

TR-4998 : Oracle HA dans AWS EC2 avec Pacemaker Clustering et FSx ONTAP
 Suggérer des modifications
Suggérer des modifications
Allen Cao, Niyaz Mohamed, NetApp
Cette solution fournit une vue d'ensemble et des détails pour activer la haute disponibilité (HA) d'Oracle dans AWS EC2 avec le clustering Pacemaker sur Redhat Enterprise Linux (RHEL) et Amazon FSx ONTAP pour le stockage de base de données HA via le protocole NFS.
But
De nombreux clients qui s’efforcent de gérer et d’exécuter eux-mêmes Oracle dans le cloud public doivent surmonter quelques défis. L’un de ces défis consiste à permettre une haute disponibilité de la base de données Oracle. Traditionnellement, les clients Oracle s'appuient sur une fonctionnalité de base de données Oracle appelée « Real Application Cluster » ou RAC pour la prise en charge des transactions actives-actives sur plusieurs nœuds de cluster. Un nœud défaillant ne bloquerait pas le traitement de l’application. Malheureusement, l’implémentation d’Oracle RAC n’est pas facilement disponible ou prise en charge dans de nombreux clouds publics populaires tels qu’AWS EC2. En exploitant le clustering Pacemaker intégré (PCS) dans RHEL et Amazon FSx ONTAP, les clients peuvent obtenir une alternative viable sans coût de licence Oracle RAC pour le clustering actif-passif sur le calcul et le stockage afin de prendre en charge la charge de travail de base de données Oracle critique dans le cloud AWS.
Cette documentation présente les détails de la configuration du clustering Pacemaker sur RHEL, du déploiement de la base de données Oracle sur EC2 et Amazon FSx ONTAP avec le protocole NFS, de la configuration des ressources Oracle dans Pacemaker pour HA et de la conclusion de la démonstration avec une validation dans les scénarios HA les plus fréquemment rencontrés. La solution fournit également des informations sur la sauvegarde, la restauration et le clonage rapides de bases de données Oracle avec l'outil d'interface utilisateur NetApp SnapCenter .
Cette solution répond aux cas d’utilisation suivants :
-
Configuration et configuration du clustering Pacemaker HA dans RHEL.
-
Déploiement de la base de données Oracle HA dans AWS EC2 et Amazon FSx ONTAP.
Public
Cette solution est destinée aux personnes suivantes :
-
Un DBA qui souhaite déployer Oracle dans AWS EC2 et Amazon FSx ONTAP.
-
Un architecte de solutions de base de données qui souhaite tester les charges de travail Oracle dans AWS EC2 et Amazon FSx ONTAP.
-
Un administrateur de stockage souhaitant déployer et gérer une base de données Oracle dans AWS EC2 et Amazon FSx ONTAP.
-
Un propriétaire d'application qui souhaite mettre en place une base de données Oracle dans AWS EC2 et Amazon FSx ONTAP.
Environnement de test et de validation de solutions
Les tests et la validation de cette solution ont été réalisés dans un environnement de laboratoire qui pourrait ne pas correspondre à l’environnement de déploiement final. Voir la sectionFacteurs clés à prendre en compte lors du déploiement pour plus d'informations.
Architecture
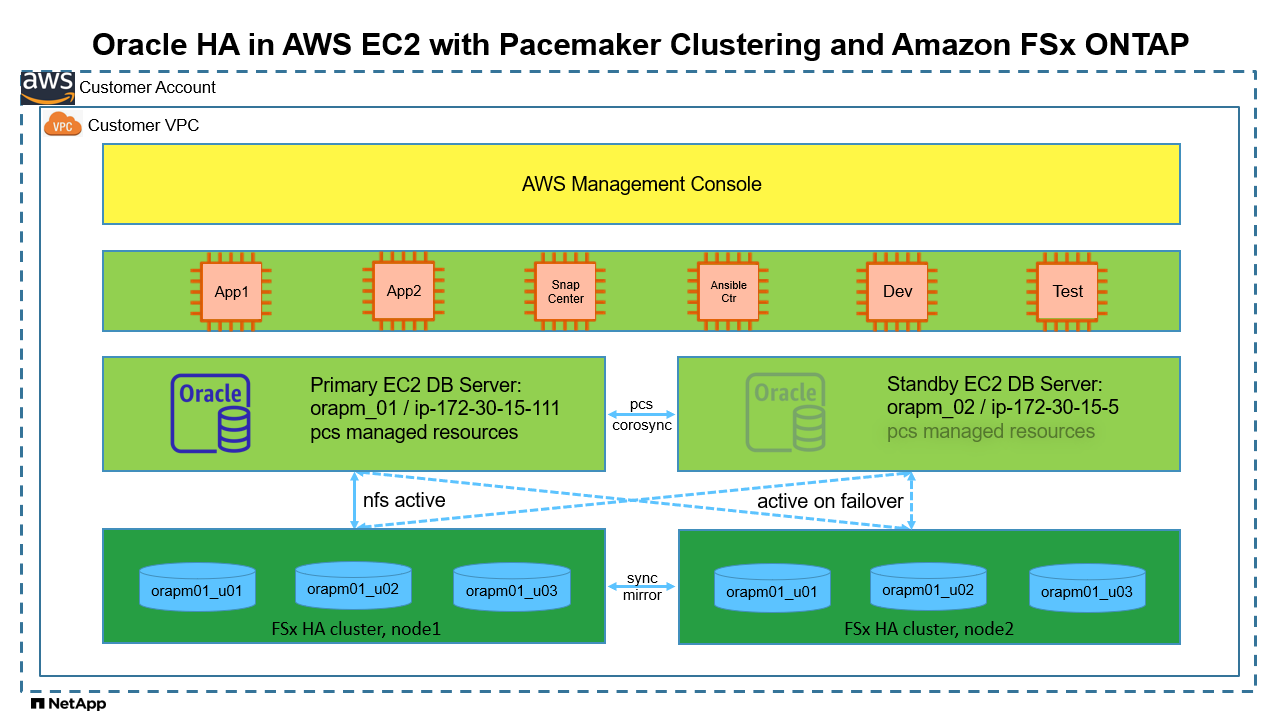
Composants matériels et logiciels
Matériel |
||
Stockage Amazon FSx ONTAP |
Version actuelle proposée par AWS |
Single-AZ dans US-East-1, capacité de 1 024 Gio, débit de 128 Mo/s |
Instances EC2 pour serveur de base de données |
t2.xlarge/4vCPU/16G |
Deux instances EC2 T2 xlarge EC2, l'une comme serveur de base de données principal et l'autre comme serveur de base de données de secours |
VM pour contrôleur Ansible |
4 vCPU, 16 Go de RAM |
Une machine virtuelle Linux pour exécuter le provisionnement automatisé d'AWS EC2/FSx et le déploiement Oracle sur NFS |
Logiciel |
||
RedHat Linux |
RHEL Linux 8.6 (LVM) - x64 Gen2 |
Abonnement RedHat déployé pour les tests |
Base de données Oracle |
Version 19.18 |
Patch RU appliqué p34765931_190000_Linux-x86-64.zip |
Oracle OPatch |
Version 12.2.0.1.36 |
Dernier correctif p6880880_190000_Linux-x86-64.zip |
Stimulateur cardiaque |
Version 0.10.18 |
Module complémentaire de haute disponibilité pour RHEL 8.0 par RedHat |
NFS |
Version 3.0 |
Oracle dNFS activé |
Ansible |
noyau 2.16.2 |
Python 3.6.8 |
Configuration active/passive de la base de données Oracle dans l'environnement de laboratoire AWS EC2/FSx
Serveur |
Base de données |
Stockage de base de données |
nœud principal : orapm01/ip-172.30.15.111 |
NTAP(NTAP_PDB1,NTAP_PDB2,NTAP_PDB3) |
/u01, /u02, /u03 Montages NFS sur les volumes Amazon FSx ONTAP |
nœud de secours : orapm02/ip-172.30.15.5 |
NTAP(NTAP_PDB1,NTAP_PDB2,NTAP_PDB3) lors du basculement |
/u01, /u02, /u03 Montages NFS lors du basculement |
Facteurs clés à prendre en compte lors du déploiement
-
* Amazon FSx ONTAP HA.* Amazon FSx ONTAP est provisionné dans une paire HA de contrôleurs de stockage dans une ou plusieurs zones de disponibilité par défaut. Il fournit une redondance de stockage de manière active/passive pour les charges de travail de base de données critiques. Le basculement du stockage est transparent pour l’utilisateur final. L’intervention de l’utilisateur n’est pas requise en cas de basculement du stockage.
-
Groupe de ressources PCS et commande de ressources. Un groupe de ressources permet à plusieurs ressources avec dépendance de s'exécuter sur le même nœud de cluster. L'ordre des ressources applique l'ordre de démarrage et l'ordre d'arrêt des ressources en sens inverse.
-
Nœud préféré. Le cluster Pacemaker est volontairement déployé dans un clustering actif/passif (ce qui n'est pas une exigence de Pacemaker) et est synchronisé avec le clustering FSx ONTAP . L'instance EC2 active est configurée comme nœud préféré pour les ressources Oracle lorsqu'elle est disponible avec une contrainte d'emplacement.
-
Délai de clôture sur le nœud de secours. Dans un cluster PCS à deux nœuds, le quorum est artificiellement défini à 1. En cas de problème de communication entre les nœuds du cluster, l'un ou l'autre nœud pourrait essayer de clôturer l'autre nœud, ce qui peut potentiellement entraîner une corruption des données. La configuration d’un délai sur le nœud de secours atténue le problème et permet au nœud principal de continuer à fournir des services pendant que le nœud de secours est clôturé.
-
Considération sur le déploiement multi-az. La solution est déployée et validée dans une zone de disponibilité unique. Pour un déploiement multi-az, des ressources réseau AWS supplémentaires sont nécessaires pour déplacer l'IP flottante PCS entre les zones de disponibilité.
-
Disposition de stockage de la base de données Oracle. Dans cette démonstration de solution, nous provisionnons trois volumes de base de données pour la base de données de test NTAP afin d'héberger les binaires, les données et les journaux Oracle. Les volumes sont montés sur le serveur Oracle DB en tant que /u01 - binaire, /u02 - données et /u03 - journal via NFS. Les fichiers de contrôle double sont configurés sur les points de montage /u02 et /u03 pour la redondance.
-
Configuration dNFS. En utilisant dNFS (disponible depuis Oracle 11g), une base de données Oracle exécutée sur une machine virtuelle DB peut générer beaucoup plus d'E/S que le client NFS natif. Le déploiement Oracle automatisé configure dNFS sur NFSv3 par défaut.
-
Sauvegarde de la base de données. NetApp fournit une suite SnapCenter software pour la sauvegarde, la restauration et le clonage de bases de données avec une interface utilisateur conviviale. NetApp recommande de mettre en œuvre un tel outil de gestion pour obtenir une sauvegarde instantanée rapide (moins d'une minute), une restauration rapide (quelques minutes) de la base de données et un clonage de la base de données.
Déploiement de la solution
Les sections suivantes fournissent des procédures étape par étape pour le déploiement et la configuration de la base de données Oracle HA dans AWS EC2 avec le clustering Pacemaker et Amazon FSx ONTAP pour la protection du stockage de la base de données.
Prérequis pour le déploiement
Details
Le déploiement nécessite les prérequis suivants.
-
Un compte AWS a été configuré et les segments VPC et réseau nécessaires ont été créés dans votre compte AWS.
-
Provisionnez une machine virtuelle Linux en tant que nœud de contrôleur Ansible avec la dernière version d'Ansible et de Git installée. Consultez le lien suivant pour plus de détails :"Premiers pas avec l'automatisation des solutions NetApp " dans la section -
Setup the Ansible Control Node for CLI deployments on RHEL / CentOSou
Setup the Ansible Control Node for CLI deployments on Ubuntu / Debian.Activez l'authentification par clé publique/privée SSH entre le contrôleur Ansible et les machines virtuelles de base de données d'instance EC2.
Provisionner des instances EC2 et un cluster de stockage Amazon FSx ONTAP
Details
Bien que l'instance EC2 et Amazon FSx ONTAP puissent être provisionnés manuellement à partir de la console AWS, il est recommandé d'utiliser la boîte à outils d'automatisation basée sur NetApp Terraform pour automatiser le provisionnement des instances EC2 et du cluster de stockage FSx ONTAP . Voici les procédures détaillées.
-
À partir d'AWS CloudShell ou d'une machine virtuelle du contrôleur Ansible, clonez une copie de la boîte à outils d'automatisation pour EC2 et FSx ONTAP.
git clone https://bitbucket.ngage.netapp.com/scm/ns-bb/na_aws_fsx_ec2_deploy.git
Si la boîte à outils n'est pas exécutée à partir d'AWS CloudShell, l'authentification AWS CLI est requise avec votre compte AWS à l'aide de la paire de clés d'accès/secret du compte utilisateur AWS. -
Consultez le fichier READme.md inclus dans la boîte à outils. Révisez main.tf et les fichiers de paramètres associés si nécessaire pour les ressources AWS requises.
An example of main.tf: resource "aws_instance" "orapm01" { ami = var.ami instance_type = var.instance_type subnet_id = var.subnet_id key_name = var.ssh_key_name root_block_device { volume_type = "gp3" volume_size = var.root_volume_size } tags = { Name = var.ec2_tag1 } } resource "aws_instance" "orapm02" { ami = var.ami instance_type = var.instance_type subnet_id = var.subnet_id key_name = var.ssh_key_name root_block_device { volume_type = "gp3" volume_size = var.root_volume_size } tags = { Name = var.ec2_tag2 } } resource "aws_fsx_ontap_file_system" "fsx_01" { storage_capacity = var.fs_capacity subnet_ids = var.subnet_ids preferred_subnet_id = var.preferred_subnet_id throughput_capacity = var.fs_throughput fsx_admin_password = var.fsxadmin_password deployment_type = var.deployment_type disk_iops_configuration { iops = var.iops mode = var.iops_mode } tags = { Name = var.fsx_tag } } resource "aws_fsx_ontap_storage_virtual_machine" "svm_01" { file_system_id = aws_fsx_ontap_file_system.fsx_01.id name = var.svm_name svm_admin_password = var.vsadmin_password } -
Valider et exécuter le plan Terraform. Une exécution réussie créerait deux instances EC2 et un cluster de stockage FSx ONTAP dans le compte AWS cible. La sortie d'automatisation affiche l'adresse IP de l'instance EC2 et les points de terminaison du cluster FSx ONTAP .
terraform plan -out=main.planterraform apply main.plan
Ceci termine le provisionnement des instances EC2 et FSx ONTAP pour Oracle.
Configuration du groupe de stimulateurs cardiaques
Details
Le module complémentaire haute disponibilité pour RHEL est un système en cluster qui offre fiabilité, évolutivité et disponibilité aux services de production critiques tels que les services de base de données Oracle. Dans cette démonstration de cas d'utilisation, un cluster Pacemaker à deux nœuds est configuré et configuré pour prendre en charge la haute disponibilité d'une base de données Oracle dans un scénario de clustering actif/passif.
Connectez-vous aux instances EC2, en tant qu'utilisateur ec2, effectuez les tâches suivantes sur both Instances EC2 :
-
Supprimez le client AWS Red Hat Update Infrastructure (RHUI).
sudo -i yum -y remove rh-amazon-rhui-client* -
Enregistrez les machines virtuelles d’instance EC2 auprès de Red Hat.
sudo subscription-manager register --username xxxxxxxx --password 'xxxxxxxx' --auto-attach -
Activer les rpm haute disponibilité RHEL.
sudo subscription-manager config --rhsm.manage_repos=1sudo subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms -
Installer un stimulateur cardiaque et un agent de clôture.
sudo yum update -ysudo yum install pcs pacemaker fence-agents-aws -
Créez un mot de passe pour l’utilisateur hacluster sur tous les nœuds du cluster. Utilisez le même mot de passe pour tous les nœuds.
sudo passwd hacluster -
Démarrez le service pcs et activez-le pour qu'il démarre au démarrage.
sudo systemctl start pcsd.servicesudo systemctl enable pcsd.service -
Valider le service pcsd.
sudo systemctl status pcsd[ec2-user@ip-172-30-15-5 ~]$ sudo systemctl status pcsd ● pcsd.service - PCS GUI and remote configuration interface Loaded: loaded (/usr/lib/systemd/system/pcsd.service; enabled; vendor preset: disabled) Active: active (running) since Tue 2024-09-10 18:50:22 UTC; 33s ago Docs: man:pcsd(8) man:pcs(8) Main PID: 65302 (pcsd) Tasks: 1 (limit: 100849) Memory: 24.0M CGroup: /system.slice/pcsd.service └─65302 /usr/libexec/platform-python -Es /usr/sbin/pcsd Sep 10 18:50:21 ip-172-30-15-5.ec2.internal systemd[1]: Starting PCS GUI and remote configuration interface... Sep 10 18:50:22 ip-172-30-15-5.ec2.internal systemd[1]: Started PCS GUI and remote configuration interface. -
Ajoutez des nœuds de cluster aux fichiers hôtes.
sudo vi /etc/hosts[ec2-user@ip-172-30-15-5 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 # cluster nodes 172.30.15.111 ip-172-30-15-111.ec2.internal 172.30.15.5 ip-172-30-15-5.ec2.internal
-
Installez et configurez awscli pour la connectivité au compte AWS.
sudo yum install awsclisudo aws configure[ec2-user@ip-172-30-15-111 ]# sudo aws configure AWS Access Key ID [None]: XXXXXXXXXXXXXXXXX AWS Secret Access Key [None]: XXXXXXXXXXXXXXXX Default region name [None]: us-east-1 Default output format [None]: json
-
Installez le package resource-agents s'il n'est pas déjà installé.
sudo yum install resource-agents
Sur only one du nœud du cluster, effectuez les tâches suivantes pour créer un cluster de pcs.
-
Authentifiez l'utilisateur pcs hacluster.
sudo pcs host auth ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal[ec2-user@ip-172-30-15-111 ~]$ sudo pcs host auth ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal Username: hacluster Password: ip-172-30-15-111.ec2.internal: Authorized ip-172-30-15-5.ec2.internal: Authorized
-
Créez le cluster pcs.
sudo pcs cluster setup ora_ec2nfsx ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal[ec2-user@ip-172-30-15-111 ~]$ sudo pcs cluster setup ora_ec2nfsx ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal No addresses specified for host 'ip-172-30-15-5.ec2.internal', using 'ip-172-30-15-5.ec2.internal' No addresses specified for host 'ip-172-30-15-111.ec2.internal', using 'ip-172-30-15-111.ec2.internal' Destroying cluster on hosts: 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal'... ip-172-30-15-5.ec2.internal: Successfully destroyed cluster ip-172-30-15-111.ec2.internal: Successfully destroyed cluster Requesting remove 'pcsd settings' from 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal' ip-172-30-15-111.ec2.internal: successful removal of the file 'pcsd settings' ip-172-30-15-5.ec2.internal: successful removal of the file 'pcsd settings' Sending 'corosync authkey', 'pacemaker authkey' to 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal' ip-172-30-15-111.ec2.internal: successful distribution of the file 'corosync authkey' ip-172-30-15-111.ec2.internal: successful distribution of the file 'pacemaker authkey' ip-172-30-15-5.ec2.internal: successful distribution of the file 'corosync authkey' ip-172-30-15-5.ec2.internal: successful distribution of the file 'pacemaker authkey' Sending 'corosync.conf' to 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal' ip-172-30-15-111.ec2.internal: successful distribution of the file 'corosync.conf' ip-172-30-15-5.ec2.internal: successful distribution of the file 'corosync.conf' Cluster has been successfully set up.
-
Activer le cluster.
sudo pcs cluster enable --all[ec2-user@ip-172-30-15-111 ~]$ sudo pcs cluster enable --all ip-172-30-15-5.ec2.internal: Cluster Enabled ip-172-30-15-111.ec2.internal: Cluster Enabled
-
Démarrer et valider le cluster.
sudo pcs cluster start --allsudo pcs status[ec2-user@ip-172-30-15-111 ~]$ sudo pcs status Cluster name: ora_ec2nfsx WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Wed Sep 11 15:43:23 2024 on ip-172-30-15-111.ec2.internal * Last change: Wed Sep 11 15:43:06 2024 by hacluster via hacluster on ip-172-30-15-111.ec2.internal * 2 nodes configured * 0 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Ceci termine la configuration initiale et la configuration du cluster Pacemaker.
Configuration de clôture du cluster de stimulateurs cardiaques
Details
La configuration de la clôture du stimulateur cardiaque est obligatoire pour un cluster de production. Il garantit qu'un nœud défectueux sur votre cluster AWS EC2 est automatiquement isolé, empêchant ainsi le nœud de consommer les ressources du cluster, de compromettre la fonctionnalité du cluster ou de corrompre les données partagées. Cette section illustre la configuration de la clôture de cluster à l'aide de l'agent de clôture fence_aws.
-
En tant qu'utilisateur root, saisissez la requête de métadonnées AWS suivante pour obtenir l'ID d'instance pour chaque nœud d'instance EC2.
echo $(curl -s http://169.254.169.254/latest/meta-data/instance-id)[root@ip-172-30-15-111 ec2-user]# echo $(curl -s http://169.254.169.254/latest/meta-data/instance-id) i-0d8e7a0028371636f or just get instance-id from AWS EC2 console
-
Entrez la commande suivante pour configurer le périphérique de clôture. Utilisez la commande pcmk_host_map pour mapper le nom d’hôte RHEL à l’ID d’instance. Utilisez la clé d’accès AWS et la clé d’accès secrète AWS du compte utilisateur AWS que vous avez précédemment utilisé pour l’authentification AWS.
sudo pcs stonith \ create clusterfence fence_aws access_key=XXXXXXXXXXXXXXXXX secret_key=XXXXXXXXXXXXXXXXXX \ region=us-east-1 pcmk_host_map="ip-172-30-15-111.ec2.internal:i-0d8e7a0028371636f;ip-172-30-15-5.ec2.internal:i-0bc54b315afb20a2e" \ power_timeout=240 pcmk_reboot_timeout=480 pcmk_reboot_retries=4 -
Valider la configuration de la clôture.
pcs status[root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Wed Sep 11 21:17:18 2024 on ip-172-30-15-111.ec2.internal * Last change: Wed Sep 11 21:16:40 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 1 resource instance configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
-
Définissez stonith-action sur off au lieu de redémarrer au niveau du cluster.
pcs property set stonith-action=off[root@ip-172-30-15-111 ec2-user]# pcs property config Cluster Properties: cluster-infrastructure: corosync cluster-name: ora_ec2nfsx dc-version: 2.1.7-5.1.el8_10-0f7f88312 have-watchdog: false last-lrm-refresh: 1726257586 stonith-action: off
Avec stonith-action défini sur off, le nœud de cluster clôturé sera initialement arrêté. Après la période définie dans stonith power_timeout (240 secondes), le nœud clôturé sera redémarré et rejoindra le cluster. -
Définissez le délai de clôture sur 10 secondes pour le nœud de secours.
pcs stonith update clusterfence pcmk_delay_base="ip-172-30-15-111.ec2.internal:0;ip-172-30-15-5.ec2.internal:10s"[root@ip-172-30-15-111 ec2-user]# pcs stonith config Resource: clusterfence (class=stonith type=fence_aws) Attributes: clusterfence-instance_attributes access_key=XXXXXXXXXXXXXXXX pcmk_delay_base=ip-172-30-15-111.ec2.internal:0;ip-172-30-15-5.ec2.internal:10s pcmk_host_map=ip-172-30-15-111.ec2.internal:i-0d8e7a0028371636f;ip-172-30-15-5.ec2.internal:i-0bc54b315afb20a2e pcmk_reboot_retries=4 pcmk_reboot_timeout=480 power_timeout=240 region=us-east-1 secret_key=XXXXXXXXXXXXXXXX Operations: monitor: clusterfence-monitor-interval-60s interval=60s
|
|
Exécuter pcs stonith refresh commande pour actualiser l'agent de clôture Stonith arrêté ou effacer les actions de ressource Stonith ayant échoué.
|
Déployer une base de données Oracle dans un cluster PCS
Details
Nous vous recommandons d’utiliser le playbook Ansible fourni par NetApp pour exécuter les tâches d’installation et de configuration de la base de données avec des paramètres prédéfinis sur le cluster PCS. Pour ce déploiement Oracle automatisé, trois fichiers de paramètres définis par l'utilisateur nécessitent une saisie utilisateur avant l'exécution du playbook.
-
hôtes - définissez les cibles sur lesquelles le playbook d'automatisation s'exécute.
-
vars/vars.yml - le fichier de variables globales qui définit les variables qui s'appliquent à toutes les cibles.
-
host_vars/host_name.yml - le fichier de variables locales qui définit les variables qui s'appliquent uniquement à une cible nommée. Dans notre cas d’utilisation, il s’agit des serveurs de base de données Oracle.
En plus de ces fichiers de variables définis par l'utilisateur, il existe plusieurs fichiers de variables par défaut qui contiennent des paramètres par défaut qui ne nécessitent aucune modification, sauf si nécessaire. Ce qui suit montre les détails du déploiement Oracle automatisé dans AWS EC2 et FSx ONTAP dans une configuration de clustering PCS.
-
À partir du répertoire de base de l’utilisateur administrateur du contrôleur Ansible, clonez une copie de la boîte à outils d’automatisation de déploiement NetApp Oracle pour NFS.
git clone https://bitbucket.ngage.netapp.com/scm/ns-bb/na_oracle_deploy_nfs.git
Le contrôleur Ansible peut être situé dans le même VPC que l'instance EC2 de la base de données ou sur site tant qu'il existe une connectivité réseau entre eux. -
Remplissez les paramètres définis par l'utilisateur dans les fichiers de paramètres des hôtes. Voici un exemple de configuration de fichier hôte typique.
[admin@ansiblectl na_oracle_deploy_nfs]$ cat hosts #Oracle hosts [oracle] orapm01 ansible_host=172.30.15.111 ansible_ssh_private_key_file=ec2-user.pem orapm02 ansible_host=172.30.15.5 ansible_ssh_private_key_file=ec2-user.pem
-
Remplissez les paramètres définis par l'utilisateur dans les fichiers de paramètres vars/vars.yml. Voici un exemple de configuration de fichier vars.yml typique.
[admin@ansiblectl na_oracle_deploy_nfs]$ cat vars/vars.yml ###################################################################### ###### Oracle 19c deployment user configuration variables ###### ###### Consolidate all variables from ONTAP, linux and oracle ###### ###################################################################### ########################################### ### ONTAP env specific config variables ### ########################################### # Prerequisite to create three volumes in NetApp ONTAP storage from System Manager or cloud dashboard with following naming convention: # db_hostname_u01 - Oracle binary # db_hostname_u02 - Oracle data # db_hostname_u03 - Oracle redo # It is important to strictly follow the name convention or the automation will fail. ########################################### ### Linux env specific config variables ### ########################################### redhat_sub_username: xxxxxxxx redhat_sub_password: "xxxxxxxx" #################################################### ### DB env specific install and config variables ### #################################################### # Database domain name db_domain: ec2.internal # Set initial password for all required Oracle passwords. Change them after installation. initial_pwd_all: "xxxxxxxx"
-
Remplissez les paramètres définis par l'utilisateur dans les fichiers de paramètres host_vars/host_name.yml. Voici un exemple de configuration typique du fichier host_vars/host_name.yml.
[admin@ansiblectl na_oracle_deploy_nfs]$ cat host_vars/orapm01.yml # User configurable Oracle host specific parameters # Database SID. By default, a container DB is created with 3 PDBs within the CDB oracle_sid: NTAP # CDB is created with SGA at 75% of memory_limit, MB. Consider how many databases to be hosted on the node and # how much ram to be allocated to each DB. The grand total of SGA should not exceed 75% available RAM on node. memory_limit: 8192 # Local NFS lif ip address to access database volumes nfs_lif: 172.30.15.95
L'adresse nfs_lif peut être récupérée à partir des points de terminaison du cluster FSx ONTAP issus du déploiement automatisé EC2 et FSx ONTAP dans la section précédente. -
Créez des volumes de base de données à partir de la console AWS FSx. Assurez-vous d'utiliser le nom d'hôte du nœud principal PCS (orapm01) comme préfixe pour les volumes, comme illustré ci-dessous.
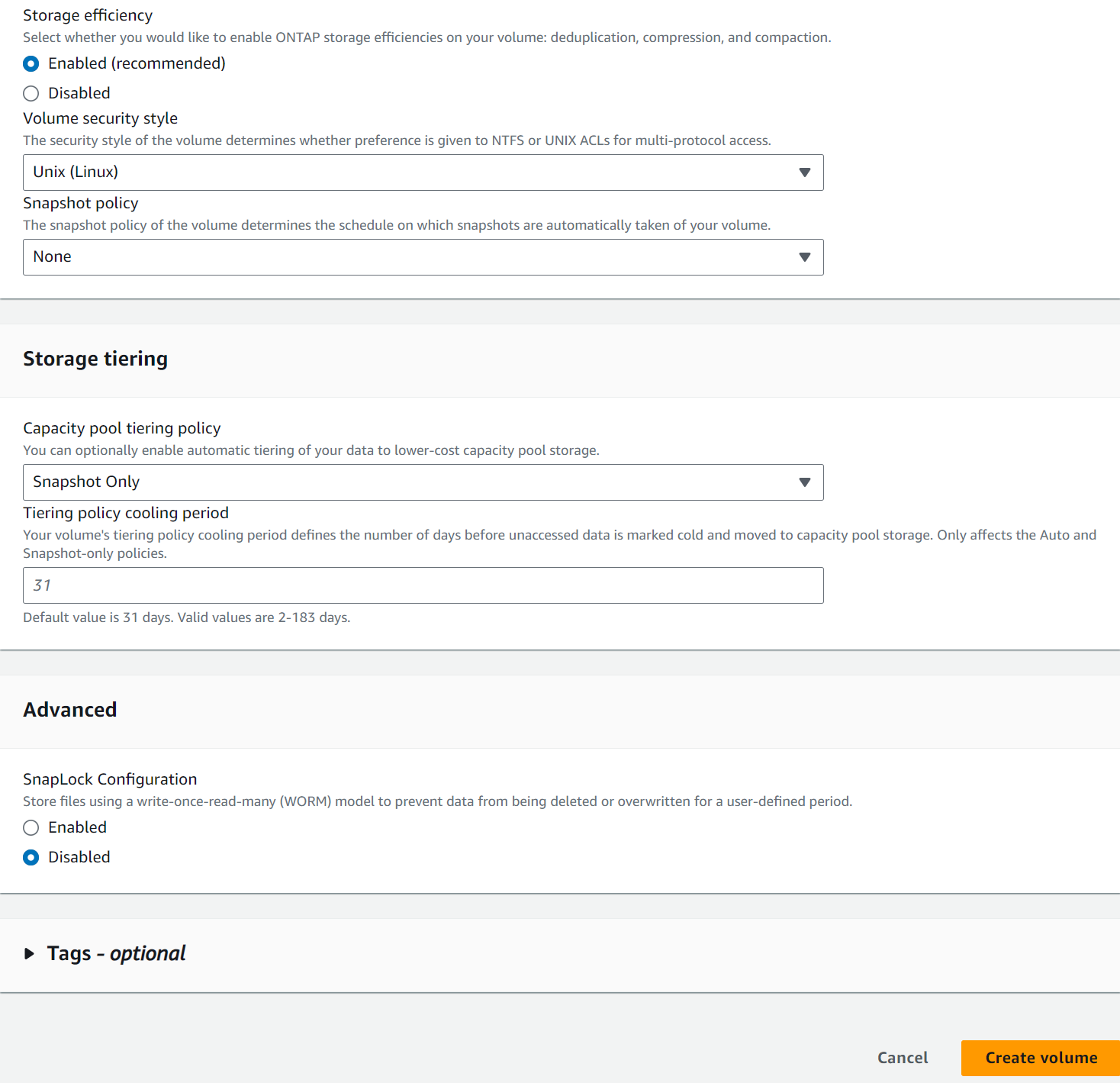
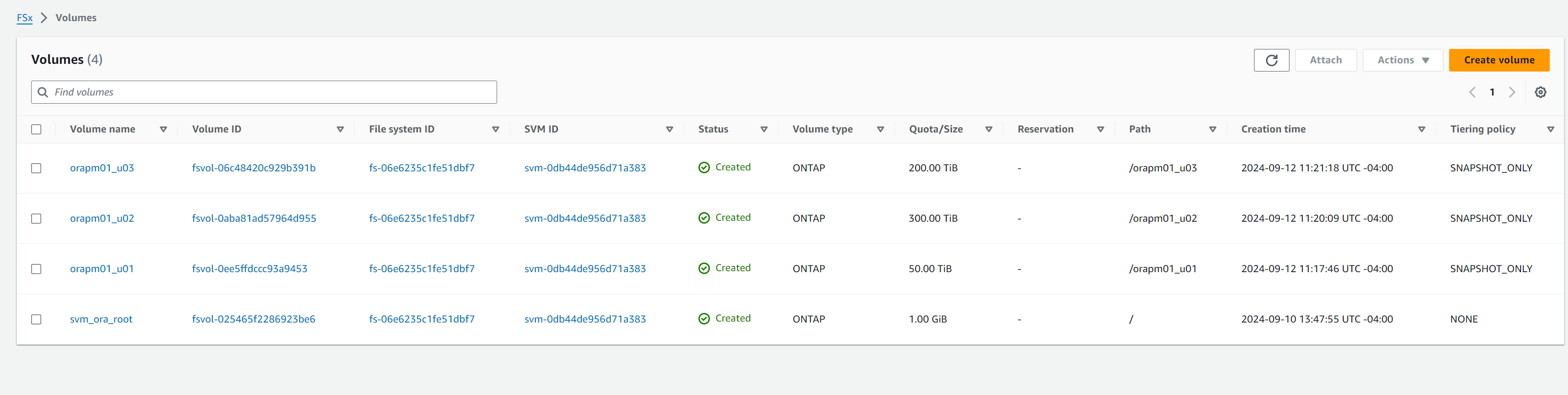
-
Étape suivant les fichiers d'installation d'Oracle 19c sur le nœud principal PCS, instance EC2 ip-172-30-15-111.ec2.internal /tmp/archive répertoire avec autorisation 777.
installer_archives: - "LINUX.X64_193000_db_home.zip" - "p34765931_190000_Linux-x86-64.zip" - "p6880880_190000_Linux-x86-64.zip"
-
Exécuter le playbook pour la configuration Linux pour
all nodes.ansible-playbook -i hosts 2-linux_config.yml -u ec2-user -e @vars/vars.yml[admin@ansiblectl na_oracle_deploy_nfs]$ ansible-playbook -i hosts 2-linux_config.yml -u ec2-user -e @vars/vars.yml PLAY [Linux Setup and Storage Config for Oracle] **************************************************************************************************************************************************************************************************************************************************************************** TASK [Gathering Facts] ****************************************************************************************************************************************************************************************************************************************************************************************************** ok: [orapm01] ok: [orapm02] TASK [linux : Configure RedHat 7 for Oracle DB installation] **************************************************************************************************************************************************************************************************************************************************************** skipping: [orapm01] skipping: [orapm02] TASK [linux : Configure RedHat 8 for Oracle DB installation] **************************************************************************************************************************************************************************************************************************************************************** included: /home/admin/na_oracle_deploy_nfs/roles/linux/tasks/rhel8_config.yml for orapm01, orapm02 TASK [linux : Register subscriptions for RedHat Server] ********************************************************************************************************************************************************************************************************************************************************************* ok: [orapm01] ok: [orapm02] . . .
-
Exécuter le playbook pour la configuration Oracle
only on primary node(commentez le nœud de secours dans le fichier hosts).ansible-playbook -i hosts 4-oracle_config.yml -u ec2-user -e @vars/vars.yml --skip-tags "enable_db_start_shut"[admin@ansiblectl na_oracle_deploy_nfs]$ ansible-playbook -i hosts 4-oracle_config.yml -u ec2-user -e @vars/vars.yml --skip-tags "enable_db_start_shut" PLAY [Oracle installation and configuration] ******************************************************************************************************************************************************************************************************************************************************************************** TASK [Gathering Facts] ****************************************************************************************************************************************************************************************************************************************************************************************************** ok: [orapm01] TASK [oracle : Oracle software only install] ******************************************************************************************************************************************************************************************************************************************************************************** included: /home/admin/na_oracle_deploy_nfs/roles/oracle/tasks/oracle_install.yml for orapm01 TASK [oracle : Create mount points for NFS file systems / Mount NFS file systems on Oracle hosts] *************************************************************************************************************************************************************************************************************************** included: /home/admin/na_oracle_deploy_nfs/roles/oracle/tasks/oracle_mount_points.yml for orapm01 TASK [oracle : Create mount points for NFS file systems] ******************************************************************************************************************************************************************************************************************************************************************** changed: [orapm01] => (item=/u01) changed: [orapm01] => (item=/u02) changed: [orapm01] => (item=/u03) . . .
-
Une fois la base de données déployée, commentez les montages /u01, /u02, /u03 dans /etc/fstab sur le nœud principal, car les points de montage seront gérés uniquement par PCS.
sudo vi /etc/fstab[root@ip-172-30-15-111 ec2-user]# cat /etc/fstab UUID=eaa1f38e-de0f-4ed5-a5b5-2fa9db43bb38 / xfs defaults 0 0 /mnt/swapfile swap swap defaults 0 0 #172.30.15.95:/orapm01_u01 /u01 nfs rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 0 0 #172.30.15.95:/orapm01_u02 /u02 nfs rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 0 0 #172.30.15.95:/orapm01_u03 /u03 nfs rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 0 0
-
Copiez /etc/oratab /etc/oraInst.loc, /home/oracle/.bash_profile sur le nœud de secours. Assurez-vous de conserver la propriété et les autorisations appropriées des fichiers.
-
Arrêtez la base de données, l'écouteur et démontez /u01, /u02, /u03 sur le nœud principal.
[root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Wed Sep 18 16:51:02 UTC 2024 [oracle@ip-172-30-15-111 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Wed Sep 18 16:51:16 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> shutdown immediate; SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 [oracle@ip-172-30-15-111 ~]$ lsnrctl stop listener.ntap [oracle@ip-172-30-15-111 ~]$ exit logout [root@ip-172-30-15-111 ec2-user]# umount /u01 [root@ip-172-30-15-111 ec2-user]# umount /u02 [root@ip-172-30-15-111 ec2-user]# umount /u03
-
Créez des points de montage sur le nœud de secours ip-172-30-15-5.
mkdir /u01 mkdir /u02 mkdir /u03 -
Montez les volumes de base de données FSx ONTAP sur le nœud de secours ip-172-30-15-5.
mount -t nfs 172.30.15.95:/orapm01_u01 /u01 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536mount -t nfs 172.30.15.95:/orapm01_u02 /u02 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536mount -t nfs 172.30.15.95:/orapm01_u03 /u03 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536[root@ip-172-30-15-5 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.7G 33M 7.7G 1% /dev/shm tmpfs 7.7G 17M 7.7G 1% /run tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup /dev/xvda2 50G 21G 30G 41% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 844G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 844G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 844G 100% /u03
-
Modifié en utilisateur Oracle, relier le binaire.
[root@ip-172-30-15-5 ec2-user]# su - oracle Last login: Thu Sep 12 18:09:03 UTC 2024 on pts/0 [oracle@ip-172-30-15-5 ~]$ env | grep ORA ORACLE_SID=NTAP ORACLE_HOME=/u01/app/oracle/product/19.0.0/NTAP [oracle@ip-172-30-15-5 ~]$ cd $ORACLE_HOME/bin [oracle@ip-172-30-15-5 bin]$ ./relink writing relink log to: /u01/app/oracle/product/19.0.0/NTAP/install/relinkActions2024-09-12_06-21-40PM.log
-
Copiez la bibliothèque dnfs dans le dossier odm. Relink pourrait perdre le fichier de bibliothèque dfns.
[oracle@ip-172-30-15-5 odm]$ cd /u01/app/oracle/product/19.0.0/NTAP/rdbms/lib/odm [oracle@ip-172-30-15-5 odm]$ cp ../../../lib/libnfsodm19.so .
-
Démarrer la base de données pour valider sur le nœud de secours ip-172-30-15-5.
[oracle@ip-172-30-15-5 odm]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Thu Sep 12 18:30:04 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to an idle instance. SQL> startup; ORACLE instance started. Total System Global Area 6442449688 bytes Fixed Size 9177880 bytes Variable Size 1090519040 bytes Database Buffers 5335154688 bytes Redo Buffers 7598080 bytes Database mounted. Database opened. SQL> select name, open_mode from v$database; NAME OPEN_MODE --------- -------------------- NTAP READ WRITE SQL> show pdbs CON_ID CON_NAME OPEN MODE RESTRICTED ---------- ------------------------------ ---------- ---------- 2 PDB$SEED READ ONLY NO 3 NTAP_PDB1 READ WRITE NO 4 NTAP_PDB2 READ WRITE NO 5 NTAP_PDB3 READ WRITE NO -
Arrêtez la base de données et restaurez-la sur le nœud principal ip-172-30-15-111.
SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. SQL> exit [root@ip-172-30-15-5 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.7G 33M 7.7G 1% /dev/shm tmpfs 7.7G 17M 7.7G 1% /run tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup /dev/xvda2 50G 21G 30G 41% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 844G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 844G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 844G 100% /u03 [root@ip-172-30-15-5 ec2-user]# umount /u01 [root@ip-172-30-15-5 ec2-user]# umount /u02 [root@ip-172-30-15-5 ec2-user]# umount /u03 [root@ip-172-30-15-111 ec2-user]# mount -t nfs 172.30.15.95:/orapm01_u01 /u01 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. [root@ip-172-30-15-111 ec2-user]# mount -t nfs 172.30.15.95:/orapm01_u02 /u02 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. [root@ip-172-30-15-111 ec2-user]# mount -t nfs 172.30.15.95:/orapm01_u03 /u03 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. [root@ip-172-30-15-111 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.8G 48M 7.7G 1% /dev/shm tmpfs 7.8G 33M 7.7G 1% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/xvda2 50G 29G 22G 58% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 844G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 844G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 844G 100% /u03 [root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Thu Sep 12 18:13:34 UTC 2024 on pts/1 [oracle@ip-172-30-15-111 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Thu Sep 12 18:38:46 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to an idle instance. SQL> startup; ORACLE instance started. Total System Global Area 6442449688 bytes Fixed Size 9177880 bytes Variable Size 1090519040 bytes Database Buffers 5335154688 bytes Redo Buffers 7598080 bytes Database mounted. Database opened. SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 [oracle@ip-172-30-15-111 ~]$ lsnrctl start listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 12-SEP-2024 18:39:17 Copyright (c) 1991, 2022, Oracle. All rights reserved. Starting /u01/app/oracle/product/19.0.0/NTAP/bin/tnslsnr: please wait... TNSLSNR for Linux: Version 19.0.0.0.0 - Production System parameter file is /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Log messages written to /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=ip-172-30-15-111.ec2.internal)(PORT=1521))) Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=ip-172-30-15-111.ec2.internal)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias listener.ntap Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 12-SEP-2024 18:39:17 Uptime 0 days 0 hr. 0 min. 0 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=ip-172-30-15-111.ec2.internal)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) The listener supports no services The command completed successfully
Configurer les ressources Oracle pour la gestion PCS
Details
L'objectif de la configuration du clustering Pacemaker est de mettre en place une solution de haute disponibilité active/passive pour exécuter Oracle dans un environnement AWS EC2 et FSx ONTAP avec une intervention minimale de l'utilisateur en cas de panne. L'exemple suivant illustre la configuration des ressources Oracle pour la gestion PCS.
-
En tant qu'utilisateur root sur l'instance EC2 principale ip-172-30-15-111, créez une adresse IP privée secondaire avec une adresse IP privée inutilisée dans le bloc CIDR VPC en tant qu'IP flottante. Au cours du processus, créez un groupe de ressources Oracle auquel appartiendra l’adresse IP privée secondaire.
pcs resource create privip ocf:heartbeat:awsvip secondary_private_ip=172.30.15.33 --group oracle[root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 16:25:35 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 16:25:23 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 2 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-5.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Si le privilège est créé sur un nœud de cluster de secours, déplacez-le vers le nœud principal comme indiqué ci-dessous. -
Déplacer une ressource entre les nœuds du cluster.
pcs resource move privip ip-172-30-15-111.ec2.internal[root@ip-172-30-15-111 ec2-user]# pcs resource move privip ip-172-30-15-111.ec2.internal Warning: A move constraint has been created and the resource 'privip' may or may not move depending on other configuration [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx WARNINGS: Following resources have been moved and their move constraints are still in place: 'privip' Run 'pcs constraint location' or 'pcs resource clear <resource id>' to view or remove the constraints, respectively Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 16:26:38 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 16:26:27 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 2 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal (Monitoring) Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled -
Créez une IP virtuelle (vip) pour Oracle. L'IP virtuelle flottera entre le nœud principal et le nœud de secours selon les besoins.
pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.30.15.33 cidr_netmask=25 nic=eth0 op monitor interval=10s --group oracle[root@ip-172-30-15-111 ec2-user]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.30.15.33 cidr_netmask=25 nic=eth0 op monitor interval=10s --group oracle [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx WARNINGS: Following resources have been moved and their move constraints are still in place: 'privip' Run 'pcs constraint location' or 'pcs resource clear <resource id>' to view or remove the constraints, respectively Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 16:27:34 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 16:27:24 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 3 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled -
En tant qu'utilisateur Oracle, mettez à jour les fichiers listener.ora et tnsnames.ora pour pointer vers l'adresse VIP. Redémarrez l'auditeur. Faites rebondir la base de données si nécessaire pour que la base de données s'enregistre auprès de l'écouteur.
vi $ORACLE_HOME/network/admin/listener.oravi $ORACLE_HOME/network/admin/tnsnames.ora[oracle@ip-172-30-15-111 admin]$ cat listener.ora # listener.ora Network Configuration File: /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora # Generated by Oracle configuration tools. LISTENER.NTAP = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.30.15.33)(PORT = 1521)) (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521)) ) ) [oracle@ip-172-30-15-111 admin]$ cat tnsnames.ora # tnsnames.ora Network Configuration File: /u01/app/oracle/product/19.0.0/NTAP/network/admin/tnsnames.ora # Generated by Oracle configuration tools. NTAP = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.30.15.33)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = NTAP.ec2.internal) ) ) LISTENER_NTAP = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.30.15.33)(PORT = 1521)) [oracle@ip-172-30-15-111 admin]$ lsnrctl status listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 13-SEP-2024 18:28:17 Copyright (c) 1991, 2022, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.30.15.33)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias listener.ntap Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 13-SEP-2024 18:15:51 Uptime 0 days 0 hr. 12 min. 25 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=172.30.15.33)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcps)(HOST=ip-172-30-15-111.ec2.internal)(PORT=5500))(Security=(my_wallet_directory=/u01/app/oracle/product/19.0.0/NTAP/admin/NTAP/xdb_wallet))(Presentation=HTTP)(Session=RAW)) Services Summary... Service "21f0b5cc1fa290e2e0636f0f1eacfd43.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b74445329119e0636f0f1eacec03.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b83929709164e0636f0f1eacacc3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAP.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAPXDB.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb1.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb2.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... The command completed successfully **Oracle listener now listens on vip for database connection** -
Ajoutez les points de montage /u01, /u02, /u03 au groupe de ressources Oracle.
pcs resource create u01 ocf:heartbeat:Filesystem device='172.30.15.95:/orapm01_u01' directory='/u01' fstype='nfs' options='rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536' --group oraclepcs resource create u02 ocf:heartbeat:Filesystem device='172.30.15.95:/orapm01_u02' directory='/u02' fstype='nfs' options='rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536' --group oraclepcs resource create u03 ocf:heartbeat:Filesystem device='172.30.15.95:/orapm01_u03' directory='/u03' fstype='nfs' options='rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536' --group oracle -
Créez un ID utilisateur de moniteur PCS dans Oracle DB.
[root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Fri Sep 13 18:12:24 UTC 2024 on pts/0 [oracle@ip-172-30-15-111 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 19:08:41 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> CREATE USER c##ocfmon IDENTIFIED BY "XXXXXXXX"; User created. SQL> grant connect to c##ocfmon; Grant succeeded. SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0
-
Ajoutez une base de données au groupe de ressources Oracle.
pcs resource create ntap ocf:heartbeat:oracle sid='NTAP' home='/u01/app/oracle/product/19.0.0/NTAP' user='oracle' monuser='C##OCFMON' monpassword='XXXXXXXX' monprofile='DEFAULT' --group oracle -
Ajoutez un écouteur de base de données au groupe de ressources Oracle.
pcs resource create listener ocf:heartbeat:oralsnr sid='NTAP' listener='listener.ntap' --group=oracle -
Mettez à jour toutes les contraintes d'emplacement des ressources dans le groupe de ressources Oracle sur le nœud principal en tant que nœud préféré.
pcs constraint location privip prefers ip-172-30-15-111.ec2.internal pcs constraint location vip prefers ip-172-30-15-111.ec2.internal pcs constraint location u01 prefers ip-172-30-15-111.ec2.internal pcs constraint location u02 prefers ip-172-30-15-111.ec2.internal pcs constraint location u03 prefers ip-172-30-15-111.ec2.internal pcs constraint location ntap prefers ip-172-30-15-111.ec2.internal pcs constraint location listener prefers ip-172-30-15-111.ec2.internal[root@ip-172-30-15-111 ec2-user]# pcs constraint config Location Constraints: Resource: listener Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: ntap Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: privip Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: u01 Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: u02 Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: u03 Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: vip Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Ordering Constraints: Colocation Constraints: Ticket Constraints: -
Valider la configuration des ressources Oracle.
pcs status[root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 19:25:32 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 19:23:40 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * ntap (ocf::heartbeat:oracle): Started ip-172-30-15-111.ec2.internal * listener (ocf::heartbeat:oralsnr): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Validation HA après déploiement
Details
Après le déploiement, il est essentiel d'exécuter des tests et des validations pour garantir que le cluster de basculement de base de données Oracle PCS est configuré correctement et fonctionne comme prévu. La validation du test comprend le basculement géré et la simulation d'une défaillance et d'une récupération inattendues des ressources par le mécanisme de protection du cluster.
-
Validez la clôture du nœud en déclenchant manuellement la clôture du nœud de secours et observez que le nœud de secours a été mis hors ligne et redémarré après un délai d'attente.
pcs stonith fence <standbynodename>[root@ip-172-30-15-111 ec2-user]# pcs stonith fence ip-172-30-15-5.ec2.internal Node: ip-172-30-15-5.ec2.internal fenced [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 21:58:45 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 21:55:12 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-111.ec2.internal ] * OFFLINE: [ ip-172-30-15-5.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * ntap (ocf::heartbeat:oracle): Started ip-172-30-15-111.ec2.internal * listener (ocf::heartbeat:oralsnr): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled -
Simulez une panne d'écoute de base de données en tuant le processus d'écoute et observez que PCS a surveillé la panne d'écoute et l'a redémarré en quelques secondes.
[root@ip-172-30-15-111 ec2-user]# ps -ef | grep lsnr oracle 154895 1 0 18:15 ? 00:00:00 /u01/app/oracle/product/19.0.0/NTAP/bin/tnslsnr listener.ntap -inherit root 217779 120186 0 19:36 pts/0 00:00:00 grep --color=auto lsnr [root@ip-172-30-15-111 ec2-user]# kill -9 154895 [root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Thu Sep 19 14:58:54 UTC 2024 [oracle@ip-172-30-15-111 ~]$ lsnrctl status listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 13-SEP-2024 19:36:51 Copyright (c) 1991, 2022, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.30.15.33)(PORT=1521))) TNS-12541: TNS:no listener TNS-12560: TNS:protocol adapter error TNS-00511: No listener Linux Error: 111: Connection refused Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC1521))) TNS-12541: TNS:no listener TNS-12560: TNS:protocol adapter error TNS-00511: No listener Linux Error: 111: Connection refused [oracle@ip-172-30-15-111 ~]$ lsnrctl status listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 19-SEP-2024 15:00:10 Copyright (c) 1991, 2022, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.30.15.33)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias listener.ntap Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 16-SEP-2024 14:00:14 Uptime 3 days 0 hr. 59 min. 56 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=172.30.15.33)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcps)(HOST=ip-172-30-15-111.ec2.internal)(PORT=5500))(Security=(my_wallet_directory=/u01/app/oracle/product/19.0.0/NTAP/admin/NTAP/xdb_wallet))(Presentation=HTTP)(Session=RAW)) Services Summary... Service "21f0b5cc1fa290e2e0636f0f1eacfd43.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b74445329119e0636f0f1eacec03.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b83929709164e0636f0f1eacacc3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAP.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAPXDB.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb1.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb2.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... The command completed successfully
-
Simulez une panne de base de données en arrêtant le processus pmon et observez que PCS a surveillé la panne de la base de données et l'a redémarrée en quelques secondes.
**Make a remote connection to ntap database** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 15:42:42 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Thu Sep 12 2024 13:37:28 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-111.ec2.internal SQL> **Kill ntap pmon process to simulate a failure** [root@ip-172-30-15-111 ec2-user]# ps -ef | grep pmon oracle 159247 1 0 18:27 ? 00:00:00 ora_pmon_NTAP root 230595 120186 0 19:44 pts/0 00:00:00 grep --color=auto pmon [root@ip-172-30-15-111 ec2-user]# kill -9 159247 **Observe the DB failure** SQL> / select instance_name, host_name from v$instance * ERROR at line 1: ORA-03113: end-of-file on communication channel Process ID: 227424 Session ID: 396 Serial number: 4913 SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 **Reconnect to DB after reboot** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 15:47:24 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Sep 13 2024 15:42:47 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-111.ec2.internal SQL>
-
Validez un basculement de base de données gérée du nœud principal vers le nœud de secours en mettant le nœud principal en mode veille pour basculer les ressources Oracle vers le nœud de secours.
pcs node standby <nodename>**Stopping Oracle resources on primary node in reverse order** [root@ip-172-30-15-111 ec2-user]# pcs node standby ip-172-30-15-111.ec2.internal [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:01:16 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:01:08 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Node ip-172-30-15-111.ec2.internal: standby (with active resources) * Online: [ ip-172-30-15-5.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Stopping ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Stopped * u03 (ocf::heartbeat:Filesystem): Stopped * ntap (ocf::heartbeat:oracle): Stopped * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **Starting Oracle resources on standby node in sequencial order** [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:01:34 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:01:08 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Node ip-172-30-15-111.ec2.internal: standby * Online: [ ip-172-30-15-5.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-5.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-5.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-5.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-5.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-5.ec2.internal * ntap (ocf::heartbeat:oracle): Starting ip-172-30-15-5.ec2.internal * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **NFS mount points mounted on standby node** [root@ip-172-30-15-5 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.7G 33M 7.7G 1% /dev/shm tmpfs 7.7G 17M 7.7G 1% /run tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup /dev/xvda2 50G 21G 30G 41% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 840G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 840G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 840G 100% /u03 tmpfs 1.6G 0 1.6G 0% /run/user/54321 **Database opened on standby node** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 16:34:08 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Sep 13 2024 15:47:28 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select name, open_mode from v$database; NAME OPEN_MODE --------- -------------------- NTAP READ WRITE SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-5.ec2.internal SQL> -
Validez une restauration de base de données gérée du mode veille au mode principal par un nœud principal non en veille et observez que les ressources Oracle reviennent automatiquement en raison du paramètre de nœud préféré.
pcs node unstandby <nodename>**Stopping Oracle resources on standby node for failback to primary** [root@ip-172-30-15-111 ec2-user]# pcs node unstandby ip-172-30-15-111.ec2.internal [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:41:30 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:41:18 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Stopping ip-172-30-15-5.ec2.internal * vip (ocf::heartbeat:IPaddr2): Stopped * u01 (ocf::heartbeat:Filesystem): Stopped * u02 (ocf::heartbeat:Filesystem): Stopped * u03 (ocf::heartbeat:Filesystem): Stopped * ntap (ocf::heartbeat:oracle): Stopped * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **Starting Oracle resources on primary node for failback** [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:41:45 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:41:18 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * ntap (ocf::heartbeat:oracle): Starting ip-172-30-15-111.ec2.internal * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **Database now accepts connection on primary node** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 16:46:07 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Sep 13 2024 16:34:12 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-111.ec2.internal SQL>
Ceci complète la validation Oracle HA et la démonstration de la solution dans AWS EC2 avec le clustering Pacemaker et Amazon FSx ONTAP comme backend de stockage de base de données.
Sauvegarde, restauration et clonage Oracle avec SnapCenter
Details
NetApp recommande l'outil d'interface utilisateur SnapCenter pour gérer la base de données Oracle déployée dans AWS EC2 et Amazon FSx ONTAP. Se référer à TR-4979"Oracle simplifié et autogéré dans VMware Cloud sur AWS avec FSx ONTAP monté en invité" section Oracle backup, restore, and clone with SnapCenter pour plus de détails sur la configuration de SnapCenter et l'exécution des flux de travail de sauvegarde, de restauration et de clonage de la base de données.
Où trouver des informations supplémentaires
Pour en savoir plus sur les informations décrites dans ce document, consultez les documents et/ou sites Web suivants :