

Premiers pas avec le cloud public AWS
 Suggérer des modifications
Suggérer des modifications
Cette section décrit le processus de déploiement de Cloud Manager et de Cloud Volumes ONTAP dans AWS.
Cloud public AWS

|
Pour faciliter le suivi, nous avons créé ce document basé sur un déploiement dans AWS. Cependant, le processus est très similaire pour Azure et GCP. |
[[1-pre-flight-check]]
=== 1. Contrôle pré-vol
Avant le déploiement, assurez-vous que l’infrastructure est en place pour permettre le déploiement à l’étape suivante. Cela comprend les éléments suivants :
-
compte AWS
-
VPC dans la région de votre choix
-
Sous-réseau avec accès à l'Internet public
-
Autorisations pour ajouter des rôles IAM à votre compte AWS
-
Une clé secrète et une clé d'accès pour votre utilisateur AWS
[[2-steps-to-deploy-cloud-manager-and-cloud-volumes-ontap-in-aws]]
=== 2. Étapes pour déployer Cloud Manager et Cloud Volumes ONTAP dans AWS
|
|
Il existe de nombreuses méthodes pour déployer Cloud Manager et Cloud Volumes ONTAP; cette méthode est la plus simple mais nécessite le plus d'autorisations. Si cette méthode n'est pas adaptée à votre environnement AWS, veuillez consulter le "Documentation NetApp Cloud" . |
Déployer le connecteur Cloud Manager
-
Accéder à "NetApp BlueXP" et connectez-vous ou inscrivez-vous.
-
Après vous être connecté, vous devriez être redirigé vers le Canvas.
-
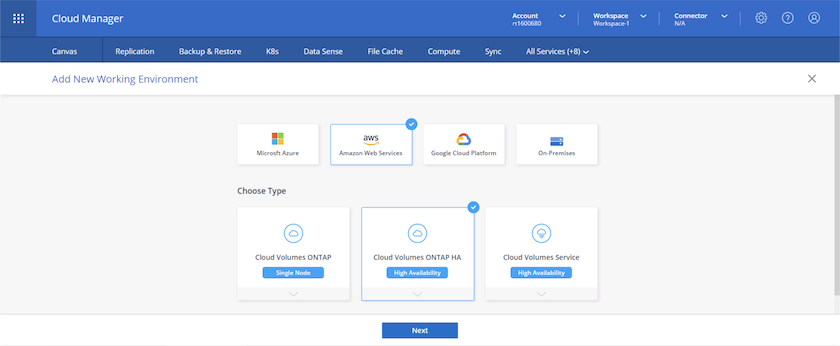
Cliquez sur « Ajouter un environnement de travail » et choisissez Cloud Volumes ONTAP dans AWS. Ici, vous choisissez également si vous souhaitez déployer un système à nœud unique ou une paire à haute disponibilité. J'ai choisi de déployer une paire haute disponibilité.
-
Si aucun connecteur n'a été créé, une fenêtre contextuelle apparaît vous demandant de créer un connecteur.
-
Cliquez sur Commencer, puis choisissez AWS.
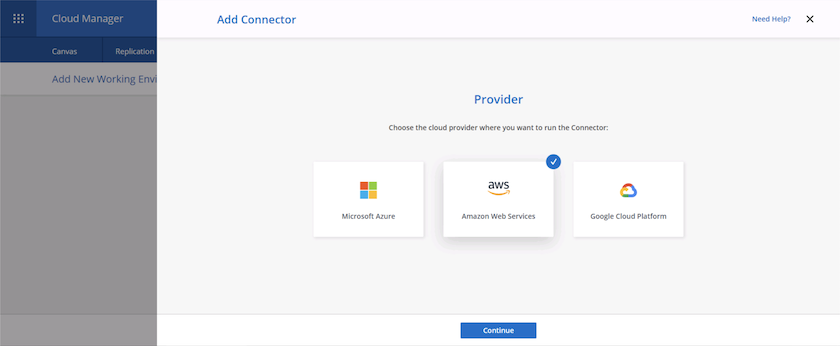
-
Entrez votre clé secrète et votre clé d'accès. Assurez-vous que votre utilisateur dispose des autorisations appropriées décrites sur le "Page des politiques NetApp" .
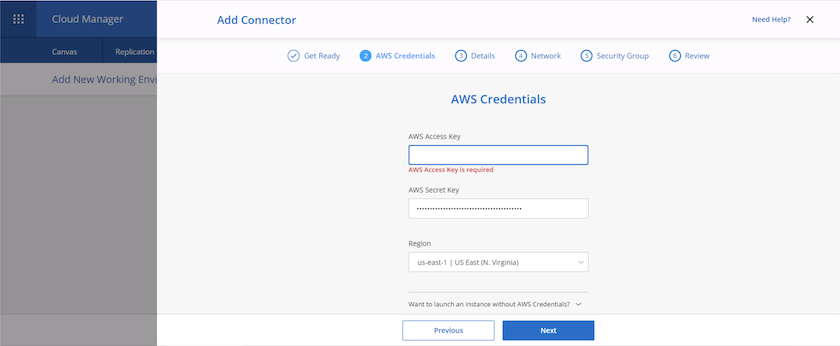
-
Donnez un nom au connecteur et utilisez un rôle prédéfini comme décrit sur le "Page des politiques NetApp" ou demandez à Cloud Manager de créer le rôle pour vous.
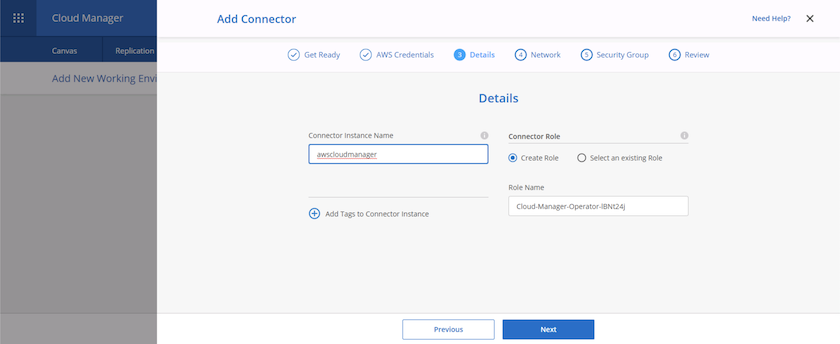
-
Fournissez les informations réseau nécessaires au déploiement du connecteur. Vérifiez que l'accès Internet sortant est activé en :
-
Attribuer au connecteur une adresse IP publique
-
Donner au connecteur un proxy pour fonctionner
-
Donner au connecteur un itinéraire vers l'Internet public via une passerelle Internet
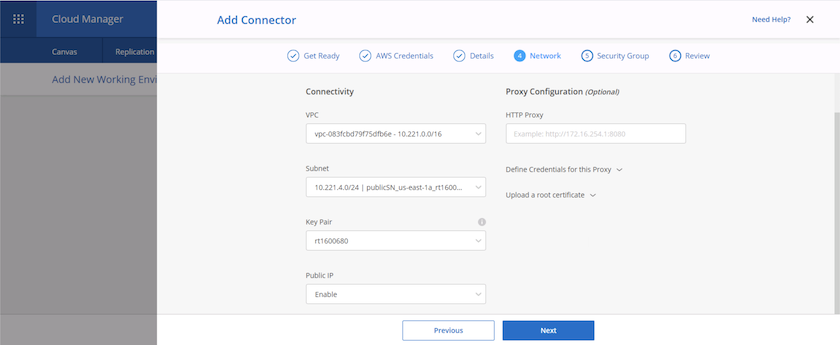
-
-
Assurez la communication avec le connecteur via SSH, HTTP et HTTPS en fournissant un groupe de sécurité ou en créant un nouveau groupe de sécurité. J'ai activé l'accès au connecteur à partir de mon adresse IP uniquement.
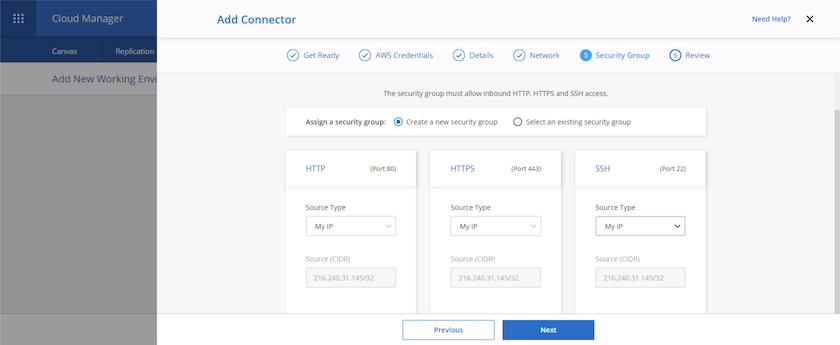
-
Consultez les informations sur la page récapitulative et cliquez sur Ajouter pour déployer le connecteur.
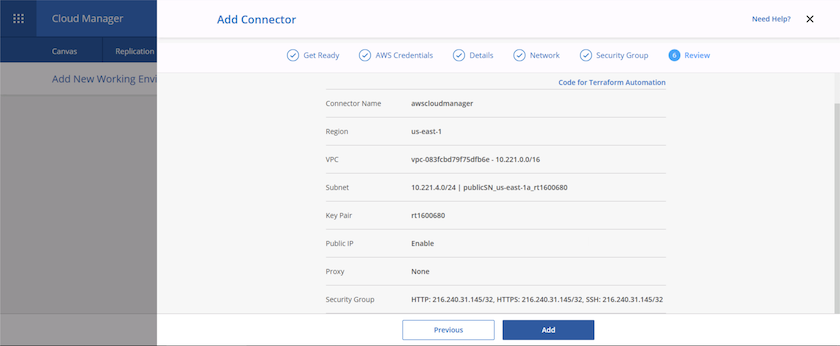
-
Le connecteur se déploie désormais à l’aide d’une pile de formation cloud. Vous pouvez suivre sa progression depuis Cloud Manager ou via AWS.
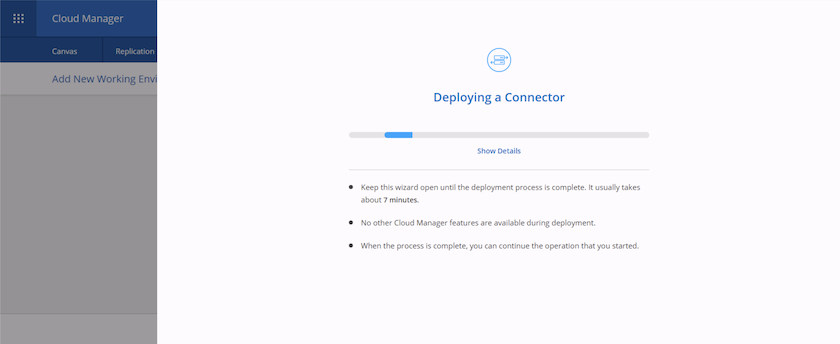
-
Une fois le déploiement terminé, une page de réussite s’affiche.
Déployer Cloud Volumes ONTAP
-
Sélectionnez AWS et le type de déploiement en fonction de vos besoins.
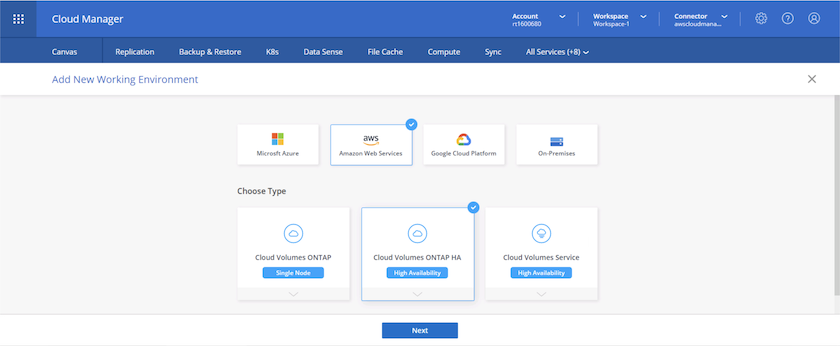
-
Si aucun abonnement n'a été attribué et que vous souhaitez acheter avec PAYGO, choisissez Modifier les informations d'identification.
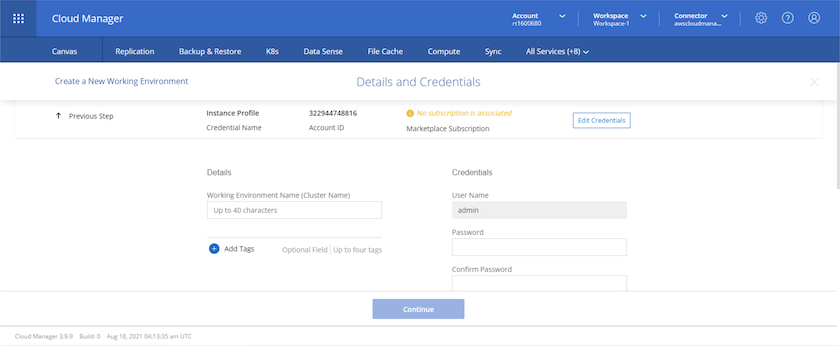
-
Choisissez Ajouter un abonnement.
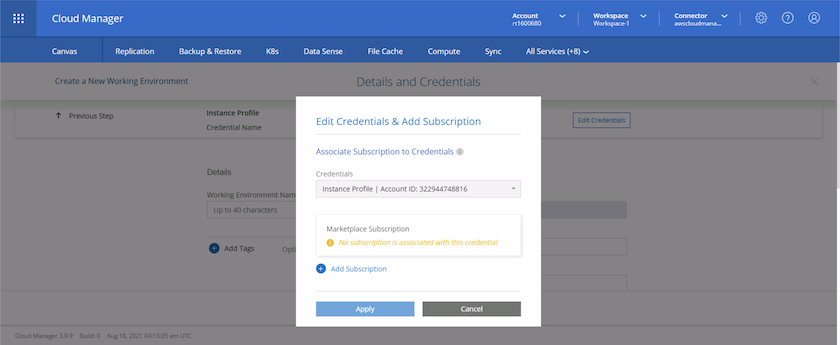
-
Choisissez le type de contrat auquel vous souhaitez souscrire. J'ai choisi le paiement à l'utilisation.
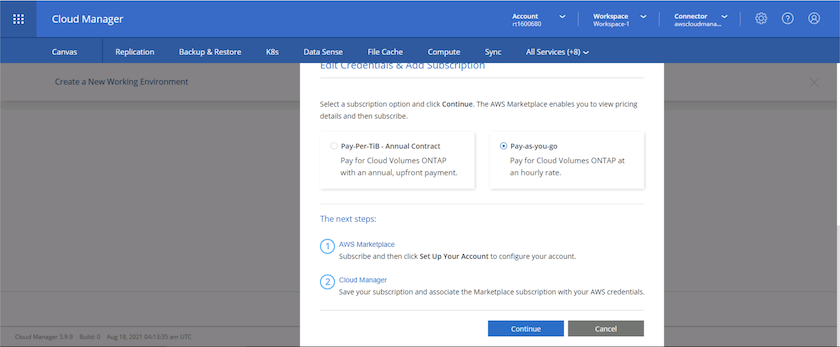
-
Vous êtes redirigé vers AWS ; choisissez Continuer pour vous abonner.
-
Abonnez-vous et vous serez redirigé vers NetApp Cloud Central. Si vous êtes déjà abonné et que vous n'êtes pas redirigé, choisissez le lien « Cliquez ici ».
-
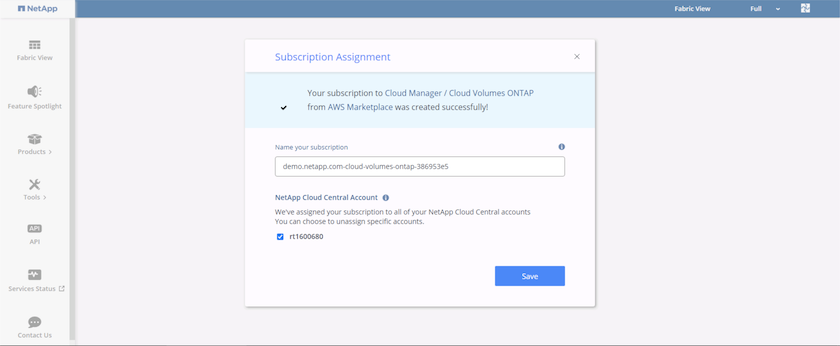
Vous êtes redirigé vers Cloud Central où vous devez nommer votre abonnement et l'attribuer à votre compte Cloud Central.
-
En cas de réussite, une page de coche apparaît. Revenez à votre onglet Gestionnaire de Cloud.
-
L'abonnement apparaît désormais dans Cloud Central. Cliquez sur Appliquer pour continuer.
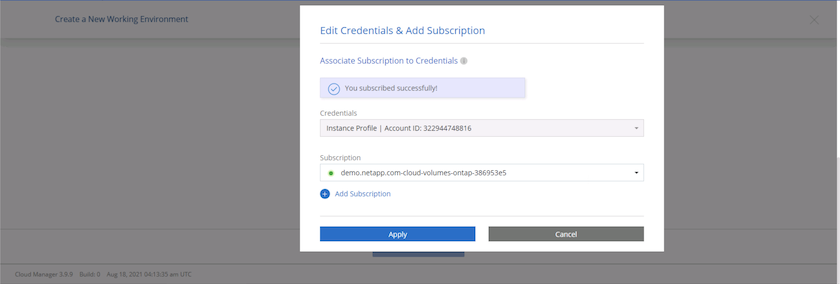
-
Saisissez les détails de l’environnement de travail tels que :
-
Nom du cluster
-
Mot de passe du cluster
-
Balises AWS (facultatif)
-
-
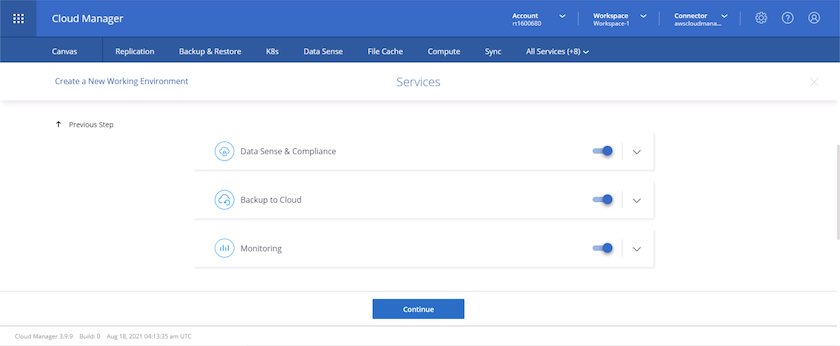
Choisissez les services supplémentaires que vous souhaitez déployer. Pour en savoir plus sur ces services, visitez le "BlueXP: des opérations de gestion de données modernes simplifiées" .
-
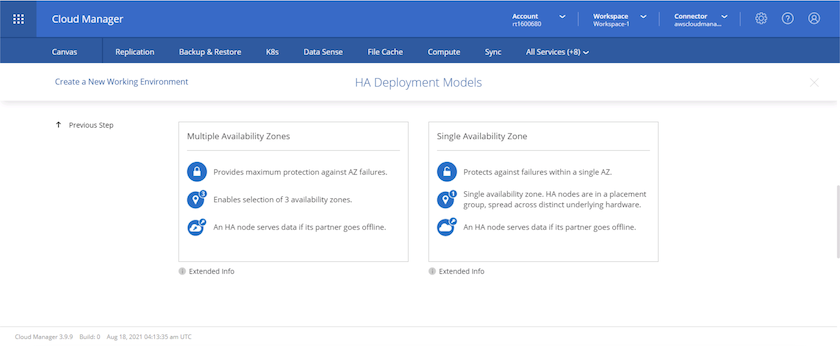
Choisissez de déployer dans plusieurs zones de disponibilité (nécessite trois sous-réseaux, chacun dans une zone de disponibilité différente) ou dans une seule zone de disponibilité. J'ai choisi plusieurs AZ.
-
Choisissez la région, le VPC et le groupe de sécurité dans lesquels le cluster doit être déployé. Dans cette section, vous attribuez également les zones de disponibilité par nœud (et médiateur) ainsi que les sous-réseaux qu'ils occupent.
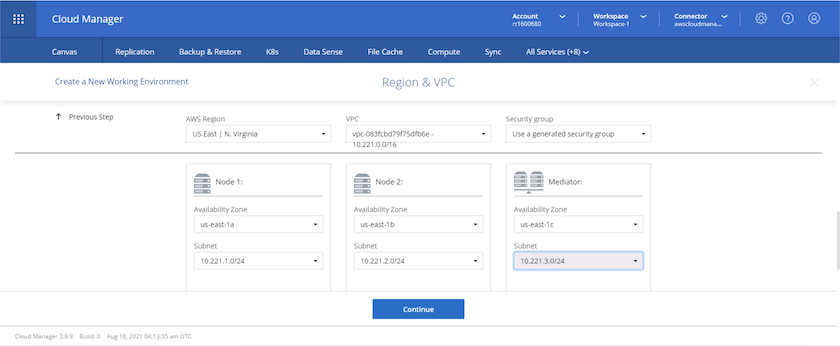
-
Choisissez les méthodes de connexion pour les nœuds ainsi que le médiateur.
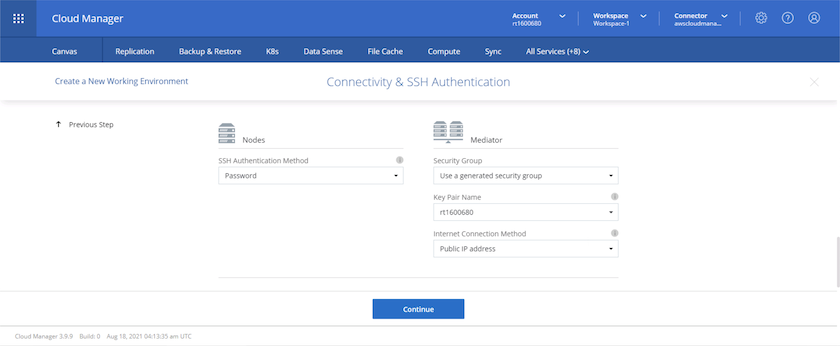

|
Le médiateur nécessite une communication avec les API AWS. Une adresse IP publique n'est pas requise tant que les API sont accessibles après le déploiement de l'instance EC2 du médiateur. |
-
Les adresses IP flottantes sont utilisées pour permettre l'accès aux différentes adresses IP utilisées par Cloud Volumes ONTAP , y compris la gestion des clusters et les adresses IP de service de données. Il doit s'agir d'adresses qui ne sont pas déjà routables au sein de votre réseau et qui sont ajoutées aux tables de routage de votre environnement AWS. Ces éléments sont nécessaires pour permettre des adresses IP cohérentes pour une paire HA lors du basculement. Vous trouverez plus d'informations sur les adresses IP flottantes dans le "Documentation NetApp Cloud" .
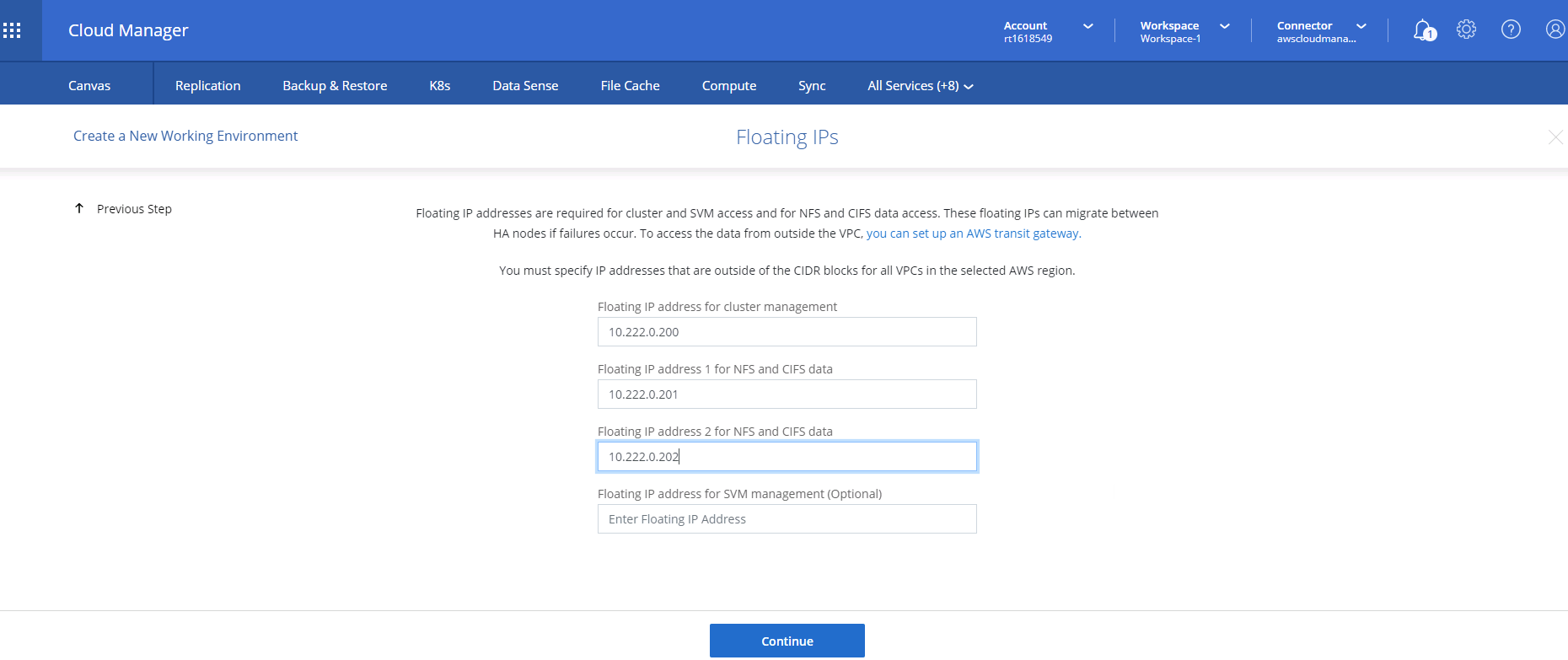
-
Sélectionnez les tables de routage auxquelles les adresses IP flottantes sont ajoutées. Ces tables de routage sont utilisées par les clients pour communiquer avec Cloud Volumes ONTAP.
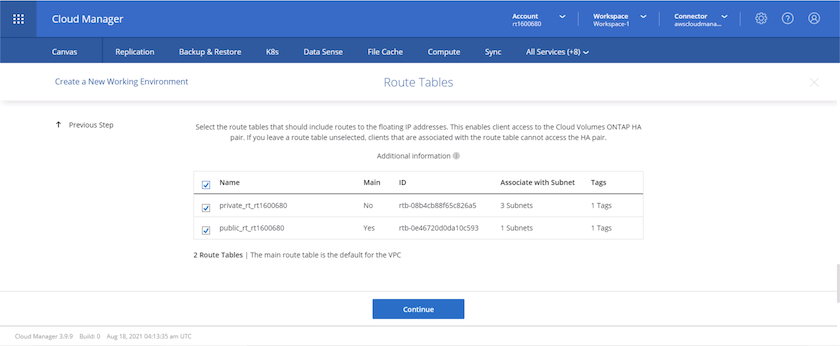
-
Choisissez d'activer le chiffrement géré par AWS ou AWS KMS pour chiffrer les disques racine, de démarrage et de données ONTAP .
-
Choisissez votre modèle de licence. Si vous ne savez pas lequel choisir, contactez votre représentant NetApp .
-
Sélectionnez la configuration la mieux adaptée à votre cas d’utilisation. Ceci est lié aux considérations de dimensionnement abordées dans la page des prérequis.
-
En option, créez un volume. Ce n’est pas obligatoire, car les étapes suivantes utilisent SnapMirror, qui crée les volumes pour nous.
-
Passez en revue les sélections effectuées et cochez les cases pour vérifier que vous comprenez que Cloud Manager déploie des ressources dans votre environnement AWS. Lorsque vous êtes prêt, cliquez sur Aller.
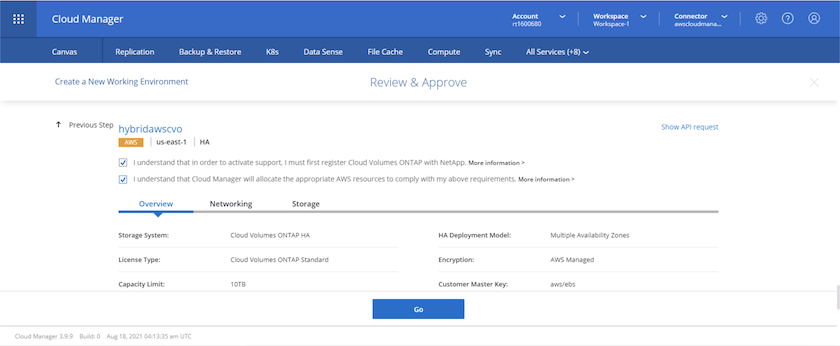
-
Cloud Volumes ONTAP démarre maintenant son processus de déploiement. Cloud Manager utilise les API AWS et les piles de formation cloud pour déployer Cloud Volumes ONTAP. Il configure ensuite le système selon vos spécifications, vous offrant ainsi un système prêt à l'emploi qui peut être utilisé instantanément. Le calendrier de ce processus varie en fonction des sélections effectuées.
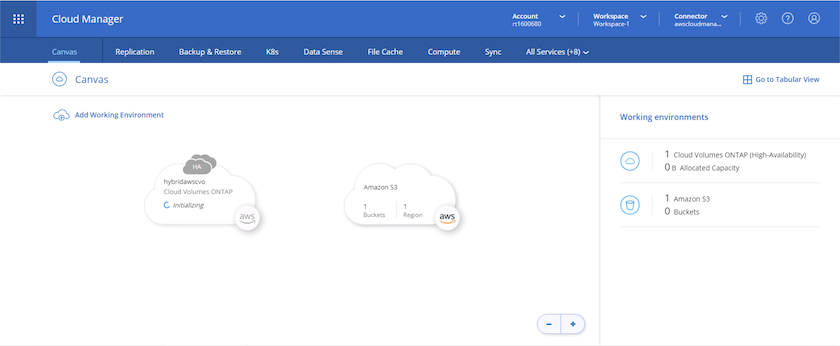
-
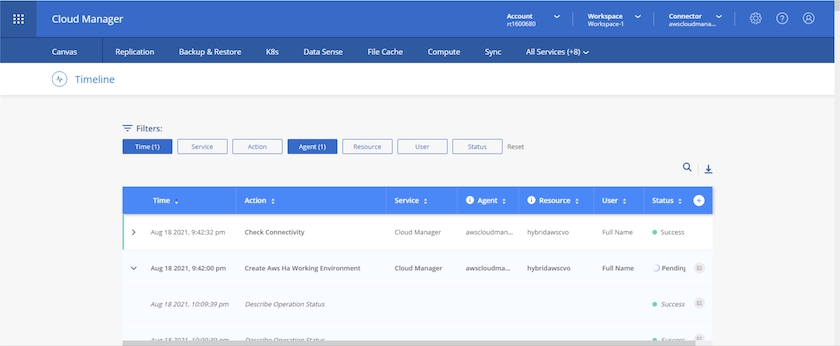
Vous pouvez suivre la progression en accédant à la chronologie.
-
La chronologie agit comme un audit de toutes les actions effectuées dans Cloud Manager. Vous pouvez afficher tous les appels d'API effectués par Cloud Manager lors de la configuration sur AWS ainsi que sur le cluster ONTAP . Cela peut également être utilisé efficacement pour résoudre tous les problèmes auxquels vous êtes confronté.
-
Une fois le déploiement terminé, le cluster CVO apparaît sur le canevas, avec la capacité actuelle. Le cluster ONTAP dans son état actuel est entièrement configuré pour permettre une véritable expérience prête à l'emploi.
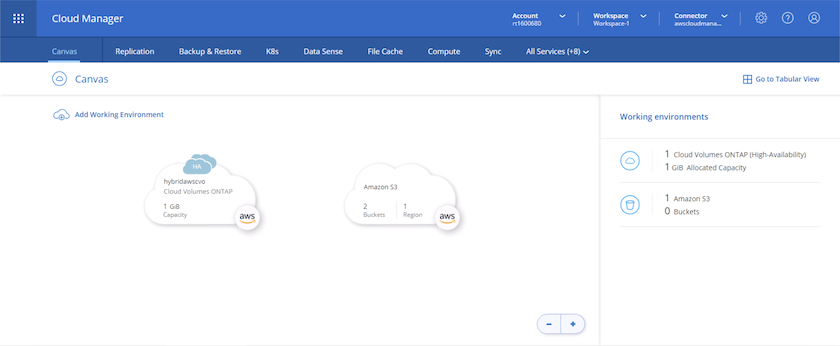
Configurer SnapMirror depuis le site vers le cloud
Maintenant que vous disposez d’un système ONTAP source et d’un système ONTAP de destination déployés, vous pouvez répliquer des volumes contenant des données de base de données dans le cloud.
Pour un guide sur les versions ONTAP compatibles pour SnapMirror, consultez le "Matrice de compatibilité SnapMirror" .
-
Cliquez sur le système ONTAP source (sur site) et faites-le glisser vers la destination, sélectionnez Réplication > Activer ou sélectionnez Réplication > Menu > Répliquer.
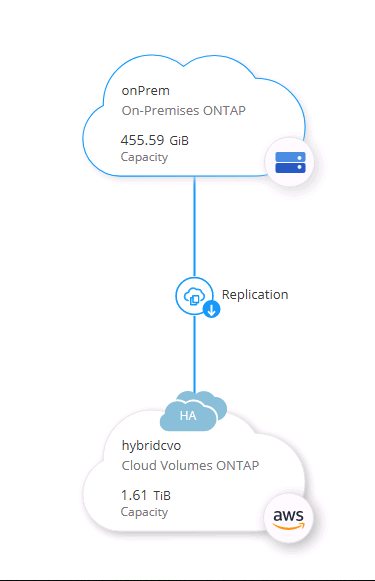
Sélectionnez Activer.
Ou Options.
Reproduire.
-
Si vous n’avez pas fait de glisser-déposer, choisissez le cluster de destination vers lequel répliquer.
-
Choisissez le volume que vous souhaitez répliquer. Nous avons répliqué les données et tous les volumes de journaux.
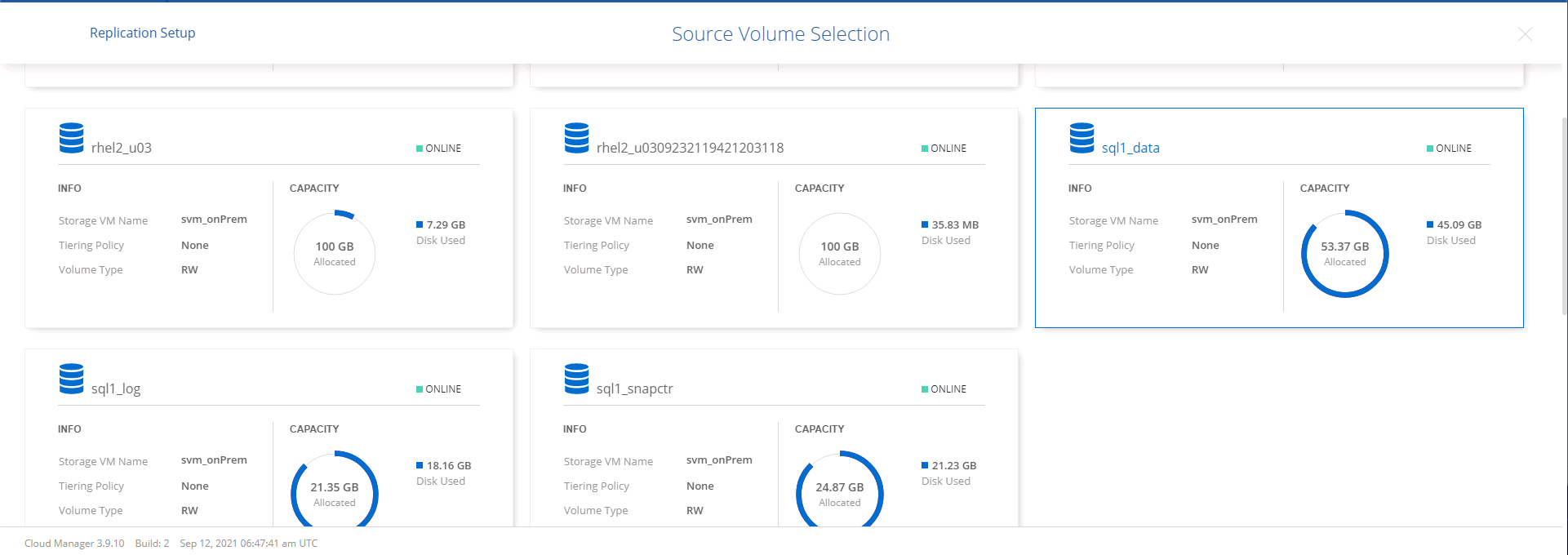
-
Choisissez le type de disque de destination et la politique de hiérarchisation. Pour la reprise après sinistre, nous recommandons un SSD comme type de disque et pour maintenir la hiérarchisation des données. La hiérarchisation des données hiérarchise les données en miroir dans un stockage d'objets à faible coût et vous permet d'économiser de l'argent sur les disques locaux. Lorsque vous rompez la relation ou clonez le volume, les données utilisent le stockage local rapide.
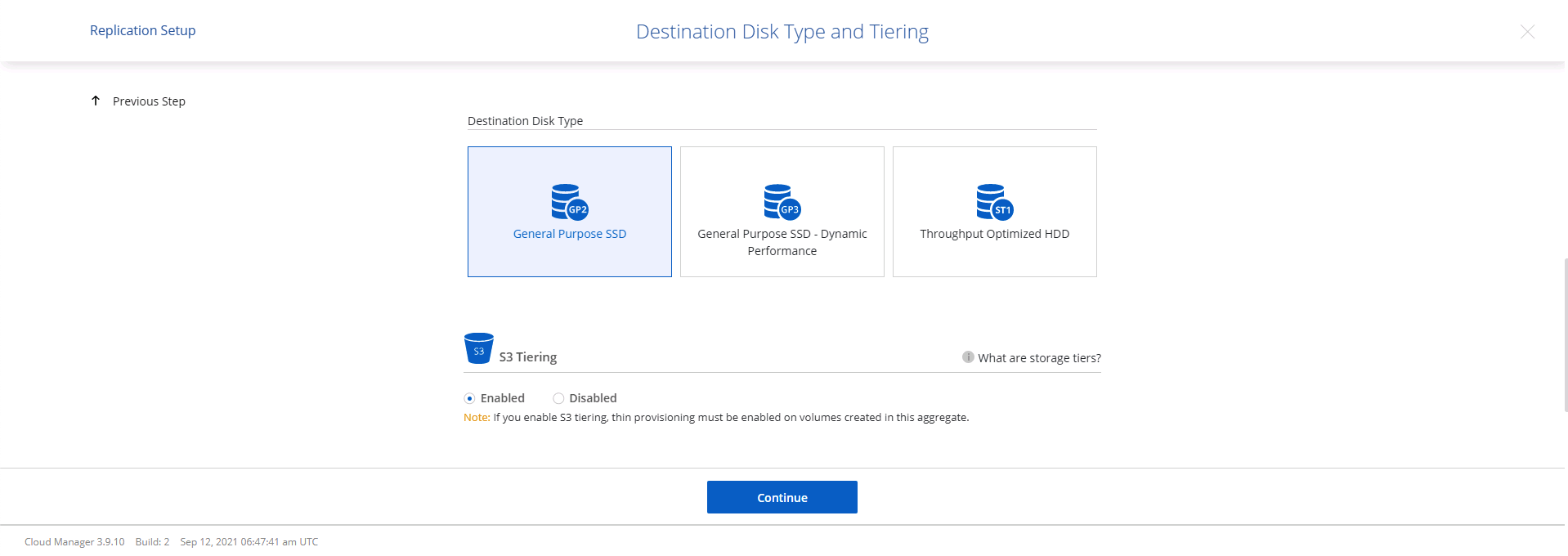
-
Sélectionnez le nom du volume de destination : nous avons choisi
[source_volume_name]_dr.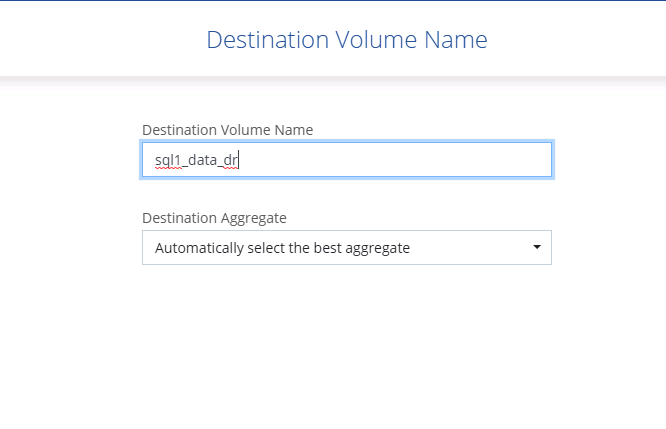
-
Sélectionnez le taux de transfert maximal pour la réplication. Cela vous permet d'économiser de la bande passante si vous disposez d'une connexion à faible bande passante au cloud, comme un VPN.
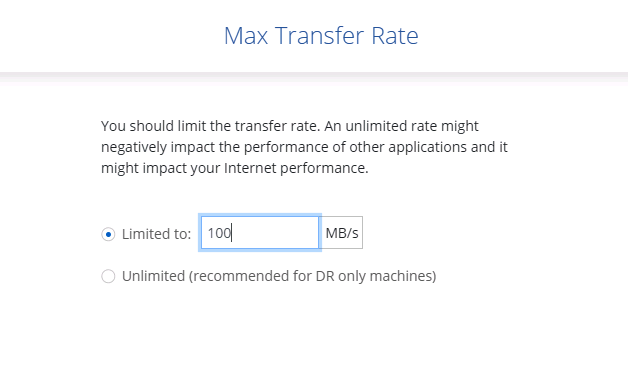
-
Définir la politique de réplication. Nous avons choisi un miroir, qui prend l’ensemble de données le plus récent et le réplique dans le volume de destination. Vous pouvez également choisir une politique différente en fonction de vos besoins.

-
Choisissez le calendrier de déclenchement de la réplication. NetApp recommande de définir une planification « quotidienne » pour le volume de données et une planification « horaire » pour les volumes de journaux, bien que cela puisse être modifié en fonction des besoins.
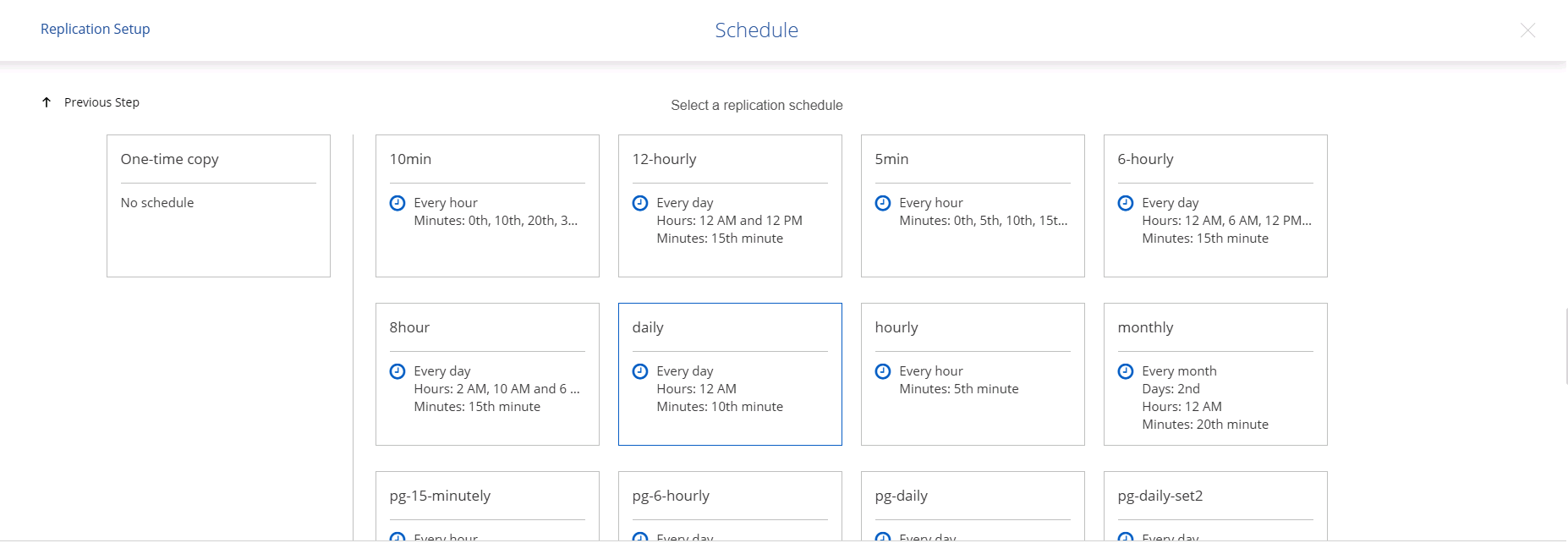
-
Vérifiez les informations saisies, cliquez sur Accéder pour déclencher l’homologue du cluster et l’homologue SVM (s’il s’agit de votre première réplication entre les deux clusters), puis implémentez et initialisez la relation SnapMirror .
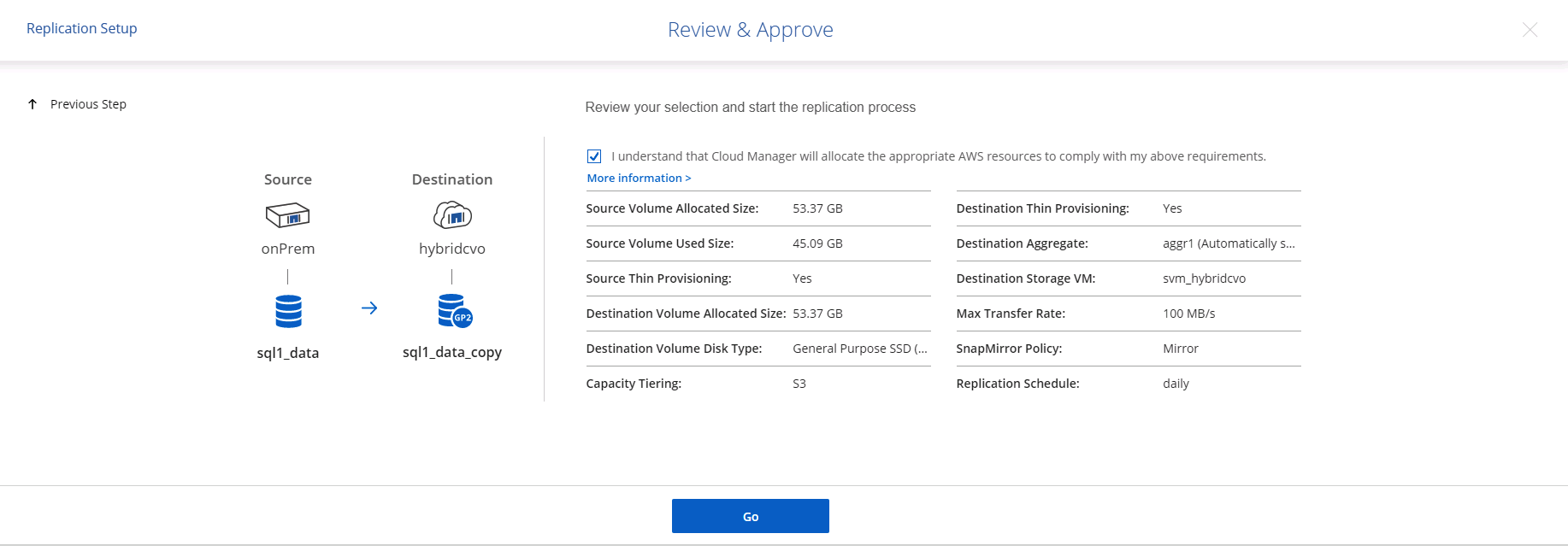
-
Continuez ce processus pour les volumes de données et les volumes de journaux.
-
Pour vérifier toutes vos relations, accédez à l’onglet Réplication dans Cloud Manager. Ici, vous pouvez gérer vos relations et vérifier leur statut.
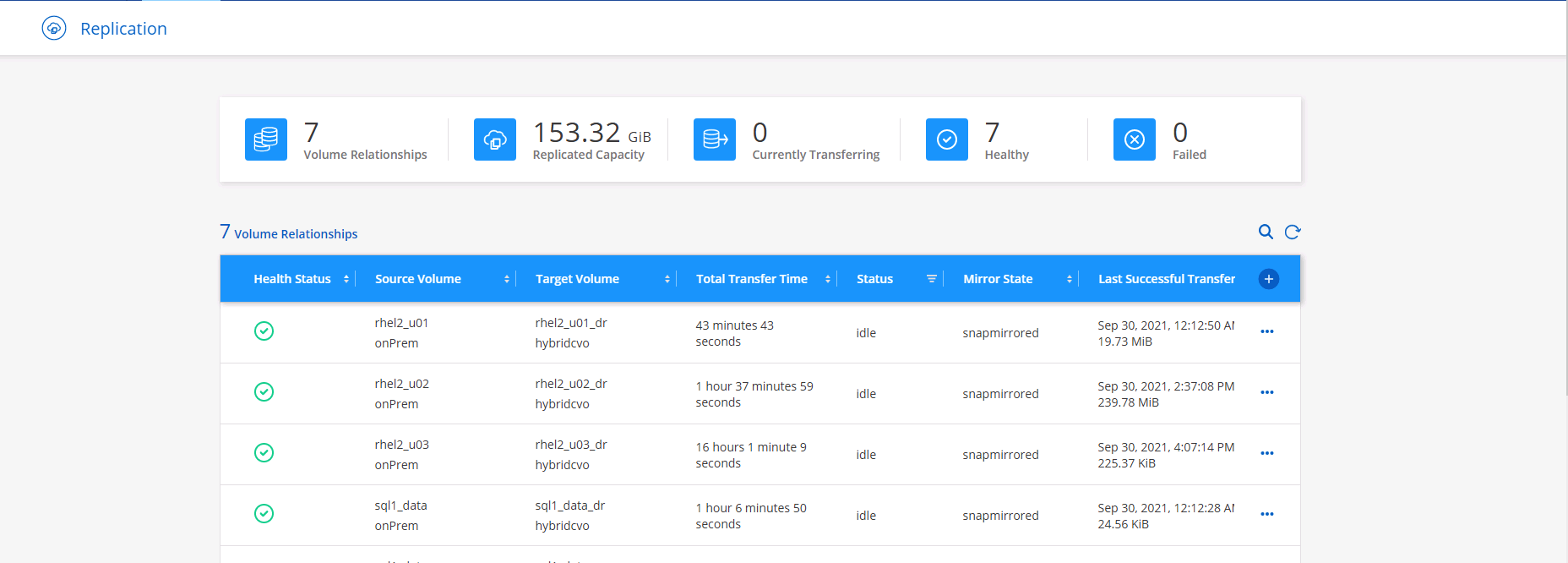
-
Une fois tous les volumes répliqués, vous êtes dans un état stable et prêt à passer aux flux de travail de reprise après sinistre et de développement/test.
[[3-deploy-ec2-compute-instance-for-database-workload]]
=== 3. Déployer une instance de calcul EC2 pour la charge de travail de la base de données
AWS a préconfiguré des instances de calcul EC2 pour diverses charges de travail. Le choix du type d'instance détermine le nombre de cœurs de processeur, la capacité de mémoire, le type et la capacité de stockage, ainsi que les performances du réseau. Pour les cas d'utilisation, à l'exception de la partition du système d'exploitation, le stockage principal pour exécuter la charge de travail de la base de données est alloué à partir de CVO ou du moteur de stockage FSx ONTAP . Par conséquent, les principaux facteurs à prendre en compte sont le choix des cœurs de processeur, de la mémoire et du niveau de performance du réseau. Les types d'instances AWS EC2 typiques peuvent être trouvés ici : "Type d'instance EC2" .
Dimensionnement de l'instance de calcul
-
Sélectionnez le type d’instance approprié en fonction de la charge de travail requise. Les facteurs à prendre en compte incluent le nombre de transactions commerciales à prendre en charge, le nombre d’utilisateurs simultanés, la taille de l’ensemble de données, etc.
-
Le déploiement de l'instance EC2 peut être lancé via le tableau de bord EC2. Les procédures de déploiement exactes dépassent le cadre de cette solution. Voir "Amazon EC2" pour plus de détails.
Configuration d'instance Linux pour la charge de travail Oracle
Cette section contient des étapes de configuration supplémentaires après le déploiement d'une instance EC2 Linux.
-
Ajoutez une instance de secours Oracle au serveur DNS pour la résolution de noms dans le domaine de gestion SnapCenter .
-
Ajoutez un ID utilisateur de gestion Linux comme informations d’identification du système d’exploitation SnapCenter avec des autorisations sudo sans mot de passe. Activez l’ID avec l’authentification par mot de passe SSH sur l’instance EC2. (Par défaut, l'authentification par mot de passe SSH et sudo sans mot de passe sont désactivés sur les instances EC2.)
-
Configurez l’installation d’Oracle pour qu’elle corresponde à l’installation Oracle sur site, comme les correctifs du système d’exploitation, les versions et correctifs Oracle, etc.
-
Les rôles d'automatisation de base de données NetApp Ansible peuvent être exploités pour configurer des instances EC2 pour les cas d'utilisation de développement/test de base de données et de reprise après sinistre. Le code d'automatisation peut être téléchargé à partir du site GitHub public de NetApp : "Déploiement automatisé d'Oracle 19c" . L’objectif est d’installer et de configurer une pile logicielle de base de données sur une instance EC2 pour correspondre aux configurations de système d’exploitation et de base de données sur site.
Configuration de l'instance Windows pour la charge de travail SQL Server
Cette section répertorie les étapes de configuration supplémentaires après le déploiement initial d’une instance Windows EC2.
-
Récupérez le mot de passe administrateur Windows pour vous connecter à une instance via RDP.
-
Désactivez le pare-feu Windows, joignez l’hôte au domaine Windows SnapCenter et ajoutez l’instance au serveur DNS pour la résolution de noms.
-
Provisionnez un volume de journal SnapCenter pour stocker les fichiers journaux SQL Server.
-
Configurez iSCSI sur l’hôte Windows pour monter le volume et formater le lecteur de disque.
-
Encore une fois, de nombreuses tâches précédentes peuvent être automatisées avec la solution d’automatisation NetApp pour SQL Server. Consultez le site GitHub public d'automatisation NetApp pour connaître les rôles et solutions récemment publiés : "Automatisation NetApp" .