

Architecture
 Suggérer des modifications
Suggérer des modifications
Bien que Red Hat OpenShift et Trident soutenus par NetApp ONTAP ne fournissent pas d'isolation entre les charges de travail par défaut, ils offrent une large gamme de fonctionnalités qui peuvent être utilisées pour configurer la multilocation. Pour mieux comprendre la conception d’une solution multilocataire sur un cluster Red Hat OpenShift avec Trident soutenu par NetApp ONTAP, considérons un exemple avec un ensemble d’exigences et décrivons la configuration qui l’entoure.
Supposons qu’une organisation exécute deux de ses charges de travail sur un cluster Red Hat OpenShift dans le cadre de deux projets sur lesquels travaillent deux équipes différentes. Les données de ces charges de travail résident sur des PVC provisionnés dynamiquement par Trident sur un backend NAS NetApp ONTAP . L'organisation a besoin de concevoir une solution multilocataire pour ces deux charges de travail et d'isoler les ressources utilisées pour ces projets afin de garantir que la sécurité et les performances sont maintenues, principalement axées sur les données qui servent ces applications.
La figure suivante illustre la solution multilocataire sur un cluster Red Hat OpenShift avec Trident soutenu par NetApp ONTAP.
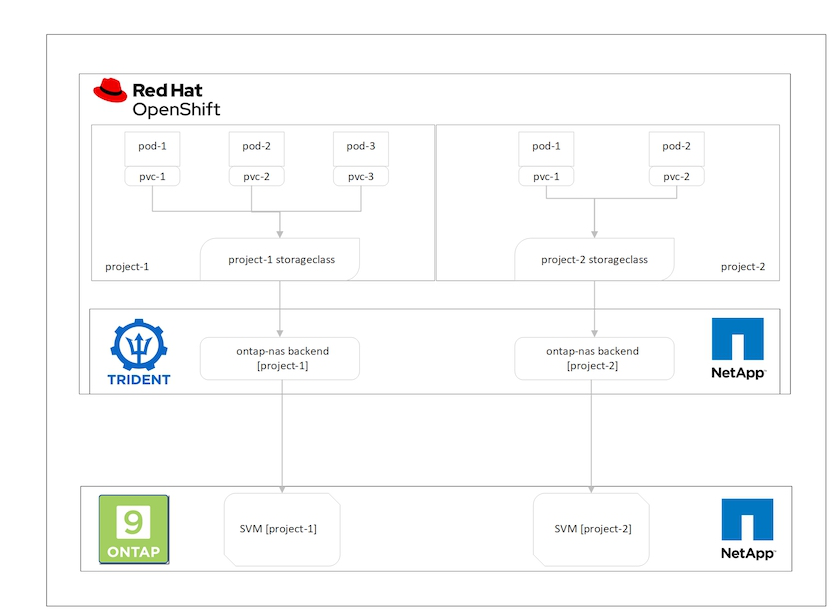
Exigences technologiques
-
Cluster de stockage NetApp ONTAP
-
Cluster Red Hat OpenShift
-
Trident
Red Hat OpenShift – Ressources de cluster
Du point de vue du cluster Red Hat OpenShift, la ressource de niveau supérieur par laquelle commencer est le projet. Un projet OpenShift peut être considéré comme une ressource de cluster qui divise l’ensemble du cluster OpenShift en plusieurs clusters virtuels. Par conséquent, l’isolement au niveau du projet fournit une base pour la configuration de la multilocation.
L’étape suivante consiste à configurer RBAC dans le cluster. La meilleure pratique consiste à configurer tous les développeurs travaillant sur un seul projet ou une seule charge de travail dans un seul groupe d’utilisateurs dans le fournisseur d’identité (IdP). Red Hat OpenShift permet l'intégration IdP et la synchronisation des groupes d'utilisateurs, permettant ainsi aux utilisateurs et aux groupes de l'IdP d'être importés dans le cluster. Cela aide les administrateurs de cluster à séparer l'accès aux ressources de cluster dédiées à un projet à un ou plusieurs groupes d'utilisateurs travaillant sur ce projet, limitant ainsi l'accès non autorisé à toutes les ressources de cluster. Pour en savoir plus sur l'intégration d'IdP avec Red Hat OpenShift, consultez la documentation "ici" .
NetApp ONTAP
Il est important d'isoler le stockage partagé servant de fournisseur de stockage persistant pour un cluster Red Hat OpenShift afin de garantir que les volumes créés sur le stockage pour chaque projet apparaissent aux hôtes comme s'ils étaient créés sur un stockage séparé. Pour ce faire, créez autant de SVM (machines virtuelles de stockage) sur NetApp ONTAP qu'il y a de projets ou de charges de travail, et dédiez chaque SVM à une charge de travail.
Trident
Une fois que vous avez créé différents SVM pour différents projets sur NetApp ONTAP, vous devez mapper chaque SVM à un backend Trident différent. La configuration du backend sur Trident pilote l'allocation du stockage persistant aux ressources du cluster OpenShift et nécessite que les détails du SVM soient mappés. Cela devrait être au minimum le pilote de protocole pour le backend. En option, il vous permet de définir comment les volumes sont provisionnés sur le stockage et de définir des limites pour la taille des volumes ou l'utilisation des agrégats, etc. Les détails concernant la définition des backends Trident peuvent être trouvés "ici" .
Red Hat OpenShift – ressources de stockage
Après avoir configuré les backends Trident , l’étape suivante consiste à configurer les StorageClasses. Configurez autant de classes de stockage qu'il y a de backends, en fournissant à chaque classe de stockage l'accès pour faire tourner des volumes uniquement sur un backend. Nous pouvons mapper la StorageClass à un backend Trident particulier en utilisant le paramètre storagePools lors de la définition de la classe de stockage. Les détails pour définir une classe de stockage peuvent être trouvés "ici" . Il existe donc un mappage un à un de StorageClass vers le backend Trident qui pointe vers un SVM. Cela garantit que toutes les demandes de stockage via la StorageClass attribuée à ce projet sont traitées par le SVM dédié à ce projet uniquement.
Étant donné que les classes de stockage ne sont pas des ressources d'espace de noms, comment pouvons-nous garantir que les revendications de stockage sur la classe de stockage d'un projet par des pods dans un autre espace de noms ou projet soient rejetées ? La réponse est d’utiliser ResourceQuotas. Les ResourceQuotas sont des objets qui contrôlent l'utilisation totale des ressources par projet. Il peut limiter le nombre ainsi que la quantité totale de ressources pouvant être consommées par les objets du projet. Presque toutes les ressources d'un projet peuvent être limitées à l'aide de ResourceQuotas et leur utilisation efficace peut aider les organisations à réduire les coûts et les pannes dues au surprovisionnement ou à la surconsommation de ressources. Se référer à la documentation "ici" pour plus d'informations.
Pour ce cas d'utilisation, nous devons empêcher les pods d'un projet particulier de réclamer du stockage à partir de classes de stockage qui ne sont pas dédiées à leur projet. Pour ce faire, nous devons limiter les revendications de volume persistant pour d’autres classes de stockage en définissant <storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaims à 0. De plus, un administrateur de cluster doit s’assurer que les développeurs d’un projet ne doivent pas avoir accès à la modification des ResourceQuotas.