
Base de données vectorielles
Une base de données vectorielle est un type de base de données spécialisé conçu pour gérer, indexer et rechercher des données non structurées à l'aide d'intégrations provenant de modèles d'apprentissage automatique. Au lieu d'organiser les données dans un format tabulaire traditionnel, il organise les données sous forme de vecteurs de grande dimension, également appelés plongements vectoriels. Cette structure unique permet à la base de données de gérer des données complexes et multidimensionnelles de manière plus efficace et plus précise.
L’une des principales capacités d’une base de données vectorielle est son utilisation de l’IA générative pour effectuer des analyses. Cela inclut les recherches de similarité, où la base de données identifie les points de données qui ressemblent à une entrée donnée, et la détection d'anomalies, où elle peut repérer les points de données qui s'écartent considérablement de la norme.
De plus, les bases de données vectorielles sont bien adaptées pour gérer des données temporelles ou des données horodatées. Ce type de données fournit des informations sur « ce » qui s'est produit et quand cela s'est produit, dans l'ordre et par rapport à tous les autres événements au sein d'un système informatique donné. Cette capacité à gérer et à analyser des données temporelles rend les bases de données vectorielles particulièrement utiles pour les applications qui nécessitent une compréhension des événements au fil du temps.
Avantages de la base de données vectorielle pour le ML et l'IA :
-
Recherche à haute dimension : les bases de données vectorielles excellent dans la gestion et la récupération de données à haute dimension, qui sont souvent générées dans les applications d'IA et de ML.
-
Évolutivité : ils peuvent évoluer efficacement pour gérer de grands volumes de données, soutenant ainsi la croissance et l'expansion des projets d'IA et de ML.
-
Flexibilité : les bases de données vectorielles offrent un haut degré de flexibilité, permettant l’hébergement de divers types et structures de données.
-
Performances : Ils offrent une gestion et une récupération de données hautes performances, essentielles à la rapidité et à l'efficacité des opérations d'IA et de ML.
-
Indexation personnalisable : les bases de données vectorielles offrent des options d'indexation personnalisables, permettant une organisation et une récupération optimisées des données en fonction de besoins spécifiques.
Bases de données vectorielles et cas d'utilisation.
Cette section fournit diverses bases de données vectorielles et les détails de leurs cas d'utilisation.
Faiss et ScaNN
Ce sont des bibliothèques qui servent d’outils essentiels dans le domaine de la recherche vectorielle. Ces bibliothèques offrent des fonctionnalités essentielles à la gestion et à la recherche de données vectorielles, ce qui en fait des ressources inestimables dans ce domaine spécialisé de la gestion des données.
Elasticsearch
Il s'agit d'un moteur de recherche et d'analyse largement utilisé, qui a récemment intégré des capacités de recherche vectorielle. Cette nouvelle fonctionnalité améliore ses fonctionnalités, lui permettant de gérer et de rechercher plus efficacement les données vectorielles.
Pomme de pin
Il s’agit d’une base de données vectorielle robuste dotée d’un ensemble unique de fonctionnalités. Il prend en charge les vecteurs denses et clairsemés dans sa fonctionnalité d'indexation, ce qui améliore sa flexibilité et son adaptabilité. L’un de ses principaux atouts réside dans sa capacité à combiner des méthodes de recherche traditionnelles avec une recherche vectorielle dense basée sur l’IA, créant ainsi une approche de recherche hybride qui exploite le meilleur des deux mondes.
Principalement basé sur le cloud, Pinecone est conçu pour les applications d'apprentissage automatique et s'intègre bien à une variété de plates-formes, notamment GCP, AWS, Open AI, GPT-3, GPT-3.5, GPT-4, Catgut Plus, Elasticsearch, Haystack, et plus encore. Il est important de noter que Pinecone est une plate-forme à source fermée et est disponible en tant qu'offre de logiciel en tant que service (SaaS).
Compte tenu de ses capacités avancées, Pinecone est particulièrement bien adapté au secteur de la cybersécurité, où ses capacités de recherche hautement dimensionnelle et de recherche hybride peuvent être exploitées efficacement pour détecter et répondre aux menaces.
Chroma
Il s'agit d'une base de données vectorielle dotée d'une API principale avec quatre fonctions principales, dont l'une comprend un magasin de vecteurs de documents en mémoire. Il utilise également la bibliothèque Face Transformers pour vectoriser les documents, améliorant ainsi sa fonctionnalité et sa polyvalence. Chroma est conçu pour fonctionner à la fois dans le cloud et sur site, offrant une flexibilité en fonction des besoins des utilisateurs. Il excelle particulièrement dans les applications liées à l'audio, ce qui en fait un excellent choix pour les moteurs de recherche basés sur l'audio, les systèmes de recommandation musicale et d'autres cas d'utilisation liés à l'audio.
Tisser
Il s'agit d'une base de données vectorielle polyvalente qui permet aux utilisateurs de vectoriser leur contenu à l'aide de ses modules intégrés ou de modules personnalisés, offrant une flexibilité en fonction des besoins spécifiques. Il propose des solutions entièrement gérées et auto-hébergées, répondant à une variété de préférences de déploiement.
L’une des principales caractéristiques de Weaviate est sa capacité à stocker à la fois des vecteurs et des objets, améliorant ainsi ses capacités de gestion des données. Il est largement utilisé pour une gamme d’applications, notamment la recherche sémantique et la classification des données dans les systèmes ERP. Dans le secteur du e-commerce, il alimente les moteurs de recherche et de recommandation. Weaviate est également utilisé pour la recherche d'images, la détection d'anomalies, l'harmonisation automatisée des données et l'analyse des menaces de cybersécurité, démontrant ainsi sa polyvalence dans plusieurs domaines.
Redis
Redis est une base de données vectorielle hautes performances connue pour son stockage rapide en mémoire, offrant une faible latence pour les opérations de lecture-écriture. Cela en fait un excellent choix pour les systèmes de recommandation, les moteurs de recherche et les applications d’analyse de données qui nécessitent un accès rapide aux données.
Redis prend en charge diverses structures de données pour les vecteurs, notamment les listes, les ensembles et les ensembles triés. Il fournit également des opérations vectorielles telles que le calcul des distances entre les vecteurs ou la recherche d'intersections et d'unions. Ces fonctionnalités sont particulièrement utiles pour la recherche de similarité, le clustering et les systèmes de recommandation basés sur le contenu.
En termes d'évolutivité et de disponibilité, Redis excelle dans la gestion des charges de travail à haut débit et offre la réplication des données. Il s’intègre également bien avec d’autres types de données, y compris les bases de données relationnelles traditionnelles (SGBDR). Redis inclut une fonctionnalité de publication/abonnement (Pub/Sub) pour les mises à jour en temps réel, ce qui est bénéfique pour la gestion des vecteurs en temps réel. De plus, Redis est léger et simple à utiliser, ce qui en fait une solution conviviale pour la gestion des données vectorielles.
Milvus
Il s'agit d'une base de données vectorielle polyvalente qui offre une API semblable à un magasin de documents, un peu comme MongoDB. Il se distingue par sa prise en charge d'une grande variété de types de données, ce qui en fait un choix populaire dans les domaines de la science des données et de l'apprentissage automatique.
L’une des fonctionnalités uniques de Milvus est sa capacité de multi-vectorisation, qui permet aux utilisateurs de spécifier au moment de l’exécution le type de vecteur à utiliser pour la recherche. De plus, il utilise Knowwhere, une bibliothèque qui se trouve au-dessus d'autres bibliothèques comme Faiss, pour gérer la communication entre les requêtes et les algorithmes de recherche vectorielle.
Milvus offre également une intégration transparente avec les workflows d'apprentissage automatique, grâce à sa compatibilité avec PyTorch et TensorFlow. Cela en fait un excellent outil pour une gamme d'applications, notamment le commerce électronique, l'analyse d'images et de vidéos, la reconnaissance d'objets, la recherche de similarité d'images et la récupération d'images basée sur le contenu. Dans le domaine du traitement du langage naturel, Milvus est utilisé pour le regroupement de documents, la recherche sémantique et les systèmes de réponses aux questions.
Pour cette solution, nous avons choisi Milvus pour la validation de la solution. Pour les performances, nous avons utilisé à la fois milvus et postgres (pgvecto.rs).
Pourquoi avons-nous choisi Milvus pour cette solution ?
-
Open-Source : Milvus est une base de données vectorielle open source, encourageant le développement et les améliorations pilotés par la communauté.
-
Intégration de l'IA : elle exploite l'intégration de la recherche de similarité et des applications d'IA pour améliorer les fonctionnalités de la base de données vectorielle.
-
Gestion de gros volumes : Milvus a la capacité de stocker, d'indexer et de gérer plus d'un milliard de vecteurs d'intégration générés par des modèles de réseaux neuronaux profonds (DNN) et d'apprentissage automatique (ML).
-
Convivial : il est facile à utiliser, la configuration prenant moins d'une minute. Milvus propose également des SDK pour différents langages de programmation.
-
Vitesse : Il offre des vitesses de récupération ultra-rapides, jusqu'à 10 fois plus rapides que certaines alternatives.
-
Évolutivité et disponibilité : Milvus est hautement évolutif, avec des options d'évolutivité et de mise à l'échelle selon les besoins.
-
Riche en fonctionnalités : il prend en charge différents types de données, le filtrage des attributs, la prise en charge des fonctions définies par l'utilisateur (UDF), les niveaux de cohérence configurables et le temps de trajet, ce qui en fait un outil polyvalent pour diverses applications.
Présentation de l'architecture Milvus
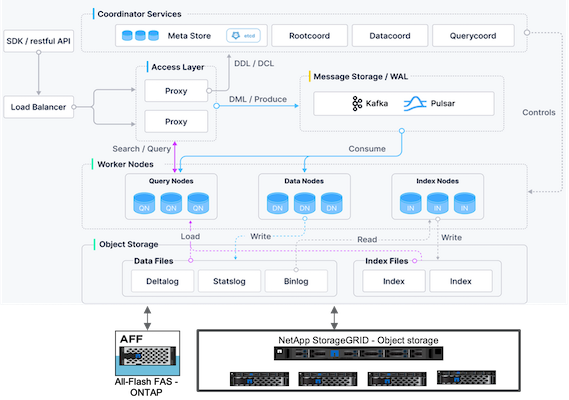
Cette section fournit des composants et des services de niveau supérieur utilisés dans l'architecture Milvus. * Couche d'accès – Elle est composée d'un groupe de proxys sans état et sert de couche frontale du système et de point de terminaison pour les utilisateurs. * Service de coordination – il attribue les tâches aux nœuds de travail et agit comme le cerveau du système. Il dispose de trois types de coordinateurs : coordonnées racine, coordonnées de données et coordonnées de requête. * Nœuds de travail : il suit les instructions du service de coordination et exécute les commandes DML/DDL déclenchées par l'utilisateur. Il dispose de trois types de nœuds de travail tels que le nœud de requête, le nœud de données et le nœud d'index. * Stockage : il est responsable de la persistance des données. Il comprend un stockage méta, un courtier de journaux et un stockage d'objets. Le stockage NetApp tel que ONTAP et StorageGRID fournit un stockage d'objets et un stockage basé sur des fichiers à Milvus pour les données client et les données de base de données vectorielles.